目录
[1. 冯诺依曼体系结构](#1. 冯诺依曼体系结构)
[2. 操作系统的定位与功能](#2. 操作系统的定位与功能)
[如何理解 "管理"](#如何理解 “管理”)
[二、进程核心概念:从定义到 PCB](#二、进程核心概念:从定义到 PCB)
[1. 进程的定义](#1. 进程的定义)
[2. 进程的描述:PCB(进程控制块)](#2. 进程的描述:PCB(进程控制块))
[task_struct 的核心内容](#task_struct 的核心内容)
[3. 进程的查看与标识获取](#3. 进程的查看与标识获取)
[4. 进程创建:fork 系统调用](#4. 进程创建:fork 系统调用)
[fork 的核心特性](#fork 的核心特性)
[1. Linux 内核中的进程状态定义](#1. Linux 内核中的进程状态定义)
[2. 进程状态查看命令](#2. 进程状态查看命令)
[3. 重点状态:僵尸进程与孤儿进程](#3. 重点状态:僵尸进程与孤儿进程)
[僵尸进程(Z 状态)](#僵尸进程(Z 状态))
[4. 进程状态转换逻辑](#4. 进程状态转换逻辑)
[1. 核心概念](#1. 核心概念)
[2. 进程优先级详解](#2. 进程优先级详解)
[核心参数:PRI 与 NI](#核心参数:PRI 与 NI)
[3. Linux 2.6 内核的 O (1) 调度算法](#3. Linux 2.6 内核的 O (1) 调度算法)
[4. 进程切换:CPU 上下文切换](#4. 进程切换:CPU 上下文切换)
在计算机系统中,进程是操作系统资源分配与调度的核心单位。从我们日常使用 QQ 聊天、发送文件,到后台服务器同时处理成千上万的请求,背后都离不开进程的管理与协作。本文将从计算机底层架构出发,全面剖析进程的核心概念、状态转换、调度机制,带你构建完整的进程知识体系。
一、基础铺垫:冯诺依曼体系与操作系统
要理解进程,首先需要明确计算机的底层架构和操作系统的核心定位 ------ 这是进程存在和运行的基础环境。
1. 冯诺依曼体系结构
我们常见的计算机,如笔记本、服务器,大部分都遵守冯诺依曼体系结构。其核心组件包括:
- 输入设备:键盘、鼠标、扫描仪、网卡等,负责向系统输入数据;
- 输出设备:显示器、打印机、网卡、磁盘等,负责输出系统处理结果;
- 存储器:这里特指内存,是数据和程序的临时存储介质;
- 中央处理器(CPU):包含运算器和控制器,是执行计算和控制指令的核心。
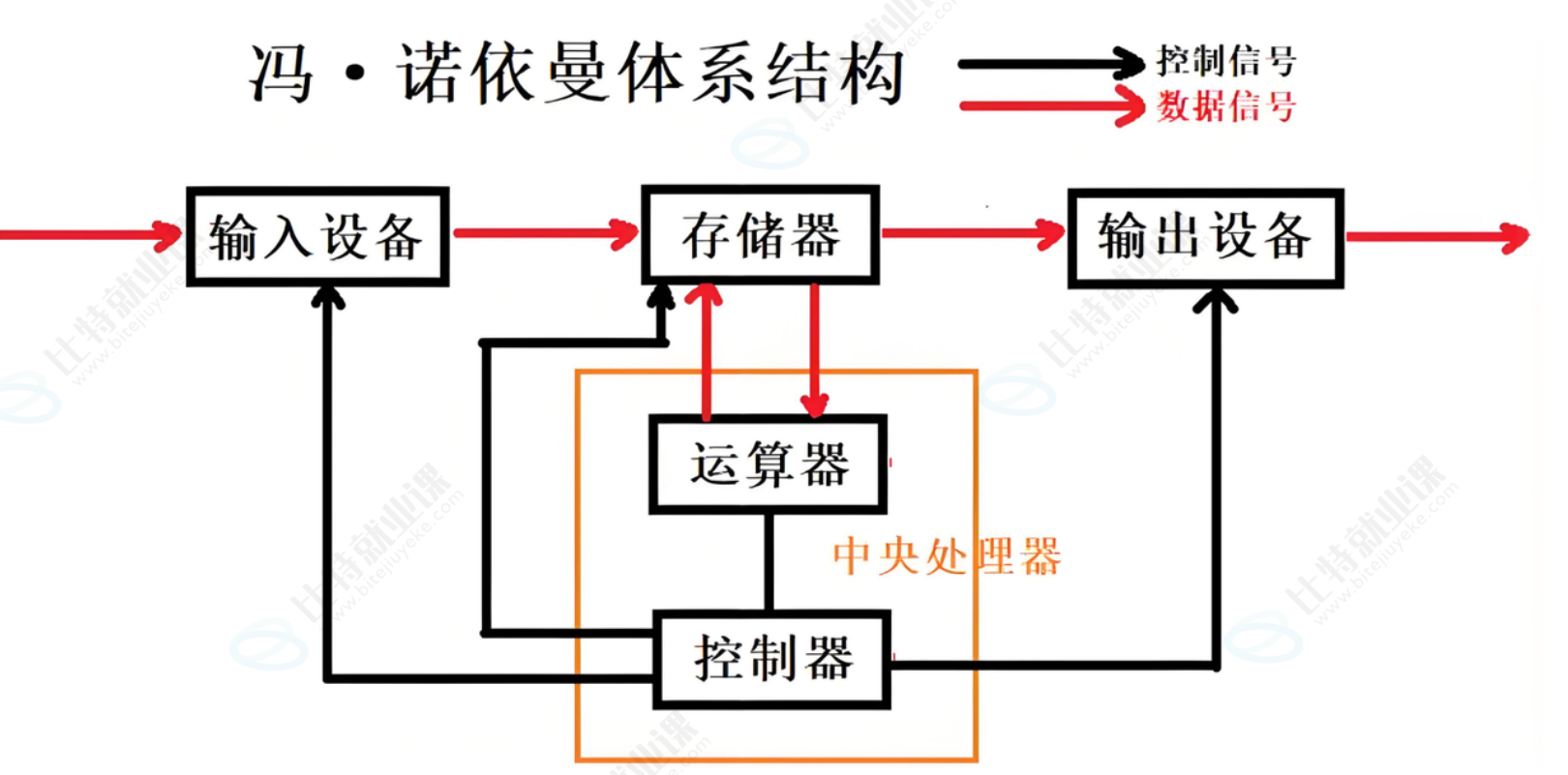
核心规则与数据流动
冯诺依曼体系的关键约束是:CPU 只能直接与内存交互,无法直接访问外设(输入 / 输出设备)。所有设备的数据交换都必须通过内存完成,即 "数据从一个设备拷贝到另一个设备"。
以 QQ 聊天为例,数据流动过程如下:
- 你通过键盘输入消息,输入设备将数据拷贝到内存;
- CPU 从内存读取该消息数据,执行 QQ 程序的处理逻辑;
- 处理后的消息数据被写入内存;
- 内存将消息数据拷贝到网卡(输出设备),通过网络发送给对方;
- 对方的网卡接收数据后拷贝到其内存,再由 CPU 处理后显示到显示器。
