
深入解析了中国AGI(人工智能)的发展趋势,并清晰地展示了其市场分层结构。
**
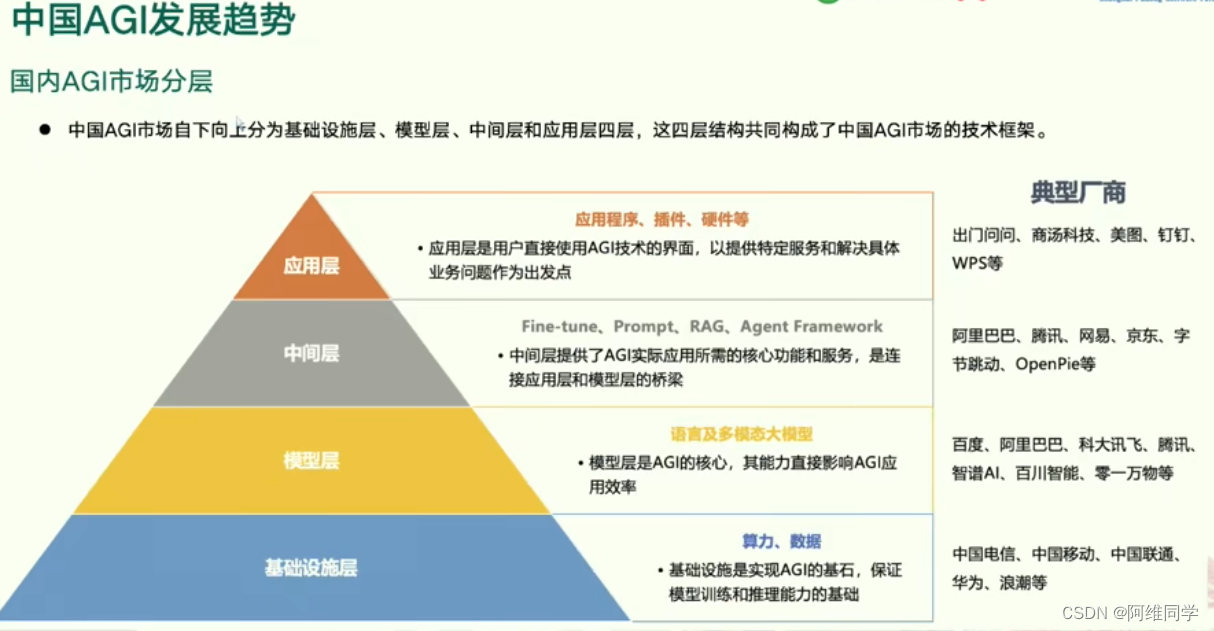
从下至上,AGI市场被划分为四个主要层级:基础设施层、模型层、中间层和应用层。
基础设施层作为最底层,为AGI的发展提供了坚实的基石。它涵盖了算力、数据等核心资源,确保模型训练和推理的高效进行。在这一层级,中国电信、中国移动、中国联通、华为、浪潮等厂商发挥着关键作用。
模型层位于中间,是AGI技术的核心所在。它专注于语言及多模态大模型的开发,这些模型的能力直接影响AGI在应用层和业务层的表现。百度、阿里巴巴、科大讯飞、腾讯、智谱AI、百川智能、零一万物等厂商在这一领域具有显著优势。
中间层则连接了应用层和模型层,提供了AGI实际应用所需的核心功能和服务。这一层级涵盖了应用程序、插件、硬件等,旨在为用户提供特定服务和解决具体业务问题。出门问问、商汤科技、美图、钉钉、WPS等厂商在这一层级中扮演着重要角色。
应用层作为最上层,是用户直接使用AGI技术的界面。它涵盖了Fine-tune、Prompt、RAG、Agent Framework等技术,为用户提供丰富的服务和应用。阿里巴巴、腾讯、网易、京东、字节跳动、OpenAI等厂商在这一层级中展现了强大的实力。
通过这种分层结构,我们可以清晰地看到AGI技术的发展路径和市场布局。从基础设施到应用层,每一层级都承载着不同的功能和角色,共同推动着AGI技术的不断进步和广泛应用。
