酒店推荐系统开题报告
一、研究背景与意义
随着旅游业的蓬勃发展和人们生活水平的提高,酒店行业迎来了前所未有的发展机遇。然而,面对众多的酒店选择,消费者往往难以在短时间内找到最适合自己需求和预算的酒店。因此,开发一款高效、智能的酒店推荐系统,对于提升消费者体验、促进酒店业发展具有重要意义。
本研究的酒店推荐系统旨在通过分析用户的偏好、行为数据以及酒店的各项信息,为用户推荐最符合其需求的酒店。该系统不仅能够为消费者节省选择时间,提高满意度,还能帮助酒店业者更好地了解消费者需求,优化服务质量和提高运营效率。
二、研究目的与目标
本研究的主要目的是开发一款高效、智能的酒店推荐系统,具体目标包括:
- 构建用户画像:通过分析用户的历史行为数据、偏好等信息,构建用户画像,为推荐算法提供精准的用户特征。
- 酒店信息整合:收集并整合各类酒店信息,包括酒店位置、价格、设施、评价等,为推荐算法提供全面的酒店数据支持。
- 推荐算法研究:研究并应用先进的推荐算法,如协同过滤、深度学习等,根据用户画像和酒店信息为用户推荐最符合其需求的酒店。
- 系统开发与实现:设计并实现酒店推荐系统的功能模块,包括用户管理、酒店信息管理、推荐算法模块等,确保系统的稳定性和易用性。
