
------沙漠中的巨人
目录
前言:从进程到线程的演进必要性
在80年代之前,操作系统只有进程的概念,但随着操作系统的发展,只有进程所带来的局限性日益突出 :创建和销毁进程开销巨大、进程间通信复杂且低效(IPC)、进程间切换开销较大... 线程的引入正是为了在保持进程优势(进程独立性)的同时,解决进程在创建开销、切换成本、通信效率、内存共享等 方面的不足,并提高系统并发度,更加高效地利用CPU等系统资源。
想象一个Web服务器需要同时处理成千上万个客户端请求。如果为每个客户端创建一个新进程,内存和CPU开销将是巨大的。而使用线程,可以在同一个地址空间内创建多个执行流,大大提高了并发处理能力。
一、线程基础
1.Linux线程的本质:轻量级进程
让我们先看看常见教材中对线程的定义:
线程:是操作系统能够进行运算调度 的最小单位。它被包含在进程之中 ,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的执行流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
教材上有关操作系统专业名称的解释,都是经过高度抽象后放之任何操作系统都不会错的理论。上面的这段话虽然不错,当太过笼统。当今主流操作系统中的线程实现都有独家风格,如果想要真正理解线程的概念,笔者建议先从一款具体的操作系统中学习线程,再以此为基础扩展到其他操作系统。本文的主角正是一款具体操作系统线程的实现原理,Linux线程。
首先教材上对于线程的描述太笼统了,下面总结精简线程的概念并附上进程的概念以对照区分:
进程:进程是由内核中的数据结构,加上内存中的代码与数据构成的,它是承担操作系统分配资源的基本单位。
线程:是进程内部的一个执行分支,是操作系统调度的基本单位。
既然Linux中的进程 = task_struct + 代码和数据,那么Linux中的线程可能是什么呢?实际上Linux中的线程实现取了个巧,Linux内核设计者并没有单独为线程设计代码,而是复用了进程的内核代码------struct task_struct,也就是说Linux中的线程也用task_struct来描述管理线程,每一个线程都有自己的task_struct,所以从内核的角度看,每个线程与进程一般,都是一个独立的调度实体,可以独立地被调度到CPU上运行。这也是Linux线程被成为"轻量级进程"(Lightweight Process, LWP)的原因所在。