**
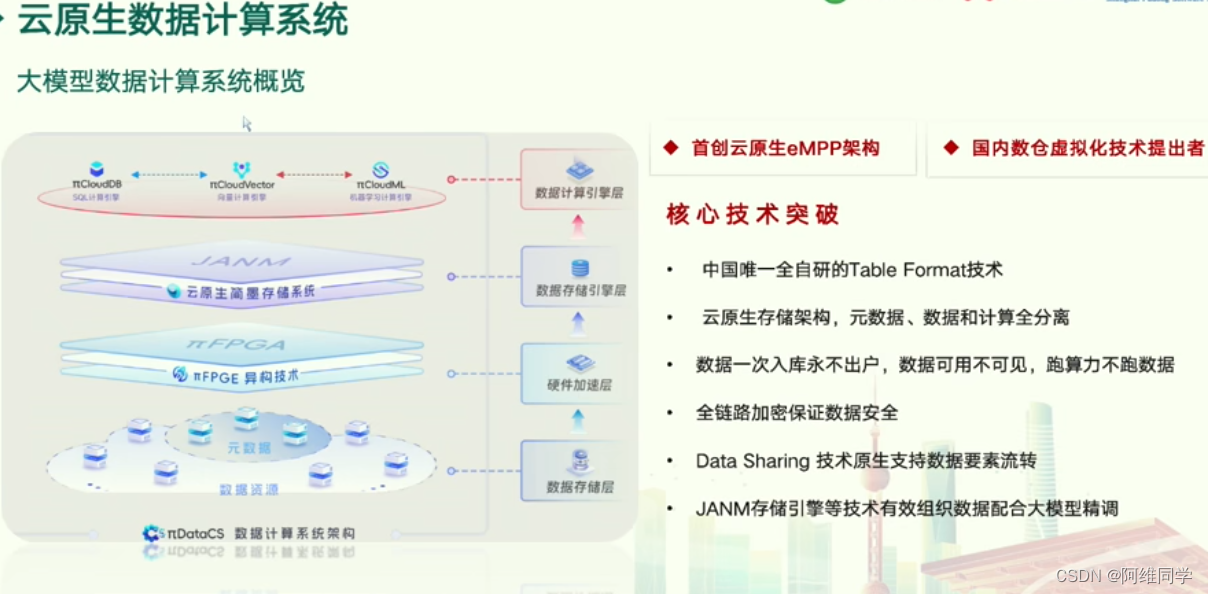
云原生数据计算系统"的架构及其技术突破。
**
该系统以云原生技术为核心,构建了一个从数据收集、处理、存储到应用服务的完整数据流。
- 系统采用了云原生基础设施作为底座,包括云原生存储、网络等关键组件,为数据处理提供了高效、可靠的基础。
- 在数据计算层,系统集成了多种数据计算框架,如Spark、Flink、Hadoop等,以满足不同场景下的数据处理需求。同时,系统还引入了首创的云原生eMPP架构,这是中国唯一自研的Table Format技术,极大地提高了数据处理效率和灵活性。
- 数据存储层采用了云原生存储架构,实现了元数据、数据和计算的完全分离。这种设计确保了数据的安全性,数据一旦入库便永不出户,同时实现了数据可用不可见,算力不随数据迁移,从而大大提高了系统的稳定性和可靠性。
- 在数据服务层,系统提供了数据湖、数据仓库、数据集市等多种服务,支持数据的共享和访问,促进了不同用户或应用程序之间的协作。此外,系统还采用了全链路加密技术,确保数据从源头到使用的全过程中都得到保护。
- 在数据智能层,系统利用人工智能技术和算法,从海量数据中提取有价值的信息和洞察,为决策提供有力支持。同时,系统还引入了Data Sharing技术,支持数据要素在多方之间安全流转和共享,进一步推动了数据的价值最大化。
- 在应用层 ,系统提供了丰富的数据应用和数据工具,帮助用户更好地利用数据资源,实现业务目标。
