说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解 ),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1 . 项目背景
在当今医疗健康领域,乳腺癌作为威胁女性健康的主要恶性肿瘤之一,其早期诊断与精准治疗对于提高患者生存率至关重要。随着医学信息学与人工智能技术的飞速发展,利用大数据分析、机器学习以及深度学习等先进手段构建乳腺癌分类预测模型,已成为研究热点和临床实践的重要方向。
近年来,全球乳腺癌发病率持续上升,成为全球范围内女性癌症发病率最高的疾病之一。尽管乳腺癌在早期发现时治疗效果较为理想,但传统的诊断方法如钼靶摄影、超声检查及组织活检等存在一定的局限性,如误诊率、漏诊率问题以及对患者造成的身体与心理负担。因此,开发高效、准确且便捷的乳腺癌分类预测模型,不仅能够提高诊断效率,还能促进个性化医疗方案的制定,为患者带来更为及时有效的干预措施。
研究意义:
提升早期诊断率:通过分析乳腺影像学、生物标志物、遗传学及临床数据,构建的预测模型能够有效识别乳腺癌早期迹象,为患者争取宝贵的治疗时间。
个性化医疗策略:结合患者的个体差异,预测模型能辅助医生定制化治疗方案,实现精准医疗。
资源优化配置:高效预测模型可减少不必要的检查和治疗,优化医疗资源分配,减轻公共卫生系统的负担。
促进科研进展:模型的开发与验证过程能够深化对乳腺癌生物学机制的理解,推动相关基础研究与技术创新。
基于以上背景,本研究拟采用先进的机器学习算法,结合丰富的乳腺癌临床数据集,构建一个高度准确且具有临床实用价值的乳腺癌分类预测模型。最终目标是为乳腺癌的早期筛查与精准管理提供科学依据,进而改善患者预后,提升公众健康水平。
本项目通过逻辑回归分类模型、决策树分类模型、随机森林分类模型和XGBoost分类模型实现乳腺癌分类预测。
2 . 数据获取
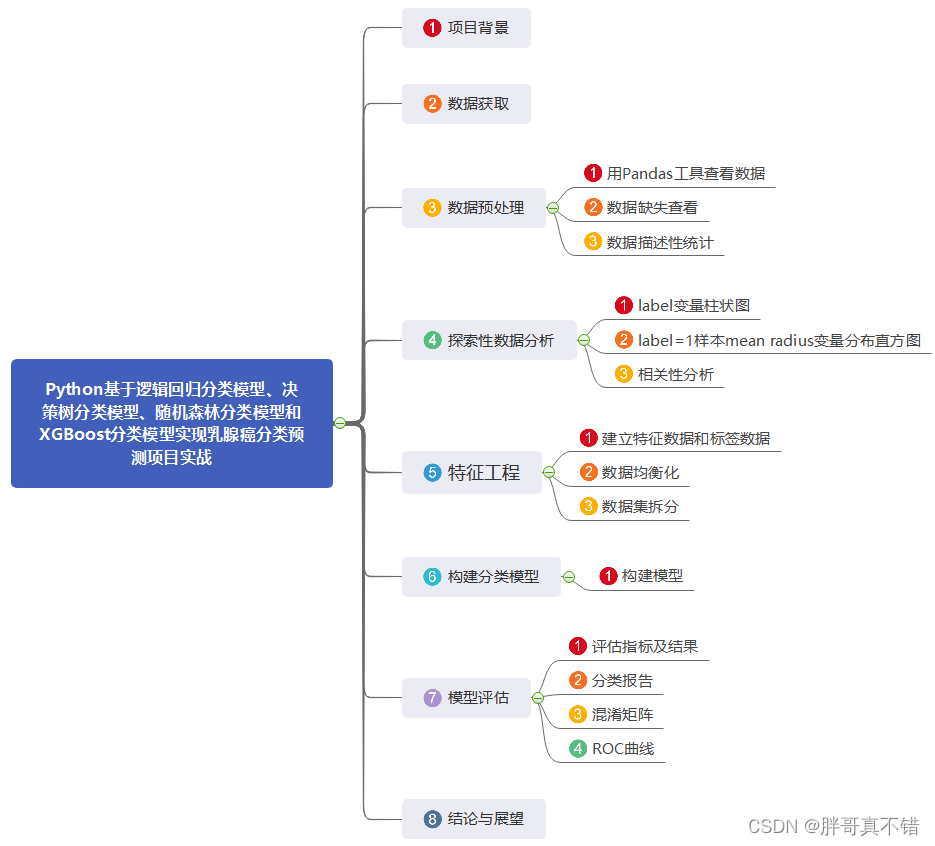
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
