优化不必要字段
有些时候,最开始设计索引的人可能没有注意,就把一些根本不会被搜索到的字段也存储到了Elasticsearch。更加可怕的是还是用了动态的mapping,这可能无意间索引了很多新字段。
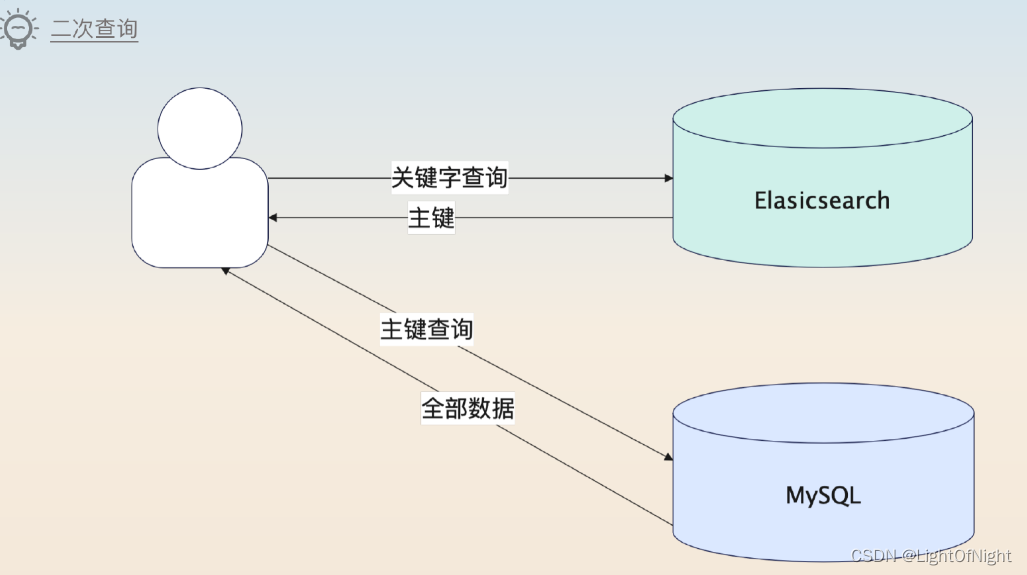
在实践中最常见错误,就是把数据库里存储的数据全量同步到Elasticsearch上,但是其实根本没有必要。所以这种优化手段就是只把要被查询的字段同步到Elasticsearch上,而把数据的主体部分留在原本的数据库里。
之前我接手的一个历史系统需要把数据同步到Elasticsearch上支持搜索,最开始的数据量并不是很大,所以是直接把全量数据 同步到了Elasticsearch上的。后面业务起来之后,就发现我这个业务的数据占据了大量的内存和磁盘空间。
梳理业务后发现不用全部同步过去,因为要被搜索的字段只是其中的一小部分,而另外一些字段同步过去只是白白加重了Elasticsearch的负担。所以后面就修改了同步的过程,那一部分数据就直接传入null了 。查询过程相当于在Elasticsearch上根据各种输入查到业务的主键,如果还需要Elasticsearch中没有的字段,就回数据库再次查询 。
当然,这样做的代价是有一些查询需要再次查询数据库,评估过请求量,受影响的请求不足10%,可以接受这个结果。
少同步一些数据,就意味着你的索引所需的内存、磁盘更少,所以查询速度也会更快。紧接着补充一个reindex的改进计划。
不过后续我也在考虑重新创建一个索引,现在这种有字段但是不同步数据的方式不太优雅。
这种同步部分数据的手段,在日志检索 中也很常见。毕竟日志一般都非常长,而搜索一般都是根据业务ID之类的来查询。
还可以尝试在这个地方把话题引导到分库分表中间表上。
这种二次查询类似于分库分表中利用中间表来支持一些无分库分表键查询的解决方案,都是要先在一个地方用查询条件拿到主键或分库分表键,再到具体的数据库上查询到完整的数据。
冷热分离
基本思路是同一个业务里面数据也有冷热之分,而对于冷数据来说,可以考虑使用运行在廉价服务器 上Elasticsearch来存储;对于热数据来说,可以使用运行在昂贵的高性能服务器上的Elasticsearch。
之前在公司的时候做过一个Elasticsearch优化,就是冷热数据分离存储。我们的数据最开始都是存在统一规格的Elasticsearch上,然后为了降本增效,决定试试业界用的比较多的冷热分离方案。
基本思路就是把整个Elasticsearch的节点分为冷热两类,数据最开始都是写入到热节点上。等过一段时间之后,数据依旧不热了,就迁移到冷节点上。
这部分是借助了新出来的索引生命周期特性 来实现的。比如我们的日志,三天内的数据都在热节点上,三天后的数据迁移到了冷节点上。这个过程是自动的 ,不需要人工介入。
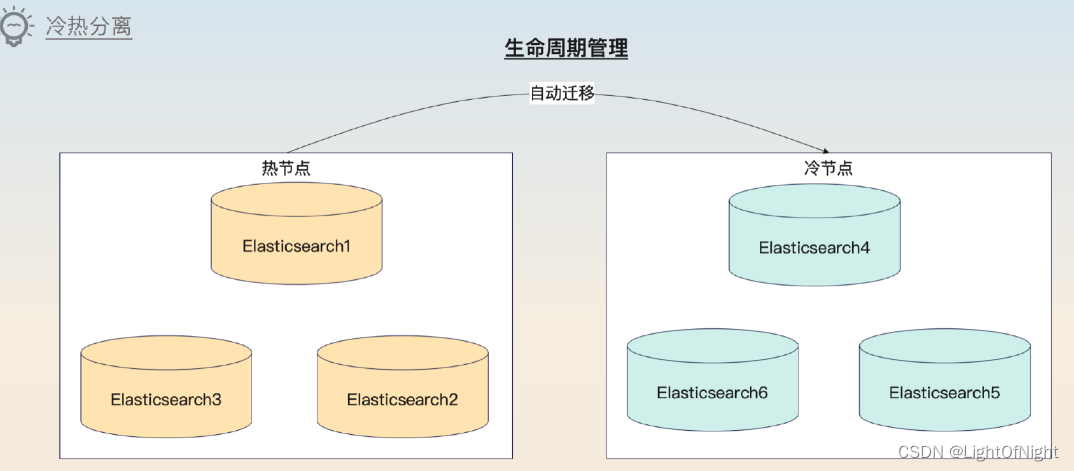
利用生命周期管理功能实现冷热数据分离操作起来还是很简单的,你可以考虑通过Kibana来直接在界面傻瓜式操作,或是使用云服务厂商提供的功能。
最好是根据自己的业务来定制这个回答,这种冷热分离的思路不仅仅可以在Elasticsearch中使用,在微服务治理、缓存中中也有类似的思路,有机会的话也可以尝试引导话题。
常规优化
优化垃圾回收
如果本身是Java开发,非常建议使用这个优化,能展示在JVM上的深厚功底。
一般Elasticsearch优化垃圾回收的第一个思路就是调整垃圾回收算法 。Elasticsearch需要一个很大的堆,那么CMS是肯定撑不住的,停顿时间会非常长。
