11天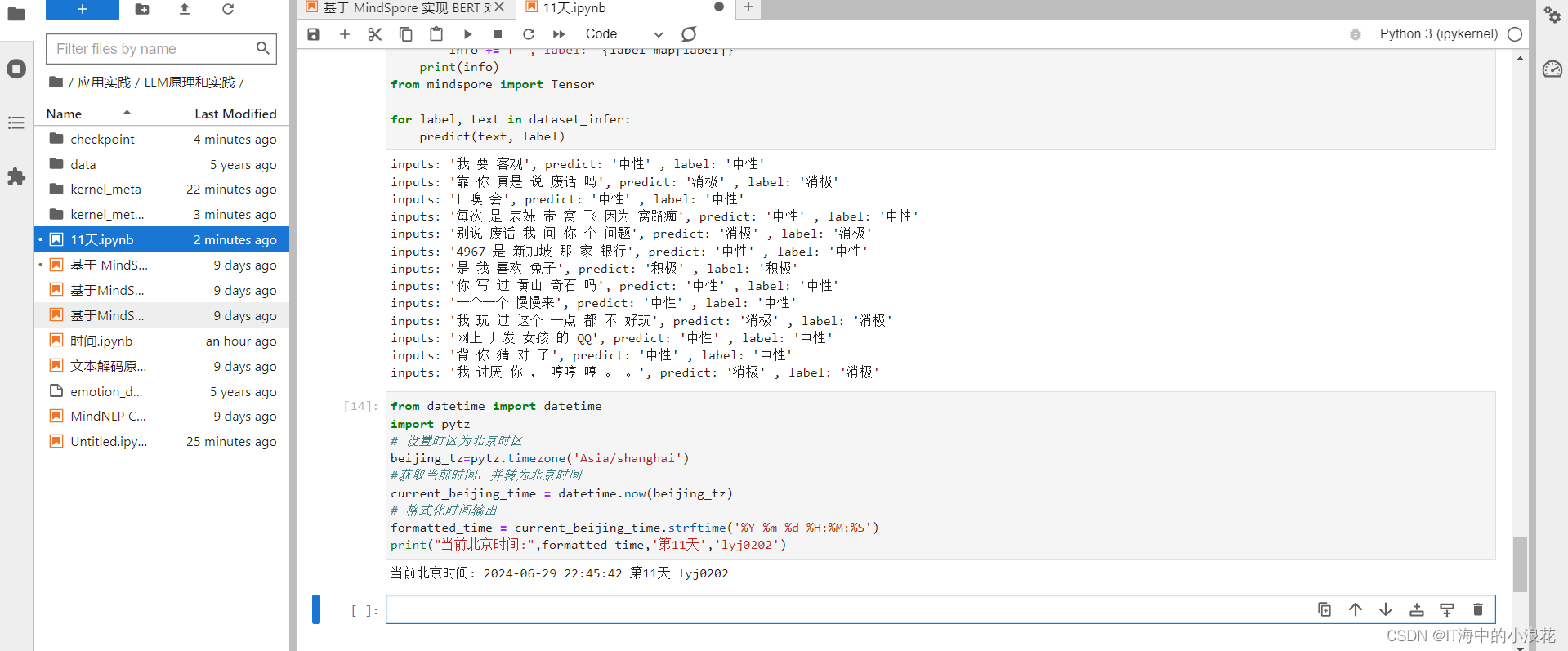 本节学习到BERT全称是来自变换器的双向编码器表征量,它是Google于2018年末开发并发布的一种新型语言模型。BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。通过一个文本情感分类任务为例子来学习了BERT模型的整个应用过程。
本节学习到BERT全称是来自变换器的双向编码器表征量,它是Google于2018年末开发并发布的一种新型语言模型。BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。通过一个文本情感分类任务为例子来学习了BERT模型的整个应用过程。
《昇思25天学习打卡营第11天 | 昇思MindSpore基于 MindSpore 实现 BERT 对话情绪识别》
IT海中的小浪花2024-07-03 14:11
相关推荐
李燚2 小时前
RAG 流水线设计:Eino 的 Loader → Transformer → Indexer → Retriever(第60篇-E46)码农学院3 小时前
Vue3小程序开发实战:服装鞋帽箱包行业库存同步方案To_OC3 小时前
跟 AI 写代码越写越乱?我靠这套「Vibe Coding」思路彻底治好了幻觉屎山IT小盘3 小时前
03-大模型API不只是发送Prompt-流式输出超时重试与异常处理深圳慧闻智造技术有限公司3 小时前
机器人减速机壳体加工精度要求的四大核心维度分析冬奇Lab3 小时前
AI 评测系列(07):自定义 Benchmark——从业务场景到评测集骏晔科技DreamLNK4 小时前
国产蓝牙模块哪个品牌好?骏晔科技 7 款主流型号横向对比用户938515635075 小时前
从零搭建 AI 日记助手:用 Milvus 向量数据库 + RAG 让机器读懂你的每一天一只小菜鸡..5 小时前
南京大学 操作系统 (JYY) 学习笔记:进程、系统调用与状态机管理阿部多瑞 ABU6 小时前
新帝国殖民主义:文化-情感-金融复合体的当代运作机制