
AbutionGraph是一款端到端的流式数据实时分析的图谱数据库,实时(流式写入实时、高QPS决策分析实时、流式预处理实时)表现在:
- 构建实时查询QPS响应时长与历史数据量无关的图模型;
- 接入流式数据并实时更新图计算指标;
- 实时查询历史和时序窗口聚合的数据。
AbutionGraph具有多种数据库的特性,除传统图谱数据存储模型外,Abution的目标是以足够低的延迟(亚秒级)来服务大规模图谱数据(达BP级)的实时决策分析。 AbutionGraph特别适用于业务指标系统建设、实时交互式数据分析、可视化大屏展现、IOT流式数据监测、拓扑数据动态行为计算、相同点边id的数据根据标签分类管理等等。 AbutionGraph使用Java/C++开发,支持Aremlin、Gremlin、GraphQL查询语法,并支持与Java进行混合编程开发和Python API。
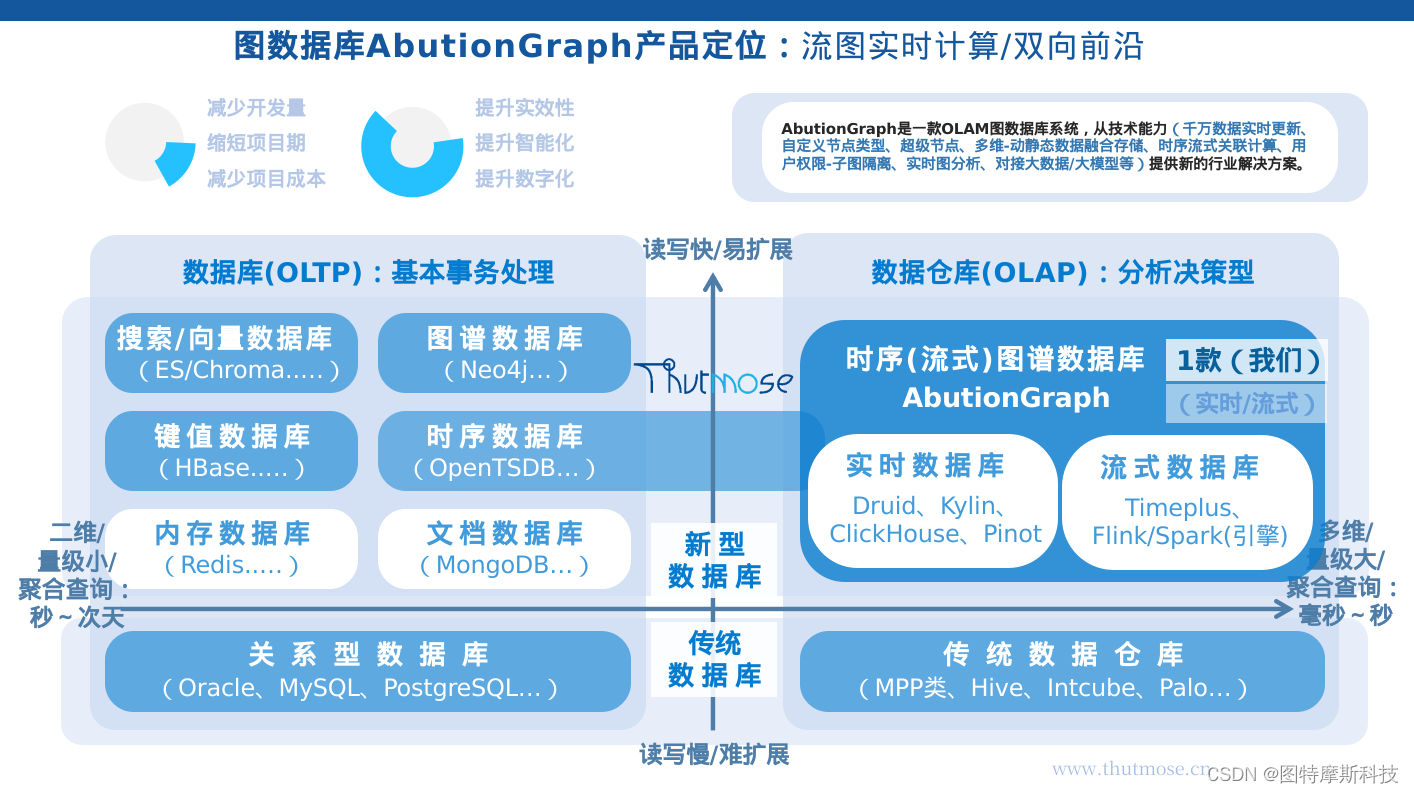
AbutionGraph特性:
分布式企业级图数据库,提供图数据的实时-存储、查询和OLAP分析能力,主要面向对局部数据 的海量并发查询和全量数据 的实时在线计算/更新/监控。
用于大数据量高吞吐率和低延迟的同时,实时反馈数据态势变化(异常)情况,保障决策分析业务7*24小时在线运行。
| 支持功能 | AbutionGraph | Neo4j | TigerGraph |
|---|---|---|---|
| 分布式 | √ | X | √ |
| RDF图模型 | √ | X | X |
| 属性图模型 | √ | √ | √ |
| 实时增删查改 | √ | √ | √ |
| TB级大容量 | √ | √ | √ |
| 高性能批量导入 | √ | √ | √ |
| 点边检索、全文检索 | √ | √ | √ |
| 千万顶点/秒的高吞吐率 | √ | √ | √ |
| 对接流式数据源、关系型数据源 | √ | √ | √ |
| 图分析算法 | √ | √ | √ |
| 高可用性支持 | √ | √ | √ |
| 图谱可视化工具 | √ | √ | √ |
| 读写任务内高效并行存储) | √ | √ | √ |
| 在线/离线、全量/增量的备份恢复 | √ | √ | √ |
| 多图(大图与多个子图) | √ | √ | √ |
| 丰富的离线图算法 | √ | √ | √ |
| - | - | - | |
| 单独删除点边(支持独立点/边存储) | √ | X | X |
| 动态新增/隐藏字段 | √ | X | X |
| 时间窗口计算(流式数据库的标志特性) | √ | X | X |
| 实时大数据流式图 存储/计算/更新 | √ | X | X |
| 多重/多维图关系(每对点间都允许多种不同标签的边共存) | √ | X | X |
| 多重/多维图实体(每个点上都允许多种不同标签的点共存) | √ | X | X |
| 动图-时序关系聚合(根据年月日等时间窗口-自动合并边属性) | √ | X | X |
| 动图-时序实体聚合(根据年月日等时间窗口-自动合并点属性) | √ | X | X |
| 导出图数据到大数据平台继续计算(Spark/Flink/Hadoop等。 对接AI算法作为特征工程库,实时更新模型指标,实时取用) | √ | X | X |
| 子图隔离(原子级用户权限管理) | √ | X | X |
| 分布式图实例 | √ | X | X |
| 节点模糊查询 | √ | X | X |
| 自定义节点类型 | √ | X | X |
| 图数据库专家支持服务 | √ | X | X |
AbutionGraph适用:
- 交互式数据分析
希望快速从大规模历史数据中得出统计分析报告用于决策,数据探索-秒内响应、年月日时间窗口分析-秒内响应等。 - 流式数据监控
希望从实时源源不断产生数据的iot/应用程序中立即反映趋势,态势感知、实时聚合计算、时序指标变化规律等。 - 多维数据管理
希望将同一个id-人身份证等,绑定上工商/税务/车房产/银行/通话等不同结构的数据,并通过设定标签识别类别数据,实现高效管理与查询。 - 图谱关联计算