这个云原生数据计算系统通过集成多种先进技术和服务,构建了一个高效、可靠、安全的数据处理平台,为企业的数字化转型提供了有力支持。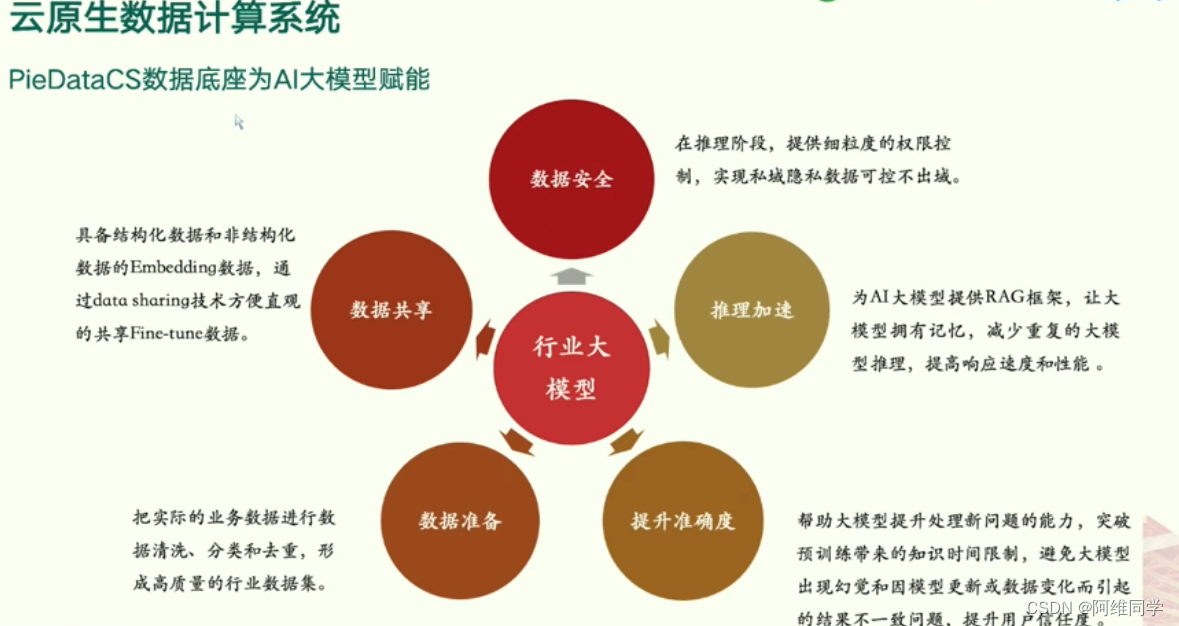
PieDataCS数据底座如何为AI大模型提供全面赋能。
- PieDataCS在推理阶段实施细粒度的权限控制,确保私域隐私数据的安全,防止数据泄露。其次,该系统支持结构化与非结构化数据的Embedding,通过先进的数据共享技术,实现数据的直观共享,促进数据流通。
- 在数据准备方面,PieDataCS能够处理实时的业务数据,通过数据清洗、分类和去重等步骤,构建高质量的行业数据集,为AI大模型提供精准的数据支持。此外,该系统还致力于提升AI大模型的准确度,通过优化算法和模型结构,突破预训练带来的知识时间限制,避免模型因数据变化或更新而产生的不一致问题,从而增强用户信任度。
- PieDataCS为AI大模型提供了RAG框架,使大模型具备记忆功能,减少重复的推理过程,显著提高响应速度和性能。这一创新技术使得行业大模型在处理复杂任务时更加高效和准确。
PieDataCS数据底座通过其强大的数据安全、数据共享、数据准备、提升准确度和推理加速等功能 ,为AI大模型提供了全方位的赋能,推动了行业大模型的发展和应用。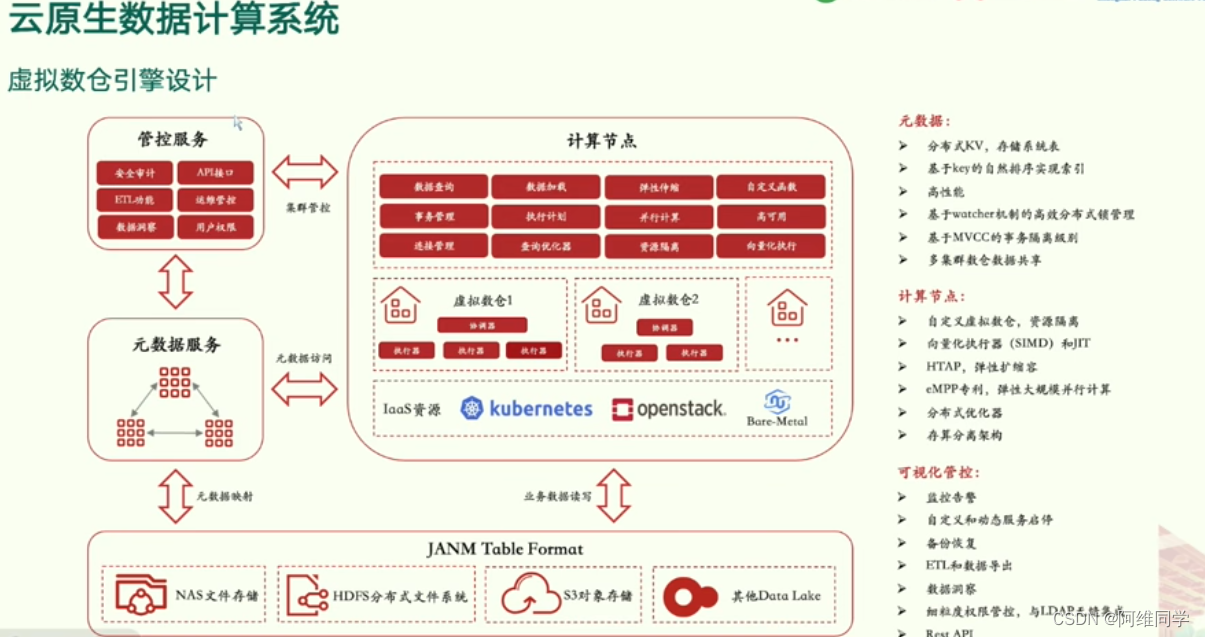
云原生数据计算系统的架构,特别是虚拟数仓引擎的设计。该系统集成了多个关键组件,旨在提供高性能、高可用性和灵活扩展性的数据处理能力。
