背景介绍
很早以前就看过一篇介绍 RAG 的综述性文章 Retrieval-Augmented Generation for Large Language Models: A Survey, 其中介绍了 RAG 的模块化架构:
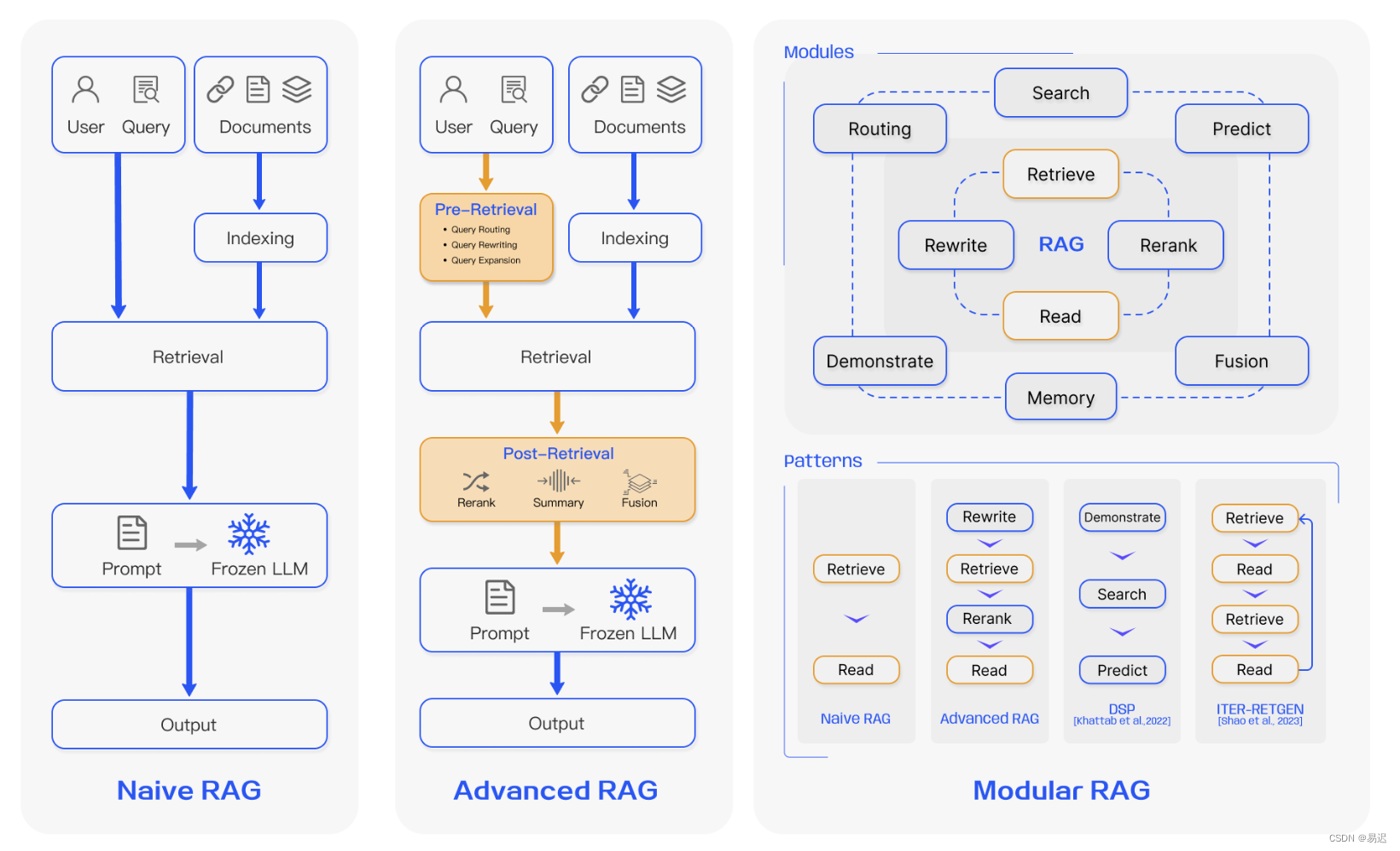
但是一直没有看到对应的实现方案,以前也没有理解此框架的优势之处。随着在相关领域的持续实践,逐渐理解到模块化 RAG 的优势。模块化 RAG 可以方便地进行服务的迭代升级,另外模块可以自由组合,灵活性更好。
最近注意到来自中科院的 RAG 服务 GoMate 开源了,核心亮点就是模块化 RAG 设计,本文就深入介绍来 GoMate 的框架设计与实现细节。
框架设计
之前介绍的 RAG 框架存在着不同的侧重点,来自有道的 QAnything 强调其 Rerank 设计,RagFlow 强调其精细的文件处理。而 GoMate 则主要强调其模块化设计。
GoMate 的框架设计图如下所示:

可以看到,框架中将 RAG 流程拆分为不同模块,熟悉 RAG 服务还是比较容易理解的,一些核心模块如下所示:
Retrieval对应的就是知识库的检索Rerank&Judge对应的就是检索内容的重排序与过滤Generation对应的就是大模型内容生成Citation对应的就是检索内容引用的处理
每个模块可以存在多种不同的实现形式,比如 Retrieval 图中包含如下所示的实现:
Sparse Retriever对应的是稀疏检索,目前常见的 BM25 的检索;Dense Retriever对应的密集检索,RAG 中最常见的是向量检索;Ensemble Retriever对应的应该是混合检索;
从架构图可以看到 GoMate 就是包含了多个基础的功能模块,通过功能模块的的组合实现具体的应用。
实现细节
GoMate 是从 2024 年 2 月开始开发的,截止目前经过了 4 个月的开发,虽然功能还不够完善,但是已经可以看到模块化的完整设计思想了。
项目主要包含两部分:
- modules 包含的就是基础模块, 与上面架构图中的模块可以对应起来
- applications 表示的是模块组合生成的应用,实现业务所需的功能
功能模块
每个模块对应的职责比较明确,以 RAG 中核心的检索模块为例,深入查看对应的实现:
基础的检索接口在 gomate/modules/retrieval/base.py 中定义,只包含一个 retrieve() 方法:
python
class BaseRetriever(ABC):
@abstractmethod
def retrieve(self, query: str) -> str:
passBM25 检索算法在 gomate/modules/retrieval/bm25_retriever.py 实现,其中实现了 BM25Okapi, BM25L 和 BM25Plus 版本的算法,具体如下所示:
python
class BM25Retriever(BaseRetriever):
# 实现不同的 BM25 算法
def build_from_texts(self, corpus):
self.corpus=corpus
if self.algorithm == 'Okapi':
self.bm25 = BM25Okapi(corpus=corpus, tokenizer=self.tokenizer, k1=self.k1, b=self.b, epsilon=self.epsilon)
elif self.algorithm == 'BM25L':
self.bm25 = BM25L(corpus=corpus, tokenizer=self.tokenizer, k1=self.k1, b=self.b, delta=self.delta)
elif self.algorithm == 'BM25Plus':
self.bm25 = BM25Plus(corpus=corpus, tokenizer=self.tokenizer, k1=self.k1, b=self.b, delta=self.delta)
else:
raise ValueError('Algorithm not supported')
# 检索接口的实现
def retrieve(self, query: str='',top_k:int=3) -> List[Dict]:
tokenized_query = " ".join(self.tokenizer(query))
search_docs = self.bm25.get_top_n(tokenized_query, self.corpus, n=top_k)
return search_docs向量检索算法是基于 Faiss 实现的,简化后实现如下所示:
python
class DenseRetriever(BaseRetriever):
