代码仓库
代码实现部分很简单!
为了大家方便,代码我已经全部都上传到了 GitHub,希望大家可以点个Start!
https://github.com/turbo-duck/biquge_fiction_spider
背景信息
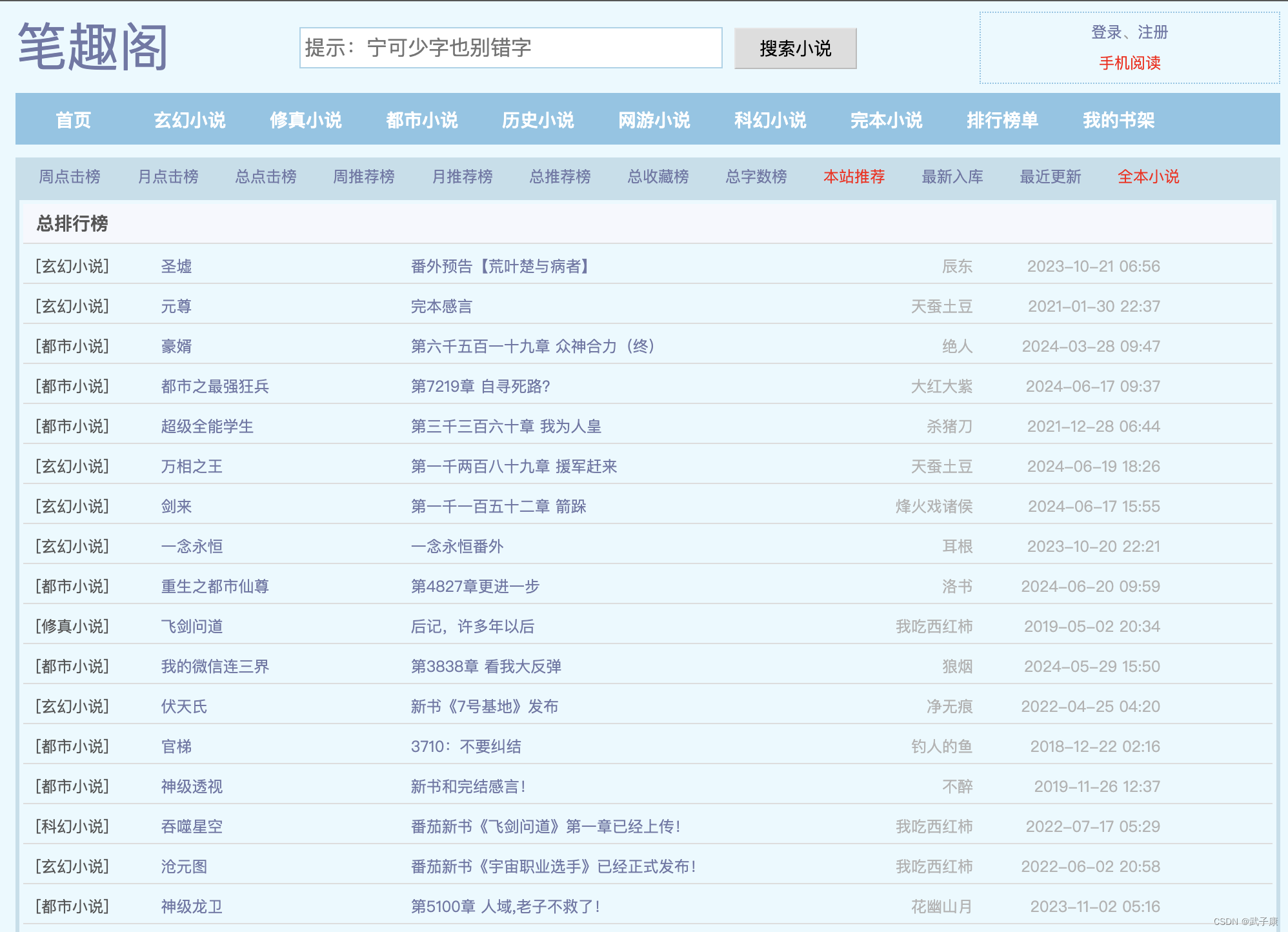
我们计划对笔趣阁网站的小说进行爬取。我们通过小说的排行榜对整个网站的所有小说进行爬取。
shell
https://www.xbiqugew.com/top/allvisit/对其翻页进行分析
shell
https://www.xbiqugew.com/top/allvisit/2.html可以看到,构造URL的方式就是:1.html,2.html等等···
同时该网站是没有防护的(请注意!出于学习的目的,你应该合理控制请求的速度,不要给人家网站打挂了!!! )
使用技术
- Scrapy 对数据进行爬取
- SQLite
由于数据量并没有非常大, 所以使用了Python就可以直接使用的SQLite。
对于Scrapy的指令,这里简单一放,详细的大家可以系统学习一下!
