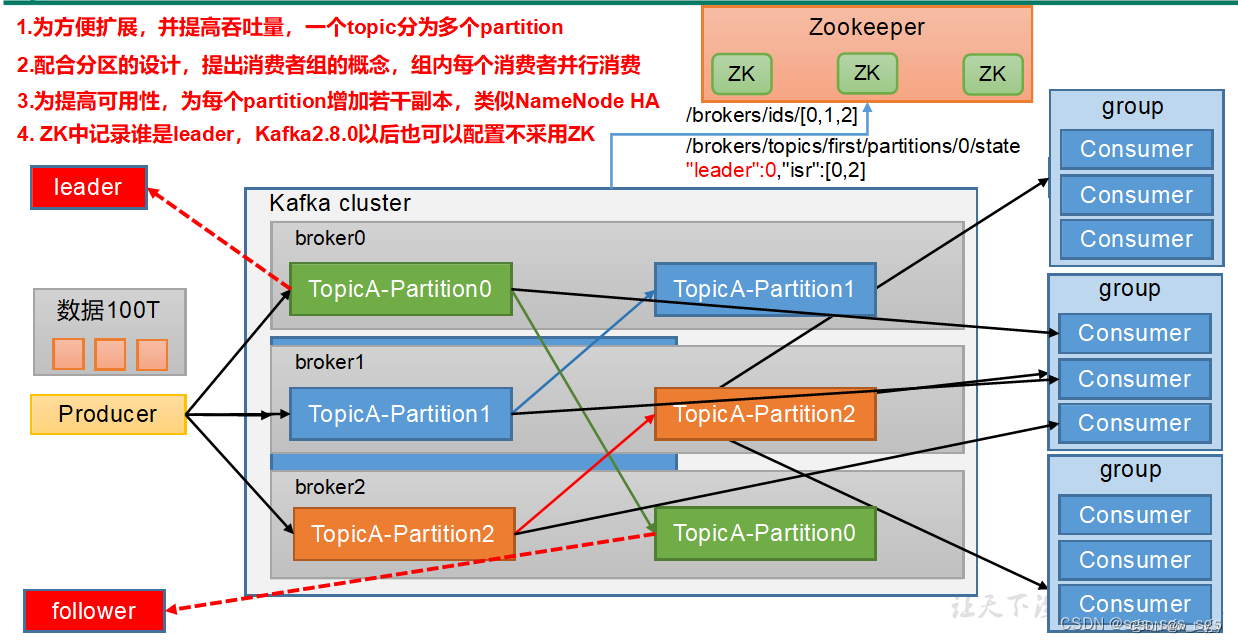
一、broker
1、介绍
kafka服务器的官方名字,一个集群由多个broker组成,一个broker可以容纳多个topic。
2、工作流程
3、重要参数
|-----------------------------------------|----------------------------------------------------------------------|
| 参数名称 | 描述 |
| replica.lag.time.max.ms | ISR中,如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值,默认30s。 |
| auto.leader.rebalance.enable | 默认是true。 自动Leader Partition 平衡。 |
| leader.imbalance.per.broker.percentage | 默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值300秒。检查leader负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka中log日志是分成一块块存储的,此配置是指log日志划分 成块的大小,默认值1G。 |
| log.index.interval.bytes | 默认4kb,kafka里面每当写入了4kb大小的日志(.log),然后就往index文件里面记录一个索引。 |
| log.retention.hours | Kafka中数据保存的时间,默认7天。 |
| log.retention.minutes | Kafka中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | Kafka中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是5分钟。 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的segment。 |
| log.cleanup.policy | 默认是delete,表示所有数据启用删除策略; 如果设置值为compact,表示所有数据启用压缩策略。 |
| num.io.threads | 默认是8。负责写磁盘的线程数。整个参数值要占总核数的50%。 |
| num.replica.fetchers | 副本拉取线程数,这个参数占总核数的50%的1/3 |
| num.network.threads | 默认是3。数据传输线程数,这个参数占总核数的50%的2/3 。 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是long的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是null。一般不建议修改,交给系统自己管理。 |
4、文件存储
3.1、文件存储机制
3.2、文件清洗策略
二、生产者
