一、引言
我们在对数据进行可视化时遇到最头疼、最常见的问题是什么?数据问题。
因为我们往往不会从零自己编程进行可视化,往往是现有模板或积累,而正确的数据格式对应正确的图形包要求,一定会正确出图,所以只有一个问题------数据格式问题。
在R中,绝大多数图形要求的格式------都是长格式。
二、定义
何为长格式?
运行下面这个代码,你会有所理解:
R
library(tidyr)
# 假设的宽格式数据(从长格式转换而来)
wide_data <- data.frame(
City = c("CityA", "CityB", "CityC"),
Year = c(2020, 2020, 2020),
Education = c(100, 110, 95),
Healthcare = c(120, 130, 115),
Transportation = c(80, 90, 75)
)
print(wide_data)
# 转换为长格式数据
long_data <- pivot_longer(wide_data,
cols = -c(City, Year), # 指定哪些列需要被转换成长格式(除了City和Year)
names_to = "Category", # 新增列的名称,用于存储原宽格式中的列名
values_to = "Expenditure") # 新增列的名称,用于存储原宽格式中的值
# 查看长格式数据
print(long_data)我们习惯的宽格式如下(一个城市在某一年对应的教育、健康及交通指数):

这是转化过后的长格式(将教育、健康及交通列进行转换):

也就是说, 我选定n列,这n列的列名重新生成一列(names_to),这n列的数据重新生成一列(values_to),这两列相互对应。
三、理解
为什么要这样呢?
我们都熟悉在R中是按列名操作数据的,如果是宽格式,那么宽,不方便操作。而转换成长格式呢?我们就可以方便地对两列数据进行操作。
并且要知道"组"的概念,上述例子中,有三个组别:CityA、B、C,而每一组又有三个标签(组别):教育、健康、交通。
运行下面这个例子体会:
R
# 制作分组柱状图
ggplot(long_data, aes(x = Category, y = Expenditure, fill = Category)) +
geom_bar(stat = "identity", position = "dodge") + # 使用identity统计量,并设置位置为分组(dodge)
facet_wrap(~ City, scales = "free_y") + # 按城市分组,y轴比例自由调整
labs(title = "分组柱状图:不同城市的各类支出",
x = "类别",
y = "支出金额",
fill = "类别") +
theme_minimal() + # 使用简约主题
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # 旋转x轴标签以改善可读性 按城市为大组进行分类:

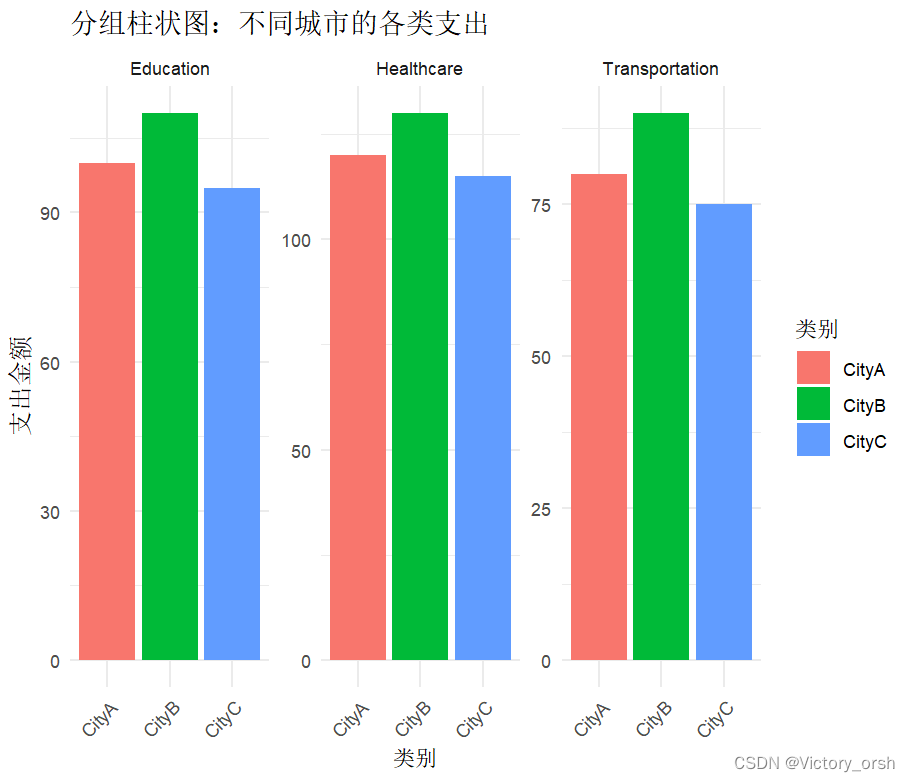
运行下述代码:
R
ggplot(long_data, aes(x = City, y = Expenditure, fill = City)) +
geom_bar(stat = "identity", position = "dodge") + # 使用identity统计量,并设置位置为分组(dodge)
facet_wrap(~ Category, scales = "free_y") + # 按城市分组,y轴比例自由调整
labs(title = "分组柱状图:不同城市的各类支出",
x = "类别",
y = "支出金额",
fill = "类别") +
theme_minimal() + # 使用简约主题
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # 旋转x轴标签以改善可读性 按照 教育、健康、交通为大组进行分类:
到这里,相信你对长格式及数据格式的使用都有了深刻理解,自己去试试吧!