|------------|-------------------------|-----------------------|
| 编号 | 变量名称 | 描述 |
| 1 | mean radius | 平均半径:肿瘤区域的平均边界距离中心的距离 |
| 2 | mean texture | 平均纹理:肿瘤区域灰度变化的程度 |
| 3 | mean perimeter | 平均周长:肿瘤区域的边界长度 |
| 4 | mean area | 平均面积:肿瘤区域所占的总面积 |
| 5 | mean smoothness | 平均平滑度:轮廓的光滑程度 |
| 6 | mean compactness | 平均紧密度:形状接近球形的程度 |
| 7 | mean concavity | 平均凹度:轮廓凹进去的程度 |
| 8 | mean concave points | 平均凹点数:轮廓凹陷部分的尖点数量 |
| 9 | mean symmetry | 平均对称性:肿瘤区域相对于中心的对称程度 |
| 10 | mean fractal dimension | 平均分形维数:描述肿瘤边缘复杂性的度量 |
| 11 | radius error | 半径误差:半径测量的不确定性 |
| 12 | texture error | 纹理误差:纹理测量的不确定性 |
| 13 | perimeter error | 周长误差:周长测量的不确定性 |
| 14 | area error | 面积误差:面积测量的不确定性 |
| 15 | smoothness error | 平滑度误差:平滑度测量的不确定性 |
| 16 | compactness error | 紧密度误差:紧密度测量的不确定性 |
| 17 | concavity error | 凹度误差:凹度测量的不确定性 |
| 18 | concave points error | 凹点数误差:凹点数测量的不确定性 |
| 19 | symmetry error | 对称性误差:对称性测量的不确定性 |
| 20 | fractal dimension error | 分形维数误差:分形维数测量的不确定性 |