可以考虑把垃圾回收算法换成G1,或是更加激进的ZGC。现在一般用G1比较多。
长期以来我们使用Elasticsearch有一个很大的问题,就是触发垃圾回收的时候,停顿时间比较长,会有100多毫。这主要是因为我们的Elasticsearch用的还是非常古老的CMS,而CMS在超过8G的堆上面,表现就比较差 。
后面尝试把Elasticsearch换成了G1,换了以后效果非常不错,现在停顿时间都可以控制在15毫秒以内。不过我也在调研ZGC,ZGC在特大堆上的表现比G1还要好。目前这方面业界实践不多,所以也没有进一步优化。
使用这个方案的核心就是把话题引导到垃圾回收这个主题上
优化swap
Elasticsearch也是一个内存依赖非常严重的中间件,在触发了swap的时候,性能下降的很快。
这里有两种做法:
- 在操作系统层面上直接禁用了swap,或者把vm.swappness设置成一个非常小的值。
- 在Elasticsearch里把bootstrap.memory_lock 设置为true
在面试的时候要注意把Elasticsearch和其他中间件联系在一起,以kafka为例
使用Elasticsearch的时候要把swap禁用,或者把vm.swappness设置的很小,也可以把bootstrap.memory_lock 设置为true。
所有类似Elasticsearch的中间件都可以采用这种优化手段,比如Kafka。
知识补充
在Linux操作系统中,swap 是一种内存管理功能,它允许系统将当前不活跃的内存页面移动到磁盘上,以便为活跃的进程腾出内存空间。这种机制使得Linux能够运行需要更多内存的程序,即使物理内存(RAM)不足以容纳它们。
Swap的工作原理:
- 页面替换算法: 当系统检测到物理内存不足时,它会使用页面替换算法(如LRU - 最近最少使用算法)来决定哪些页面应该被移动到swap空间。
- 磁盘空间: swap空间通常是一个专门的磁盘分区或文件,操作系统在这个空间中存储被交换出去的内存页面。
- 性能影响: 虽然swap可以提供额外的内存空间,但频繁地使用swap会降低系统性能,因为磁盘I/O比RAM访问要慢得多。
- 交换区和交换文件:
- 交换区(Swap partition):在磁盘上专门划分一个分区作为swap空间。
- 交换文件(Swap file):在磁盘上创建一个大文件作为swap空间,大小固定。
Swap的使用和管理:
- 查看swap空间:使用 free -h 命令可以查看系统的总swap空间以及已使用和空闲的swap空间。
- 启用交换空间:在Linux启动时,swap空间会自动挂载。如果需要手动挂载,可以使用 swapon 命令。
- 添加交换文件:使用 fallocate 创建交换文件,然后使用 mkswap 初始化它,最后使用 swapon 启用它。
- 调整交换行为:通过 /proc/sys/vm/swappiness 文件可以调整系统倾向于使用swap的倾向性。值越高,系统越倾向于使用swap空间。
- 监控swap使用 :使用 sar、vmstat、top 或 htop 等工具可以监控swap的使用情况。
Swap的注意事项: - 不要过度依赖swap:虽然swap可以提供额外的内存空间,但频繁的页面交换(swap thrashing)会导致系统响应变慢。
- 合理配置swap空间:根据系统的实际需求配置适量的swap空间。一般建议物理内存的1.5倍,但对于有大量内存需求的服务器,可能需要更多。
- 监控系统性能:定期监控系统性能,确保swap的使用在可接受的范围内。