可以是flume、MySQL、java等,其实就是向kafka发送数据的。
1、发送原理
在消息发送的过程中,涉及到了两个线程------main线程和Sender线程。在main线程中创建了一个双端队列RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka Broker。
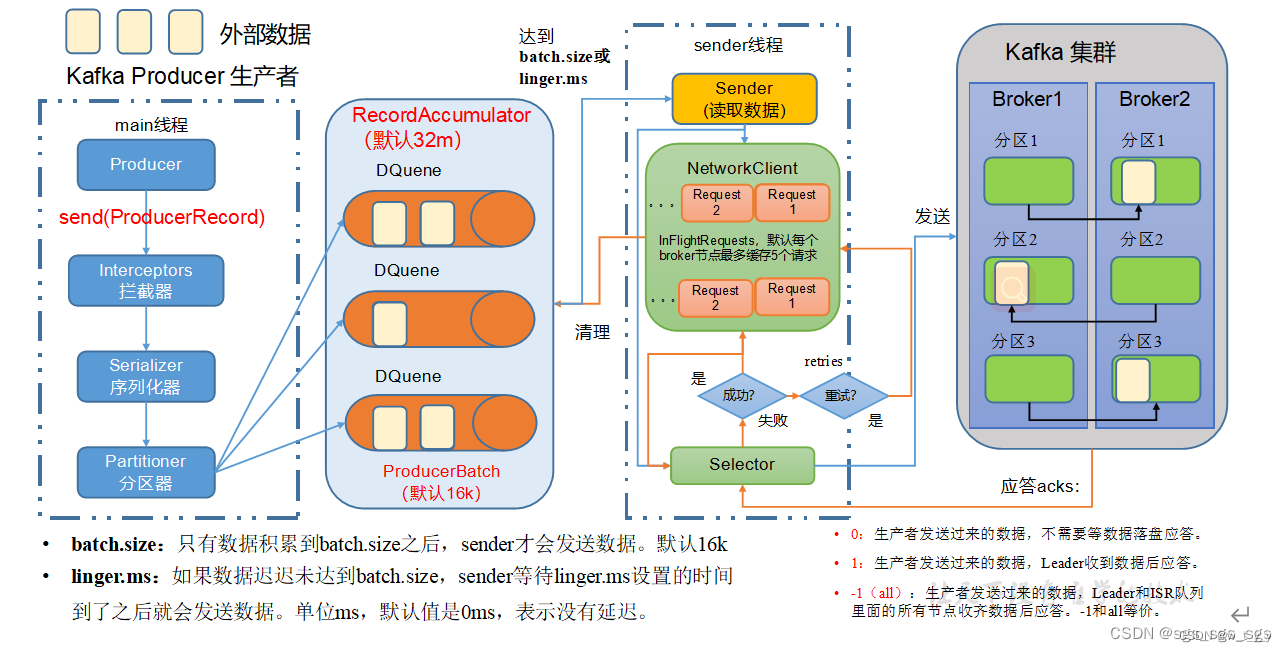
从图中的流程可以看出,生产者和kafka集群之间还有一个RecordAccumulator队列默认大小是32M,topic分区的话,producer会对应有一个分区器,数据在进入中间队列前,已经被分区器进行了分区,sender()方法在发送数据时,就直接根据分区进行拉取了,拉取时有两个参数,也就是调优参数。
(1)batch.size :也就是批大小,只有数据累计到batch.size后,sender才会发送数据,默认16k (2)linger.ms :也就是等待时间,如果数据未达到batch.size,sender等待linger.ms设置的时间就会发送数据,单位ms,默认值就是0ms,就是有了一条数据直接发(默认为0是因为kafka要接实时数仓,所以设置为0)。
2、生产者重要参数列表
|---------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------|
| 参数名称 | 描述 |
| bootstrap.servers | 生产者连接集群所需的broker地址清单。例如hadoop102:9092,hadoop103:9092,hadoop104:9092,可以设置1个或者多个,中间用逗号隔开。注意这里并非需要所有的broker地址,因为生产者从给定的broker里查找到其他broker信息。 |
| key.serializer和value.serializer | 指定发送消息的key和value的序列化类型。一定要写全类名。 |
| buffer.memory | RecordAccumulator缓冲区总大小,默认32m。 |
| batch.size | 缓冲区一批数据最大值,默认16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。生产环境建议该值大小为5-100ms之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和isr队列里面的所有节点收齐数据后应答。默认值是-1,-1和all是等价的。 |
| max.in.flight.requests.per.connection | 允许最多没有返回ack的次数,默认为5,开启幂等性要保证该值是 1-5的数字。 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retries表示重试次数。默认是int最大值,2147483647。 如果设置了重试,还想保证消息的有序性,需要设置 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则在重试此失败消息的时候,其他的消息可能发送成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是100ms。 |