| 21 | worst radius | 最差半径:最不理想的半径测量值 |
| 22 | worst texture | 最差纹理:最不理想的纹理测量值 |
| 23 | worst perimeter | 最差周长:最不理想的周长测量值 |
| 24 | worst area | 最差面积:最不理想的面积测量值 |
| 25 | worst smoothness | 最差平滑度:最不理想的平滑度测量值 |
| 26 | worst compactness | 最差紧密度:最不理想的紧密度测量值 |
| 27 | worst concavity | 最差凹度:最不理想的凹度测量值 |
| 28 | worst concave points | 最差凹点数:最不理想的凹点数测量值 |
| 29 | worst symmetry | 最差对称性:最不理想的对称性测量值 |
| 30 | worst fractal dimension | 最差分形维数:最不理想的分形维数测量值 |
| 31 | label | 1良性,0恶性 |
数据详情如下(部分展示):
3. 数据预处理
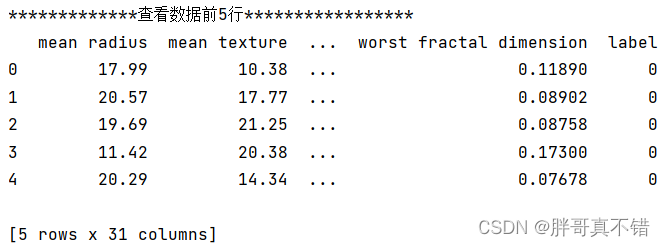
3.1 用P andas 工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:

3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:
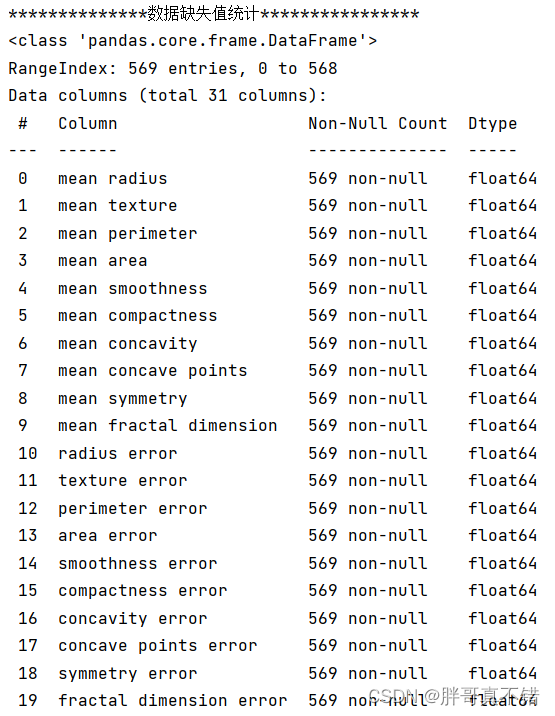

从上图可以看到,总共有31个变量,数据中无缺失值,共569条数据。
关键代码:

3. 3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
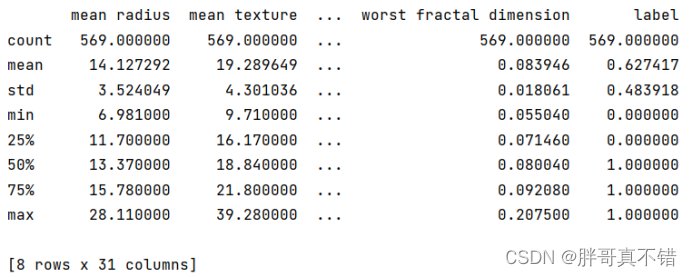
关键代码如下:

4. 探索性数据分析
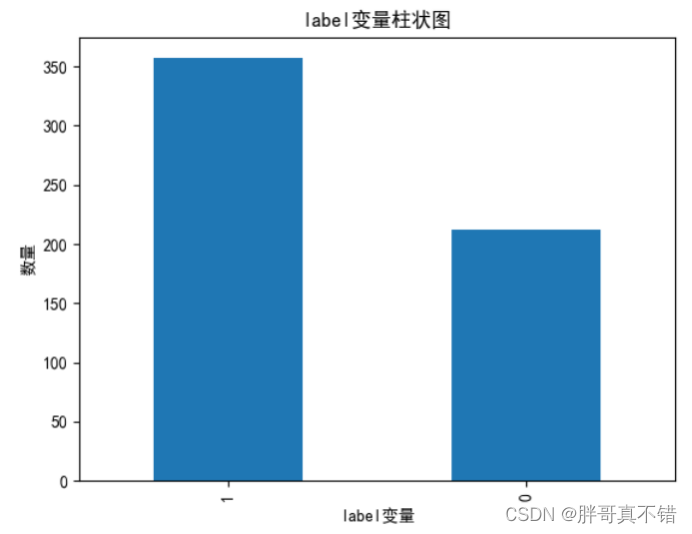