发送文件的逻辑类似,只是数据量更大,需通过磁盘与内存的多次拷贝完成传输。这一体系结构的效率由设备间的拷贝速度决定,也解释了为什么内存速度远快于磁盘却容量更小 ------ 这是性价比权衡的结果。
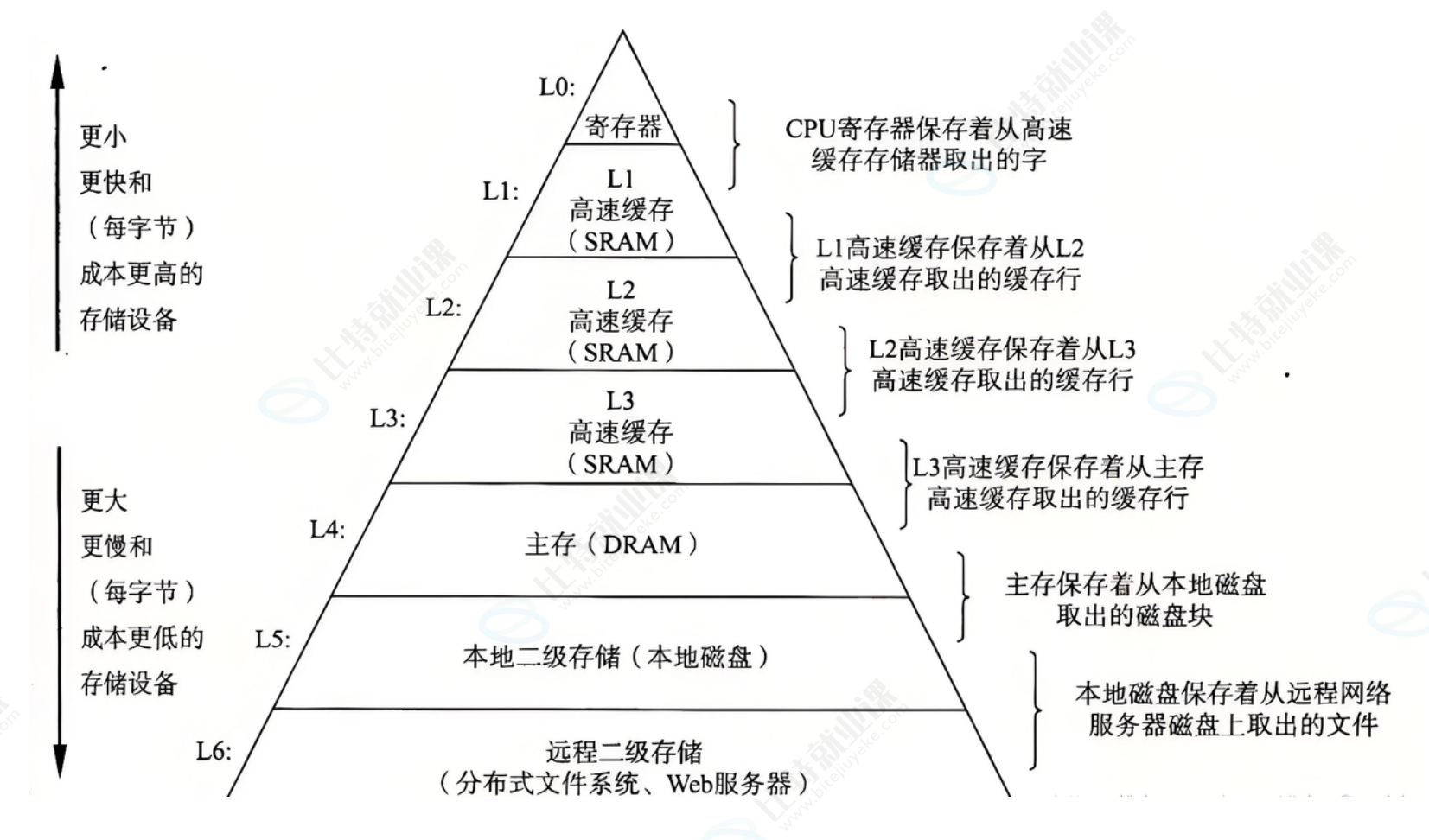
存储层级补充
从 CPU 到远程存储,形成了层级化的存储结构,各层级特性如下:
- L1/L2/L3 高速缓存(SRAM):容量小、速度快、成本高,用于缓存近期频繁访问的数据;
- 主存(DRAM):即内存,容量中等、速度中等,是进程运行时数据和程序的主要存储区域;
- 本地磁盘:容量大、速度慢、成本低,用于长期存储程序和数据;
- 远程二级存储:如分布式文件系统、Web 服务器,用于跨网络的海量数据存储。
2. 操作系统的定位与功能
操作系统(OS)是介于硬件和应用程序之间的核心软件,本质是一款 "搞管理" 的软件,其核心目标是:
- 对下:与硬件交互,管理所有软硬件资源(进程、内存、文件、驱动);
- 对上:为应用程序提供稳定、高效的执行环境。
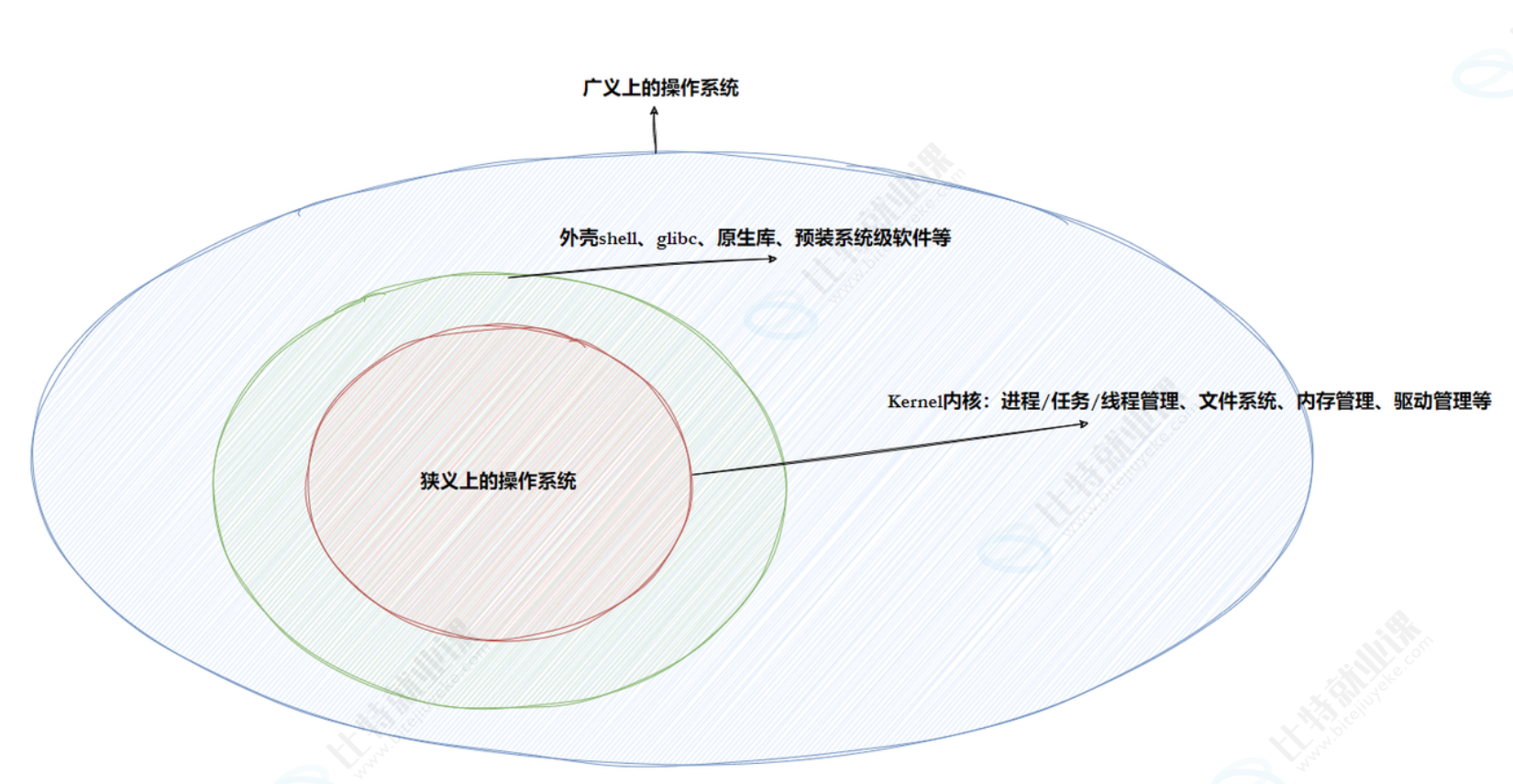
操作系统的组成
- 狭义 OS:仅包含内核(kernel),负责进程管理、内存管理、文件管理、驱动管理等核心功能;
- 广义 OS:包括内核、函数库(如 glibc)、shell 程序、原生库、预装系统级软件等。
如何理解 "管理"
操作系统的管理逻辑与现实中的管理场景(如校长管理学生)异曲同工,核心步骤是:
- 描述被管理对象:用结构体(如 C 语言的 struct)记录对象属性,例如用 task_struct 描述进程;
- 组织被管理对象:用链表或其他高效数据结构将对象组织起来,便于高效查询和修改。
例如校长管理学生,本质是对学生信息(姓名、年龄、成绩等)的管理,对应到计算机中,就是用 struct 结构体存储进程属性,再用链表组织所有进程的 task_struct。
系统调用和库函数概念
操作系统会暴露一组接口供上层开发使用,这部分接口称为系统调用 。系统调用功能基础、使用门槛高,开发者会对其进行封装形成库函数,方便应用程序二次开发。
例如 printf 函数的本质,是封装了 "将数据写入显示器设备" 的系统调用;C 标准库中的 fopen 函数,封装了文件打开相关的系统调用。库函数位于系统调用之上,为开发者提供更友好的使用接口。
二、进程核心概念:从定义到 PCB
1. 进程的定义
- 课本概念:程序的一个执行实例,正在执行的程序;
- 内核观点:担当分配系统资源(CPU 时间、内存)的实体;
- 通俗理解:进程 = 内核数据结构(PCB) + 自己的程序代码和数据。
程序本身是存储在磁盘上的静态文件,当它被加载到内存并开始执行时,就成为了动态的进程。
2. 进程的描述:PCB(进程控制块)
操作系统要管理进程,首先需要描述进程的属性,这一描述载体就是进程控制块(PCB) 。在 Linux 系统中,PCB 的具体实现是task_struct结构体,它会被装载到 RAM(内存)中,包含进程的所有关键信息。
task_struct 的核心内容
- 标示符:描述本进程的唯一标示符(PID),用于区别其他进程;
