文章目录
-
- 单选题
- 多选题
- 知识点回顾
-
- 什么是Hadoop?
- Hadoop有哪些特性?
- Hadoop生态系统是怎么样的?
- [(1) HDFS](#(1) HDFS)
- [(2) HBase](#(2) HBase)
- [(3) MapReduce](#(3) MapReduce)
- [(4) Hive](#(4) Hive)
- [(5) Pig](#(5) Pig)
- [(6) Mahout](#(6) Mahout)
- [(7) Zookeeper](#(7) Zookeeper)
- [(8) Flume](#(8) Flume)
- [(9) Sqoop](#(9) Sqoop)
- [(10) Ambari](#(10) Ambari)
单选题
-
1、下列哪个不属于Hadoop的特性?
- A、成本高 ☑️
- B、高可靠性
- C、高容错性
- D、运行在 Linux 平台上
-
2、Hadoop框架中最核心的设计是什么?
- A、为海量数据提供存储的HDFS和对数据进行计算的MapReduce ☑️
- B、提供整个HDFS文件系统的NameSpace(命名空间)管理、块管理等所有服务
- C、Hadoop不仅可以运行在企业内部的集群中,也可以运行在云计算环境中
- D、Hadoop被视为事实上的大数据处理标准
-
3、在一个基本的Hadoop集群中,DataNode主要负责什么?
- A、负责执行由JobTracker指派的任务
- B、协调数据计算任务
- C、负责协调集群中的数据存储
- D、存储被拆分的数据块 ☑️
-
4、Hadoop最初是由谁创建的?
- A、Lucene
- B、Doug Cutting ☑️
- C、Apache
- D、MapReduce
-
5、下列哪一个不属于Hadoop的大数据层的功能?
- A、数据挖掘
- B、离线分析
- C、实时计算 ☑️
- D、BI分析
-
6、在一个基本的Hadoop集群中,SecondaryNameNode主要负责什么?
- A、帮助 NameNode ☑️ 收集文件系统运行的状态信息
- B、负责执行由 JobTracker 指派的任务
- C、协调数据计算任务
- D、负责协调集群中的数据存储
-
7、下面哪一项不是Hadoop的特性?
- A、可扩展性高
- B、只支持少数几种编程语言 ☑️
- C、成本低
- D、能在linux上运行
-
8、在Hadoop项目结构中,HDFS指的是什么?
- A、分布式文件系统 ☑️
- B、分布式并行编程模型
- C、资源管理和调度器
- D、Hadoop上的数据仓库
-
9、在Hadoop项目结构中,MapReduce指的是什么?
- A、分布式并行编程模型 ☑️
- B、流计算框架
- C、Hadoop上的工作流管理系统
- D、提供分布式协调一致性服务
-
10、下面哪个不是Hadoop1.0的组件:
- A、HDFS
- B、MapReduce
- C、YARN ☑️
- D、NameNode 和 DataNode
多选题
-
1、Hadoop的特性包括哪些?
- A、高可扩展性 ☑️
- B、支持多种编程语言 ☑️
- C、成本低 ☑️
- D、运行在Linux平台上 ☑️
-
2、 下面哪个是Hadoop2.0的组件?
- A、ResourceManager ☑️
- B、JobTracker
- C、TaskTracker
- D、NodeManager ☑️
-
3、 一个基本的Hadoop集群中的节点主要包括什么?
- A、DataNode:存储被拆分的数据块 ☑️
- B、JobTracker:协调数据计算任务 ☑️
- C、TaskTracker:负责执行由JobTracker指派的任务 ☑️
- D、SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息 ☑️
-
4、 下列关于Hadoop的描述,哪些是正确的?
- A、为用户提供了系统底层细节透明的分布式基础架构 ☑️
- B、具有很好的跨平台特性 ☑️
- C、可以部署在廉价的计算机集群中 ☑️
- D、曾经被公认为行业大数据标准开源软件 ☑️
-
5、 Hadoop集群的整体性能主要受到什么因素影响?
- A、CPU性能 ☑️
- B、内存 ☑️
- C、网络 ☑️
- D、存储容量 ☑️
-
6、 下列关于Hadoop的描述,哪些是错误的?
- A、只能支持一种编程语言 ☑️
- B、具有较差的跨平台特性 ☑️
- C、可以部署在廉价的计算机集群中
- D、曾经被公认为行业大数据标准开源软件
-
7、 下列哪一项不属于Hadoop的特性?