- 元数据服务是系统的核心,它负责管控服务,包括安全管理、租户管理、用户管理、权限管理和审计服务等,确保数据的安全性和合规性。同时,元数据服务还提供元数据访问、审计和同步等功能,为整个系统提供统一的元数据视图。
- 计算节点是数据处理的核心部分,包括存储引擎和执行引擎。存储引擎负责数据的查询、解析、计算和分布式汇总等功能,确保数据的高效处理。执行引擎则负责SQL解析、查询优化和执行计划生成,优化数据处理流程,提高执行效率。
- 数据存储方面,系统采用了多种存储方案,包括MySQL用于元数据存储,HDFS分布式文件系统用于计算数据存储,以及Redis用于缓存数据存储。这些存储方案的选择旨在提供高效、可靠和可扩展的数据存储能力。
- 系统还提供了可视化查询功能,通过图形界面、自定义动态仪表板和实时仪表板等方式,为用户提供直观、便捷的数据查询和分析体验。
- 在技术栈方面,系统采用了Kubernetes进行容器编排和管理,OpenStack作为PaaS平台的基础,以及LuoShan等基础平台技术。这些技术栈的选择旨在提供稳定、可靠和高效的基础设施支持。
- 系统还具备多种特性,如分布式事务管理、多租户隔离、自定义函数(UDF)支持和计算存储分离等。这些特性使得系统能够支持复杂的数据处理场景,提供灵活、可扩展的解决方案。
- 总的来说,这个云原生数据计算系统架构图展示了一个全面、高效和灵活的数据处理平台,能够支持各种复杂的数据处理需求,为企业提供强大的数据支持能力。
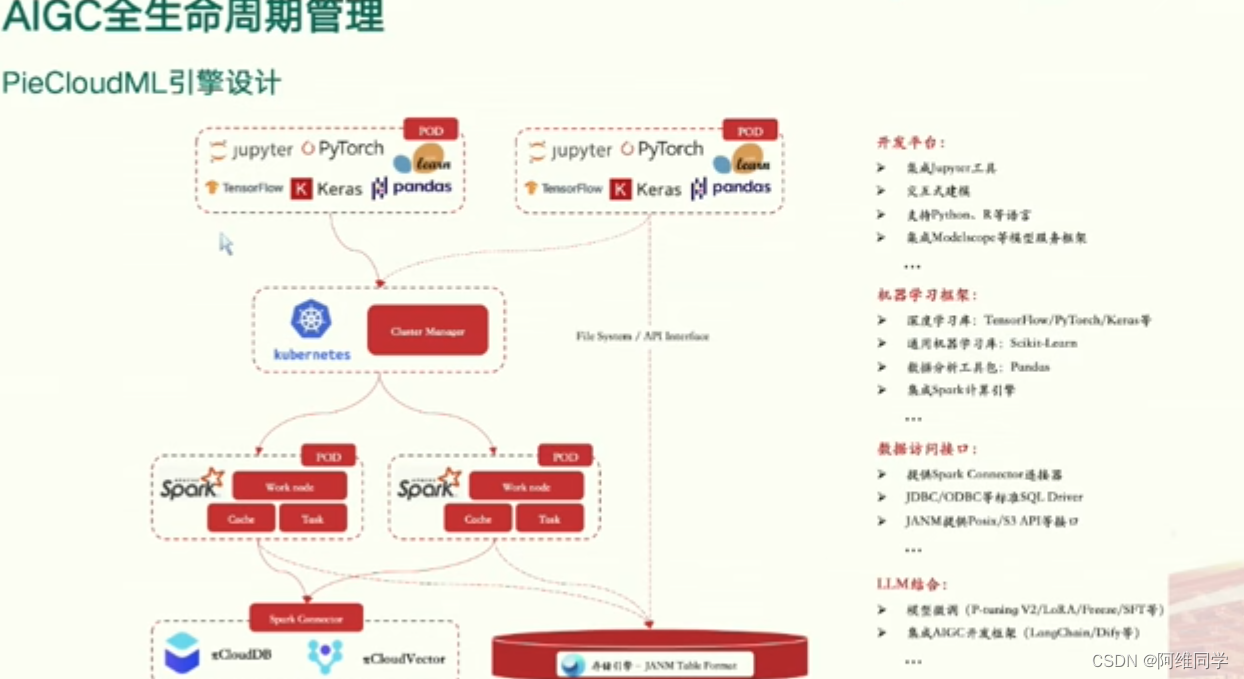
AIGC全生命周期管理的架构