为什么Linux不为线程单独设计一套数据结构,而使用已有的内核数据结构?这正是Linux的精妙所在,通过与以前的进程使用同一套数据结构可以大幅减少内核中的代码量,同时复用以前的代码使得系统精简程度更高,运行更加高效可靠,也便于日常维护。
如下图中红框中的为进程所有,而橙色框中的则为线程。
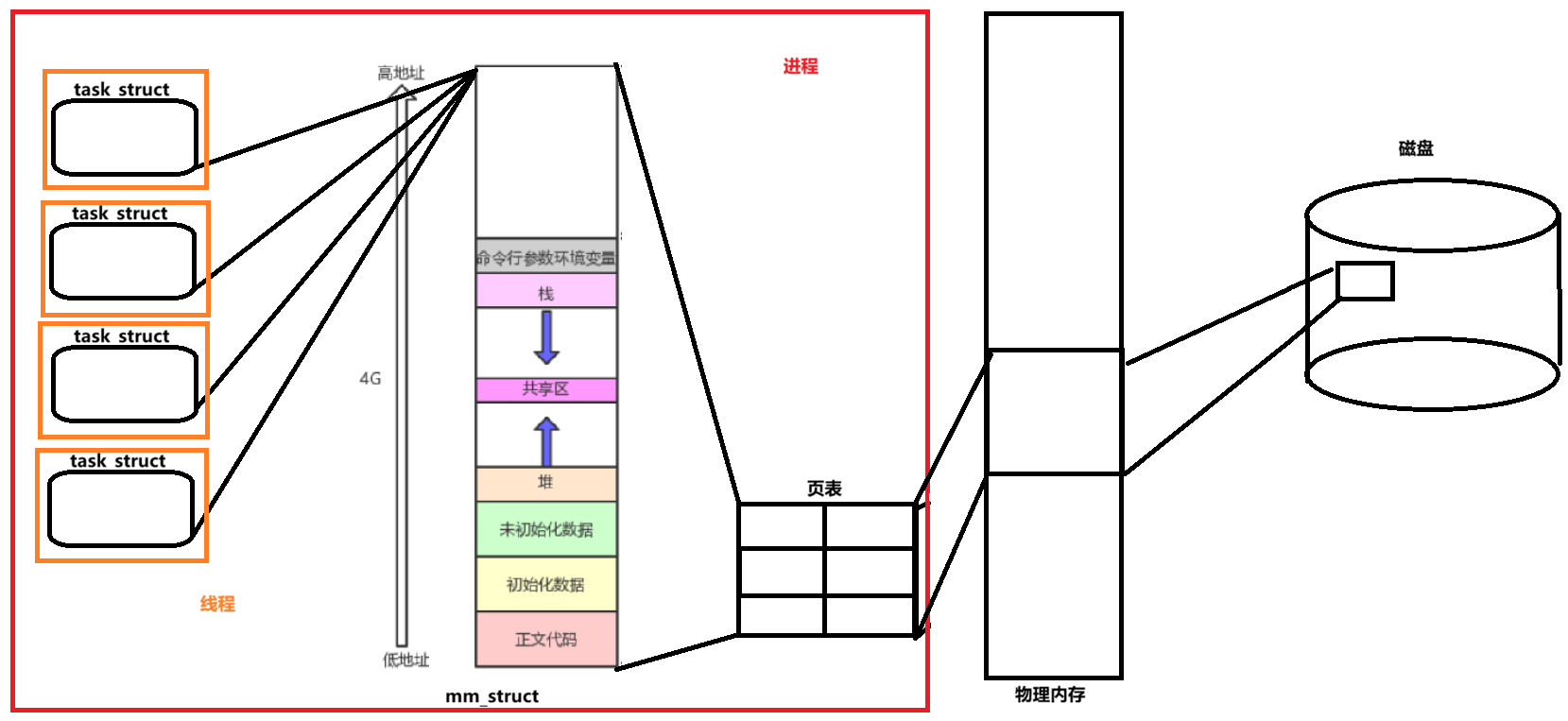
所以,以前我们编写的程序运行的进程应该叫单线程进程,也就是只有一个task_struct的进程。实际上,在现代Linux中,进程与线程的概念只在使用层面区分,Linux内核并不严格区分线程和进程 ,而是将它们都视为"任务"(task),每个任务都对应一个task_struct, 调度器调度时也不关心这是进程还是线程,调度器只关心task_struct。

2.理解线程
线程与进程地址空间
上面我们说到"线程是进程中的一个执行分支",我们应该如何理解线程呢?我们从它们拥有的资源入手分析。
首先,操作系统中同一时刻存在有许多进程,那内核是如何为这些进程划分资源的呢?我们需要从进程地址空间mm_struct入手。

当ELF类型的可执行程序从磁盘调入内存,内核为其创建内核数据结构task_struct(Linux中PCB)后,会使用ELF文中的程序头表program header table初始task_struct中mm_struct类型指向的mm_struct数据,也就是上图所示的进程地址空间。
也就是说一个进程拥有的资源,在其被创建时就已经通过进程地址空间体现出来了,该进程运行将会用到什么硬件,内存中代码数据使用了多少内存,换句话说:进程的地址空间决定了进程拥有的资源,各个进程的地址空间不同,决定了它们拥有的资源不同,进程地址空间就是进程的资源窗口。 现在就能明白为什么说进程是操作系统分配资源的基本单位了吧,因为操作系统将进程的资源都通过进程地址空间分配、描述、管理里了起来,进程访问的大部分资源,都是通过进程地址空间访问的。
那么线程呢?
