2 深度度量学习
有几种雷达应用程序旨在对一组预定义的类别进行分类,例如不同的人类活动或手势。然而,在实际环境中,存在的类不仅仅是预定义的类,这就把问题变成了一个开放集的分类任务。开放集分类意味着网络应该能够检测输入是否属于预定义或已知类之一。对于基于雷达的手势识别,这可能是随机的身体动作或手部动作,而不是手势,例如抓鼻子或伸手去拿一杯水。传统的深度学习分类器使用一个全连接层,并将softmax激活作为最终层,并使用交叉熵损失来训练网络。softmax 激活将类分数映射到已知类的概率分布。因此,已知类的概率加起来为 1。不考虑预定义类中没有的概率,这显示了softmax的闭集假设。这导致在已知类集上具有良好的分类精度,但在检测未知运动输入方面表现非常差。
解决此问题的一种方法是引入垃圾类。这需要训练不应归类为已知类之一的运动样本。然而,记录一个垃圾数据集几乎是不可行的,或者至少与非常大的努力有关,该垃圾数据集代表了现实世界环境中可能出现的所有可能的运动。更可取的做法是仅使用已知类来训练网络,以便它还能够检测输入何时不在已知类集中。为了实现这一点,网络必须学习非常特定于类和歧视性的类特征。实现这一目标的一种众所周知的方法是度量学习。深度度量学习旨在学习训练样本之间的关系或相似性。相似的样本(即同一类的样本)被拉到一起,而不同的样本(即两个不同类别的样本)被分开。通过这个学习概念,特征在特征空间中按类聚类。训练后,类集群紧凑且相距很远。因此,它作为类集群之间的间隙而出现。如果将输入样本投影到此间隙中,则可以将其检测为异常值,从而检测为未知输入类。
其余章节的结构如下:首先介绍度量学习,然后对最重要的度量学习技术进行一般理解和概述。图2.1中建议的分类法贯穿本章。我们将度量学习方法分为三大类,即成对方法、代理方法和端到端方法。成对方法根据不同训练样本之间的相似性学习指标,并需要后处理才能进行最终分类。在代理方法中,通过评估训练样本与相应的类代表性代理向量之间的相似性来学习度量,在端到端方法中,将度量的学习集成到神经网络中,并直接输出分类结果。这三种主要方法中的每一种都可以处理不同的概念,如图2.1所示,例如使用基于边距的优化或类内和类间优化。图2.1中使用的术语在整章中介绍和解释。在本章的最后,介绍了基于雷达的手势传感应用和度量学习的积极影响。
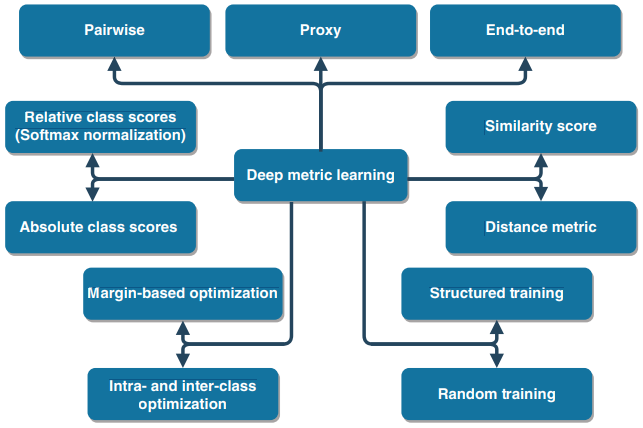
图2.1 深度度量学习方法的分类。
2.1 介绍
度量学习的目的是学习数据集中样本之间的关系或相似性。一个非常常见的学习指标是马氏距离,因为它与许多其他指标(如欧几里得距离)不同,具有可调参数。马氏距离定义如下:
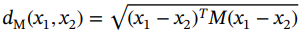 (2.1)
(2.1)
其中M是正定矩阵。矩阵M的条目可以根据特定目标进行优化。由于M是对称的和正定的,因此可以将其拆分为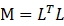 ,并将马氏距离重新表述如下:
,并将马氏距离重新表述如下:
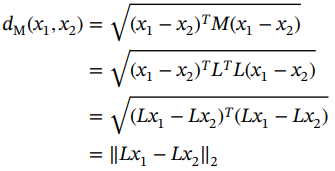 (2.2)
(2.2)
这意味着它等于线性变换输入向量x1和x2的欧几里得距离。对于深度度量学习,这种线性变换被由神经网络执行的非线性映射f(x)所取代,如方程(2.3)所示。因此,对于深度度量学习,目标是调整整个神经网络的参数,使简单的距离度量(如欧几里得距离)很好地描述数据的相似性。
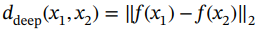 (2.3)
(2.3)
在本书中,我们重点关注分类任务的监督深度度量学习。因此,相似性变得离散。相似样本是同一类的样本,不同样本是不同类的样本。因此,在监督分类问题的离散世界中,目标是样本到其真实类中心的距离应明显小于到其他类中心的距离。理想情况下,类之间应该有一个余量。从广义上讲,任何损失函数由距离或相似性约束给出的方法都可以被视为度量学习1。
2.2 成对方法
成对度量学习方法是学习样本本身之间的相似性。因此,各个损失函数总是考虑两个或多个样本(图2.2)。
2.2.1 对比损失
Chopra等人2于 2005 年提出了最早的深度度量学习方法之一。损耗是根据一对样本计算的。一对中的样本要么来自同一类,要么来自不同的类。如果样本来自同一类,则目标是最小化两个特征向量之间的距离;但是,如果样本来自不同的类别,则目标是最大化其各自特征向量之间的距离。对比损失函数定义如下:
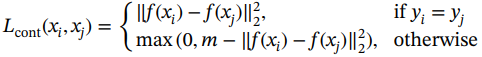 (2.4)
(2.4)
其中m是一个超参数,在两个不同的样本之间引入最小的所需边距。
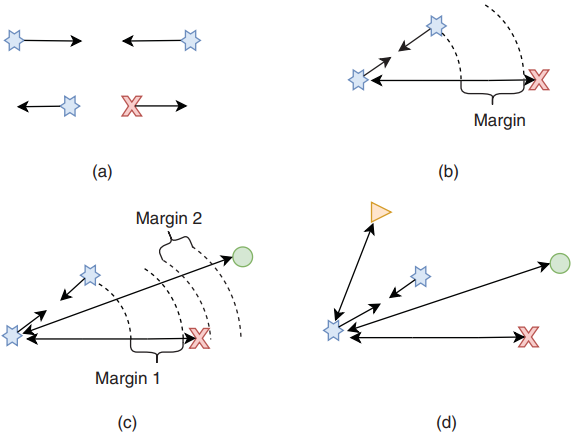
图2.2 样本之间的度量学习损失概述。(a)对比损失,(b)三重损失,(c)四重损失和(d)N对损失。
2.2.2 三重损失
三重损失与上述对比损失密切相关。三重学习的想法最早由Schroff等人于2015年发表3。目标保持不变。最小化同一类样本之间的距离,将其他类的样本推开超过一定阈值。不同之处在于损失函数是在三元组而不是一对样本上计算的。三元组由锚点、正样本和负样本组成。锚点是实际的训练样本,正样本是同一类的另一个样本,负样本是来自任何其他类的样本。损失函数定义如下:
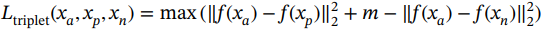 (2.5)
(2.5)
其中 m 是锚点和负样本之间至少需要的边距。三重学习方法高度依赖于选择好的正样本和负样本例子。
2.2.3 四重损失
四重损失4将三重损失扩大了另一个负样本。额外的负样本不仅来自另一个类作为锚点,而且来自另一个类作为负样本。四重损失使用锚点和正样本d(xa,xp)、锚点和负样本d(xa,xn)以及负样本和负样本d(xn,xm)之间的距离。四重损失的第一部分与使用d(xa,xp)和d(xa,xn)的三重损失完全相同。然而,四重损失的想法是增加一个辅助任务,即两个负样本之间的距离也必须大于锚点和正样本之间的距离。锚点和正样本d(xa,xp)之间的距离表示类内距离,而负样本之间的距离d(xa, xn)或d(xa, xn)表示类间距离。通过附加损失项,不仅可以确保正样本之间的类内距离小于到负样本的距离,而且可以确保类内距离小于任意类对之间的类间距离。损失目标制定如下:
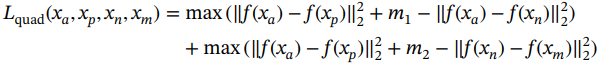 (2.6)
(2.6)
其中m1和m2 是两个独立的边距参数。4的作者指出,样本的正确顺序仍然由损失函数中的三重态部分获得。附加项是一项辅助任务,可以帮助进一步增加类间距离并提高测试数据的性能。因此,辅助损耗项对训练的影响不应与三元组损耗部分相同。因此,作者建议选择边距,使m2<m1。
2.2.4 N-对损失
N对损失5甚至比四重损失更进一步,并考虑了多对负样本。这背后的原因是,在三重态损失中,只使用一对正样本和一对负样本,单对负样本不足以代表所有负样本类。换句话说,只有一个类内距离,在每个三元组中表示,但有许多可能的类间距离,因为有许多不同的类,其中只表示许多可能性中的一种。如果偶然随机选择的类间距离很大,则满足三重损失,尽管可能有许多来自其他负样本类的示例太接近了。三重损失的希望是,在大量的三元组中,所有类最终都得到了代表。然而,这需要非常多的三元组,并且与每次不同的类间距离相比,类内距离仍然不平衡。N对损失的损失目标如下:
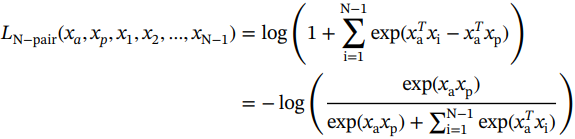 (2.7)
(2.7)
请注意,这是方程(2.13)第2.3节中介绍的多类分类的softmax损失
2.2.5 总结
除了所提出的基本成对度量学习方法外,文献中还存在许多扩展和变化,例如磁体损失 6、结构损失 7、聚类损失 8、混合损失 9 或多相似性损失 10 等等。这些方法的详细概述可以在 11 中找到。成对方法显示出非常好的结果,并引起了很多关注。但是,他们也遇到了一些问题。单对或三元组对数据的表示非常差,这就是为什么随着时间的推移,建议考虑越来越多的样本。第一种方法是对配对进行研究,然后Schroff等人引入了三元组,之后提出了四元组,最后,N对损失建议将N个样本考虑在内。样本越多,数据就越能代表;但是,它带来了另一个问题。随着样本数量的增加,组合的可能性正在爆炸式增长。此外,许多组合是糟糕的训练对或三元组。这就是为什么甚至提出了三元组生成和寻找硬负样本三元组的策略。
此外,成对方法学习的不是分类本身,而是数据中的相似性。当然,相似性的定义是预定义为监督信息。如果我们根据分类任务定义相似性,那么相似性会根据类而离散。属于同一类的样本相似,不同类的样本不同。两者之间没有任何关系。由于这种离散的相似性,网络学习将嵌入的特征投射到分离良好且紧凑的类集群中。但是,网络不会预测任何类分数,因此需要进行后处理。该网络的训练方式是欧几里得距离很好地代表了数据样本的相似性。因此,将训练网络扩展到分类器的一种非常常用的方法是K最近邻(K-NN)分类器。它将测试样本分配给其K最近邻中的优势类。
请注意,在本书中,我们将从分类的角度讨论成对度量学习方法。然而,我们想指出的是,在不同的应用中,这些方法也显示出很好的结果,例如图像检索任务12‒14。