**其核心在于PieCloudML引擎的设计。**整个架构通过集成多种工具和框架,如Jupyter、PyTorch、Kubernetes和Pandas等,形成了一个完整的数据科学和机器学习生命周期管理系统。
架构中包含了多个关键组件,如客户端管理器用于处理客户端请求,文件服务器用于存储和处理文件,Spark集群用于数据处理和分析,以及Kubernetes集群用于容器编排和管理。此外,模型服务器则负责机器学习模型的部署和管理。
- 在开发平台方面,Jupyter提供了创建和共享笔记本的便利,PyTorch则支持深度学习模型的开发,Pandas则用于数据处理和分析。同时,架构还集成了多种机器学习框架,如TensorFlow、PyTorch、Keras和Scikit-learn,以满足不同机器学习任务的需求。
- 数据访问接口方面,架构支持Spark Common Connectors、JDBC/ODBC等标准SQL驱动,以及Posix/53 API等接口,确保数据能够高效、安全地在各个模块间流动。
- 此外,架构还结合了LLM(大语言模型)技术,支持模型预测和部署,进一步提升了系统的智能化水平。同时,提供了JupyterLab、PyCharm、VSCode等开发工具,以及Git和Docker等版本控制和容器化工具,方便用户进行开发和部署。
- 在集群管理方面,Kubernetes和Spark分别负责集群管理和大数据处理,确保系统的高效运行和扩展性。数据存储方面,HDFS和Kafka分别用于大规模数据存储和实时数据流处理,满足不同的数据存储需求。