希望导入的实体与关系自动实现关联,而不是明确"点表/边表"必须一一具备,允许孤立点。此外,希望自动汇总一跳邻居节点信息如:出度入度、基数统计、百分位数等,实现复杂关联指标的即席查询。 - 子图隔离
希望在一个图谱中实现不同用户导入的数据仅自己可见,或授权可见,很适用于公安、政府、跨部门、多用户协作等场景。
及一切希望在亚秒实现关联数据分析的场景 - 执行查询即所得、数据写入即见变化,类似于Kafka、Flink、Kylin等系统,不过Abuion旨在关联计算上弥补缺陷,所以它更擅长处理关联分析问题,且比传统图数据库更节省计算资源和响应时间。 视频介绍

Abution GraphInstance
GraphInstance是连接到一个AbutionGraph的操作,是执行查询语句的入口。相当于传统数据库连接,您可以使用g.*.exec(user)去执行一系列的图查询。
- 图实例有3种使用方式:
- Graph - 本地图实例连接,用于生产环境,只能在装有Abution的节点运行,可运行所有功能;
- TmpGraph - 临时图实例连接,用于代码测试,无需部署Abution,数据即存即删,是一个临时内存图,算法功能不可用;
- MemoryGraph- 分布式缓存图实例连接,该阶段还是实验性的,未经大规模项目验证;
- RemoteGraph - 远程图实例连接,用于远程代码调试,IDEA中提交代码至服务器运行,UDF能力请使用Graph实例运行。
1)Graph实例
Graph graph = G.Graph("graphId")
.schema(schema)
.build();
g.addOrUpdate(); //保存元数据
Graph graph = G.GetGraph("graphId"); //从已有图谱中快速初始化图实例注意:
graphId、schema是必须提交的参数。
addOrUpdate为更新和保存元数据。
2)TmpGraph实例
TmpGraph实例采用java缓存保存数据,并不会持久化数据,当程序运行结束,数据将在内存中被清空,占用内存也随之释放。此实例本意是方便开发调试,并不适用于大规模数据。
Graph graph = G.TmpGraph(schema);Ps:临时初始化实例无需数据库配置参数,只需schema定义,不走数据库,只使用缓存,程序停止数据即清空。因为是临时图存储,复杂的生产场景一般不用,所以一些算法功能没有单独开发出来。
3)MemoryGraph实例
MemoryGraph实例采用分布式缓存作为数据持久化层,开启集群后将使用联邦集群的可用内存作为图数据存储,您可以在集群本地运行测试程序,也可以通过ip端口远程验证您的逻辑代码。当您关闭AbutionGraph集群后,数据将在内存中被清空,占用内存也随之释放。
3个必填参数(图谱名称、Schema、远程服务器端口)
Graph g = G.MemoryGraph("tgMemory1", schema, "127.0.0.1:5701");
// 保存元数据,以便可视化实时可见
g.addOrUpdate();4)远程/跨集群连接图实例
此功能允许在任何网络连通的机器使用AbutionGDB中的数据,无需在开发者本地部署AbutionGraph,前提是已开启AbutionGRS数据中台服务,你可以直接在IDEA中编写代码,读取本地数据,使用远程服务器运行你的代码,返回的结果数据就像是本地的Java对象一样。
Graph graph = G.GraphProxy.Builder()
//.graphId("testGraph") //可选参数,不填写则做多图知识融合查询
.host("thutmose-aliyun") //改成数据库服务器ip
.port(9090)
.contextRoot("rest")
.build();GraphProxy在数据整合、数据迁移和项目开发调试阶段非常有用,如在IDEA中即可连接到云端服务并调试,它使大数据工程师的本地代码得以在云端运行,我们在未来的版本中会不断升级它,使图数据库更具有云服务的特性。 注意:此功能为定制化业务平台专用,为方便代码调试,算法功能不可用。