我们已经知道了线程也是用内核数据结构task_struct来表示的,需要指出的是线程的task_struct与进程的task_struct有一些不同,主要体现在资源共享方面。比如,线程的task_struct会指向同一个内存地址空间(mm_struct),而进程则通常有独立的地址空间。 也就是说,进程中的所有线程都通过task_struct 指向同一个mm_struct 进程地址空间。
线程是一个进程中的一个执行流分支,上一次我们听到执行分支是什么时候?是的在语言层面我们也有说过执行分支,比如C语言中的 if - else 控制流,如果满足某个条件,就执行某个{ }代码块,否则执行另一个代码块{ }。相似的,线程也是如此,每个线程在进程地址空间中都有属于自己的代码块, 但与 if - else 不同的是**,线程是可以并发执行的**,也就是可以同时执行几个代码块,每一个线程的执行流程就被称为一个执行流,一个进程中可以存在多条执行流。
综上,**怎么理解线程呢?①进程中的线程指向同一个mm_struct 进程地址空间;②线程是一条执行流,每个线程都有自己的代码块,各个线程可并发执行。**当线程被创建时,pthread库会在进程地址空间的共享区为其分配线程栈,并将栈信息记录在线程的struct pthread中,线程要做的就是通过task_struct 找到mm_struct 执行自己的那部分代码数据,当CPU轮到自己时执行即可。
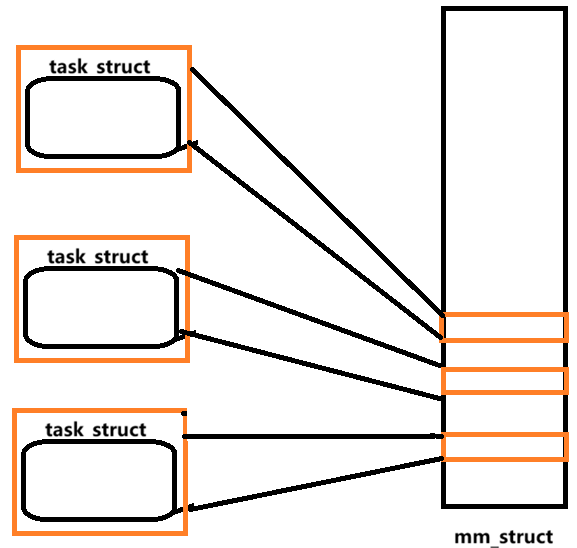
资源共享与线程独占资源
共享的资源
经过上面的讨论我们已经知道"进程中的线程指向的是同一片进程地址空间",所以各个线程除了有自己的执行代码外,进程中的资源各个线程其实是共享的, 包括之前博客提到过的:文件描述符表、信号处理方式signal_handler、进程标识信息(PID 相关)、进程级 IPC 资源(管道 共享内存 消息队列等)、环境变量(工作目录cwd等),以及进程地址空间中的各个分区中的其他资源,包括全局变量、函数代码等:

线程独占的资源
说完了线程间共享的资源,那么线程有没有独占的资源呢?是的,线程也有自己独属的资源,包括:线程ID、线程的上下文数据、线程栈、线程局部存储、erron错误码变量、调度优先级。
线程运行中创建的局部变量会存放在线程栈中。而所谓线程的上下文数据是指CPU调度时寄存器中的各种数据,它们会保存在task_struct 中随下次调度而恢复上次运行结束时的运行环境。
二、POSIX线程库
与PCB相对,线程也有自己的TCB。不对啊,不是说Linux中线程是"轻量级进程"吗,不是已经有了一个task_struct 吗,怎么还会有一个TCB呢?是的,Linux中的线程既有TCB又有task
_struct ,而且它们并不冲突反而彼此补充,或者说Linux的线程具有双TCB。
我们已经知道Linux中的线程是"轻量级进程"模拟充当的,本质是复用了之前的代码,虽然方便后续维护,但也带来了一个问题:**操作系统没有为线程提供相应的系统调用接口。**由于系统中只有"进程",所以有的也只有进程相关的系统调用,那我们该怎么创建线程呢?
