6,dropout
6,1 线性分类器中的正则化
在线性分类器中,我们提到过正则化,其目的就是为了防止过度拟合。例如,当我们要用一条curve去拟合一些散点的数据时,常常是不希望训练出来的curve过所有的点,因为这些点里面可能包含噪声。如果,拟合出来的函数曲线真的能过所有的点,包括噪点,往往不是人们期望中的那条最佳curve。
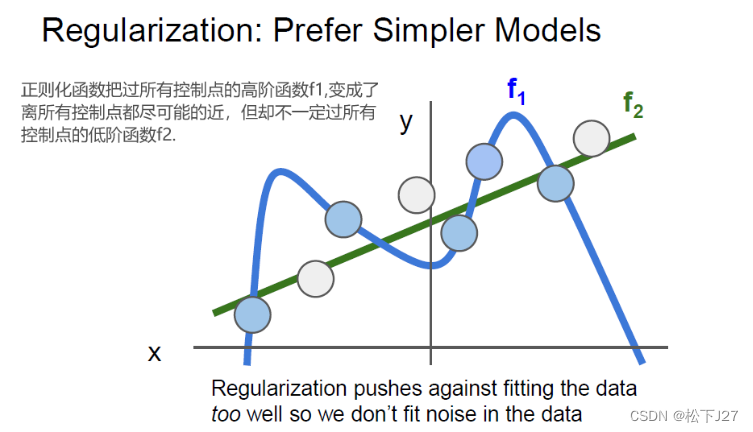
对于深度学习而言,过度拟合还好带来另一个问题,就是弱化泛化能力。说白了就是训练好的模型只在部分数据上表现良好,在其他的一些数据上的表现就没那么好。比如说,在下图的左图中随着迭代次数的增加,损失函数的值越来越低,说明训练的模型准确率越来越高。但把这个训练好的模型放在测试集上,随着迭代次数的增加,训练集的准确率越来越高,但验证集的准确率一直没变。
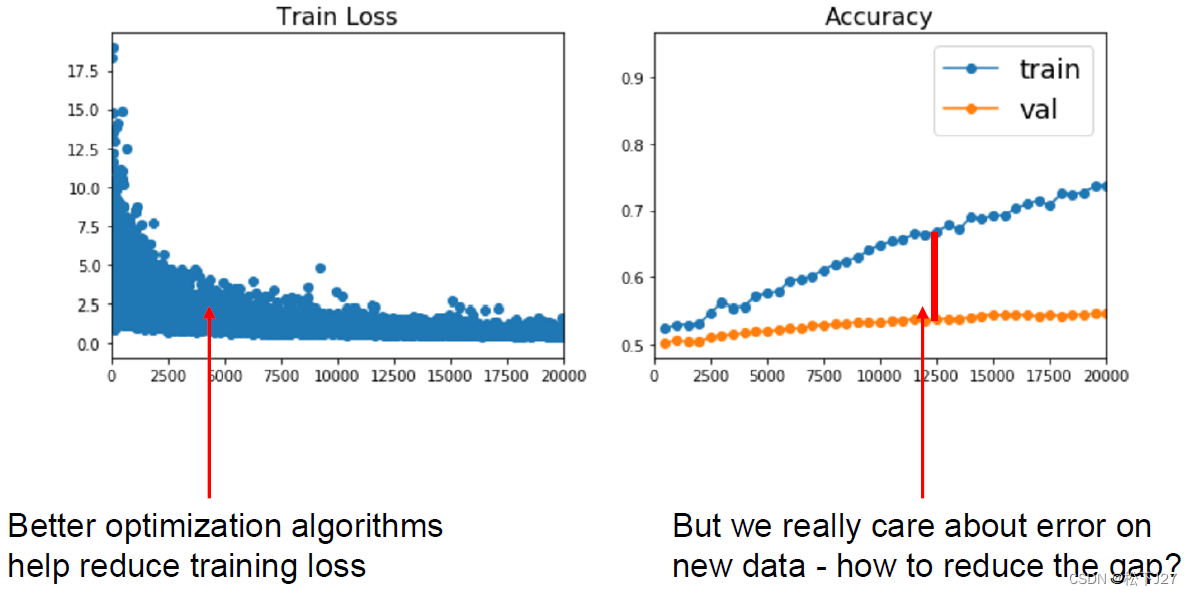

在线性分类器中,为了避免这一问题,通过在损失函数中加入了正则化项达到目的。

6,2 神经网络中的正则化---drop out
除了上面提到的L1,L2正则化,在神经网络中还有一种更为强大且常用的正则化方法---dropout他们都是为了防止过拟合。
Dropout 的原理:
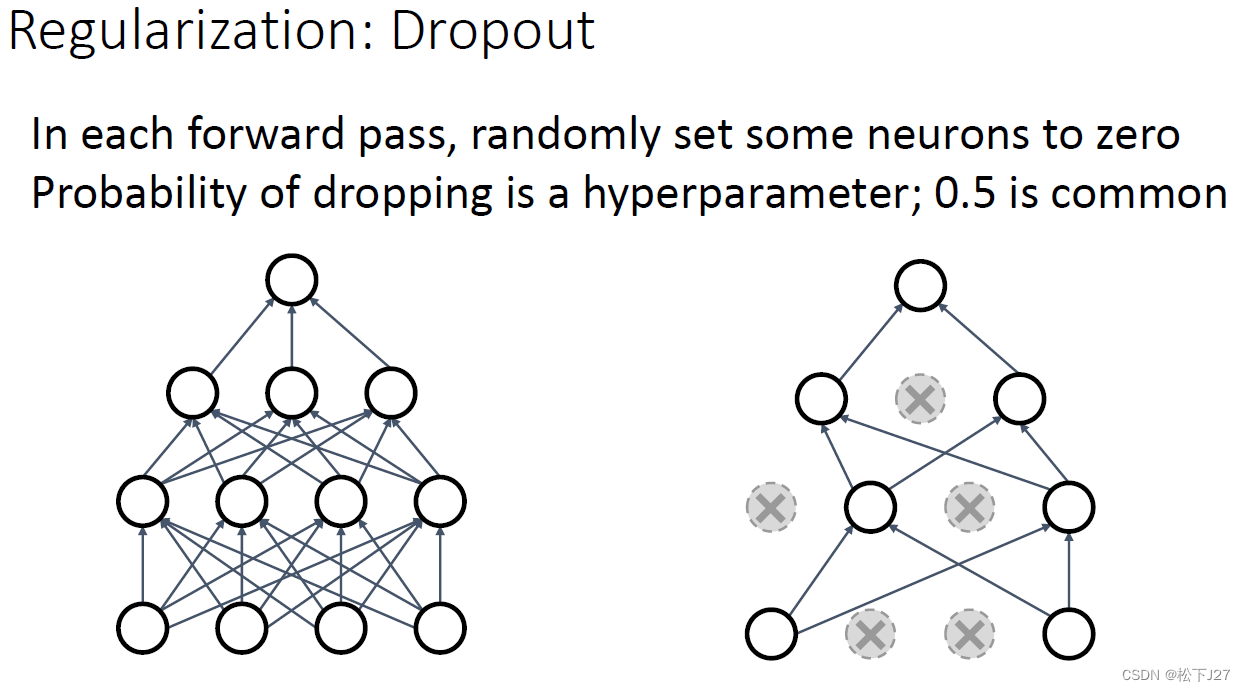