三、研究内容与方法
本研究将围绕酒店推荐系统的设计与实现展开,具体研究内容包括:
- 用户画像构建:研究用户画像的构建方法,包括数据收集、预处理、特征提取等步骤,确保用户画像的准确性和全面性。
- 酒店信息整合:研究酒店信息的获取和整合方法,包括网络爬虫、API接口等技术手段,确保酒店数据的全面性和实时性。
- 推荐算法研究:研究并应用先进的推荐算法,如基于内容的推荐、协同过滤推荐、深度学习推荐等,通过实验验证算法的有效性和准确性。
- 系统开发与实现:设计并实现酒店推荐系统的功能模块,包括用户管理、酒店信息管理、推荐算法模块等,并进行系统测试和优化。
本研究将采用文献综述、实验验证和案例分析等方法进行研究。首先通过文献综述了解酒店推荐系统的研究现状和发展趋势;然后通过实验验证推荐算法的有效性和准确性;最后通过案例分析验证系统的实用性和可推广性。
四、预期成果与贡献
本研究预期将取得以下成果和贡献:
- 构建一套高效、智能的酒店推荐系统,为消费者提供个性化的酒店推荐服务,提高消费者满意度和酒店运营效率。
- 提出一种基于用户画像和酒店信息的推荐算法,实现精准推荐,提高推荐效果和用户体验。
- 为酒店业者提供一套有效的数据分析工具,帮助他们更好地了解消费者需求和市场趋势,优化服务质量和提高盈利能力。
五、研究计划与时间安排
本研究计划分为以下阶段进行:
- 第一阶段(XX月-XX月):进行文献综述和需求分析,明确研究目标和内容。
- 第二阶段(XX月-XX月):进行用户画像构建和酒店信息整合工作,为推荐算法提供数据支持。
- 第三阶段(XX月-XX月):研究并应用推荐算法,进行实验验证和结果分析。
- 第四阶段(XX月-XX月):设计并实现酒店推荐系统的功能模块,进行系统测试和优化。
- 第五阶段(XX月-XX月):撰写论文并准备答辩工作。
以上是本研究的酒店推荐系统开题报告,如有不足之处,请各位专家和老师指正。
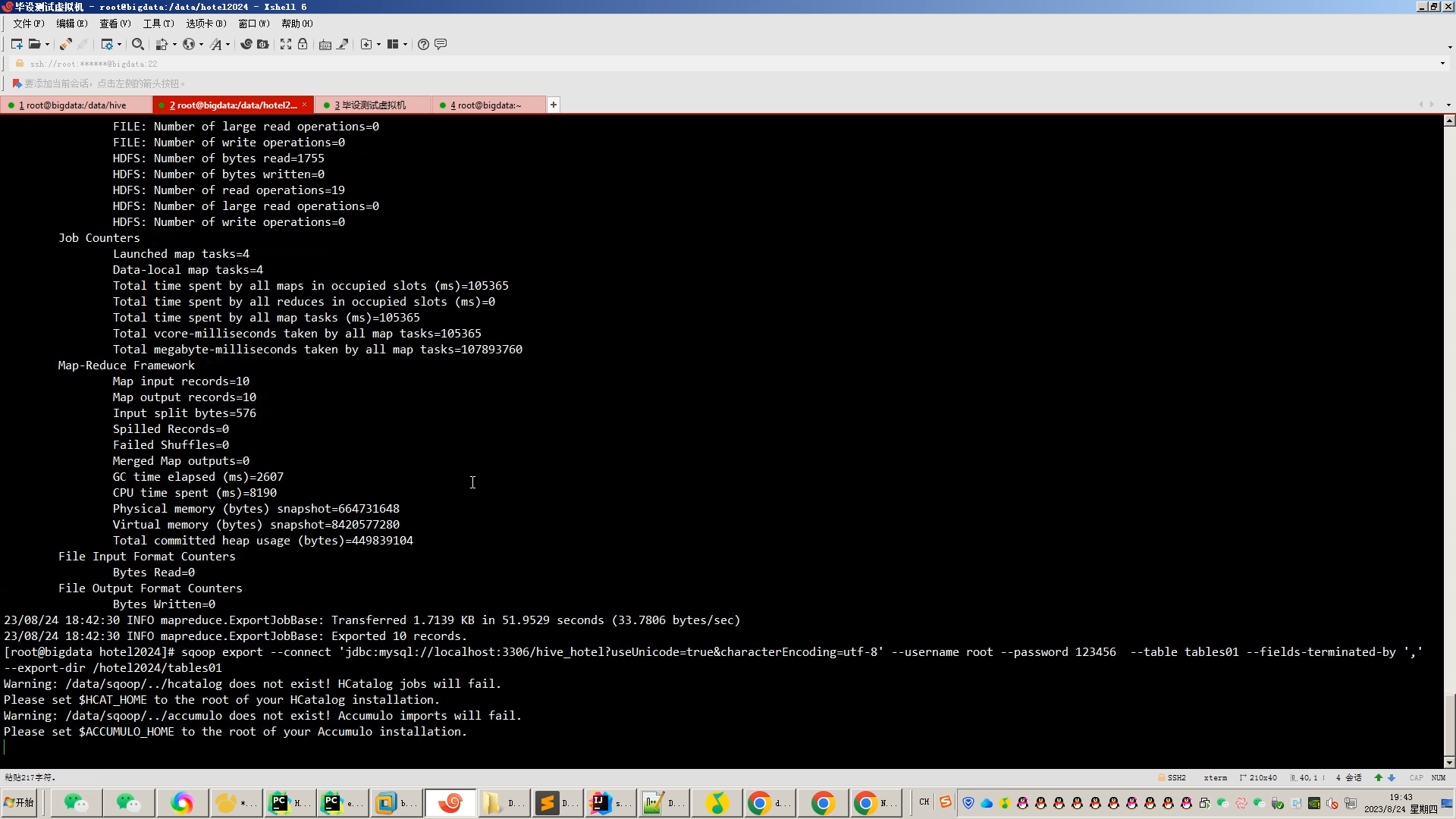
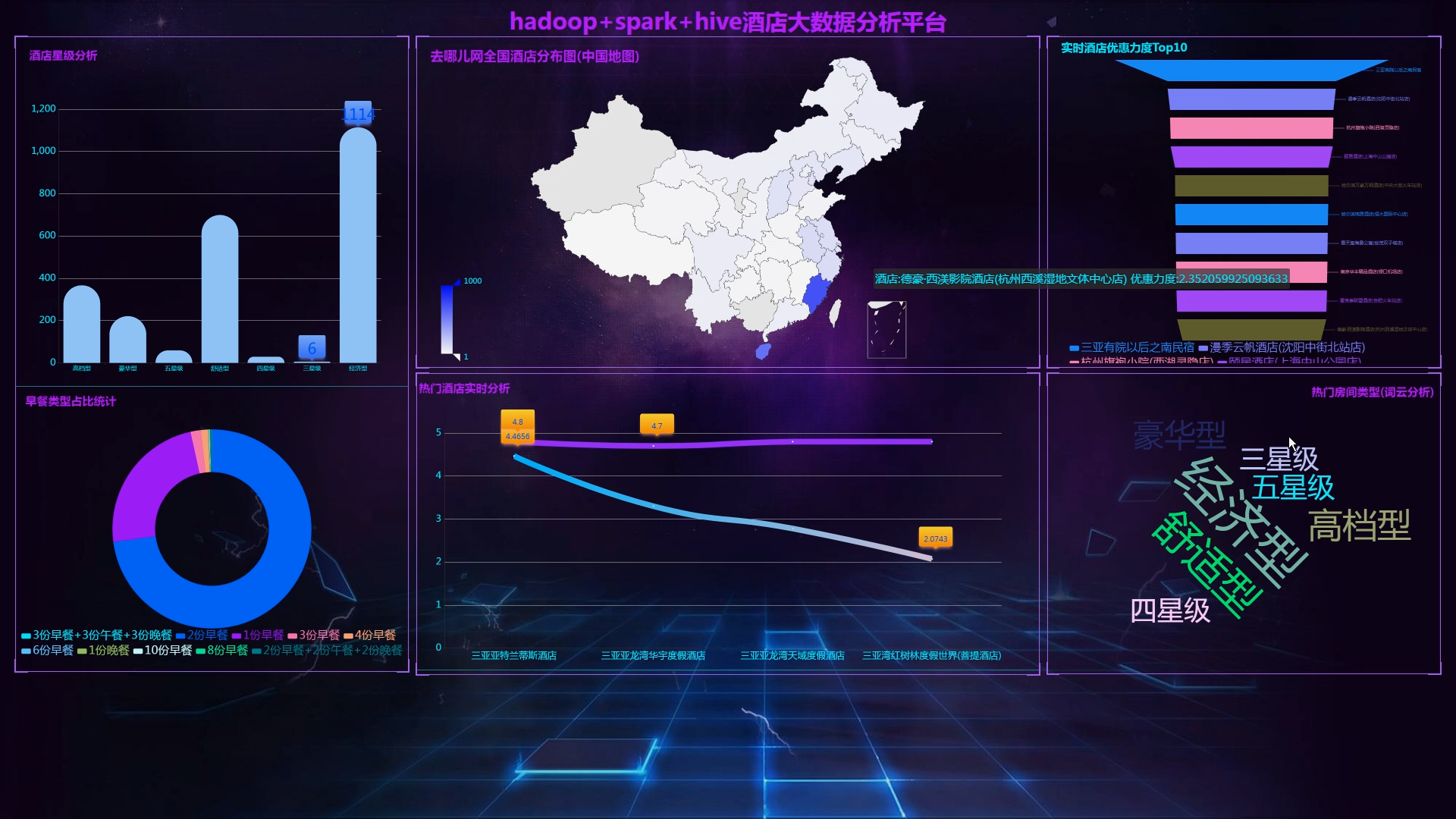
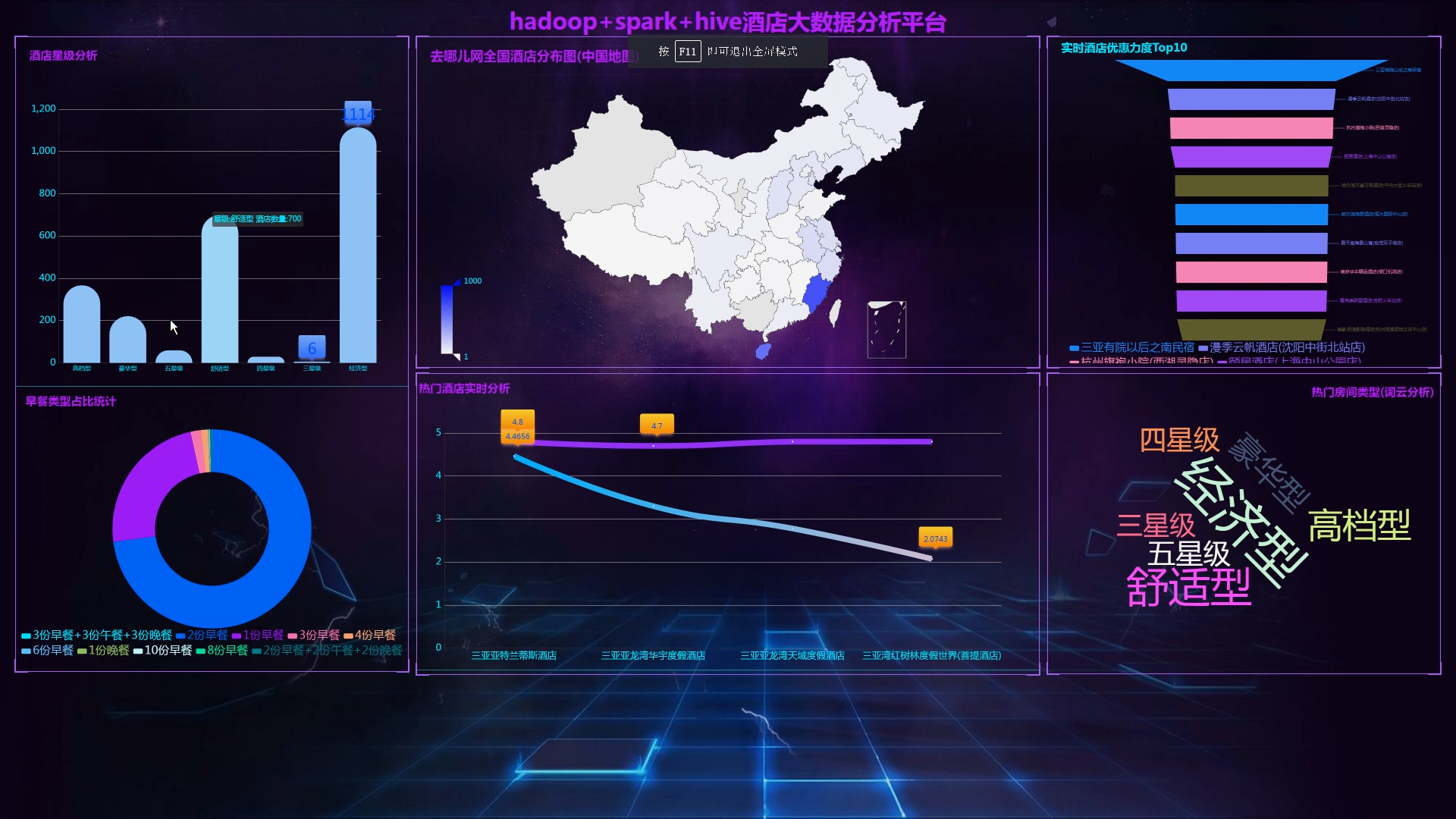


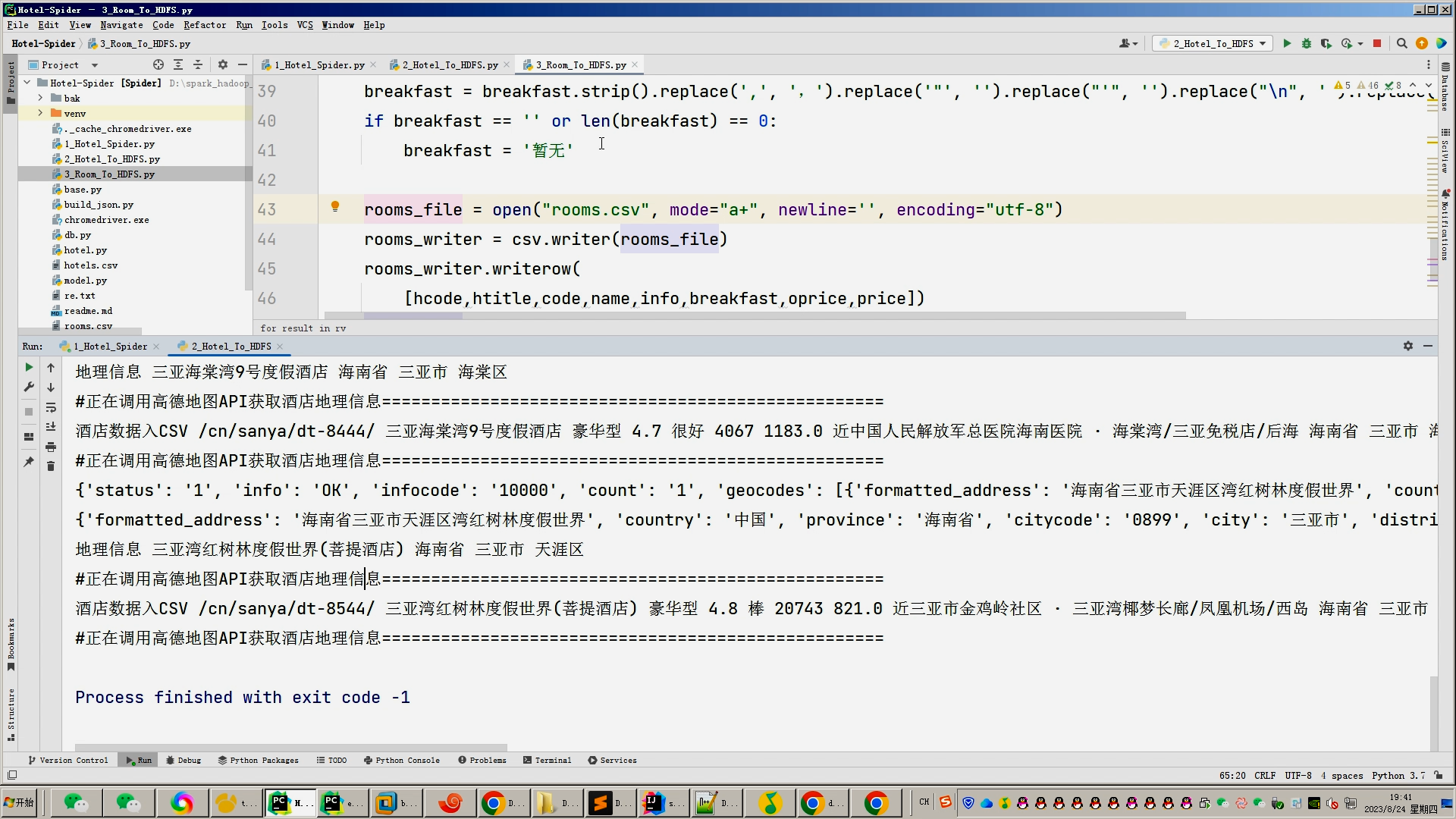