- A、较低可扩展性 ☑️
- B、只支持java语言 ☑️
- C、成本低
- D、运行在Linux平台上
知识点回顾
什么是Hadoop?
Hadoop是Apache软件基金会的开源分布式计算平台,提供了系统底层细节透明的分布式基础架构。Hadoop采用Java语言开发,具有跨平台特性,并且可以在廉价的计算机集群中部署。Hadoop的核心组件包括分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce等。
Hadoop被公认为行业标准的大数据处理软件,在分布式环境下提供了处理海量数据的能力。几乎所有主流厂商,包括谷歌、雅虎、微软、思科、淘宝等,都提供了围绕Hadoop的开发工具、开源软件、商业化工具和技术服务。
Hadoop有哪些特性?
| 特性 | 描述 |
|---|---|
| 高效性 | 能够快速处理大规模数据,支持并行计算,提高数据处理效率 |
| 高容错性 | 通过数据冗余和任务重试机制,能够在硬件故障时继续工作 |
| 高可靠性 | 利用分布式文件系统和容错机制,确保数据的高可靠性和可用性 |
| 高可扩展性 | 可以根据需要扩展集群规模,从而处理更大的数据量 |
| 成本低 | 支持在廉价的商用硬件上运行,降低了数据处理的成本 |
| 运行在Linux平台上 | 主要在Linux平台上运行,具有良好的兼容性和稳定性 |
| 支持多种编程语言 | 除了Java,还支持Python、C++等多种编程语言,提供灵活的开发环境 |
Hadoop生态系统是怎么样的?
经过多年的发展,Hadoop生态系统在不断地完善和成熟,包含了多个子项目:
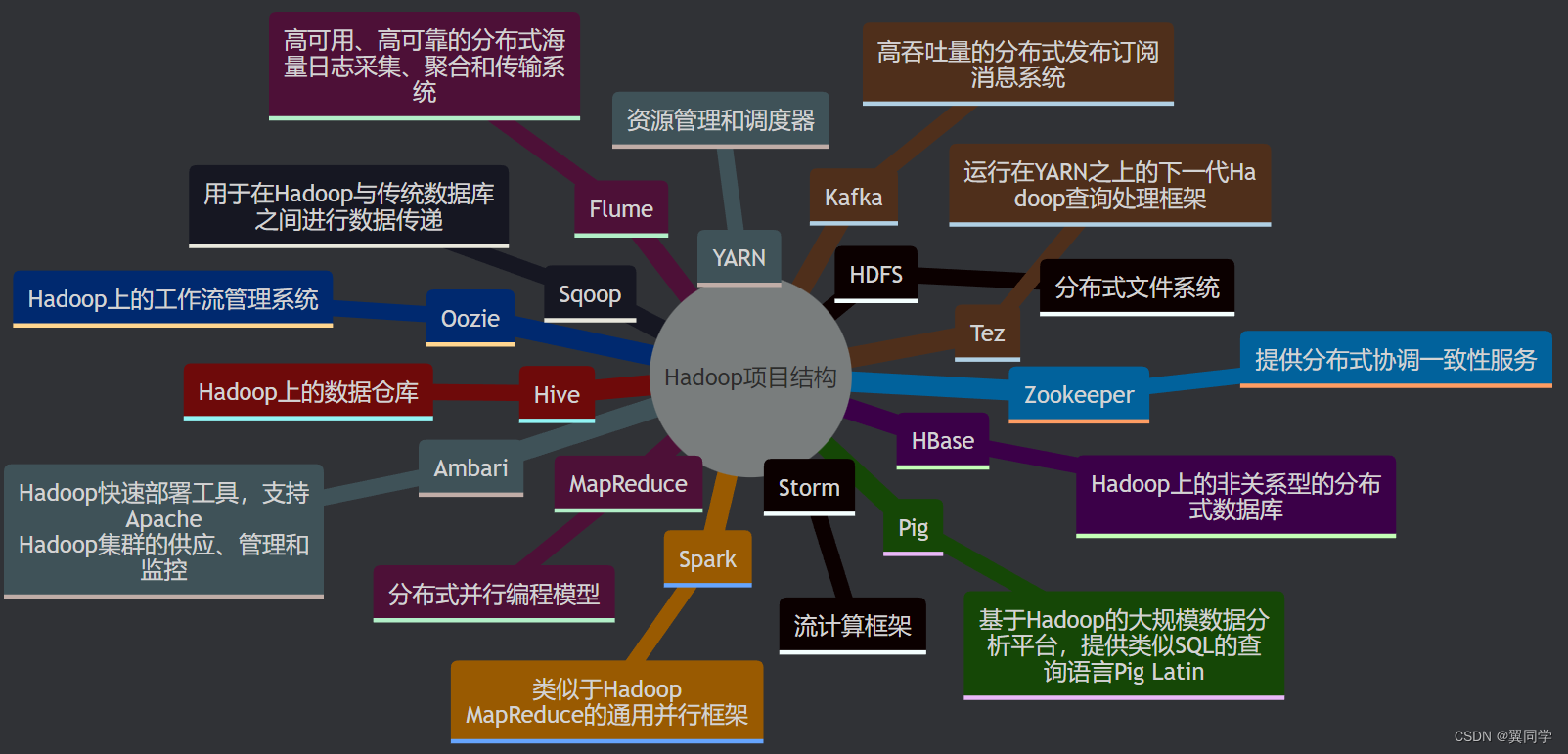
(1) HDFS
HDFS(Hadoop Distributed File System)是Hadoop的分布式文件系统。它用于存储大规模数据集并在多个计算节点上实现高吞吐量的数据访问。例如,一个企业有数十TB的日志数据需要存储和分析,HDFS可以将这些数据分布存储在多个节点上,并确保即使部分节点故障后,数据仍可访问。
(2) HBase
HBase是Hadoop上的非关系型分布式数据库。它提供了实时读写能力,适用于随机读写大数据集。比如一个社交媒体平台需要存储用户的实时活动数据,这些数据需要快速读写,HBase可以胜任此任务。
(3) MapReduce
