中间件的常考方向:
-
中间件如何做到高可用和高性能的?
-
你在实践中怎么做的高可用和高性能的?
Elasticsearch节点角色
Elasticsearch的节点可以分为很多种角色,并且一个节点可以扮演多种角色,下面列举几种主要的:
-
候选主节点:可以被选举为主节点的节点。主节点主要负责集群本身的管理,比如创建索引。类似的还有仅投票节点,这类节点只参与主从选举,但是自身并不会被选举为主节点。
-
协调节点:协调节点负责协调请求的处理过程。一个查询请求会被发送到协调节点上,协调节点确定数据节点,然后让数据节点执行查询,最后协调节点合并数据节点返回的数据集。大多数节点都会兼任这个角色。
-
数据节点:存储数据的节点。当协调节点发来查询请求的时候,也会执行查询并且把结果返回给协调节点。类似的还有热数据节点、暖数据节点、冷数据节点,它们只是用于存储不同热度的数据。
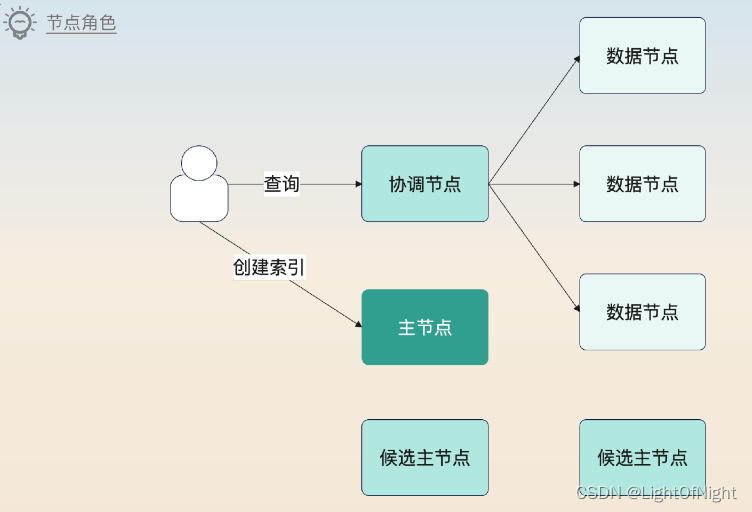
给节点设置不同的角色的原则:如果有足够的资源,就考虑一个节点只扮演一个角色;资源不足的话,就考虑一个节点扮演多个角色。
写入数据
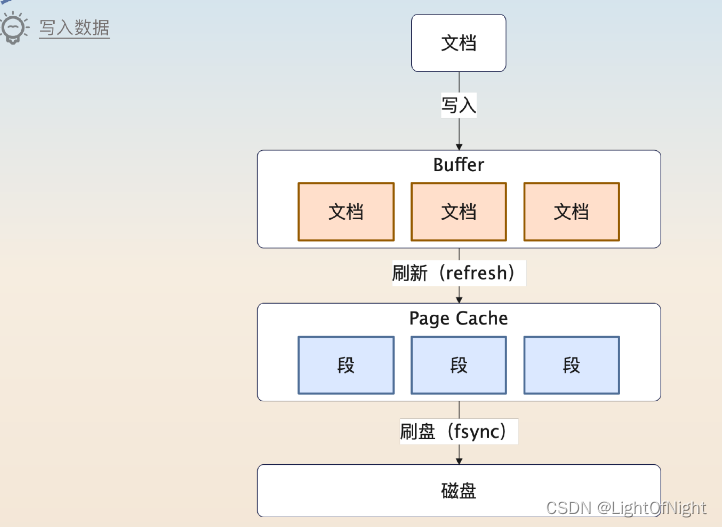
写入数据的过程整体如上所述
-
文档首先被写入到Buffer里面,这个是Elasticsearch自己的Buffer
-
定时刷新到Page Cache里,这个过程叫做refresh,默认一秒钟执行一次。
-
刷新到磁盘里,这个时候还会同步记录一个Commit Point
在写入Page Cache之后会产生很多段(Segment),一个段里面包含了多个文档。文档只有写到了这里之后才可以被搜索到。
从支持搜索的角度来说,Elasticsearch是近实时的。
不断写入会不断产生段,而每一个段都需要消耗CPU、内存和文件句柄,所以需要考虑合并。但是,这些段本身还在支持搜索,因此在合并段的时候,不能对已有的查询产生影响。
基本的过程如下,类似数据迁移:
-
已有的段不动
-
创建一个新的段,把已有段的数据写过去,标记为删除的文档就不会被写到段里面
-
告知查询使用新的段
-
等使用老的段的查询都结束了,直接删掉老的段
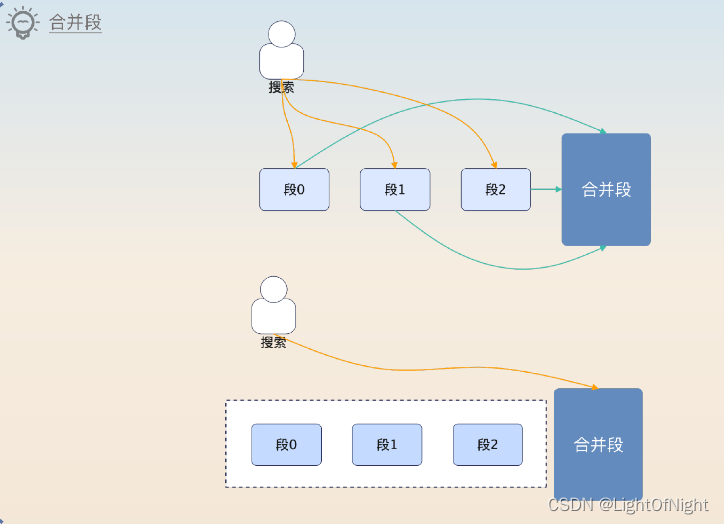
那么查询怎么知道应该使用合并段了呢?这依赖于统一的机制,就是Commit Point,里面记录了哪些段是可用的。
所以当合并段之后,产生了一个新的Commit Point,里面有合并后的段,但是没有被合并的段,相当于告知了查询使用新的段。
Translog
Elasticsearch在写入的时候,还要写入Translog。可以把这个看作是MySQL里和redo log差不多的东西,如果宕机了可以通过Translog来恢复数据。