这个AIGC全生命周期管理架构通过集成多种工具和框架,形成了一个高效、可扩展、智能化的系统,为数据科学和机器学习领域的研究和应用提供了强大的支持。

AIGC(人工智能生成内容)全生命周期管理的MaaS(基础设施即服务)底座主流架构。
整个架构自上而下分为几个关键层次,每个层次都承载着不同的技术和工具,共同支持AIGC的全生命周期管理。
- 在应用层,我们可以看到一系列模型应用,如LLM(大型语言模型)、NLU(自然语言理解)、CV(计算机视觉)、NLP(自然语言处理)和Audio(音频处理),这些应用通过Python等开发语言进行开发,以满足各种AI应用需求。
- 接下来是生态层,这里包含了DeepSpeed、Magnum.LM、Caffe.AI、HuggingFace等生态框架,以及Large.Bench、HC.CloudVector等大模型工具,这些工具和框架共同构建了一个丰富的AI生态,为上层应用提供了强大的支持。
- 在框架层,PyTorch、TensorFlow、Caffe、Mindspore、JAX等AI框架以及Mapbox等地理引擎为开发者提供了灵活的构建选项,使得AI应用的开发更加高效和便捷。
- 编译层则包含了TVM、Glow、XLA、TensorRT等AI编译器和GCC等传统编译器,这些编译器负责将高级语言编写的代码转换为机器可以执行的指令,是AI应用从开发到部署的关键环节。