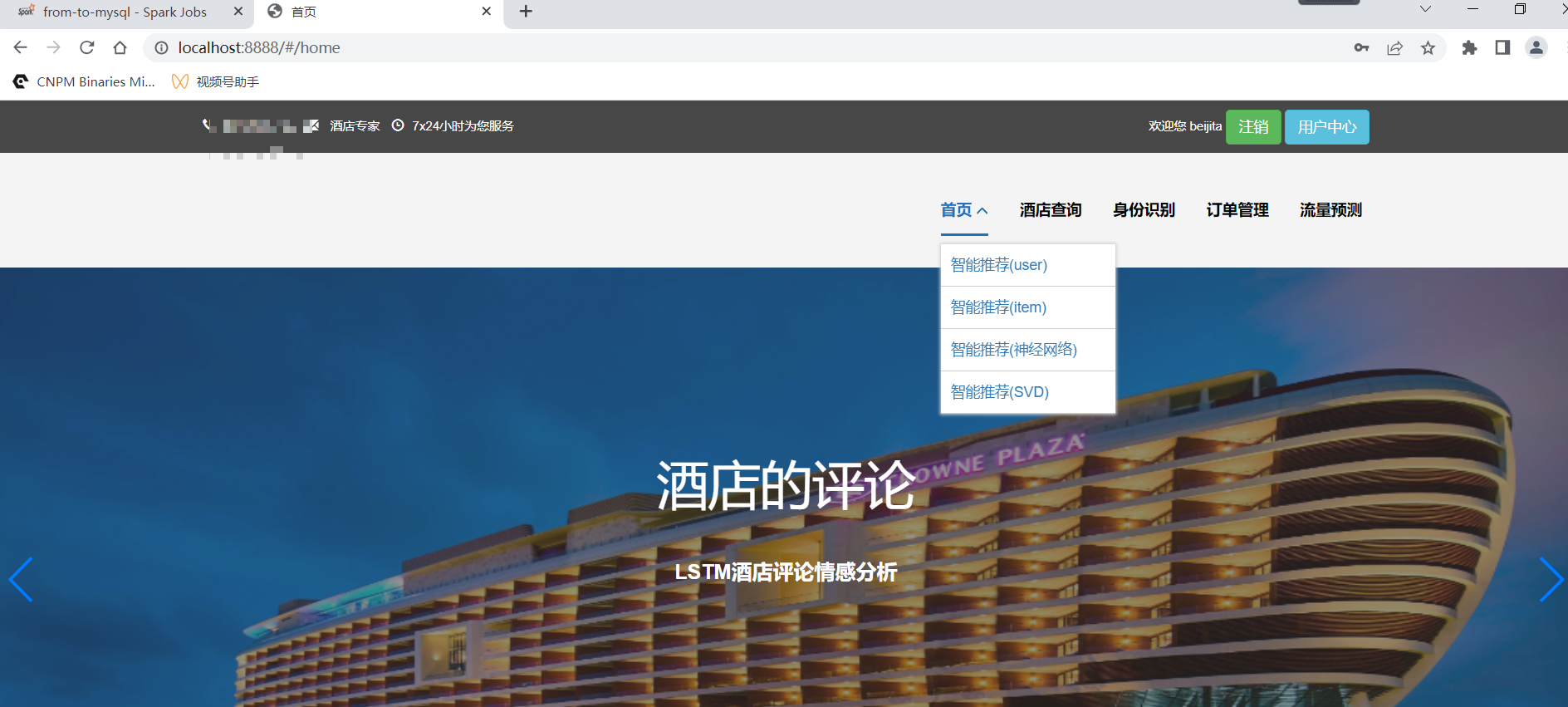
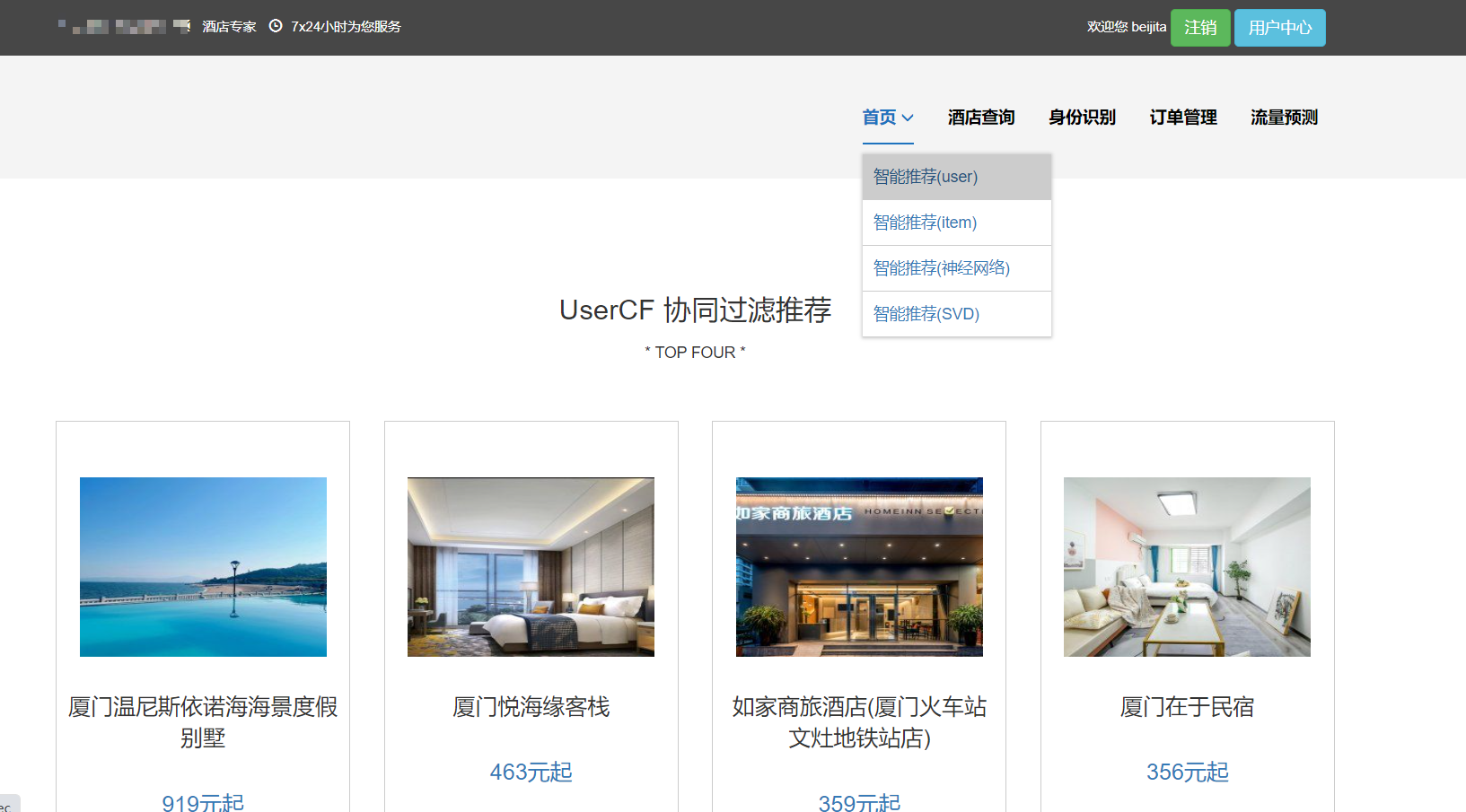



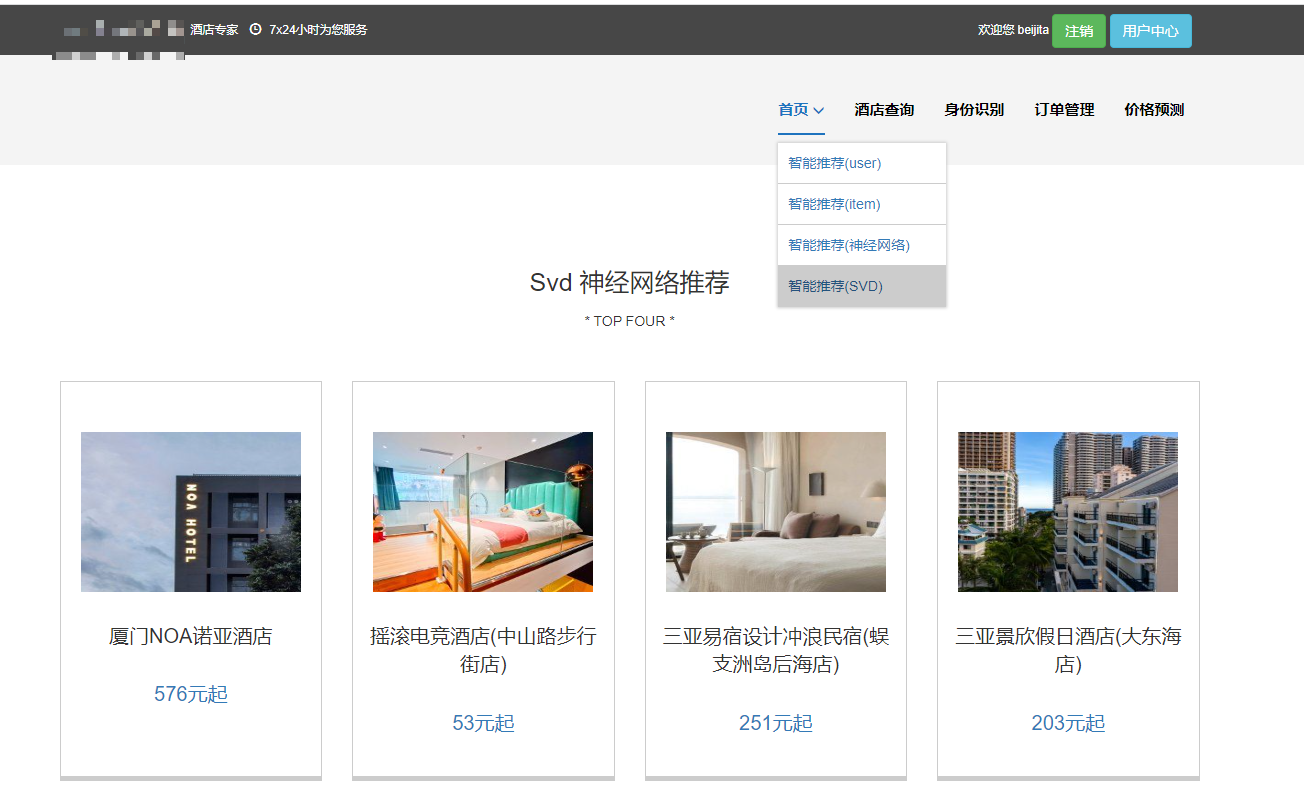
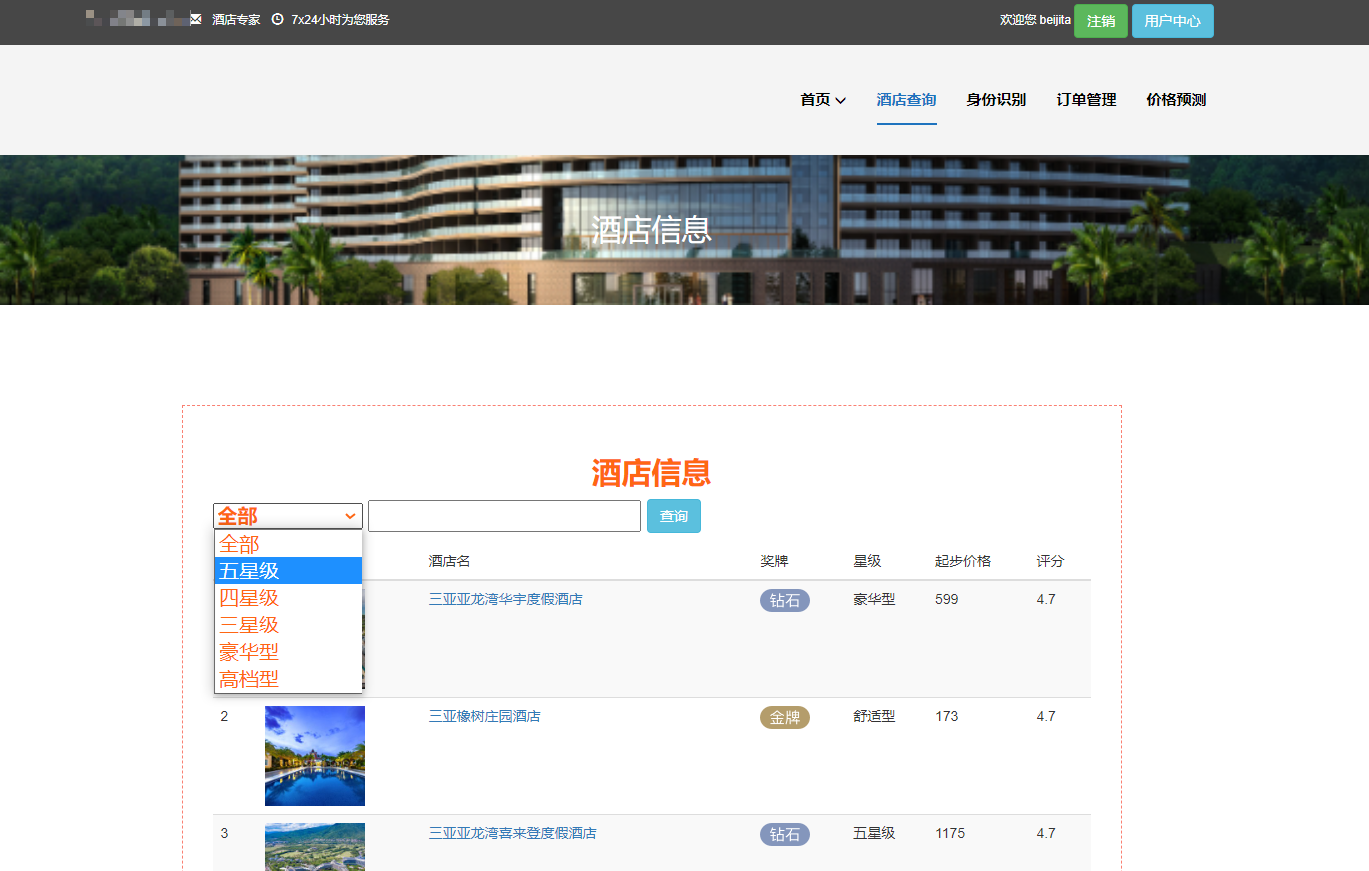

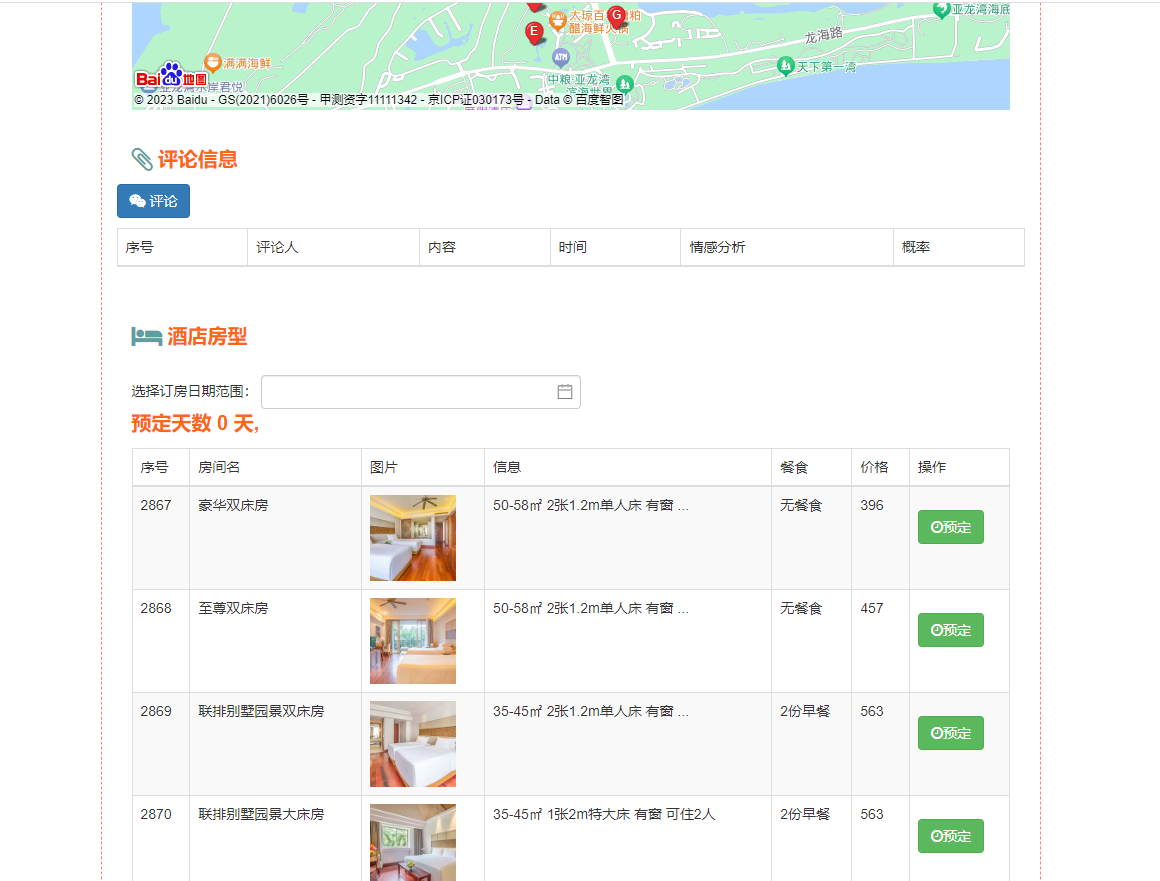

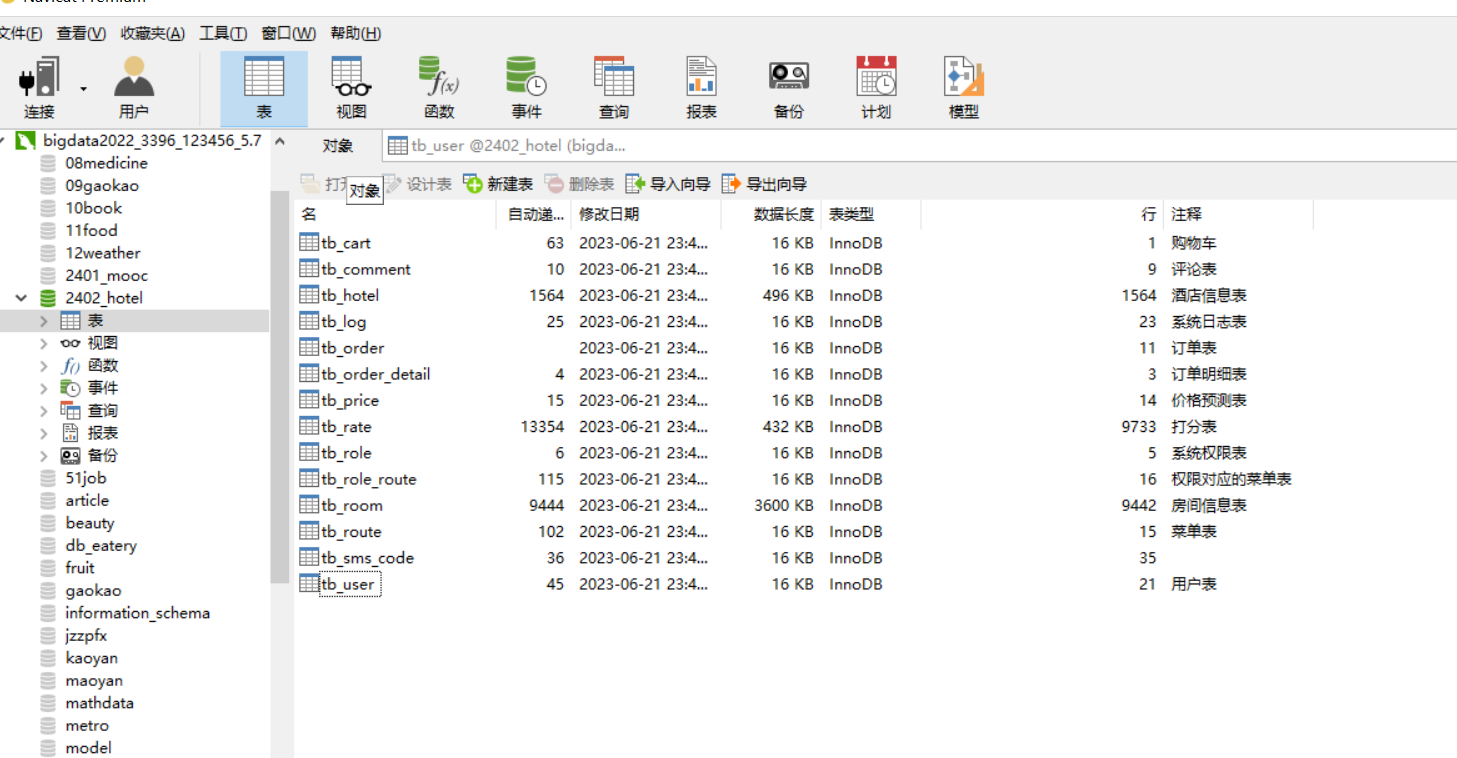





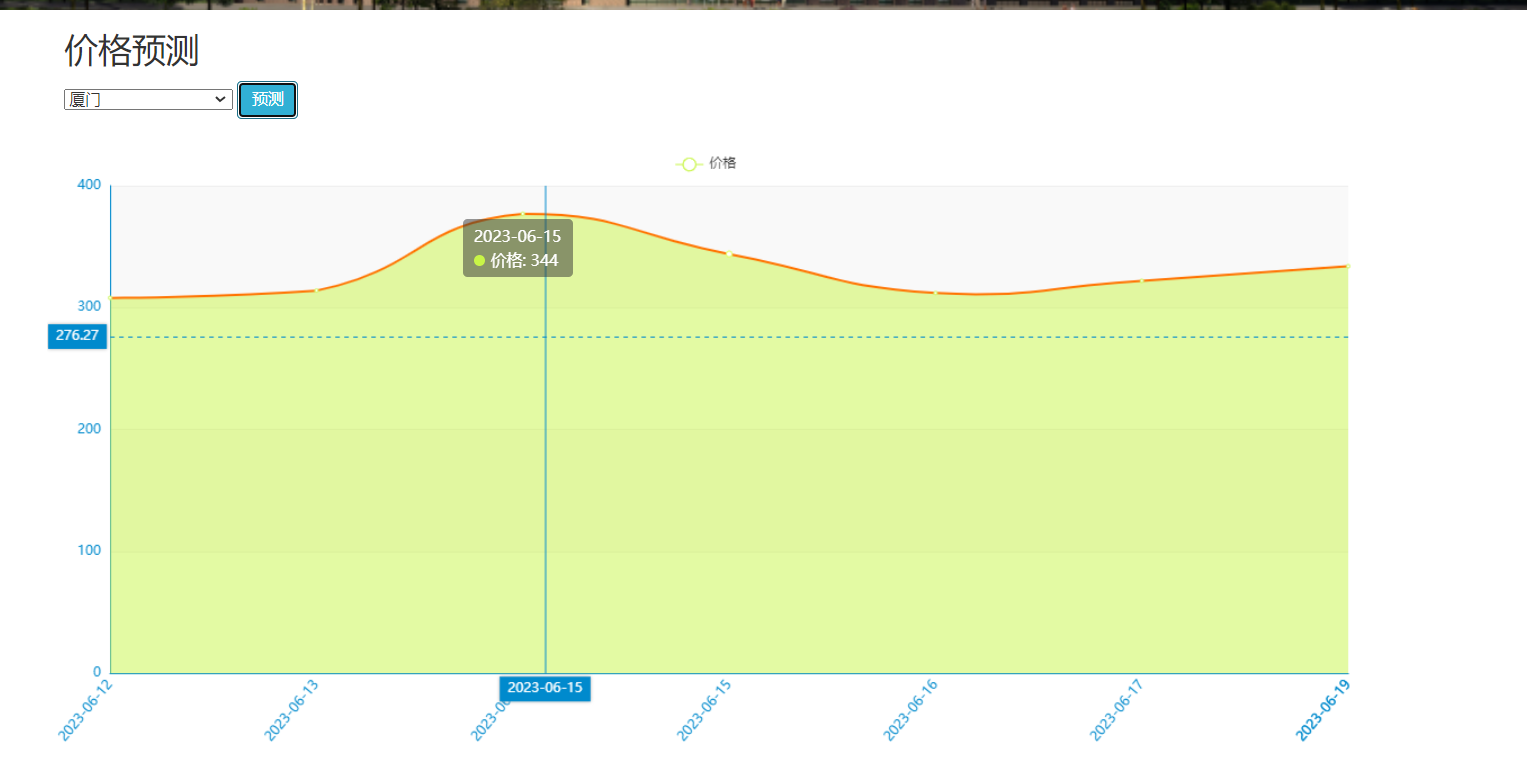






核心算法代码分享如下:
python
from flask import Flask, request
import json
from flask_mysqldb import MySQL
import io, sys
# 创建应用对象
app = Flask(__name__)
app.config['MYSQL_HOST'] = 'bigdata'
