本文深入探讨了scaPy库在文本分析和数据可视化方面的应用。首先,我们通过简单的文本处理任务,如分词和分句,来展示scaPy的基本功能。接着,我们利用scaPy的命名实体识别和词性标注功能,分析了Jane Austen的经典小说《傲慢与偏见》,识别出文中的主要人物和地点。最后,我们将这些文本分析技术应用于全球恐怖活动的数据集中,揭示了不同恐怖组织在全球各地的活动分布。文章展示了如何用scaPy进行复杂的文本挖掘和数据分析,为研究和政策制定提供见解。
目录
[四、名字实体识别------以Jane Austen 的小说《傲慢与偏见》为例](#四、名字实体识别------以Jane Austen 的小说《傲慢与偏见》为例)
Spacy是一个先进的自然语言处理(NLP)库,设计用于帮助开发者构建处理大量文本数据的应用程序。Spacy的主要优势在于其优秀的性能和可扩展性,使其能够支持快速的文本处理任务,如分词、词性标注、命名实体识别和依赖关系解析等。此外,Spacy还提供了预训练的统计模型和Word Embeddings,这使得它在学术和工业界NLP项目中是一个非常受欢迎的选择。由于这些功能,Spacy在处理多语言文本数据时显得尤为出色,被广泛应用于各种NLP和机器学习项目中。
一、文本处理-分词和分句
# 导入工具包和英文模型
import spacy
nlp = spacy.load("en_core_web_sm")#读进英文模型
doc = nlp('Weather is good, very windy and sunny. We have no classes in the afternoon.')
# 分词
for token in doc:
print (token)
#分句
for sent in doc.sents:
print (sent)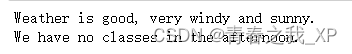
二、词性标注
for token in doc:
print ('{}-{}'.format(token,token.pos_))
三、命名体识别
首先,它将文本 "I went to Paris where I met my old friend Jack from uni." 传递给 nlp() 函数,该函数将文本处理成一个文档对象。然后,通过遍历文档对象的实体(ent),打印出每个实体及其对应的标签(label)。
import spacy
nlp = spacy.load("en_core_web_sm")#读进英文模型
doc_2 = nlp("I went to Paris where I met my old friend Jack from uni.")
for ent in doc_2.ents:
print ('{}-{}'.format(ent,ent.label_))#label就是指它是什么类型的
from spacy import displacy
doc = nlp('I went to Paris where I met my old friend Jack from uni.')
displacy.render(doc,style='ent',jupyter=True)
四、名字实体识别------ 以 Jane Austen 的小说《傲慢与偏见》 为例
本小节通过使用 spaCy 库进行自然语言处理 (NLP) 来分析 Jane Austen 的小说《傲慢与偏见》中出现的人物名称,以及每个人物名称出现的频次。首先,定义了一个名为 read_file 的函数,用于读取文本文件的内容。该函数通过 open 函数打开文件,并调用 read 函数来读取文件的内容。接下来,加载了 spaCy 的英文语言模型 nlp,并将小说文本 text 传递给 nlp 函数进行实例化。然后,使用列表推导式,遍历processed_text.sents,将每个句子存储在sentences列表中。接下来,定义了一个名为 find_person 的函数,用于查找文本中出现的人物名称及其频次。该函数首先创建了一个空的 Counter 对象 c,然后遍历文本中所有的实体 (ent),如果实体的标签是 PERSON,则将其 lemma(词干形式)加入到 Counter 对象 c 中,并增加计数器的值。最后,调用 find_person 函数,将整个文本传递给该函数,并打印出人物名称及其出现的频次。输出结果将是一个列表,列表中包含了出现频次最多的 10 个人物名称及其出现的频次。
def read_file(file_name):
with open(file_name, 'r') as file:
return file.read()
# 加载文本数据
text = read_file('./data/pride_and_prejudice.txt')#《傲慢与偏见》这篇小说
processed_text = nlp(text)#将text实例化一下
sentences = [s for s in processed_text.sents]
print (len(sentences))
# sentences[:5]
from collections import Counter,defaultdict
def find_person(doc):
c = Counter()
for ent in processed_text.ents:
if ent.label_ == 'PERSON':
c[ent.lemma_]+=1
return c.most_common(10)