- 最后,基础架构层是整个架构的基石,包括TPU、GPU、NPU等AI芯片以及RDMA、IB、Ethernet等网络加速器,它们共同构成了强大的计算能力,为上层应用提供了坚实的硬件支持。此外,超级计算集群的引入进一步提升了整个架构的计算能力,使得AI应用能够处理更加复杂和庞大的数据。
整个架构图不仅展示了从应用层到基础架构层的各个组成部分及其相互关系,还强调了MaaS(一切即服务)的理念,即在云原生架构下,提供各种AI服务,以满足不同场景下的AI应用需求。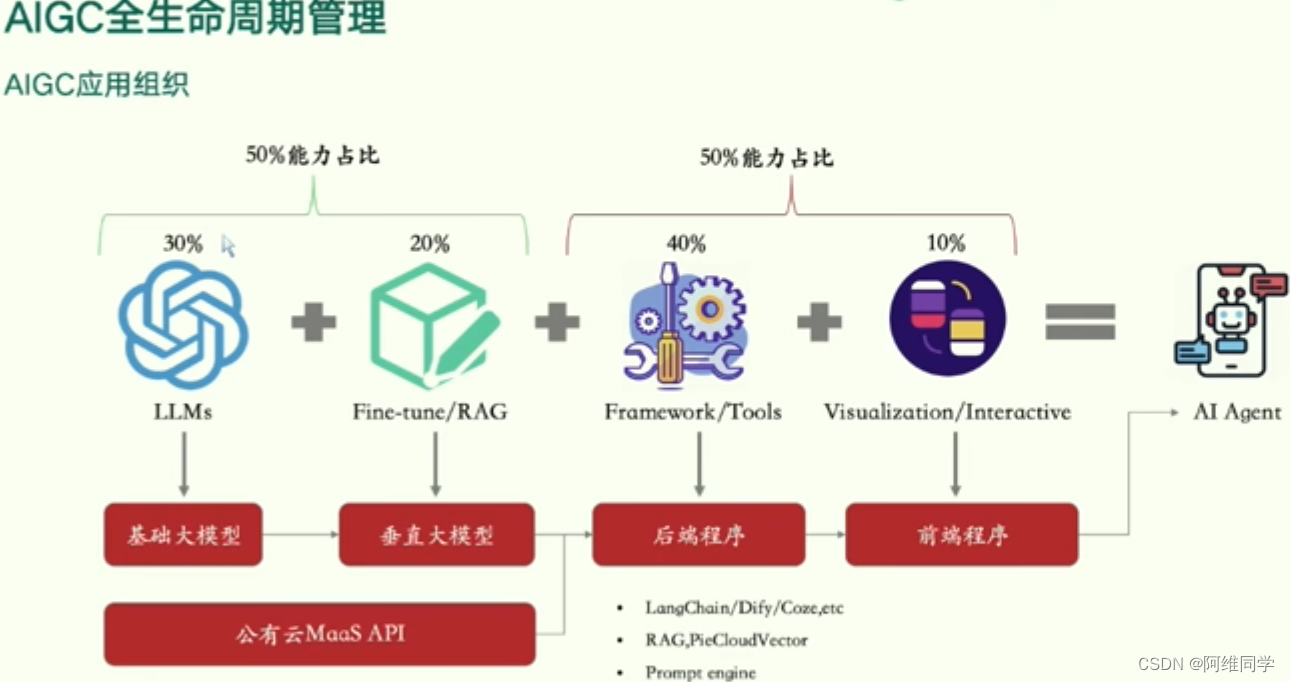
AIGC(人工智能生成内容)的全生命周期管理过程及其在组织中的应用结构
在AIGC的全生命周期管理中,首先涉及的是基础大模型 的构建,这主要基于LLMs(大型语言模型)。随后,为了满足特定领域的需求,会在基础大模型的基础上结合特定领域的知识和数据,形成垂直大模型。
进入模型训练阶段,后端程序利用Fine-tune/RAG等框架和工具对大模型进行微调或适应特定任务。同时,通过可视化或交互式的方式,前端程序展示后端程序的结果,并利用AI Agent进行用户交互。
在AIGC应用组织中,基础大模型、垂直大模型、后端程序以及前端程序各自占据50%的能力,而AI Agent则独立占据10%的能力,凸显了其在交互环节中的重要性。
技术栈方面,基础大模型依赖于公有云MaaS API,后端程序则采用LangChain、DeFi、Comexe等技术,前端程序则利用RAG、FeCloudVector等工具,而整个流程则由Prompt engine作为引擎驱动。