app.config['MYSQL_USER'] = 'root'
app.config['MYSQL_PASSWORD'] = '123456'
app.config['MYSQL_DB'] = 'hive_hotel'
mysql = MySQL(app) # this is the instantiation
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
@app.route("/getmapcountryshowdata")
def getmapcountryshowdata():
filepath = r"D:\\hadoop_spark_hive_mooc2024\\server\\data\\maps\\china.json"
with open(filepath, "r", encoding='utf-8') as f:
data = json.load(f)
return json.dumps(data, ensure_ascii=False)
@app.route('/tables01')
def tables01():
cur = mysql.connection.cursor()
cur.execute("SELECT replace(replace(REPLACE(gaode_province,'自治区',''),'省',''),'市','') gaode_province,num FROM tables01")
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables05')
def tables05():
cur = mysql.connection.cursor()
cur.execute('''select * FROM tables05 ''')
#cur.execute('''SELECT * FROM tables05 ''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables06')
def tables06():
cur = mysql.connection.cursor()
cur.execute('''select * from tables06''')
#cur.execute('''SELECT * FROM tables05 ''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables03')
def tables03():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM tables03 ''')
row_headers = ['breakfast', 'num']
#row_headers = [x[0] for x in cur.description] # this will extract row headers
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables02')
def tables02():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM tables02''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['xinji', 'num']
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables04')
def tables04():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM tables04 order by comment desc,score desc limit 4''')
#row_headers = [x[1] for x in cur.description] # this will extract row headers
row_headers = ['title', 'comment','score']
rv = cur.fetchall()
json_data = []
print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
if __name__ == "__main__":
#app.run(debug=True)
app.run(host="0.0.0.0", port=8080, debug=False)