dropout通过在训练过程中以一定概率"丢弃"神经元,即,选择性的令一部分神经元的输出为0。神经元的丢弃概率通常选择在0.2到0.5之间,具体值需要根据具体的任务和数据集进行调优。 在不同层应用不同的丢弃概率。
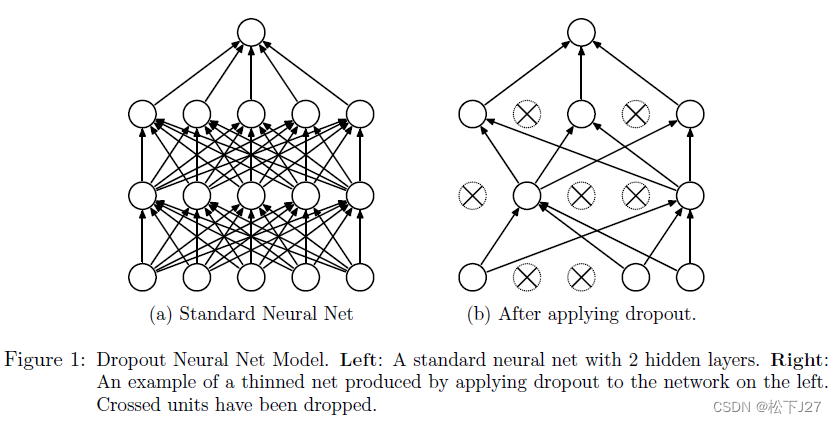
他打破了每层神经网络中的co-adapting(协同适应性),即,神经元之间的相互依赖。co-adapting会引起模型在训练数据上表现很好,但在新数据上表现不佳。且增加了不同神经元所学习到的特征的相似性。
具体实现:
1,在训练阶段,每个神经元以概率p被随机丢弃,丢弃的神经元在当前迭代中不参与计算。这样,每次迭代都使用一个不同的"子网络"。
2,在测试阶段:所有神经元都参与计算,但为了保持输出的预期值一致,需要将每个神经元的输出按丢弃概率p进行缩放(乘以1-p)。

引起co-adapting的原因:
在训练的过程中,每层神经网络中的全部神经元是通过一同更新来缩小损失函数的。换句话说就是所有的神经元协同作用并肩作战,而不是单打独斗。这就是说,对于每个隐含层而言,是整层神经元反映/学习了一个feature,而不是一层中的单个神经元反映/学习了一个feature。
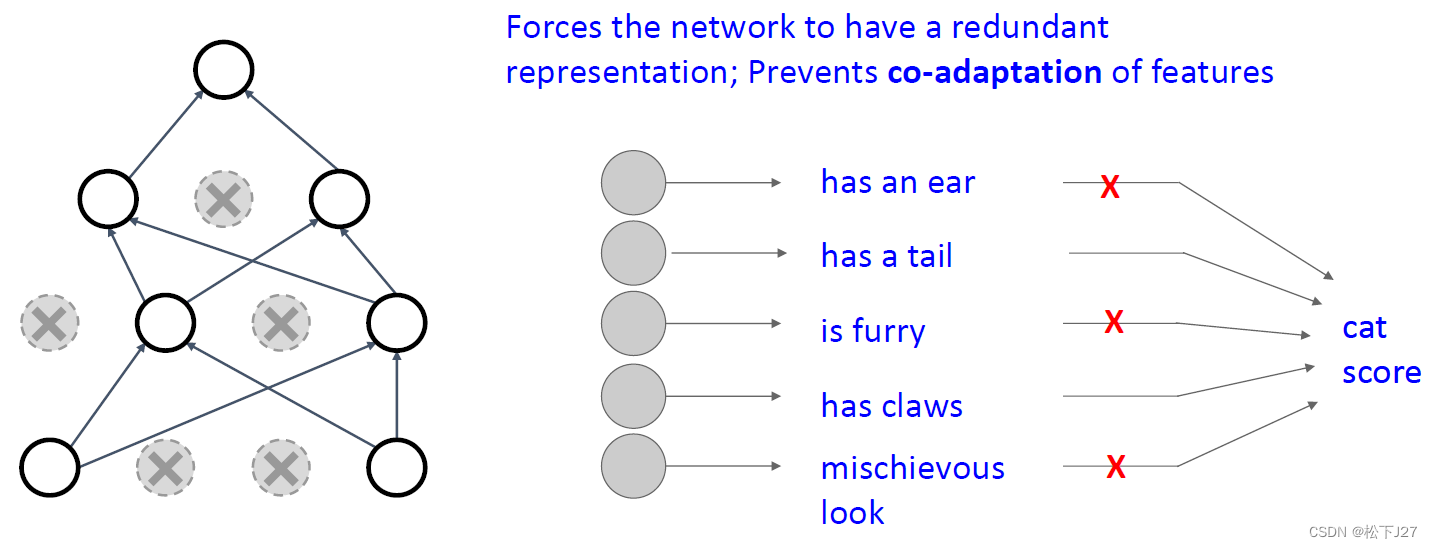
dropout通过随机丢弃神经元,迫使模型在训练的时候不能靠整层神经元去学习,而是需要每个神经元独立地处理输入数据。
这能增加了不同神经元所学习特征的多样性。下面是使用dropout技术前后神经元学习到的feature的差异。

过拟合的原因:
由于深层神经网络的学习功能十分强大,因此,在训练数据集的学习过程中,除了学习我们期望的部分,还会学习到噪声。这就会引起过度拟合,使得模型在训练数据上表现良好,但在新数据上表现不佳。
局限性:
Dropout并不是解决所有过拟合问题的万能方法,有时也需要结合其他正则化方法(如L1、L2正则化)或者数据增强等技术。
使用dropout会增加训练时间,因为每次训练迭代都要随机丢弃神经元并重新计算网络的前向和反向传播。
(全文完)
--- 作者,松下J27
参考文献(鸣谢):
1,Stanford University CS231n: Deep Learning for Computer Vision
3,10 Training Neural Networks I_哔哩哔哩_bilibili
4,Schedule | EECS 498-007 / 598-005: Deep Learning for Computer Vision
5,《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》
**版权声明:**所有的笔记,可能来自很多不同的网站和说明,在此没法一一列出,如有侵权,请告知,立即删除。欢迎大家转载,但是,如果有人引用或者COPY我的文章,必须在你的文章中注明你所使用的图片或者文字来自于我的文章,否则,侵权必究。 ----松下J27