- 状态:任务状态、退出代码、退出信号等;
- 优先级:相对于其他进程的优先级,决定 CPU 资源分配顺序;
- 程序计数器:程序中即将被执行的下一条指令的地址;
- 内存指针:包括程序代码、进程相关数据的指针,以及与其他进程共享的内存块的指针;
- 上下文数据:进程执行时处理器寄存器中的数据(类似 "休学存档",便于后续恢复执行);
- I/O 状态信息:包括未完成的 I/O 请求、分配给进程的 I/O 设备和被进程使用的文件列表;
- 记账信息:可能包括处理器时间总和、使用的时钟数总和、时间限制、记账号等;
- 其他信息:如进程所属用户、进程组 ID 等。
进程的组织方式
所有运行在系统中的进程,都以task_struct双链表的形式存在于内核中。内核通过遍历该链表,实现对所有进程的管理(如调度、终止、资源分配等)。
3. 进程的查看与标识获取
查看进程的方式
- 通过
/proc系统文件夹查看:系统在/proc下为每个进程创建一个以 PID 命名的目录,包含该进程的详细信息。例如要获取 PID 为 1 的进程信息,可访问/proc/1目录; - 通过用户级工具查看:
ps命令(如ps aux、ps axj)查看进程列表及属性,top命令实时监控进程资源占用情况。
示例:运行一个简单的循环程序,用ps命令查看进程信息
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
while(1) {
sleep(1); // 让进程持续运行,便于查看
}
return 0;
}编译运行后,在另一个终端执行查看命令:
ps aux | grep test | grep -v grep
获取进程标识(PID/PPID)
通过系统调用函数getpid()和getppid(),可在程序中获取当前进程的 PID(进程 ID)和父进程的 PPID(父进程 ID),代码:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
printf("pid: %d\n", getpid()); // 输出当前进程PID
printf("ppid: %d\n", getppid()); // 输出父进程PPID
return 0;
}4. 进程创建:fork 系统调用
Linux 中通过fork()系统调用创建新进程,其特性与行为是理解进程独立性的关键。
fork 的核心特性
- 有两个返回值:父进程中返回子进程的 PID(大于 0),子进程中返回 0;若创建失败,父进程返回 - 1;
- 父子进程代码共享,数据私有:父子进程共享程序代码,但数据(全局变量、局部变量等)采用 "写时拷贝" 机制 ------ 初始时共享数据内存,当任一进程修改数据时,才为修改方拷贝一份私有数据,保证进程独立性。
基础示例代码
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int ret = fork();
printf("hello proc : %d!, ret: %d\n", getpid(), ret);
sleep(1); // 防止进程提前退出,确保输出完整