shell
https://scrapy.org/
scrapy startproject spider
...
scrapu genspider spider spider.com编写代码
spider.py
爬虫的主逻辑
python
import scrapy
import re
import time
from biquge_top_spider.items import BiqugeTopSpiderItem
class SpiderSpider(scrapy.Spider):
name = "spider"
# allowed_domains = ["spider.com"]
# start_urls = ["https://spider.com"]
def start_requests(self):
for page in range(1, 1392):
url = f"https://www.xbiqugew.com/top/allvisit/{page}.html"
print(f"url: {url}")
yield scrapy.Request(
url=url,
callback=self.parse_list,
)
def extract_last_number(self, text):
# 使用正则表达式查找所有的数字
numbers = re.findall(r'.*?/(\d+)/', text)
# print(numbers)
if numbers:
# 返回最后一个数字
return str(numbers[-1])
else:
return ""
def parse_list(self, response):
data_list = response.xpath(".//div[@class='novelslistss']//li")
page_info = response.xpath(".//em[@id='pagestats']/text()").extract_first()
for each in data_list:
each_type = each.xpath("./span[@class='s1']/text()").extract_first()
each_href = each.xpath("./span[@class='s2']/a/@href").extract_first()
each_title = each.xpath("./span[@class='s2']/a/text()").extract_first()
each_author = each.xpath("./span[@class='s4']/text()").extract_first()
each_update_time = each.xpath("./span[@class='s5']/text()").extract_first()
each_code = self.extract_last_number(each_href)
now_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item = BiqugeTopSpiderItem()
item['each_code'] = str(each_code)
item['each_type'] = str(each_type)
item['each_href'] = str(each_href)
item['each_title'] = str(each_title)
item['each_author'] = str(each_author)
item['each_update_time'] = str(each_update_time)
item['page_info'] = str(page_info)
item['now_time'] = str(now_time)
print(f"each_code: {each_code}")
yield itemPiplines.py
python
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import sqlite3
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class BiqugeTopSpiderPipeline:
def process_item(self, item, spider):
