文章目录
Python爬虫学习 :我们可以选择一个相对简单的网站进行数据抓取。这里以抓取"豆瓣电影Top250"的信息为例,这个网站提供了丰富的电影数据,包括电影名称、评分、导演、演员等信息。
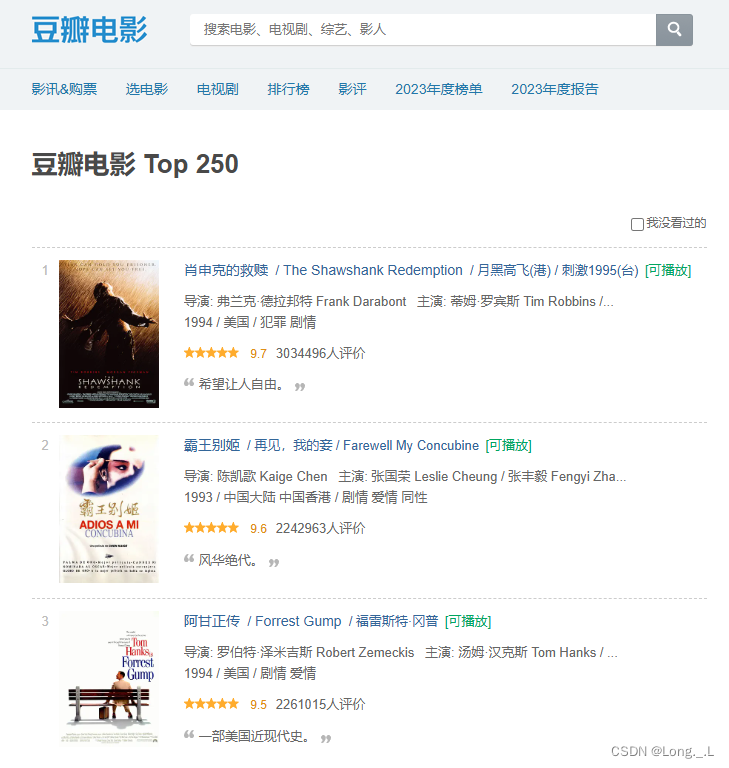
网页地址
爬虫目标
- 抓取每部电影的名称、评分、简介和前几位主演的名字。
技术栈
- Python 3.x
requests:用于发送HTTP请求。BeautifulSoup4:用于解析HTML文档。
爬虫代码
首先,确保你已经安装了requests和beautifulsoup4库,如果没有安装,可以通过以下命令安装:
bash
pip install requests beautifulsoup4以下是完整的爬虫代码:
python
# 导入requests库用于发送HTTP请求
import requests
# 导入BeautifulSoup库用于解析HTML文档
from bs4 import BeautifulSoup
# 定义一个函数用于获取电影数据
def fetch_movie_data():
# 设置请求的URL,这里是豆瓣电影Top 250的页面
url = "https://movie.douban.com/top250"
# 设置请求头,伪装成浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 发送GET请求,获取页面内容
response = requests.get(url, headers=headers)
# 使用BeautifulSoup解析获取到的页面内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找页面中所有的电影条目
movies = soup.find_all('div', class_='item')
# 遍历每部电影条目
for movie in movies:
# 提取电影标题
title = movie.find('span', class_='title').text
# 提取电影评分
rating = movie.find('span', class_='rating_num').text
# 提取电影的详细信息,这里只取第一行
info = movie.find('div', class_='bd').find('p').text.strip().split('\n')[0]
# 提取主演信息,可能有多个主演,通过分割和筛选获取
actors = [actor.strip() for actor in info.split('/') if actor.strip().startswith('主演')]
# 如果有主演信息,去除'主演:'并用逗号连接,否则显示'N/A'
actors = ', '.join(actors).replace('主演:', '') if actors else 'N/A'
# 打印电影的标题、评分和主演信息
print(f"Title: {title}")
print(f"Rating: {rating}")
print(f"Actors: {actors}\n")
# 判断是否是直接运行此脚本,如果是,则调用fetch_movie_data函数
if __name__ == "__main__":
fetch_movie_data()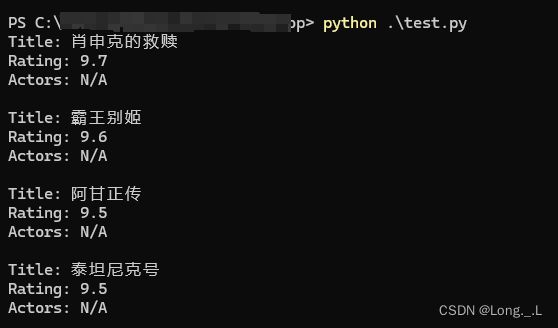
代码解释:
这段Python代码定义了一个函数fetch_movie_data()用于从豆瓣电影Top250页面抓取电影数据,包括电影标题、评分以及主演信息,并打印这些信息。
下面是代码的详细解释:
-
导入必要的库:
requests:用于发送HTTP请求。BeautifulSoup:用于解析HTML文档。
-
定义
fetch_movie_data函数:- 设置目标URL为豆瓣电影Top250页面。
- 设置请求头
headers,其中包含一个模拟浏览器的User-Agent字符串,这是为了绕过网站可能的反爬虫机制。
-
发送GET请求并解析HTML:
- 使用
requests.get方法发送GET请求到指定URL,获取响应文本。 - 使用
BeautifulSoup解析响应文本,创建一个soup对象,这个对象可以用来解析和提取HTML元素。
- 使用
-
提取电影信息:
- 使用
soup.find_all找到所有的电影条目,每个电影条目是一个div标签,类名为item。 - 对于每部电影,使用
find方法来查找特定的信息:- 电影名称:查找类名
title的span标签。 - 评分:查找类名
rating_num的span标签。 - 信息:查找
div标签下的p标签,此标签通常包含电影的年份、国家、类型及演员等信息。
- 电影名称:查找类名
- 从
info中提取主演信息,通过查找以"主演"开始的字符串,然后去除"主演:",并将所有主演名字用逗号连接起来。
- 使用
-
打印电影信息:
- 打印电影标题、评分和主演信息。
-
执行函数:
- 在
__main__模块下调用fetch_movie_data函数,执行抓取和打印操作。
- 在
注意事项
- 遵守网站规则 :在实际操作中,请确保你的行为符合目标网站的
robots.txt文件规定,不要对服务器造成过大负担。 - 动态加载内容:有些网站使用JavaScript动态加载内容,这可能需要使用如Selenium这样的工具来模拟浏览器行为。
- 错误处理:在实际应用中,应加入更完善的错误处理机制,比如重试策略、超时设置等。
漠漠水田飞白鹭,阴阴夏木啭黄鹂。