总的来说,swap是Linux系统中重要的内存管理特性,它允许系统在物理内存不足时继续运行程序。然而,依赖swap可能会影响性能,因此需要合理规划内存和swap的使用。
文件描述符
Elasticsearch需要非常多的文件描述符 ,所以正常来说需要把文件描述符的数量调大,比如调到65536,甚至更多。
可以用解决Bug的思路来面试,比如问你Elasticsearch什么Bug的时候,也可以用这个回答。
之前我们在使用Elasticsearch的时候,还遇到文件描述符耗尽的问题,因为我们用的是一个非常大的Elasticsearch,很多业务共用,导致Elasticsearch打开的文件描述符非常多。
那一次的故障后,一方面我们调大了最大文件描述符的数量,另一方面也考虑把业务逐步迁移到不同的Elasticsearch上。这次故障足以说明这是需要考虑隔离的。
隔离也可以把话题引导到微服务的隔离上。
知识补充
Elasticsearch 使用文件描述符(File Descriptors,FDs)来实现多种功能,主要包括:
-
索引存储: Elasticsearch 将索引数据存储在磁盘上,每个索引文件都通过文件描述符进行管理。
-
网络通信: Elasticsearch 节点之间以及与客户端之间的通信通过 TCP/IP 协议实现,每个网络连接都使用文件描述符来跟踪。
-
日志记录: Elasticsearch 会将日志信息写入到磁盘文件中,这些文件操作同样需要使用文件描述符。
-
缓存实现: Elasticsearch 使用文件描述符来管理其缓存机制,比如请求缓存和字段数据缓存。
-
父进程与子进程间通信: 在某些操作(如分片恢复)中,Elasticsearch 可能会使用 fork 来创建子进程,这时文件描述符用于父子进程间的通信。
-
临时文件: 在执行某些操作(如查询的某些阶段)时,Elasticsearch 可能会创建临时文件,这些文件也需要文件描述符来访问。
-
插件和脚本: Elasticsearch 支持插件和脚本,这些插件和脚本在运行时可能会打开文件,同样需要文件描述符。
-
配置文件: Elasticsearch 读取配置文件(如 elasticsearch.yml)时,也需要使用文件描述符。
最大文件描述符限制: 操作系统对每个进程可以打开的文件描述符数量有限制。如果超过这个限制,Elasticsearch 将无法打开新的文件或网络连接,可能会导致节点不稳定或无法正常工作。
配置建议: 通常建议为 Elasticsearch 节点配置适当的文件描述符限制,例如,可以通过设置 bootstrap.memory_lock 来锁定内存,并确保 Elasticsearch 进程有足够的文件描述符可用。
监控和管理: 可以使用 ulimit -n 命令来查看和设置文件描述符的限制。在生产环境中,应监控 Elasticsearch 节点的文件描述符使用情况,确保不会达到操作系统的限制。
最佳实践: 在部署 Elasticsearch 集群时,考虑到性能和稳定性,应根据节点的物理内存和预期负载来合理配置文件描述符的限制,并在必要时调整操作系统的默认设置。
总之,文件描述符在 Elasticsearch 中扮演着重要的角色,用于管理节点的多种资源和通信。正确地管理和配置文件描述符对于确保 Elasticsearch 集群的健康和性能至关重要。
总结
一般性的性能优化方案可以做个总结
- 优化查询本身:可能涉及到改写SQL、优化索引等
- 优化中间件本身:调整中间件的各种参数
- 优化操作系统:调整内存、网络IO和磁盘方面有关的参数