return 0;
}分流逻辑示例(父子进程执行不同任务)
由于 fork 有两个返回值,通常需要用 if-else 进行逻辑分流,让父子进程执行不同任务:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
int ret = fork();
if(ret < 0) {
perror("fork"); // 创建失败,打印错误信息
return 1;
} else if(ret == 0) { // 子进程(返回值为0)
printf("I am child : %d!, ppid: %d\n", getpid(), getppid());
} else { // 父进程(返回值为子进程PID)
printf("I am father : %d!, child pid: %d\n", getpid(), ret);
}
sleep(1);
return 0;
}关键问题解答
- 为什么 fork 有两个返回值?:fork 创建子进程后,父子进程会同时从 fork 语句之后继续执行,因此函数会返回两次 ------ 这是进程并发执行的结果;
- 两个返回值如何给父子进程返回?:父进程返回子进程的 PID(用于标识子进程),子进程返回 0(父进程可通过 PID 唯一标识,子进程无需标识父进程);
- 为什么一个变量能让 if 和 else 同时成立?:并非变量同时满足两个条件,而是父子进程各自拥有独立的变量副本(写时拷贝机制),父进程中 ret 是子进程 PID(大于 0),子进程中 ret 是 0,因此分别进入 else 和 else if 分支。
三、进程状态及其转换
1. Linux 内核中的进程状态定义
进程在生命周期中会经历多种状态,Linux 内核源码中通过task_state_array数组定义了 7 种核心状态:
static const char *const task_state_array[] = {
"R (running)", /* 0 - 运行状态 */
"S (sleeping)", /* 1 - 可中断睡眠状态 */
"D (disk sleep)", /* 2 - 不可中断睡眠状态 */
"T (stopped)", /* 4 - 停止状态 */
"t (tracing stop)",/* 8 - 追踪停止状态 */
"X (dead)", /* 16 - 死亡状态 */
"Z (zombie)" /* 32 - 僵尸状态 */
};各状态详细说明
- R(running):运行状态。并不意味着进程一定在运行中,它表明进程要么是在运行中,要么在运行队列里等待 CPU 调度;
- S(sleeping):可中断睡眠状态(interruptible sleep)。进程等待某个事件完成(如 I/O 完成、信号),可被信号唤醒;
- D(disk sleep):不可中断睡眠状态(uninterruptible sleep)。通常等待磁盘 I/O 完成,无法被信号唤醒,避免 I/O 中断导致数据丢失;
- T(stopped):停止状态。可通过发送 SIGSTOP 信号给进程来停止,通过 SIGCONT 信号让进程继续运行;