4 . 1 label变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
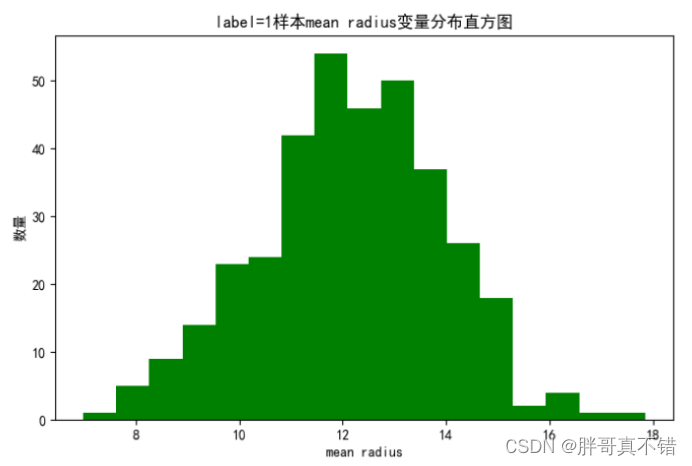
4 .2 label =1样本 mean radius 变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4 .3 相关性分析
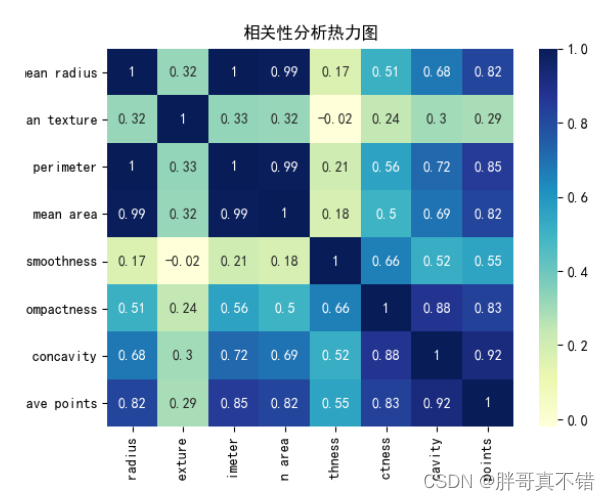
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5. 特征工程
5.1 建立特征数据和标签数据
关键代码如下:
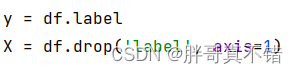
5.2 数据 均衡化

通过上图可以看到,数据均衡化后,标签两种样本的数量一致。
5. 3 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6. 构建分类模型
主要使用逻辑回归分类算法、决策树分类算法、随机森林分类算法和XGBoost分类算法,用于目标分类。
6. 1 构建模型
|------------|--------------|------------------|
| 编号 | 模型名称 | 参数 |
| 1 | 逻辑回归分类模型 | 默认参数值 |
| 2 | 决策树分类模型 | 默认参数值 |
| 3 | 决策树分类模型 | random_state=123 |
| 4 | 随机森林分类模型 | 默认参数值 |
| 5 | 随机森林分类模型 | random_state=42 |
| 6 | XGBoost分类模型 | 默认参数值 |
| 7 | XGBoost分类模型 | random_state=42 |
7 . 模型评估
7 .1 评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
|--------------|--------------|-------------|