从基础大模型构建到前端程序应用的完整流程,强调了AI Agent在提升用户体验和交互效果中的关键作用。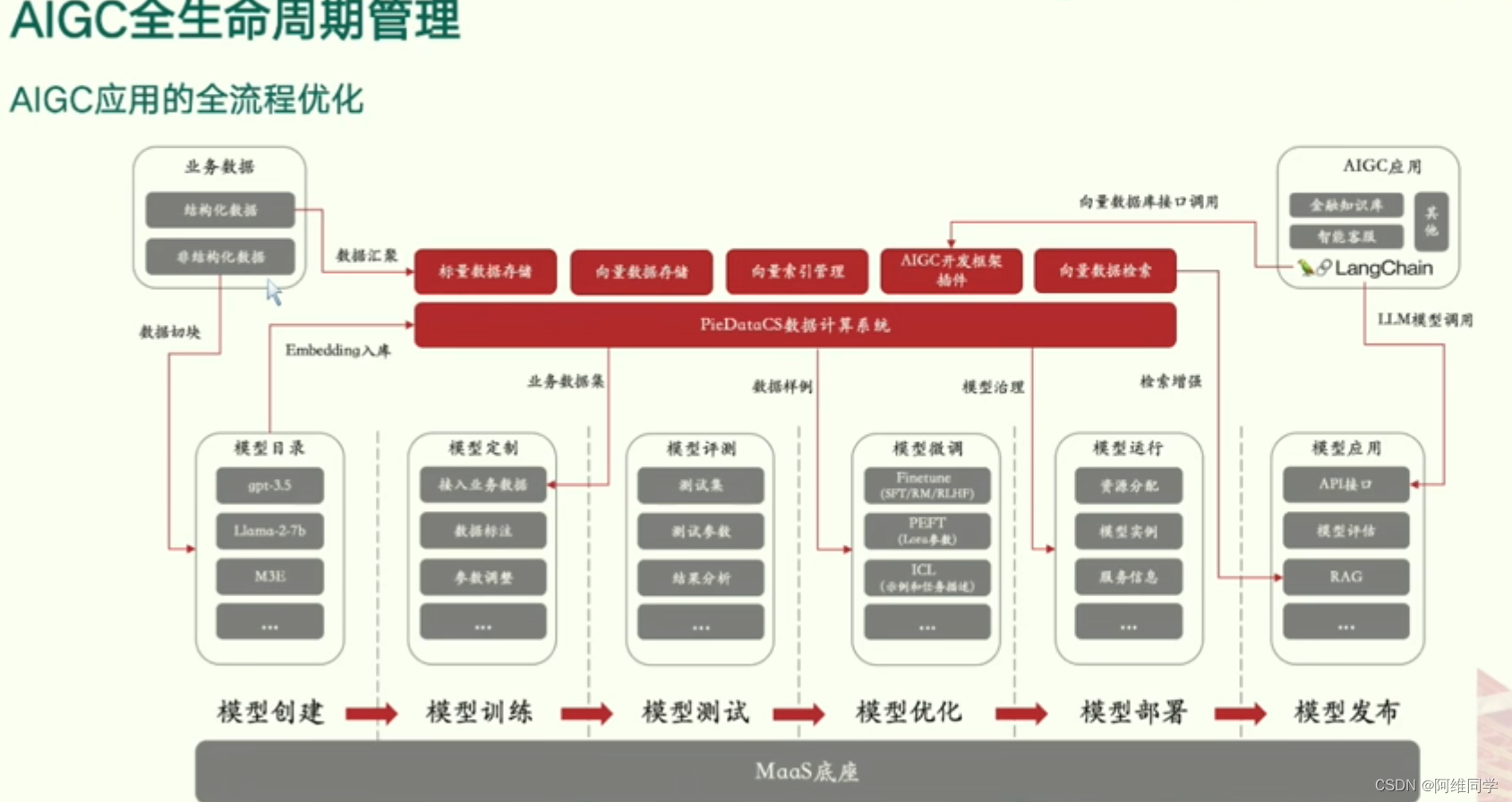
AIGC(人工智能生成内容)的全生命周期管理及其应用的全流程优化过程
整个流程从业务数据的收集开始,包括结构化数据和非结构化数据的处理,随后进入数据切分和汇聚阶段,确保数据的有效利用。
在数据准备阶段,数据被切分为适合模型训练的片段,并通过Embedding技术入库,形成业务数据集。同时,数据汇聚过程涉及标签数据存储、向量数据存储以及向量索引管理,为后续的模型开发和应用提供坚实基础。
AIGC开发框架作为核心,提供了丰富的插件支持,确保AIGC应用的顺利开发。通过向量数据库接口调用,AIGC应用能够接入金融知识库、智能客服等多个领域,实现广泛的应用场景。
在AIGC应用的全流程优化中,模型创建、训练、测试、优化、部署和发布等步骤紧密相连,形成了一套完整的模型生命周期管理流程。模型评测和微调环节通过测试集、测试参数和结果分析等手段,确保模型的性能达到最优。
此外,模型运行阶段涉及资源分配、模型实例以及服务信息的管理,确保模型在实际应用中能够高效、稳定地运行。
最后,图表还提到了模型应用的其他方面,如API接口、模型评估和RAG等,为模型的进一步应用提供了更多可能性。整个流程以MaaS(模型即服务)底座为基础,为AIGC的全生命周期管理和应用提供了强大的支持。
为AIGC的全生命周期管理和应用的全流程优化提供了清晰的指导,有助于相关团队更好地理解和实施AIGC项目。
欢迎大家关注阿维同学

VW:AWTX550W