# 初始化 Faiss 向量检索
def __init__(self, config):
self.config = config
self.tokenizer = AutoTokenizer.from_pretrained(config.model_name)
self.model = AutoModel.from_pretrained(config.model_name)
self.index = faiss.IndexFlatIP(config.dim)
# 检索接口实现
def retrieve(self, query):
D, I = self.index.search(self.get_embedding([query]), self.top_k)
return [{self.doc_map[idx]: score} for idx, score in zip(I[0], D[0]) if idx in self.doc_map]在 gomate/modules/retrieval/tree_retriever.py 中还实现了 RAPTOR 检索,感兴趣的也可以深入查看实现细节。
可以看到检索模块包含的就是不同算法的实现,上层应用可以根据需要选择合适的检索算法。
其他的模块与检索模块类似,对应的就是单个功能的实现。
应用
目前实现的应用比较少,只有 Rerank,Rewrite 和 RAG ,目前只有 RAG 属于一个完整的应用,其他都是单个模块的测试,深入查看 RAG 应用的实现,具体如下所示:
python
class RagApplication():
# 初始化向量库
def init_vector_store(self):
docs=self.reader.get_content(max_token_len=600, cover_content=150)
self.vector_store.document=docs
self.vector_store.get_vector(EmbeddingModel=self.embedding_model)
self.vector_store.persist(path='storage')
self.vector_store.load_vector(path='storage')
# 向量库中添加文件
def add_document(self, file_path):
docs = self.reader.get_content_by_file(file=file_path, max_token_len=512, cover_content=60)
self.vector_store.add_documents(self.config.vector_store_path, docs, self.embedding_model)
# RAG 对话
def chat(self, question: str = '', topk: int = 5):
# 向量检索
contents = self.vector_store.query(question, EmbeddingModel=self.embedding_model, k=topk)
content = '\n'.join(contents[:5])
# 大模型聊天
response, history = self.llm.chat(question, [], content)
return response, history,contents可以看到目前实现的 RAG 应用只是一个简单的向量库模块和大模型聊天的模块的组合,暂时看不到模块化的优势之处。
但是从目前的设计来看,模块化的设计存在一些明显的优势。基础模块可以独立进行迭代,上层应用可以根据需要组合所需的模块,比如大模型聊天只需要将下面的模块组合在一起:
- Query Processing
- Prompt Engineering
- Generation
而 RAG 完整流程可以组合下面的模块:
- Query Processing
- Query Transformation
- Retrieval
- Rerank&Judge
- Prompt Engineering
- Generation
- Prompt Engineering
- Generation
- Citation
- Post Processing
应用中的各个模块可以独立测试和优化,组合的模块也可以根据需要进行替换升级,比如 RAG 的检索方案从 DenseRetriever 调整为 BM25Retriever 只需要简单的参数修改即可。
总结
本文介绍了中科院的模块化 RAG 项目 GoMate,项目目前还处于初始阶段,还有不少功能等待实现,但是可以看到的一个模块化 RAG 的实现思路,通过精细的模块拆分,模块的迭代升级可以变得更加便利,应用的实现也会演变成简单的模块组合。对 GoMate 项目感兴趣的可以前往官网深入了解。