Linux内核确实没有专门为"线程"设计独立的系统调用。线程的创建、管理都是通过同一套系统调用完成的,但这套系统调用被设计得非常灵活,这个系统调用就是 clone( )。
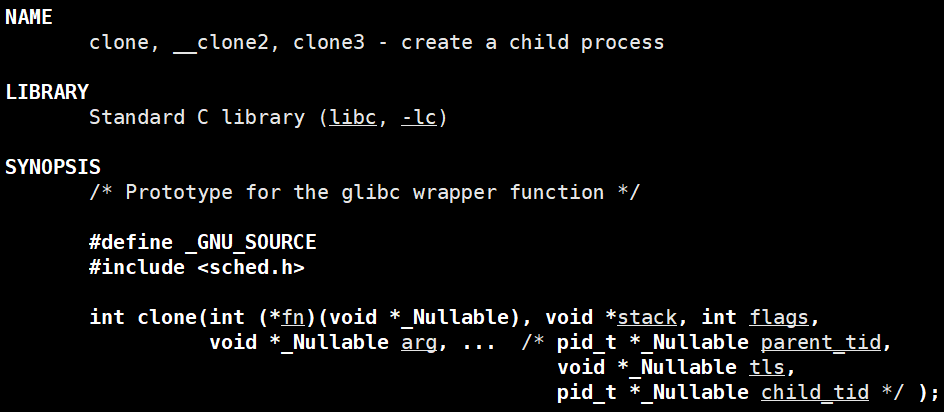
Linux通过一个通用的、可配置的系统调用clone( ) 来创建新的执行流task,也就是轻量级进程或者说线程。通过上图我们可以观察到clone( )的使用较为复杂,如果将这套创建线程的函数直接暴露给上层使用,未免不太友好,于是**POSIX线程库 即< pthread.h>**诞生了。
POSIX 线程库 中封装了clone( )等系统调用,使得在Linux中控制线程变得十分简单(相较于复杂的clone函数)。并且 POSIX 线程库 还提供了另一个有关线程非常重要的数据结构 struct pthread 。
"双TCB的分工"
在前文中我们提到"Linux中既有task_struct,又有TCB",这里的TCB指的就是struct pthread。让我们先看看TCB的定义:
TCB(Thread Control Block)是操作系统用于管理线程控制信息的数据结构,通常包含线程状态、上下文、栈指针等关键信息。
在Linux中,内核线程确实由task_struct表示,而POSIX线程库在用户态维护的struct pthrad则负责用户态的线程管理。什么意思呢?就是说:
task_strucrt:Linux线程的task_strucrt 负责的是有关线程的调度,包括保存硬件上下文,以及信号、资源等方面,负责对接操作系统起到内核态的线程管理;
struct pthrad:struct pthrad 负责存储管理线程的属性,包括线程状态、线程栈等、局部存储等,负责用户态的线程管理;
Linux通过task_struct 与 struct pthraed"双TCB",实现了对线程不同状态下的管理分离,如用户态操作获取线程ID等可以通过struct pthraed获取,无需陷入内核,提升运行速度,而内核调度方面则交给task_struct ,分工明确,易于拓展。
LWP、PID与线程ID
我们知道PID存是task_struct 中的成员变量,实际上task_struct 中除了PID还有LWP,它们分别有什么作用呢?
PID是Linux进程的唯一标识符号,操作系统通过PID区分各个进程;
LWP则是Linux线程的唯一标识,每个线程的LWP不同,CPU运行时其实是通过LWP识别上下运行的task是不是同一个执行流。 一个进程中主线程的LWP与PID值相同,其余新线程的LWP依次增大,注意现代Linux中线程的 TID 指的就是LWP 。
这线程ID又是什么呢?