- t(tracing stop):追踪停止状态。被调试工具(如 gdb)追踪时的停止状态;
- X(dead):死亡状态。进程退出后的返回状态,不会在任务列表中看到;
- Z(zombie):僵尸状态。进程退出但父进程未读取其退出代码,PCB 仍保留在系统中。
2. 进程状态查看命令
通过ps aux或ps axj命令可查看进程状态,命令参数说明:
- a:显示一个终端的所有进程,包括其他用户的进程;
- x:显示没有控制终端的进程(如后台运行的守护进程);
- j:显示进程归属的进程组 ID、会话 ID、父进程 ID 及与作业控制相关的信息;
- u:以用户为中心的格式显示进程信息,包括用户、CPU 和内存使用情况等。
3. 重点状态:僵尸进程与孤儿进程
僵尸进程(Z 状态)
-
形成原因:当进程退出并且父进程未通过
wait()等系统调用读取其退出代码时,会产生僵尸进程; -
核心特性:僵死进程会以终止状态保持在进程表中,等待父进程读取退出状态代码;
-
危害:僵尸进程的 PCB 会一直被维护,占用内存资源。若父进程长期不回收,会导致内存泄漏,严重时耗尽系统资源;
-
示例代码(创建维持 30 秒的僵尸进程):
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>int main() {
pid_t id = fork();
if(id < 0) {
perror("fork");
return 1;
} else if(id > 0) { // 父进程
printf("parent[%d] is sleeping...\n", getpid());
sleep(30); // 父进程睡眠30秒,不读取子进程退出状态
} else { // 子进程
printf("child[%d] is begin Z...\n", getpid());
sleep(5); // 子进程睡眠5秒后退出
exit(EXIT_SUCCESS); // 子进程退出
}
return 0;
}
编译运行后,在另一个终端执行监控命令,可观察到子进程的 Z 状态:
[root@MiWiFi-RICL-srv test]# while :; do ps aux | grep test | grep -v grep; done
root 3872 0.0 0.0 1868 372 pts/0 S+ 19:48 0:00 ./test
root 3873 0.0 0.0 0 0 pts/0 Z+ 19:48 0:00 [test] <defunct>孤儿进程
-
形成原因:父进程提前退出,子进程尚未退出,此时子进程成为孤儿进程;
-
处理机制:孤儿进程会被 1 号 init(或 systemd)进程领养,由 init 进程负责回收其退出状态,避免成为僵尸进程;
-
示例代码:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>int main() {
pid_t id = fork();
if(id < 0) {
perror("fork");
return 1;
} else if(id == 0) { // 子进程
