
**©作者|**坚果
**来源|**神州问学
引言
马斯克巨资60亿美元打造的"超级算力工场",通过串联10万块顶级NVIDIA H100 GPU,不仅震撼了AI和半导体行业,促使英伟达股价应声上涨6%,还强烈暗示了AI大模型及芯片需求的急剧膨胀。这一行动不仅是马斯克对AI未来的大胆押注,也成为了全球企业加速布局AI芯片领域的催化剂,预示着一场科技革新竞赛的全面升级,各方竞相提升算力,争夺AI时代的战略高地。观察近期Blackwell与Gaudi 3芯片的设计优化路径,不难发现GPU芯片制造商已在不同程度上汲取了存算一体技术的精髓,尤其侧重于近存计算架构的采纳,以此直面大模型对高算力与高存储需求的挑战。
存算一体技术详解
存算一体(Computational Memory或In-Memory Computing)的概念并非新近才出现,而是计算机科学领域一个长期的研究方向。它的起源可以追溯到早期计算机架构的探索,旨在克服冯·诺依曼架构的局限性,特别是数据传输带宽瓶颈(通常称为"内存墙")的问题。
存算一体技术的过去和现在
追溯至上世纪80年代,存算一体的概念初现端倪,彼时研究者开始探讨如何在存储器内部直接进行计算,以减少数据在处理器与内存之间频繁移动带来的延迟与能耗。然而,受限于当时的材料科学与制造工艺,早期的尝试多停留在理论探索与初步原型阶段。进入21世纪,随着纳米科技、新材料与先进制造技术的飞速发展,存算一体技术迎来了突破性进展。新型非易失性存储器,如相变存储器(PCM)、磁阻随机存取存储器(MRAM)和电阻式随机存取存储器(RRAM),因其具备高速度、低功耗及非易失性等特点,成为实现存算一体的关键载体。这些存储技术不仅能够存储信息,还能在其存储单元上直接执行基本逻辑运算,从而大幅缩短数据传输距离,显著提升整体计算效能。近年来,存算一体技术在学术界与产业界均获得了广泛关注与投资,多家科研机构与企业已研发出原型产品。例如,英特尔的Optane DC持久内存结合了DRAM的高速度与NAND闪存的非易失性,展现了存算一体的部分潜力;而IBM、三星、惠普实验室等也在探索将存算一体应用于人工智能、大数据分析等领域,以期构建更高效能的计算平台。
存算一体技术原理和分类
存算一体芯片基本架构图所示,神经网络模型的权重可以映射为子阵列中存储单元的电导率,而输入特征图(Feature map)作为行电压并行加载(图中WL方向),然后以模拟方式进行乘法(即输入电压乘以权重电导),并使用列上的电流求和(图中BL方向)来生成输出向量。
图源:
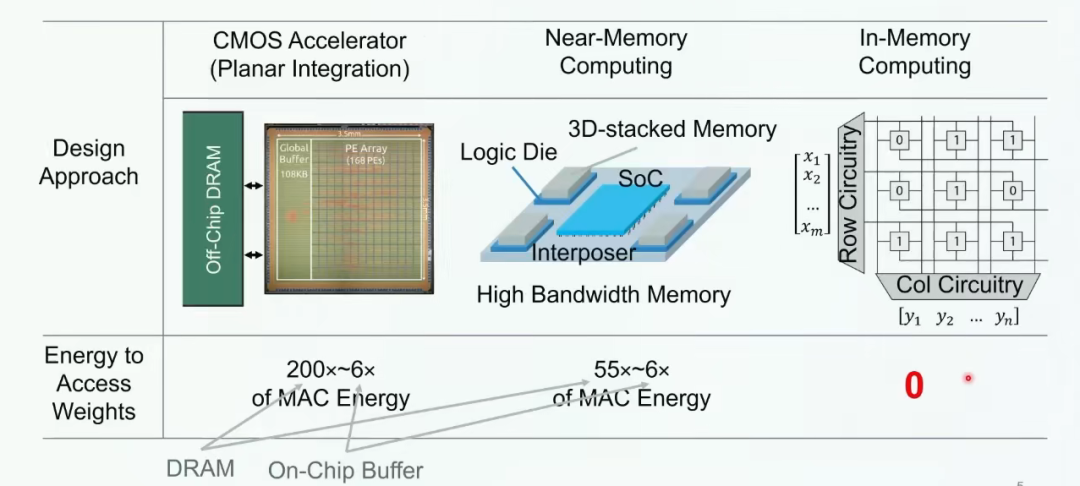
按照计算单元和存储单元的距离,存算一体技术大致分为近存计算(PNM)、存内处理(PIM)、存内计算(CIM)。
存内处理 则主要侧重于将计算过程尽可能地嵌入到存储器内部。这种实现方式旨在减少处理器访问存储器的频率,因为大部分计算已经在存储器内部完成。这种设计有助于消除冯·诺依曼瓶颈带来的问题,提高数据处理速度和效率。
