1、Text-Animator: Controllable Visual Text Video Generation
中文标题:Text-Animator:可控视觉文本视频生成


简介:视频生成是各行业中具有重要价值但同时也极具挑战性的任务,例如在游戏、电子商务和广告领域。在文本到视频(T2V)生成中,一个关键的未解决问题是如何有效地将文本可视化到生成的视频中。尽管在T2V生成方面已经取得了一些进展,但现有方法主要着眼于总结语义场景信息和描绘动作,而无法直接有效地将文本可视化到视频中。
虽然图像级别的视觉文本生成技术最近有所进步,但要将这些技术转化到视频领域仍面临诸多挑战,特别是在保留文本保真度和动作连贯性方面。
为了解决这些问题,作者提出了一种创新的方法,称为Text-Animator,用于生成具有可视化文本的视频。Text-Animator包含一个文本嵌入注入模块,能够精确地描述生成视频中的视觉文本结构。此外,还开发了相机控制模块和文本细化模块,通过控制相机移动和可视化文本运动,提高了生成视觉文本的稳定性。
定量和定性实验结果表明,Text-Animator在生成视觉文本的准确性方面优于最先进的视频生成方法。项目详情可在 https://laulampaul.github.io/text-animator.html 查看。
2、Fast and Uncertainty-Aware SVBRDF Recovery from Multi-View Capture using Frequency Domain Analysis
中文标题:使用频域分析从多视图捕获中快速且具有不确定性感知的 SVBRDF 恢复
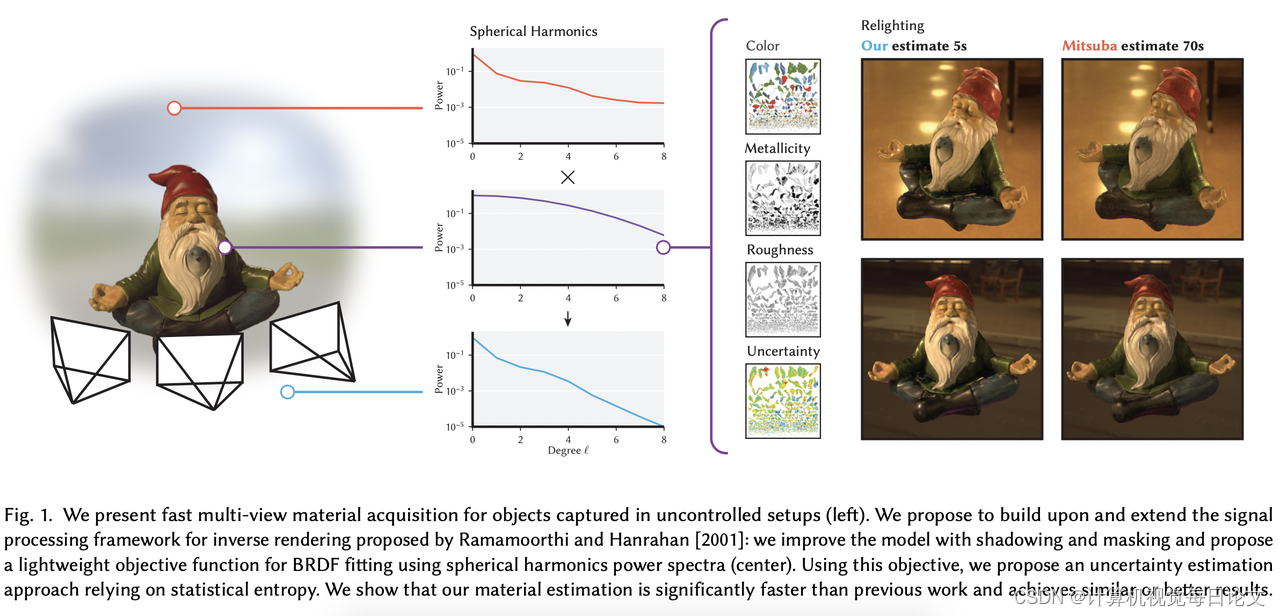
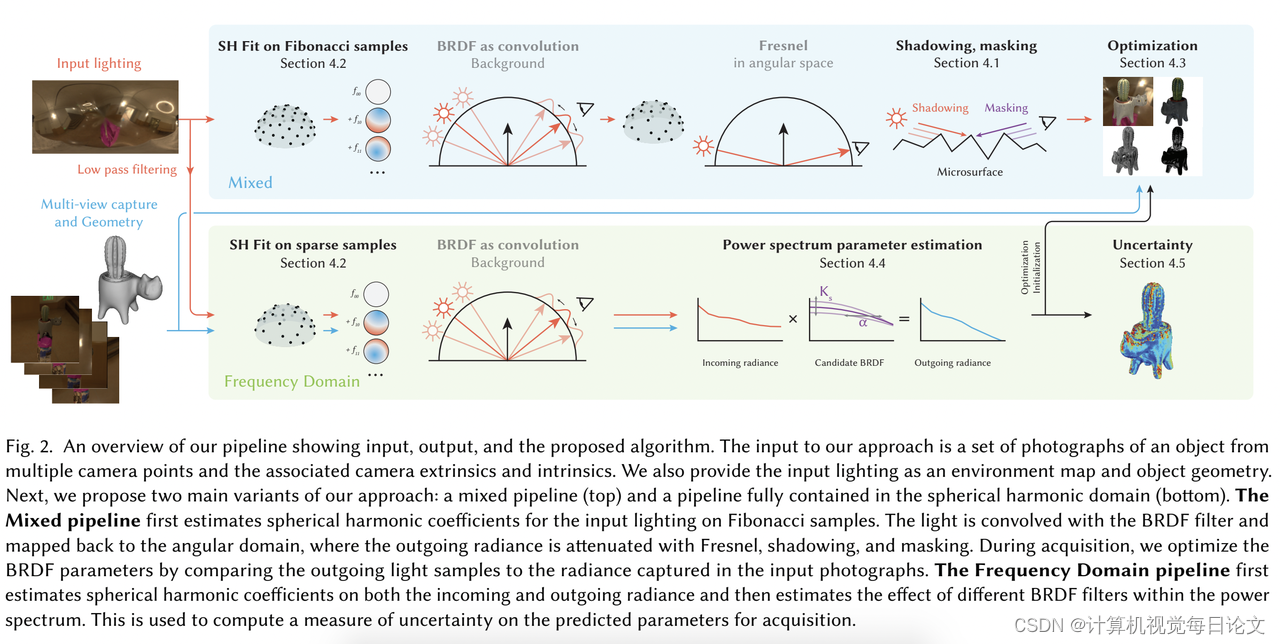
简介:数字资产创建中的一大挑战是获取可重建物体的信息。通常需要在受控照明下使用专业设备拍摄数百甚至数千张照片,才能完整重建一个物体。然而,在非结构化的视角和无法控制的照明条件下,观察到的信息可能不足以重建物体的外观属性。
为解决这一问题,我们提出了一种基于信号处理的获取方法。给定物体几何信息和照明环境,我们可以在几秒内估计出物体表面材料属性。我们利用频域分析,将材料属性恢复视为一种去卷积问题,从而实现快速的误差估计。接下来,我们根据可用数据量量化估计结果的不确定性,突出那些需要先验信息或额外样本以提高获取质量的区域。
我们将我们的方法与以往的工作进行了比较和定量评估。结果表明,我们的方法在使用极少的时间就能达到与之前工作相似的质量,并且还能提供关键的结果确定性信息。
3、MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