| enable.idempotence | 是否开启幂等性,默认true,开启幂等性。 compression.type 生产者发送的所有数据的压缩方式。默认是none,也就是不压缩。 支持压缩类型:none、gzip、snappy、lz4和zstd。 |
3、提高吞吐量
提高吞吐量,就是提高批次传输大小,还有就是效率问题
//调优参数,还是需要根据业务需求来调整
//batch.size 批次大小,默认是16k,将批次大小增大,进而提高吞吐量
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,32768);
//linger.ms 等待时长,默认是0ms,增加等待时长
properties.put(ProducerConfig.LINGER_MS_CONFIG, 5);
//双端队列大小,默认是32M,可以提高到64M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,67108864);
//调整压缩格式,默认没有压缩
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");4、数据可靠性
数据可靠性基于ack应答机制。为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后都需要向producer发送ack(acknowledgement 确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
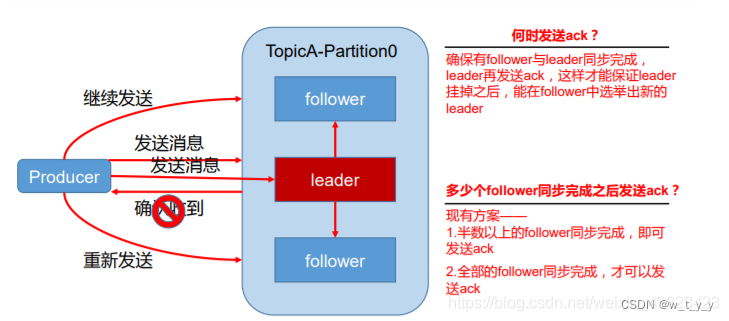
数据完全可靠的条件:**Acks级别设置为-1,分区副本大于等于2,ISR应答的最小副本数大于等于2。**具体来看下:
4.1、副本数据同步策略
|-----------------|--------------------------------|--------------------------------|
| 方案 | 优点 | 缺点 |
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点故障,需要2n+1个副本 |
| 全部完成同步,才发送ack | 选举新的leader时,容忍n台节点故障,需要n+1 个副本 | 延迟高 |
Kafka选择了第二种方案,原因如下:
(1)同样为了容忍 n 台节点的故障,第一种方案需要 2n+1 个副本,而第二种方案只需要 n+1 个副本,而 Kafka 的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
(2)虽然第二种方案的网络延迟会比较高,但网络延迟对 Kafka 的影响较小。
4.2、ISR
采用第二种方案之后,设想以下情景:leader 收到数据,所有 follower 都开始同步数据, 但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去, 直到它完成同步,才能发送 ack。这个问题怎么解决呢?