| 模型名称 | 指标名称 | 指标值 |
| 测试集 |||
| 逻辑回归分类模型 | 准确率 | 0.9720 |
| 逻辑回归分类模型 | 查准率 | 0.9452 |
| 逻辑回归分类模型 | 查全率 | 1.0 |
| 逻辑回归分类模型 | F1分值 | 0.9718 |
| 决策树分类模型 | 准确率 | 0.9441 |
| 决策树分类模型 | 查准率 | 0.9296 |
| 决策树分类模型 | 查全率 | 0.9565 |
| 决策树分类模型 | F1分值 | 0.9429 |
| 随机森林分类模型 | 准确率 | 0.9650 |
| 随机森林分类模型 | 查准率 | 0.9706 |
| 随机森林分类模型 | 查全率 | 0.9565 |
| 随机森林分类模型 | F1分值 | 0.9635 |
| XGBoost分类模型 | 准确率 | 0.9650 |
| XGBoost分类模型 | 查准率 | 0.9706 |
| XGBoost分类模型 | 查全率 | 0.9565 |
| XGBoost分类模型 | F1分值 | 0.9635 |
从上表可以看出,4个模型的F1分值都在0.9以上,说明这模型效果较好,其中逻辑回归模型F1最高为0.9718。
7. 2 分类报告
逻辑回归分类模型:
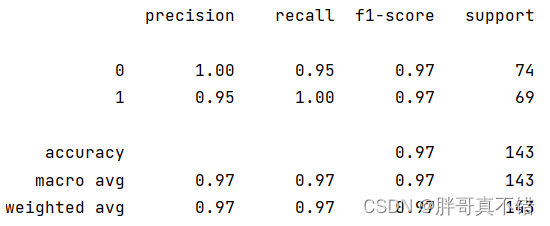
从上图可以看出,分类为0的F1分值为0.97;分类为1的F1分值为0.97。
决策树分类模型:
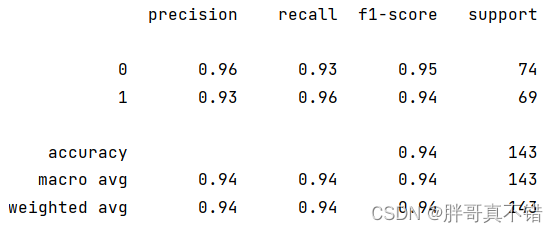
从上图可以看出,分类为0的F1分值为0.95;分类为1的F1分值为0.94。
随机森林分类模型:
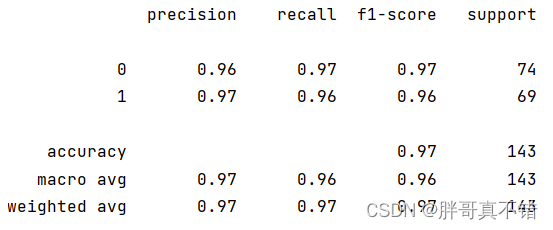
从上图可以看出,分类为0的F1分值为0.97;分类为1的F1分值为0.96。
XGBoost分类模型:
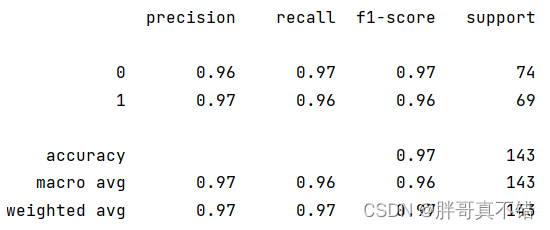
从上图可以看出,分类为0的F1分值为0.97;分类为1的F1分值为0.96。
7. 3 混淆矩阵