return item
class SQLitePipeline:
def __init__(self):
self.cursor = None
self.connection = None
def open_spider(self, spider):
self.connection = sqlite3.connect('biquge.db')
self.cursor = self.connection.cursor()
def close_spider(self, spider):
self.connection.close()
def process_item(self, item, spider):
sql = '''
INSERT INTO biquge_list (each_code, each_type, each_href, each_title, each_author, each_update_time, page_info, now_time)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
'''
self.cursor.execute(sql, (
item.get('each_code'),
item.get('each_type'),
item.get('each_href'),
item.get('each_title'),
item.get('each_author'),
item.get('each_update_time'),
item.get('page_info'),
item.get('now_time')
))
self.connection.commit()
return itemSettings.py
python
# Scrapy settings for biquge_top_spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "biquge_top_spider"
SPIDER_MODULES = ["biquge_top_spider.spiders"]
NEWSPIDER_MODULE = "biquge_top_spider.spiders"
LOG_LEVEL = "ERROR"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "biquge_top_spider (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.2
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "biquge_top_spider.middlewares.BiqugeTopSpiderSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "biquge_top_spider.middlewares.BiqugeTopSpiderDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# "biquge_top_spider.pipelines.BiqugeTopSpiderPipeline": 300,
"biquge_top_spider.pipelines.SQLitePipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"其他部分
其他部分按默认的来就行,不用修改了。
数据库表
建立了一个简单的表。
sql
CREATE TABLE biquge_list (
id INTEGER PRIMARY KEY AUTOINCREMENT,
each_code TEXT,
each_type TEXT,
each_href TEXT,
each_title TEXT,
each_author TEXT,
each_update_time TEXT,
page_info TEXT,
now_time TEXT
);测试效果
shell
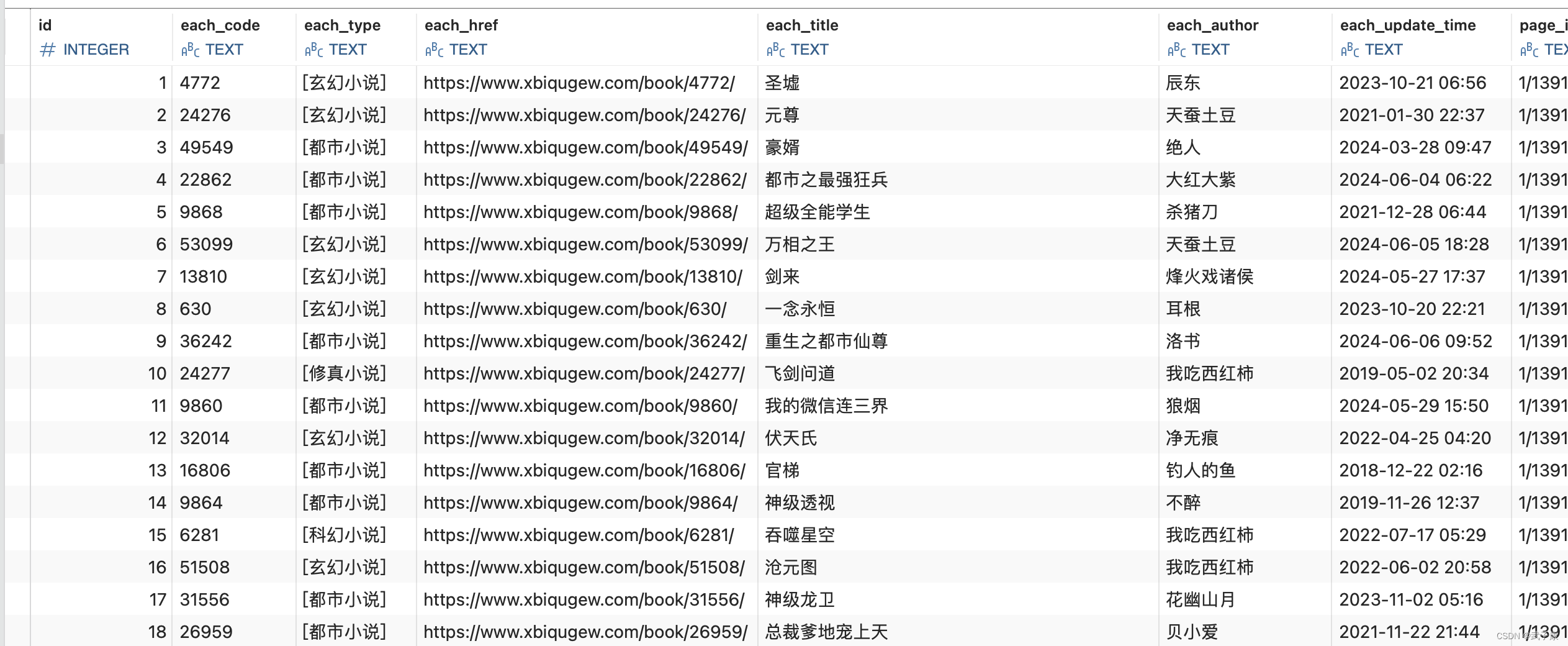
scrapy crawl spider经过一段时间的运行之后,可以查看数据库的内容。发现数据已经来了。
后续安排
我们已经拿到了每个小说的链接: each_href ,后续我们把这个URL存入到MQ中,对小说的详细内容进行爬取(小说介绍、章节列表)。