printf("I am child, pid : %d, ppid: %d\n", getpid(), getppid());
sleep(10); // 子进程睡眠10秒,期间父进程已退出
} else { // 父进程
printf("I am parent, pid: %d\n", getpid());
sleep(3); // 父进程睡眠3秒后退出
exit(0);
}
return 0;
}
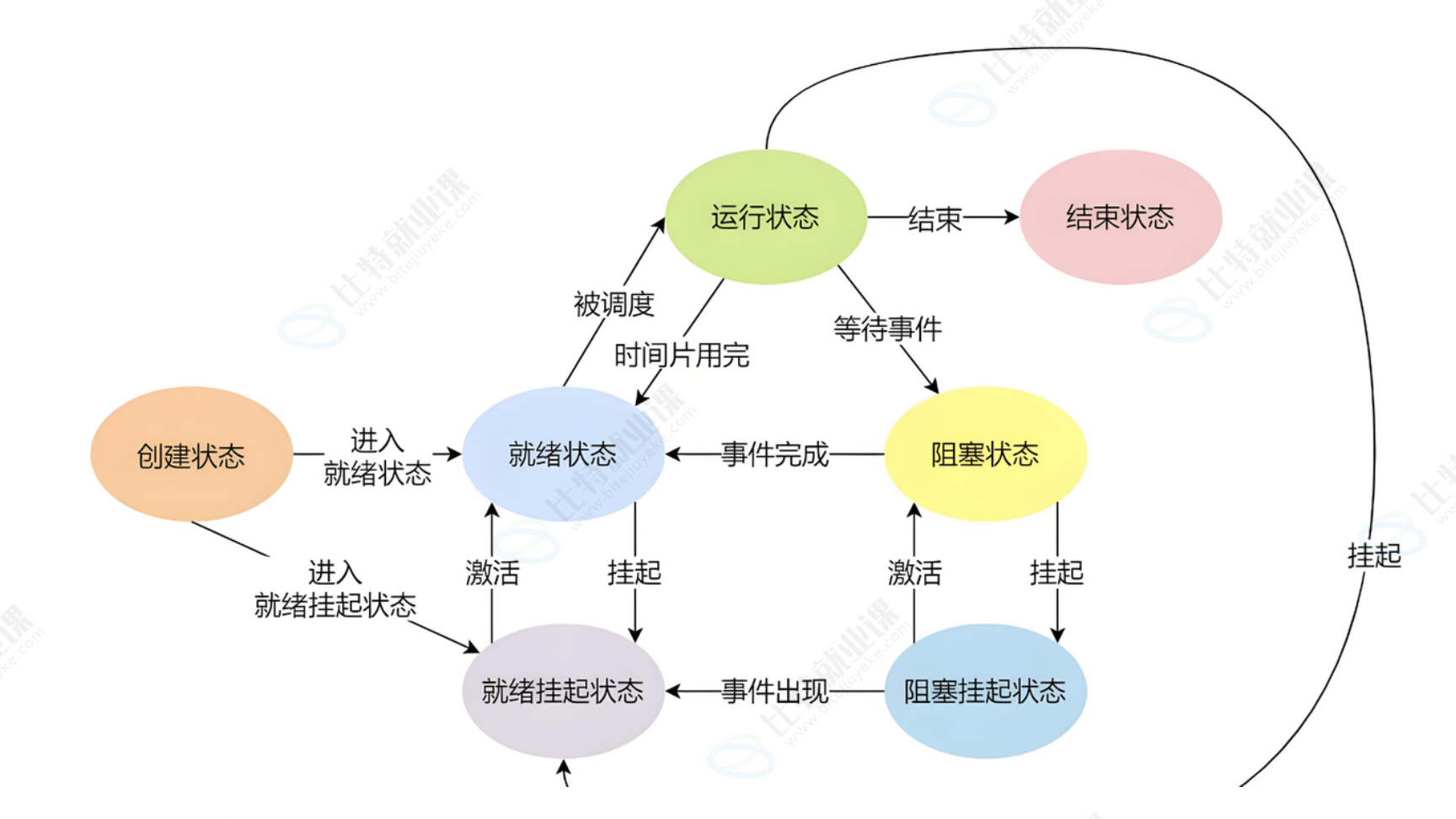
4. 进程状态转换逻辑
进程状态的转换由事件触发,核心路径如下:
- 创建状态 → 就绪状态:进程创建完成后,进入运行队列等待 CPU 调度;
- 就绪状态 ↔ 运行状态:CPU 时间片分配(就绪→运行)或时间片耗尽(运行→就绪);
- 运行状态 → 阻塞状态(S/D):进程等待事件(如 I/O 操作、sleep 调用);
- 阻塞状态 → 就绪状态:等待的事件完成(如 I/O 结束、信号到达);
- 运行状态 → 停止状态(T/t):收到 SIGSTOP 信号或被调试工具追踪;
- 停止状态 → 就绪状态:收到 SIGCONT 信号;
- 任何状态 → 死亡状态(X):进程退出,退出代码被父进程读取;
- 运行状态 → 僵尸状态(Z):进程退出,父进程未读取退出代码。
状态转换的核心驱动因素:CPU 调度、事件等待、信号触发、进程退出。
四、进程调度与优先级
1. 核心概念
- 竞争性:系统进程数目众多,而 CPU 资源有限(甚至 1 个),进程间存在竞争属性,优先级是竞争的关键依据;
- 独立性:多进程运行时需独享各种资源,运行期间互不干扰(通过写时拷贝、虚拟地址空间实现);
- 并行:多个进程在多个 CPU 下分别、同时进行运行(真正的 "同时");
- 并发:多个进程在一个 CPU 下采用进程切换的方式,在一段时间内让多个进程都得以推进(看似 "同时")。
2. 进程优先级详解
进程优先级决定 CPU 资源分配的先后顺序,合理配置优先级可改善系统性能。
核心参数:PRI 与 NI
- PRI(Priority):进程的基础优先级,值越小,优先级越高,越早被执行;
- NI(Nice 值):进程优先级的修正数值,取值范围为 - 20~19(共 40 个级别);
- 优先级计算规则:
PRI(new) = PRI(old) + NI。
例如:若进程原有 PRI 为 80,NI 设为 - 5,则新 PRI 为 75,优先级升高;若 NI 设为 10,则新 PRI 为 90,优先级降低。
查看进程优先级
通过ps -l命令可查看进程的 PRI 和 NI 值,示例输出:
[whbebite-alicloud processbar]$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 R 1000 12572 42780 0 80 0 - 38328 - pts/0 00:00:00 ps
0 S 1000 42780 42777 0 80 0 - 28919 do_wait pts/0 00:00:00 bash输出字段说明:
- UID:执行者的身份;
- PID:进程代号;
- PPID:父进程代号;
- C:CPU 使用率;
- PRI:进程基础优先级;
- NI:Nice 值。
调整进程优先级的方式
-
top 命令(调整已运行进程):
- 执行
top命令进入监控界面; - 按 "r" 键,输入要调整的进程 PID;
- 输入新的 Nice 值(-20~19),完成优先级调整。
- 执行
-
nice 命令(启动进程时设置优先级):示例:
nice -n 5 ./test(启动 test 程序,设置 NI 为 5,PRI = 默认值 + 5); -
renice 命令(调整已运行进程):示例:
renice 3 1234(将 PID=1234 的进程 NI 设为 3); -
系统调用函数:
#include <sys/time.h>
#include <sys/resource.h>// 获取优先级:which指定类型(如PRIO_PROCESS),who指定进程ID
int getpriority(int which, int who);
// 设置优先级:prio为新的Nice值
int setpriority(int which, int who, int prio);
3. Linux 2.6 内核的 O (1) 调度算法
Linux 2.6 内核采用 O (1) 调度算法,核心是通过固定时间复杂度的调度逻辑,保证调度效率不随进程数量增加而下降。
核心数据结构:runqueue(运行队列)
每个 CPU 对应一个 runqueue,用于管理该 CPU 上的所有进程,其结构体定义如下(关键字段):
struct rq {
spinlock_t lock; // 自旋锁,保证线程安全
unsigned long nr_running; // 运行状态的进程总数
unsigned long nr_switches; // 进程切换次数
struct task_struct *curr; // 当前运行的进程
struct task_struct *idle; // 空闲进程
struct prio_array *active; // 活动队列(时间片未耗尽)
struct prio_array *expired; // 过期队列(时间片耗尽)
struct prio_array arrays[2]; // 存储active和expired队列
int best_expired_prio; // 过期队列中最高优先级
// 其他字段(如负载均衡、统计信息等)
};
// 优先级队列结构体
struct prio_array {
unsigned int nr_active; // 队列中进程总数
DECLARE_BITMAP(bitmap, MAX_PRIO+1); // 标记队列是否非空的位图
struct list_head queue[MAX_PRIO]; // 进程队列数组(按优先级分队列)
};关键组件说明
- 优先级范围:
- 实时优先级:0~99(优先级高,不关心普通进程调度);
- 普通优先级:100~139(对应 Nice 值 - 20~19,Nice 值越小,普通优先级数值越小)。