逻辑回归分类模型:

从上图可以看出,实际为0预测不为0的 有4个样本;实际为1预测不为1的 有0个样本。
决策树分类模型:
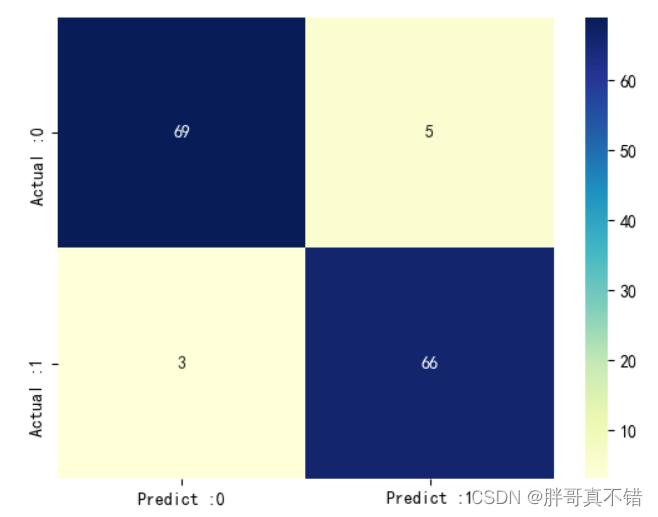
从上图可以看出,实际为0预测不为0的 有5个样本;实际为1预测不为1的 有3个样本。
随机森林分类模型:
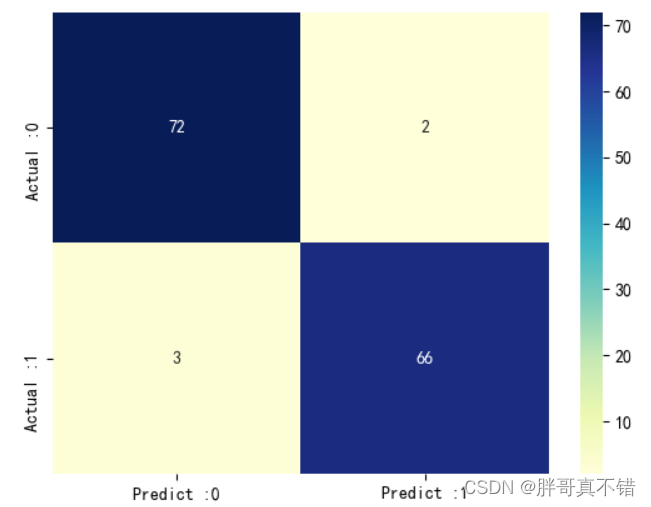
从上图可以看出,实际为0预测不为0的 有2个样本;实际为1预测不为1的 有3个样本。
XGBoost分类模型:

从上图可以看出,实际为0预测不为0的 有2个样本;实际为1预测不为1的 有3个样本。
7. 4 ROC曲线
逻辑回归分类模型:
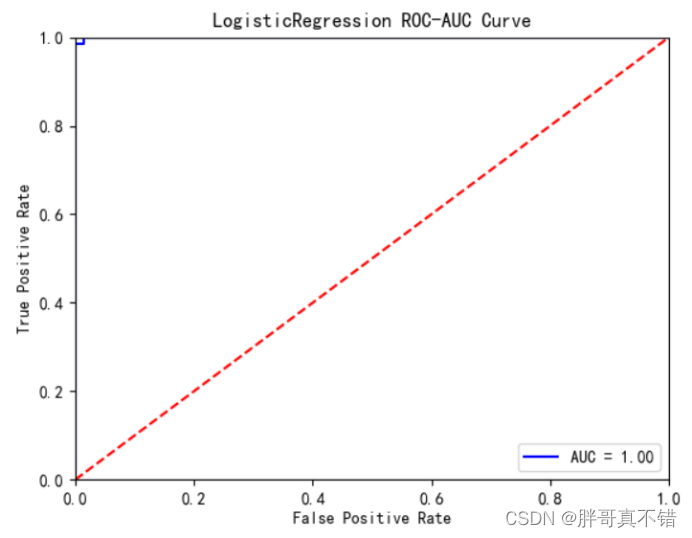
从上图可以看出,逻辑回归分类模型的AUC值为1.0。
决策树分类模型:
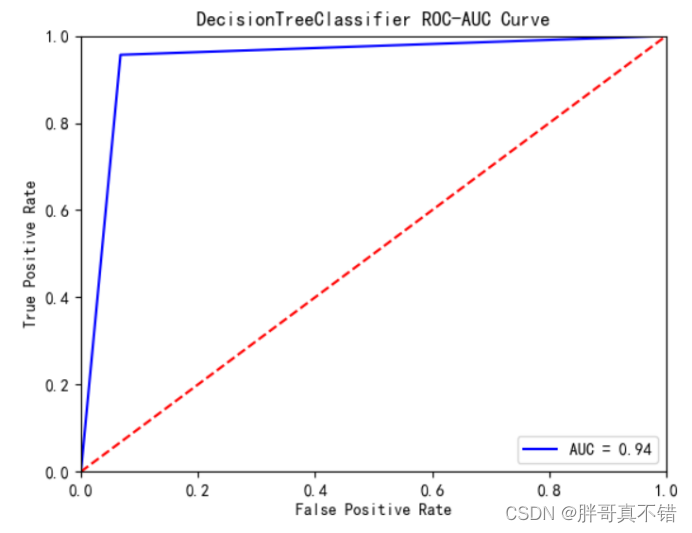
从上图可以看出,决策树分类模型的AUC值为0.94。
随机森林分类模型:
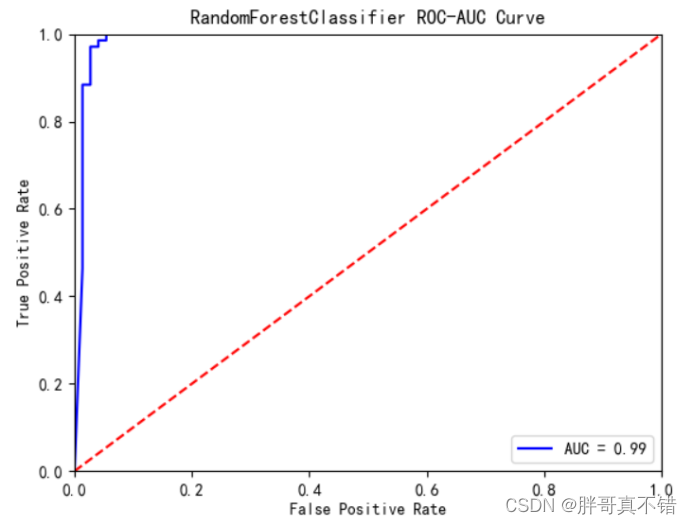
从上图可以看出,随机森林分类模型的AUC值为0.99。
XGBoost分类模型:
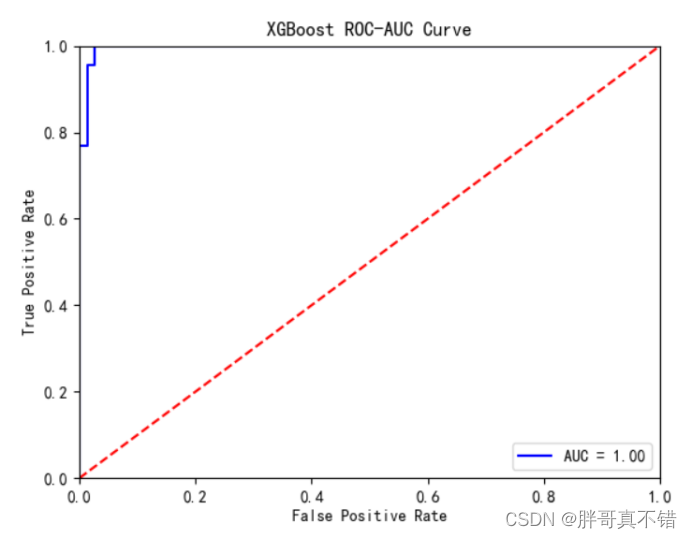
从上图可以看出,XGBoost分类模型的AUC值为1.0。
8. 结论与展望
综上所述,本文采用了逻辑回归、决策树、随机森林和XGBoost算法来构建分类模型,最终证明了4种模型效果良好,其中逻辑回归模型效果最优。此模型可用于日常产品的预测。
python
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 获取方式一:
# 项目实战合集导航:
https://docs.qq.com/sheet/DTVd0Y2NNQUlWcmd6?tab=BB08J2
# 获取方式二:
链接:https://pan.baidu.com/s/1vzkHRkRNmilTAg0TrlxgBw
提取码:z9v4