用户态线程ID是POSIX线程库(pthread)维护的线程标识符,它在用户态是唯一的 ,其类型**pthread_t实际上是一个指针,指向线程的用户态控制块即struct pthread 的首地址。**
线程ID通常在创建线程时通过pthread_create的写入型形参返回给创建处。
三、线程控制
以下函数都在POSIX线程库pthread.h头文件中。
线程创建
线程创建函数pthread_create:
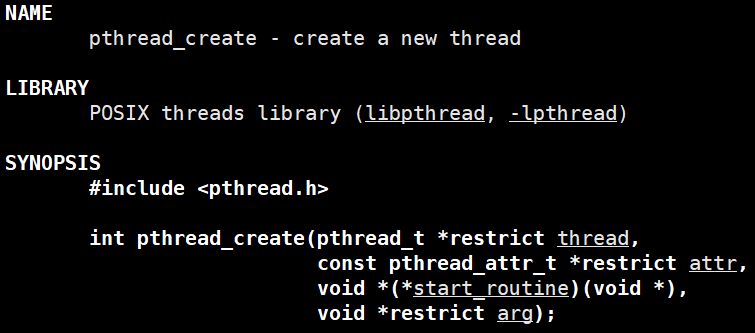
形参1:写入型参数,记录创建线程的ID即struct pthread在进程地址空间中的地址,该ID是pthread用户级线程库标识的,内核不认;
形参2:设置线程属性,一般用默认即可置nullptr;
形参3:函数指针,新线程执行的代码块,即函数地址,注意新线程执行的函数类型必须是void* XXX(void *)。
形参4:将新线程执行函数的参数。
返回值:成功返回0,失败将错误码返回。
Linux的系统调用函数返回值一般是成功返回0,失败返回-1,并且对全局变量errno赋值以指示错误。而pthreads函数出错时不会设置全局变量errno,而是将错误代码通过返回值返回。
使用示例:
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
// #include <thread>
void *routine(void *arg)
{
std::string name = static_cast<const char *>(arg);
int cnt = 5;
while (cnt--)
{
sleep(2);
printf("我是新线程");
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, routine, (void *)"pthread-1");
int cnt = 5;
while (cnt--)
{
printf("我是主线程,我的tid地址:0x%lx\n", pthread_self());
sleep(1);
}
return 0;
}线程回收
是的,如同父进程要等待子进程一样,主线程也需要等待回收创建的新线程,如果不回收将会造成内存泄漏!
线程回收函数pthread_jion:
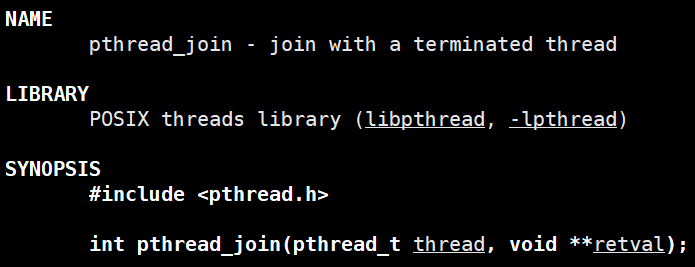
形参1:要回收线程的ID,即pthread_create返回的形参1;
形参2:通过二级指针接收线程返回值,因为新线程执行的函数是返回的void*类型的数据;
**pthread_join是阻塞式回收,而且若不回收新线程会造成资源泄漏。**为什么呢?
当线程运行结束后,操作系统会回收线程的task_struct及其它资源,但无法回收struct pthread以及线程栈等资源,因为它们是是pthread库创建管理的,属于用户级,所以需要主线程调用pthread_join进行显式回收。
cpp
void *routine(void *arg)
{
//......
return (void *)"test";
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, routine, (void *)"pthread-1");
char *ret = nullptr;
pthread_join(tid, (void **)&ret);
std::cout << "收到线程退出信息:" << (char *)ret << std::endl;
return 0;
}线程终止
在Linux中只终止线程而不终止进程有三种方法:
①在线程内部使用return 语句;
②线程可以调用pthread_exit终止自己;
③一个线程可以调用pthread_cancel终止同一进程中的另一个线程
注意:线程中不能使用exit或者_exit终止自己,因为它们会向进程发送信号,导致整个进程都被终止。
pthread_exit( )终止函数:
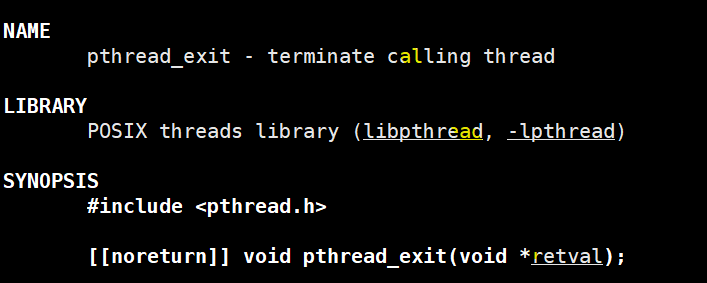
pthread_exit( )终止函数的参数,是该线程返回给调用处的变量指针。也就是pthread_exit(ret)与return ret是等价的,但有一点区别:pthread_exit()可以在线程的任何地方调用,包括深层嵌套的函数中,而**return**只能从线程启动函数返回。
为什么void* 类型?因为在**pthread_create函数中创建的线程执行函数的类型就是void* XXX(void *),所以线程只能返回void* 类型的数据。**而在主线程则通过二级指针(指针变量的指针)来接收返回的内容。
使用示例:
cpp
void *routine(void *arg)
{
//......