Leader 维护了一个动态的 in-sync replica set (ISR),意为和 leader 保持同步的 follower 集 合。当 ISR 中的 follower 完成数据的同步之后,leader 就会给 follower 发送 ack。如果 follower 长时间 未 向 leader 同 步 数 据 , 则 该 follower 将 被 踢 出 ISR , 该 时 间 阈 值 由replica.lag.time.max.ms 参数设定。Leader 发生故障之后,就会从 ISR 中选举新的 leader。
4.3、ack 应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失, 所以没必要等 ISR 中的 follower 全部接收成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡, 选择以下的配置。
(1) 0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还 没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
(2)producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower 同步成功之前 leader 故障,那么将会丢失数据;
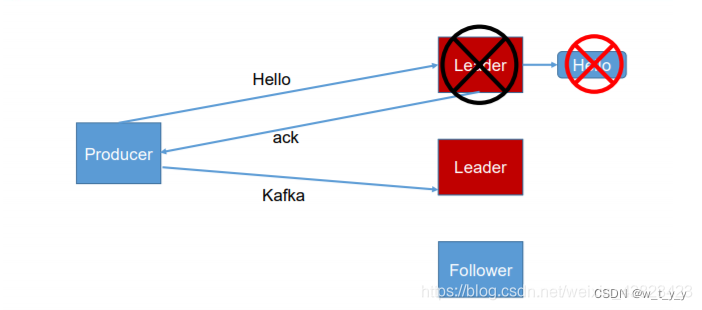
(3) -1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才 返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会 造成数据重复。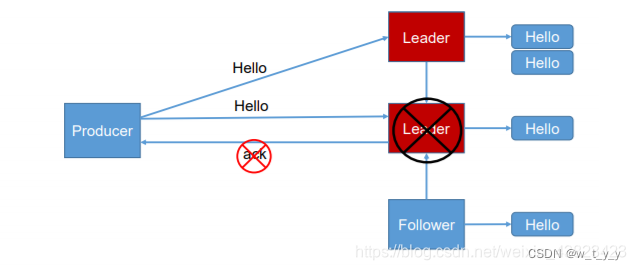
4.4、故障处理细节
Log文件中的HW和LEO。
LEO:指的是每个副本最大的 offset;
HW:指的是消费者能见到的最大的 offset,ISR 队列中最小的 LEO。
(1)follower 故障
follower 发生故障后会被临时踢出 ISR,待该 follower 恢复后,follower 会读取本地磁盘 记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。 等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重 新加入 ISR 了
(2)leader 故障
leader 发生故障之后,会从 ISR 中选出一个新的 leader,之后,为保证多个副本之间的数据一致性,其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader 同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
5、数据去重
**6、**数据有序
分区内有序,分区间无序
三、消费者组
由一个或者多个consumer组成,在kafka中,消费者都是有组的,即使是在consumer创建时没有没有设置组,但是kafka会默认一个有一个组,是组直接从kafka中的leader中拉取数据,消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
组内的所有消费者协调在一起来消费订阅主题的所有分区,但是同一个topic下的某个分区只能被消费者组中的一个消费者消费,不同消费者组中的消费者可以消费相同的分区。
在 Kafka 中,每个消费者都必须加入一个消费组(Consumer Group)才能进行消息的消费。消费组的作用在于协调多个消费者对消息的处理,以实现负载均衡和容错机制。
具体来说,spring.kafka.consumer.group-id 的作用包括以下几点:
消费者协调:Kafka 会根据 group-id 将不同的消费者分配到不同的消费组中,不同的消费组之间相互独立。消费组内的消费者协调工作由 Kafka 服务器自动完成,确保消息在消费组内得到均匀地分发。
负载均衡:当多个消费者加入同一个消费组时,Kafka 会自动对订阅的主题进行分区分配,以实现消费者之间的负载均衡。每个分区只会分配给消费组内的一个消费者进行处理,从而实现并行处理和提高整体的消息处理能力。
容错机制:在消费组内,如果某个消费者出现故障或者新的消费者加入,Kafka 会自动重新平衡分区的分配,确保各个分区的消息能够被有效地消费。
需要注意的是,同一个消费组内的消费者共享消费位移(offset),即每个分区的消息只会被消费组内的一个消费者处理。因此,同一个主题下的不同消费组是相互独立的,不会进行负载均衡和消费位移的共享。
四、消费者
(可能是MySQL、Hadoop、spark、flink、java),就是向kafka取数据的。
1、工作流程
2、重要参数
|-------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 参数名称 | 描述 |
| bootstrap.servers | 向Kafka集群建立初始连接用到的host/port列表。 |
| key.deserializer和value.deserializer | 指定接收消息的key和value的反序列化类型。一定要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为true, 则该值定义了消费者偏移量向Kafka提交的频率,默认5s。 |
| auto.offset.reset | 当Kafka中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | __consumer_offsets的分区数,默认是50个分区。 |
| heartbeat.interval.ms | Kafka消费者和coordinator之间的心跳时间,默认3s。 该条目的值必须小于 session.timeout.ms ,也不应该高于 session.timeout.ms 的1/3。 |
| session.timeout.ms | Kafka消费者和coordinator之间连接超时时间,默认45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是5分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认1个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数,默认是500条。 |