MySQL写入的时候,修改了内存里的值,然后记录了日志,也就是binlog、redo log和undo log
Elasticsearch写入的时候,也是写入了Buffer里,然后记录了Translog
两者的区别是:Translog是固定间隔刷新到磁盘上的,默认是5秒。
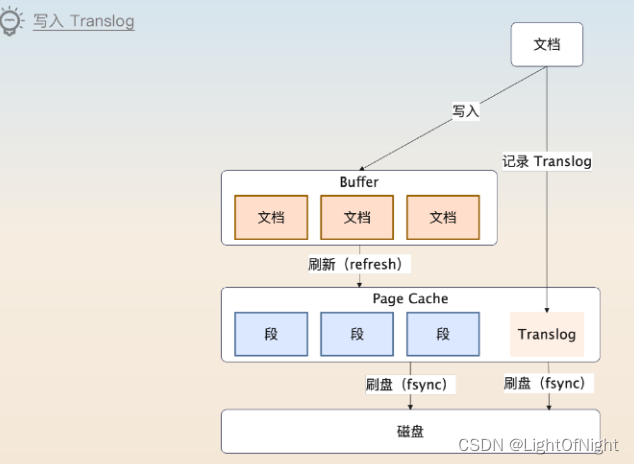
Translog是只追加的,也就是顺序写的,所以效率很高。只有刷新到磁盘的时候,才会非常慢。
但是,就算有Translog,还是有数据丢失的可能,最差情况下,会丢失5秒的数据。
Elasticsearch索引与分片
一个Elasticsearch的索引并不仅仅指倒排索引,还包括了对应的文档。这个和关系型数据库下的语义是不同的。
Elasticsearch的一个索引有多个分片,每个分片又有主从结构,类似于数据库的分库分表。可以这样理解:
-
一个索引是一个逻辑表
-
分片就是分库分表
-
每个分片都有主从结构,在分库分表里面,一般也是用主从集群来存储数据
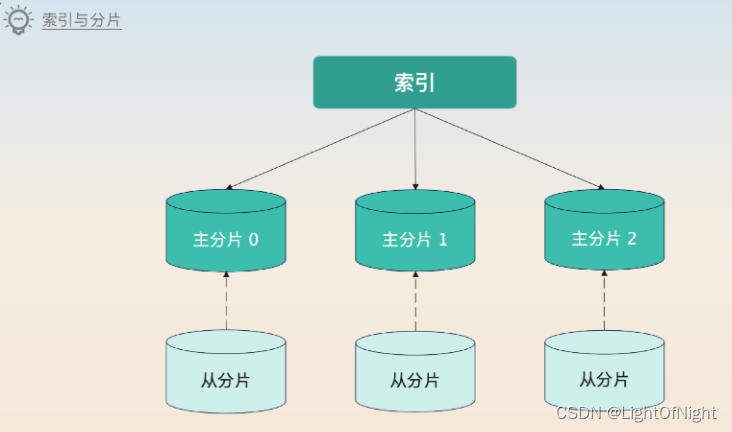
Elasticsearch会尽量把分片分散在不同的节点上,这一点和kafka尽量把分区分散在不同broker上是一样的,为了保证在节点崩溃的时候将影响最小化。
主分片崩溃后,是怎么选出新的主分片呢?
主节点选择一个分片作为主分片,类似于Redis Sentinel里的机制,如果主节点宕机了,Sentinel会从节点里选出一个作为主节点
面试准备
-
公司有没有使用Elasticsearch,用来解决什么问题?
-
Elasticsearch性能怎么样?读写流量多大?存储数据量多大?
-
创建的索引有多大?有多少个分片?如何确定分片数量的?
-
有没有采用一些措施来保证Elasticsearch的可用性?有没有用过Elasticsearch的网关?
-
Elasticsearch有没有出过问题?如何解决的?
项目介绍的时候也可以强调一下项目可用性的一个关键点就是Elasticsearch,从而打开话题。面试的时候可以收集一些使用Elasticsearch的基本案例,这样面试讲到一些理论的时候,也可以用这些案例来佐证。
和Elasticsearch相关的面试题目有很多,比如:
-
有没有用过Elasticsearch?用来解决什么问题
-
用Elasticsearch的过程中,有没有遇到过什么问题?最后是如何解决的?
-
为什么Elasticsearch是近实时的?
-
Elasticsearch的flush指的是什么?refresh又是什么?
-
Elasticsearch的写入过程是什么样的?