pthread_exit((void *)"test");
//return (void *)"test";
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, routine, (void *)"pthread-1");
char *ret = nullptr;
pthread_join(tid, (void **)&ret);
std::cout << "收到线程退出信息:" << (char *)ret << std::endl;
return 0;
}pthread_cancel( )线程撤销函数:
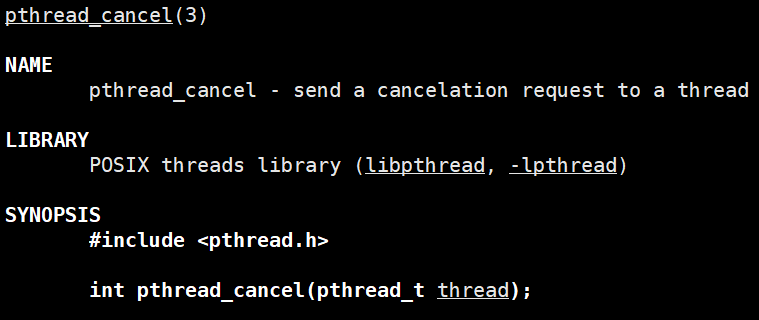
一个线程可以调用pthread_cancel终止同一进程中的另一个线程。
形参是要回收线程的ID,即pthread_create返回的形参1;
在一个被撤销线程的返回值是宏 PTHREAD_CANCELED ,该宏的值通常是-1,也就是说被撤销的线程pthread_join等待的结果是-1.
使用示例:
cpp
void *routine(void *arg)
{
std::string name = static_cast<const char *>(arg);
int cnt = 5;
while (cnt--)
{
sleep(2);
printf("我是新线程,我的tid地址:0x%lx\n", pthread_self());
}
return (void *)"test";
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, routine, (void *)"pthread-1");
int cnt = 5;
while (cnt--)
{
printf("我是主线程\n");
sleep(1);
}
pthread_cancel(tid);
int *ret = nullptr;
int n = pthread_join(tid, (void **)&ret);
if (!n)
std::cout << "收到线程退出信息:" << (long long)ret << std::endl;
else
printf("pthread_join出现错误:%s\n", strerror(n));
return 0;
}线程分离
默认情况下,新创建的线程是需要joinenble等待的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。线程分离的意思是告诉主线程不用等它了,当分离的线程运行结束后会自动释放自己的资源,不会造成资源泄漏。
当对一个已分离(detached) 的线程调用 pthread_join() 时,结果是:调用会立即失败,返回错误码 EINVAL,且不会产生任何其他副作用。
pthread_detach线程分离函数:
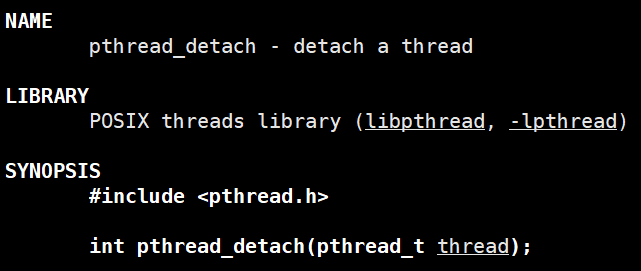
形参是要回收线程的ID,即pthread_create返回的形参1;
pthread_detach函数可以主线程设置,也可以是欲分离的线程自己通过 pthread_self( )得到自己的ID设置分离。
使用示例:
cpp
void *routine(void *arg)
{
std::string name = static_cast<const char *>(arg);
int cnt = 5;
//pthread_detach(pthread_self()); // 新线程自己分离
while (cnt--)
{
sleep(1);
printf("我是新线程,我的tid地址:0x%lx\n", pthread_self());
}
return (void *)"test";
// return (void *)100;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, routine, (void *)"pthread-1");
pthread_detach(tid); // 主线程分离新线程
std::cout << "分离线程, ID" << tid << std::endl;
sleep(5);
char *ret = nullptr;