- 活动队列(active):存放时间片未耗尽的进程,按优先级分为 140 个队列(下标 0~139),相同优先级的进程按 FIFO 规则调度;
- 过期队列(expired):存放时间片耗尽的进程,结构与 active 队列一致;
- bitmap(位图):用 5 个 32 位整数(共 160 位)标记 140 个优先级队列是否非空,通过位运算快速查找最高优先级的非空队列,提升查找效率。
调度流程
- 查找最高优先级队列:通过 bitmap 位图快速定位 active 队列中最高优先级的非空队列;
- 选择进程执行:从找到的队列中取出第一个进程(FIFO 规则),分配 CPU 执行;
- 时间片管理:进程时间片耗尽时,将其移至 expired 队列,并重新计算时间片;
- 队列切换:当 active 队列为空时,交换 active 和 expired 指针,expired 队列变为新的 active 队列,实现高效调度循环。
算法优势
由于查找最高优先级队列的时间复杂度为 O (1)(通过位图直接定位),调度流程不随进程数量增加而变慢,因此称为 O (1) 调度算法,能高效支持大量进程调度。
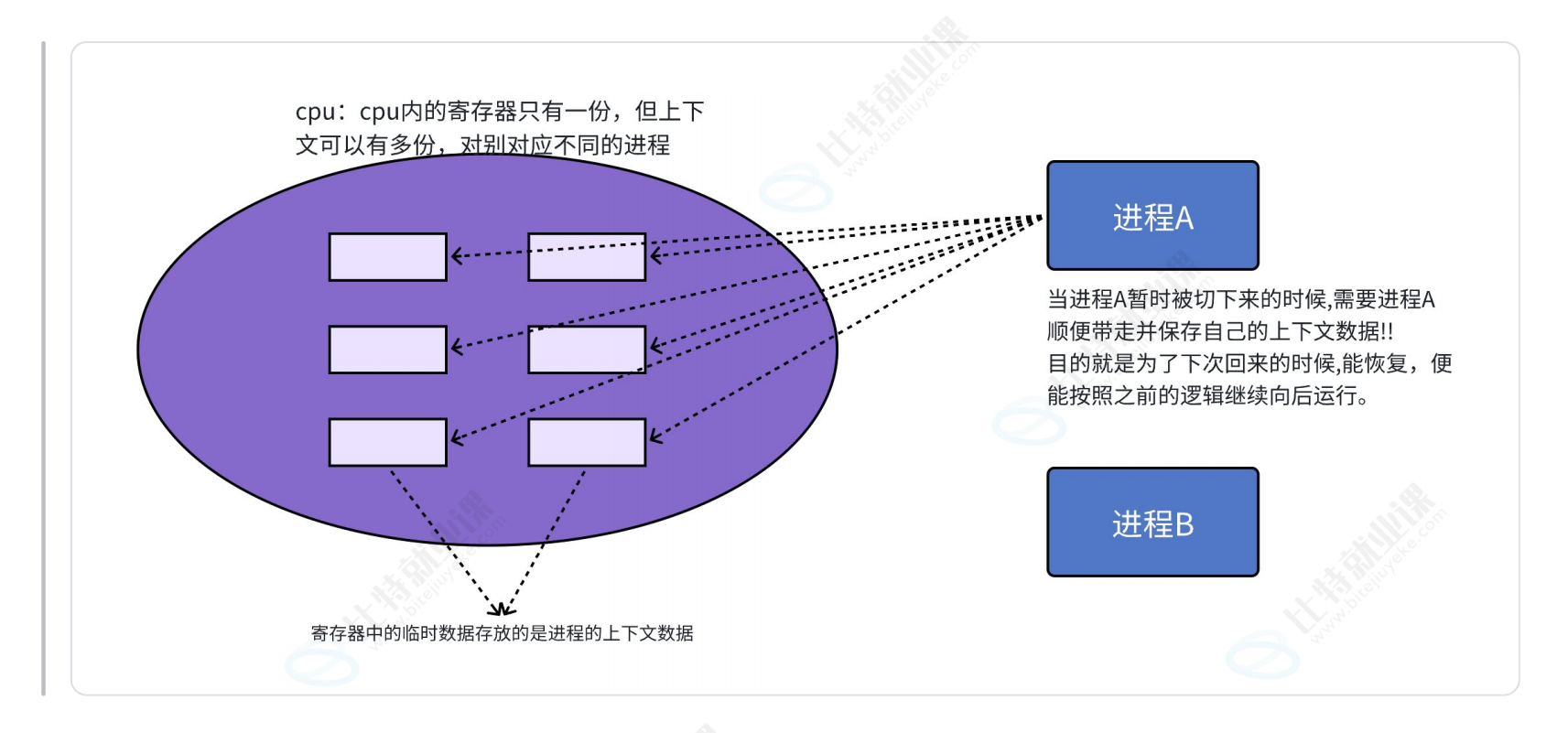
4. 进程切换:CPU 上下文切换
核心概念
CPU 上下文切换是指任务切换(或 CPU 寄存器切换),当多任务内核决定运行另一个任务时,需保存当前任务状态,加载下一个任务状态,这一过程称为上下文切换(context switch)。
关键细节
- CPU 寄存器只有一份,不同进程有各自的上下文数据;
- 进程上下文包含进程执行时 CPU 寄存器中的所有数据(如程序计数器、通用寄存器、状态寄存器等);
- 当进程 A 被切下时,需保存其上下文数据到自身堆栈;当进程 A 再次被调度时,从堆栈中恢复上下文数据,即可按之前的逻辑继续执行。
上下文切换流程
- 触发条件:进程时间片耗尽、有更高优先级进程进入就绪状态、进程主动放弃 CPU(如 sleep);
- 保存上下文:将当前进程的 CPU 寄存器数据保存到该进程的堆栈中;
- 选择下一个进程:通过调度算法从就绪队列中选择下一个要执行的进程;
- 恢复上下文:从下一个进程的堆栈中加载其上下文数据到 CPU 寄存器;
- 执行新进程:CPU 开始执行新进程的指令。
与进程切换相关的内核结构
Linux 内核中,进程的上下文数据存储在task_struct关联的struct tss_struct(任务状态段)中,用于保存进程的硬件上下文信息,支持上下文切换时的快速保存和恢复。
切换开销
上下文切换存在一定开销(如保存 / 加载寄存器数据、更新页表、刷新 CPU 缓存等),频繁切换会降低系统效率。因此调度算法需在 "进程响应速度" 和 "切换开销" 之间平衡。
五、总结
本文围绕进程核心知识展开,从冯诺依曼体系结构与操作系统的管理本质切入,详解了进程的定义、PCB的核心信息,进程创建(fork 系统调用与写时拷贝)、7 种状态及僵尸 / 孤儿进程的特性,进程优先级(PRI 与 NI)、Linux 2.6 内核 O (1) 调度算法与 CPU 上下文切换,完整覆盖进程从底层基础到实际应用的核心要点。