MapReduce是Hadoop的分布式并行编程模型。它用于处理和生成大规模数据集,将复杂度、运行在大规模集群上的并行计算过程高度抽象为两个操作:Map和Reduce。比如处理一个包含数十亿条记录的日志文件以计算每个IP地址的访问次数,MapReduce可以将任务分布到多个节点,并行处理。
(4) Hive
Hive是Hadoop上的数据仓库。它提供了类似SQL的查询语言(HiveQL),使用户能够轻松地在Hadoop上执行数据分析。比如使用HiveQL查询存储在HDFS中的电商交易数据,生成报表和分析结果。
(5) Pig
Pig是基于Hadoop的大规模数据分析平台。它提供了类似SQL的查询语言Pig Latin,简化了对大数据的处理。比如分析一个网站的点击流日志数据以识别用户行为模式,Pig Latin脚本可以用来快速实现这些数据处理任务。
(6) Mahout
Mahout是Apache的一个开源机器学习库。它提供了各种可扩展的机器学习算法,适用于分类、聚类、协同过滤等任务。比如电商网站可以使用Mahout实现商品推荐系统,基于用户的历史购买行为进行个性化推荐。
(7) Zookeeper
Zookeeper是一个分布式协调一致性服务。它提供了高可用、高性能的分布式协调机制,确保分布式系统的同步、配置管理和命名。比如在一个分布式环境中,Zookeeper可以用来管理集群中的配置和状态信息,确保各节点的一致性。
(8) Flume
Flume是一个高可用、高可靠的分布式海量日志采集、聚合和传输系统。它用于从多个数据源(如日志文件)收集数据并传输到集中存储系统(如HDFS)。比如一个大型网站的日志数据可以通过Flume收集并实时传输到HDFS进行后续分析。
(9) Sqoop
Sqoop是用于在Hadoop与传统数据库之间进行数据传递的工具。它用于将数据从关系数据库(如MySQL)导入到Hadoop(如HDFS、Hive)或将数据从Hadoop导出到关系数据库。比如企业定期将生产数据库中的数据导入到Hadoop进行大数据分析,Sqoop可以自动化这个过程。
(10) Ambari
Ambari是Hadoop的快速部署工具。它支持Apache Hadoop集群的供应、管理和监控,简化了Hadoop的安装和配置。比如系统管理员可以使用Ambari在数十台服务器上快速部署一个Hadoop集群,并通过其图形界面进行集群管理和监控。