print (find_person(processed_text))
五、恐怖袭击分析(实例)
本小节主要目的是分析一组关于恐怖主义的文章,并统计常见恐怖组织与特定地点之间的关联频率。在处理了名为data/rand-terrorism-dataset.txt的文本文件后,代码首先使用spacy的英文模型将文本转换为小写并识别其中的实体。实体包括人名(PERSON)、组织名(ORG)和地点(GPE)。接着,定义了两个列表:common_terrorist_groups包含了一些常见的恐怖组织名称,而common_locations则包含了一些常见的地点名称。在处理每行文本时,代码会找出文章中提到的恐怖组织和地点,并将它们与预定义的常见恐怖组织和地点列表进行匹配。如果文章中的某个实体同时出现在这两个列表中,那么这个实体和地点的组合就会被记录下来,并在location_entity_dict字典中进行计数。最后,使用pandas库,将location_entity_dict转换为一个DataFrame对象,名为location_entity_df。这个数据框的每一行代表一个恐怖组织,每一列代表一个地点,而单元格中的值表示该恐怖组织与该地点共同出现的次数。
# 导入工具包和英文模型
import spacy
nlp = spacy.load("en_core_web_sm")#读进英文模型
def read_file_to_list(file_name):
with open(file_name, 'r') as file:
return file.readlines()
terrorism_articles = read_file_to_list('data/rand-terrorism-dataset.txt')
#read_file_to_list函数将文本文件按行分割成了一个列表
terrorism_articles_nlp = [nlp(art.lower()) for art in terrorism_articles]
common_terrorist_groups = [
'taliban',
'al-qaeda',
'hamas',
'fatah',
'plo',
'bilad al-rafidayn'
]
common_locations = [
'iraq',
'baghdad',
'kirkuk',
'mosul',
'afghanistan',
'kabul',
'basra',
'palestine',
'gaza',
'israel',
'istanbul',
'beirut',
'pakistan'
]
location_entity_dict = defaultdict(Counter)
for article in terrorism_articles_nlp:
article_terrorist_groups = [ent.lemma_ for ent in article.ents if ent.label_=='PERSON' or ent.label_ =='ORG']#人或者组织
article_locations = [ent.lemma_ for ent in article.ents if ent.label_=='GPE']
terrorist_common = [ent for ent in article_terrorist_groups if ent in common_terrorist_groups]
locations_common = [ent for ent in article_locations if ent in common_locations]
for found_entity in terrorist_common:
for found_location in locations_common:
location_entity_dict[found_entity][found_location] += 1
import pandas as pd
location_entity_df = pd.DataFrame.from_dict(dict(location_entity_dict),dtype=int)
location_entity_df = location_entity_df.fillna(value = 0).astype(int)
location_entity_df 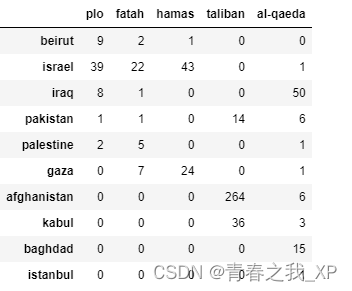

import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12, 10))
hmap = sns.heatmap(location_entity_df, annot=True, fmt='d', cmap='YlGnBu', cbar=False,square=False,annot_kws={"fontsize": 18})
# 添加信息
plt.title('Global Incidents by Terrorist group',fontsize=20)
plt.xticks(rotation=30,fontsize=15)
plt.yticks(rotation=30,fontsize=15)
plt.show()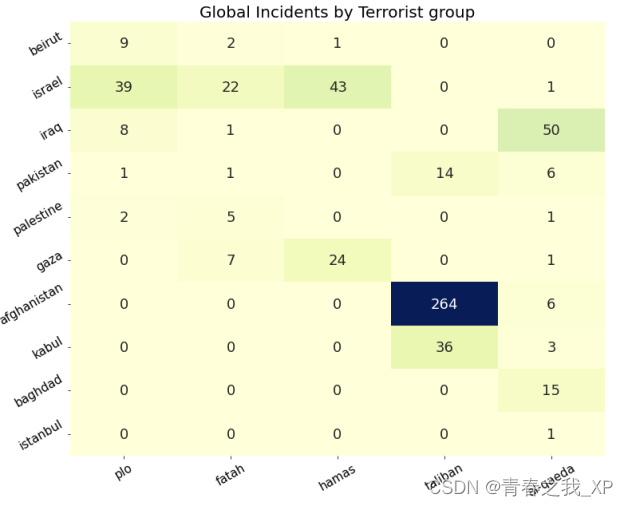
从上图,可以看出,塔利班(Taliban)在阿富汗(afghanistan)地区进行的恐怖袭击次数最多,为264次。