近存计算 是一种较为成熟的技术路径。它利用先进的封装技术,将计算逻辑芯片和存储器封装到一起,通过减少内存和处理单元之间的路径,实现高I/O密度,进而实现高内存带宽以及较低的访问开销。近存计算主要通过2.5D、3D堆叠等技术来实现,广泛应用于各类CPU和GPU上。
存内计算 同样是将计算和存储合二为一的技术。它有两种主要思路。第一种思路是通过电路革新,让存储器本身就具有计算能力。这通常需要对SRAM或者MRAM等存储器进行改动,以在数据读出的decoder等地方实现计算功能。这种方法的能效比通常较高,但计算精度可能受限。
存算一体技术的最终目标是提供一种计算平台,它能够显著降低数据搬运的成本,提高计算效率,特别是在大规模并行计算和机器学习任务中展现出巨大的潜力。然而,这一领域的研究和开发仍面临诸多挑战,包括技术成熟度、可扩展性、成本和标准化等问题。
AI处理器架构参考近存计算原则
今年推出性能优化的两款高性能AI芯片,都不同程度优化了内存模块以拓展显存容纳更大规模的参数。
NVIDIA Blackwell
今年3月18日NVIDIA 在GTC宣布推出 NVIDIA Blackwell 架构以赋能计算新时代。

图源:
https://www.nvidia.cn/data-center/technologies/blackwell-architecture/
Blackwell 架构 GPU 具有 2080 亿个晶体管,采用专门定制的台积电 4NP 工艺制造。所有 Blackwell 产品均采用双倍光刻极限尺寸的裸片,通过 10 TB/s 的片间互联技术连接成一块统一的 GPU。Blackwell架构的GPU,作为高性能计算和AI加速器,参考近存计算的架构高度集成计算单元和存储单元。
Blackwell GPU以集成的 HBM3E内存为核心,实现8Gbps速度与8TB/s带宽,大幅缩减数据传输至计算单元的时间,有效降延迟、控能耗。其计算单元与内存的协同设计,确保了数据的快速访问与高效利用,破解数据传输瓶颈。结合Grace CPU的系统集成,更促进了计算与内存管理的无缝衔接,共享数据机制减少了跨资源传输,虽非存内计算,却通过内存与计算的紧密融合,实现了减少数据移动、提升计算效能的目标,与存算一体架构理念不谋而合。
Gaudi
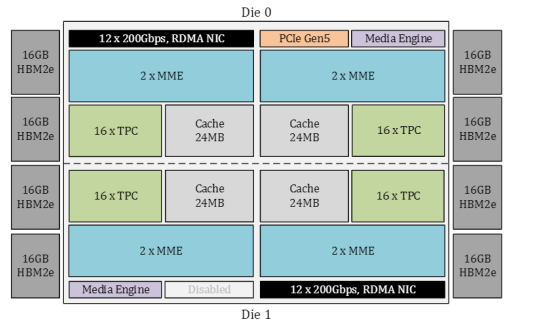
今年4月9日晚,英特尔在美国召开了"Intel Vision 2024"大会发布了Gaudi 3 AI芯片。Gaudi 3 拥有 8 个矩阵数学引擎、64 个张量内核、96MB SRAM(每个Tile 48MB,可提供12.8 TB/s的总带宽) 和 128 GB HBM2e 内存,16 个 PCIe 5.0 通道和 24 个 200GbE 链路 。在计算核心的周围,则是八个HBM2e内存堆栈,总容量为128 GB,带宽为3.7 TBps。训练性能比英伟达H100快了40%,推理快了50%。
图源:
Gaudi 3 AI加速器通过一系列优化,深刻诠释了近存计算的精髓。其搭载的128GB HBM2e内存,以超高的数据传输速率削减访问延迟;双计算集群Chiplet设计让计算贴近数据,减少移动距离;增强的网络带宽优化了分布式计算中的数据交换,有效降低节点间通信延迟;AI专用计算单元针对矩阵与卷积运算进行高效优化,间接促进数据访问效率。所有这些设计,均致力于减少数据移动,提升计算效能,完美呼应了近存计算减少延迟、降低能耗的核心目标。