int n = pthread_join(tid, (void **)&ret);
if (n != 0)
printf("该线程已分离,对一个已经分离的线程等待系统给出的报错信息是:%s\n", strerror(n));
std::cout << (char *)ret << std::endl;
return 0;
}三、线程的优缺点
线程的优点:
①相比进程,创建一个新线程的代价要比创建一个新进程小得多;
②与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多,最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是要更换进程的虚拟地址空间的,并且线程切换TLB与cache中的数据不会全部失效。
③线程占用的资源要比进程少;
④能充分利用处理器中的多核数据实现真正意义上的并行;
⑤在等待慢速I/O操作结束的同时,程序可执行其他的计算任务;
补充:进程切换损耗
进程切换的性能损耗,除了要将寄存器中的内容切换出,另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制: 切换进程的上下文,处理器中所有已经缓存的内存地址一瞬间都作废,处理的⻚表缓冲TLB(快表)会被全部刷新,硬件cache中已经缓存的数据也全部失效,这将导致CPU在访问内存的在一段时间内相当的低效。
线程缺点:
①如果一个进程运行时线程数量多于CPU处理核心数,那么会增加额外的同步和调度开销,导致性能损失;
②健壮性降低。不像进程间具有独立性,由于线程共享进程地址空间,所以一个线程是有可能访问到不应该被访问的变量,从而可能造成隐藏bug。
但换个视角,这也是线程之间通信相较进程间通信方便的原因之一.
③如果一个线程在运行过程中发生异常,那操作系统会终止整个进程,导致其他线程被迫终止。
四、知识拓展
动态库映射
动态库在加载到内存后,会通过页表映射进进程地址空间的共享区中(栈区往下,堆区往上),所以pthread库为线程创建的struct pthread 是在进程地址空间中的虚拟地址是在共享区中,而物理地址则根据页表映射到相关的物理内存上。
线程栈
类似于进程task_struct 中有指向地址空间mm_struct 的指针一样,线程的struct pthread中也有指向线程栈的指针,并且**线程的线程栈大小是固定的,不会像进程那样动态增长。**即使线程有独立的资源,但线程之间是可以互访共享的,这是程序员站在上帝视角做的------可以知道每个线程struct pthread 的地址,知道它会执行什么函数,最终原理还是它们都在同一块进程地址空间中。
注意主线程的栈就是进程地址空间中可动态增长的栈,所有线程共用进程地址空间中的堆。
线程的局部存储
上面说到线程有个独有的资源叫做局部存储,这是怎么回事呢?
当我们想让某个变量的值只为某个线程使用,改变只对当前线程自己生效时,我们可以在该全局变量前加__thread:
cpp
__thread int count = 100;什么原理呢?当编译器编译时看到__thread后就会在每个线程的局部存储中创造一个同名变量 ,当某个线程运行并使用该变量时,在代码中一定是通过变量名访问的,编译器在编译时就会将变量名转换成线程自己局部存储中的地址,所以在代码层面看到似乎每个线程都可以访问或修改该变量,但实际通过编译便后该变量的地址是不同(有点像多态)。所以尽管在同一进程中共享地址空间,但该变量其他进程看不到,因为使用该变量名所指的虚拟地址是每个线程都不一样的 ,除非直接拿着某个线程中存储该变量的地址去寻值,但这是未定义行为。
本文回顾
本文深入探讨了Linux系统中线程的实现原理。
首先分析了线程与进程的关系,指出Linux采用"轻量级进程"机制,复用进程的task_struct结构来表示线程。然后详细讲解了线程的共享资源(地址空间、文件描述符等)和独占资源(线程ID、栈等),并介绍了POSIX线程库如何通过封装系统调用简化线程操作。
此外,文章还阐述了线程控制的关键操作(创建、回收、终止、分离)及其实现细节,分析了线程的优缺点。最后,文章拓展了线程栈、局部存储等高级概念,帮助读者全面理解Linux线程的工作机制。
笔者水平浅薄,文中难免有错漏之处,若读者发现万望指出,共同进步。
读完点赞,手留余香~