中文标题:MG-LLaVA:迈向多粒度视觉指令调整
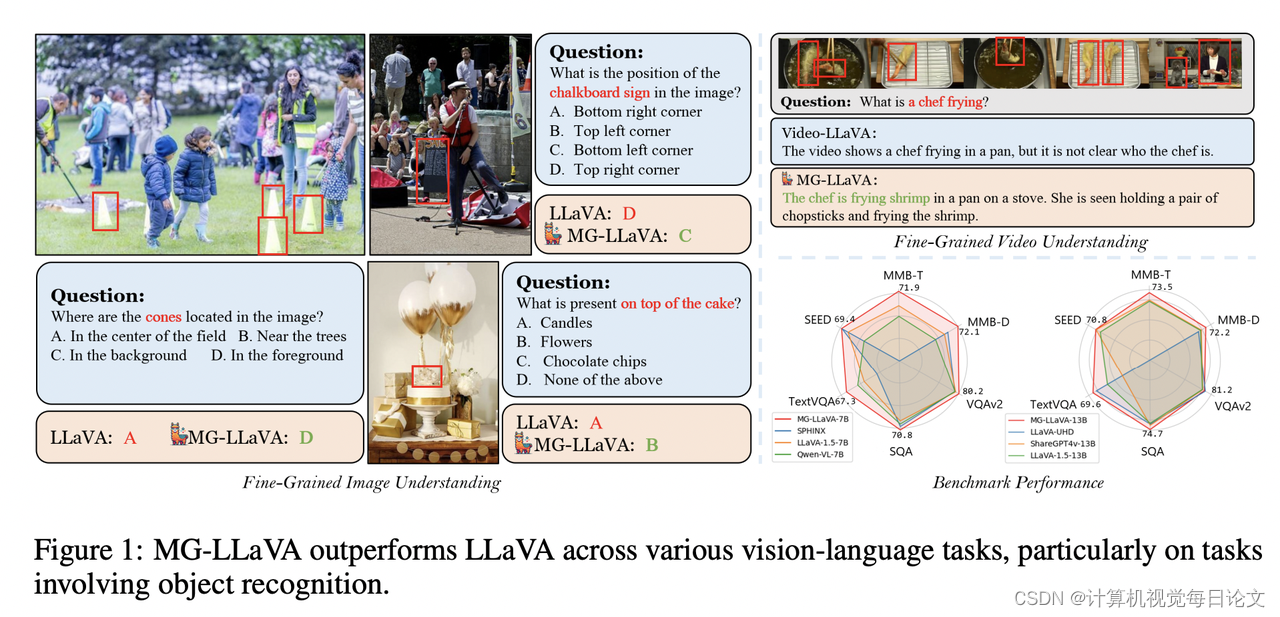
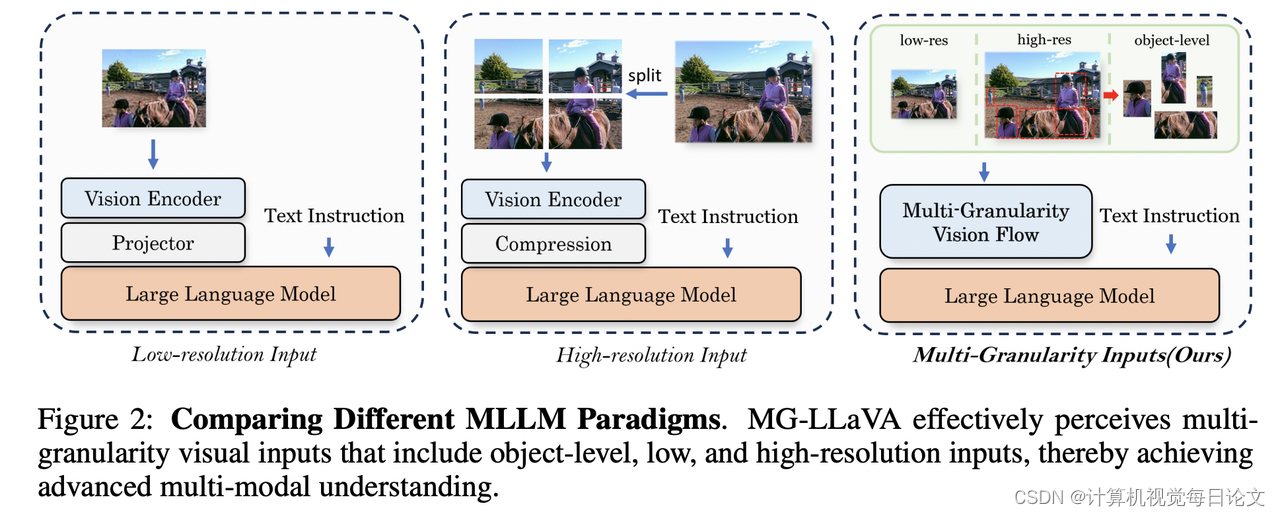
简介:多模态大语言模型(MLLMs)在各种视觉理解任务中取得了显著进展。然而,大多数这些模型仅能处理低分辨率图像,这限制了它们在需要详细视觉信息的感知任务中的有效性。
为了解决这个问题,我们提出了MG-LLaVA,这是一种创新的MLLM。MG-LLaVA通过整合多粒度视觉特征(包括低分辨率、高分辨率和以对象为中心的特征),增强了模型的视觉处理能力。具体来说,我们添加了高分辨率视觉编码器来捕捉细节信息,并通过Conv-Gate融合网络将其与基础视觉特征相融合。为了进一步提高对象识别能力,我们还结合了离线检测器识别出的边界框提取的对象级特征。
MG-LLaVA仅通过指令调整在公开可用的多模态数据上进行训练,就展示了出色的感知能力。我们使用从3.8B到34B不等的各种语言编码器实例化了MG-LLaVA,并进行了全面的性能评估。广泛的基准测试结果表明,MG-LLaVA在参数量相当的情况下优于现有的MLLMs,展现了显著的效果。
我们将在 https://github.com/PhoenixZ810/MG-LLaVA 上开源MG-LLaVA的代码实现。