其他
除了以上厂家其他厂家也采用了近存计算或类似架构原则。
AMD MI200系列 GPU:
AMD的Instinct MI200系列GPU采用了3D V-Cache技术,以及HBM2e内存,提供了高带宽数据访问,旨在减少数据传输延迟。
Groq Tensor Processing Unit (TPU):
Groq的TPU采用了独特的架构设计,其中包括了大规模的片上SRAM,以及高度并行的计算单元,旨在提供低延迟和高吞吐量的计算环境。
Graphcore IPU:
Graphcore的Intelligence Processing Units (IPUs) 设计有大规模的片上内存,以及分布式内存架构,以减少数据移动,提高机器学习模型的训练和推理速度。
存算一体架构解决大模型高算力高存储的需求
大模型高算力高存储需求的挑战
大模型计算任务对高算力的依赖源于其参数量的天文数字------如GPT-3的1750亿参数------以及数据密集型训练需求,后者涉及处理570GB规模的文本数据集。模型的深度与宽度、高维特征的处理、训练迭代中的权重更新,乃至分布式训练的协调,无一不在考验着系统的计算极限。此外,模型优化和探索阶段的资源消耗也不容小觑。为此,现代数据中心装备了高性能GPU、TPU及配套基础设施,旨在支撑这一计算盛宴。
高存储挑战则聚焦于显存的极限。大模型的海量参数,即便是采用FP16或BF16低精度表示,也需占用大量存储空间。前向与反向传播产生的中间结果、优化器状态维护、混合精度训练中的精度转换,以及批量处理和数据预处理阶段的临时数据生成,均显著提升了显存需求。尤其是模型推理阶段,面对长序列或高分辨率数据,显存消耗尤为突出。因此,诸如NVIDIA A100 GPU配备的80GB HBM2显存成为必要,以应对大规模模型的训练与推理需求。
存算一体架构优势
存算一体架构针对大模型运算的高算力和高存储需求,展现出了显著优势,通过在存储单元本地执行计算,极大地减少了数据在CPU和内存之间传输的延迟和能量损耗,从而大幅度提升了计算效率。这种架构特别适合处理拥有海量参数和大规模数据集的大模型,如深度神经网络,因为它能有效地解决"存储墙"问题,确保即使在处理高维特征空间和进行复杂的模型优化时,也能保持高性能和低功耗,是实现未来高性能计算的关键技术之一。
结论
随着数字化程度的日益加深,数字资产随之累积,导致大模型所需的数据源愈发丰富,模型参数量亦呈指数级增长。这无疑对AI处理器提出了更高的要求,不仅需要更强大的存储能力来容纳这些海量数据,还必须具备更快的运算能力以实现高效处理。当前,AI处理器的研发正从多方面展开创新,除了持续优化科学计算的基本处理单元结构,还积极探索借鉴存算一体架构中的近存计算设计理念,旨在通过缩短数据读取路径,扩大存储规模并减少数据传输中的能耗,从而大幅提升效率。显然,存算一体架构已成为驱动AI芯片技术进步的关键因素。
