理论上RLHF(强化学习)效果比sft好,也更难训练。ppo有采用阶段,步骤比较多,训练速度很慢.
记录下工作中使用llama-factory调试rlhf-ppo算法流程及参数配置,希望对大家有所帮助.
llama-factory版本: 0.8.2
一 rlhf流程
ppo训练流程图如下, 会用到多个模型, 但初始化阶段, 只需提供sft和reward模型就行.
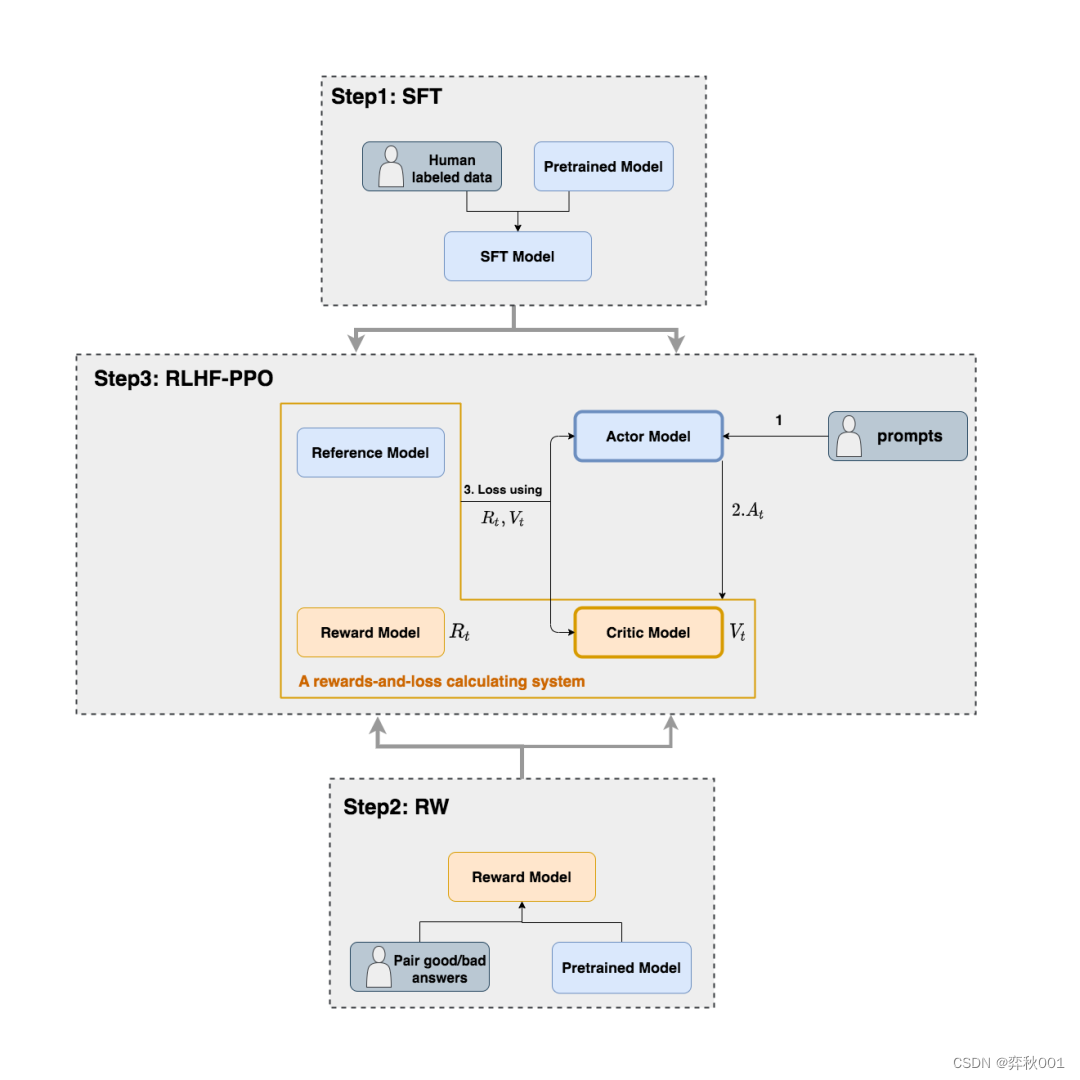
四个子模型用途:
- Actor Model:演员模型,这就是我们想要训练的目标语言模型
- Reference Model :参考模型,它的作用是在RLHF阶段给语言模型增加一些"约束",防止语言模型训歪。我们希望训练出来的Actor模型既能达到符合人类喜好的目的,又尽量让它和SFT模型不要差异太大。即希望两个模型的输出分布尽量相似,通过与Actor Model之间的KL散度控制。
- Critic Model:评论家模型,它的作用是预估总收益V->(t),在RLHF中,我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic)。这就是Critic模型存在的意义。
- Reward Model :奖励模型,它的作用是计算即时收益R->(t) Actor/Critic Model. 在RLHF阶段是需要训练的;而Reward/Reference Model是参数冻结的。
整体算法流程如下:
-
训练sft模型
-
训练reward奖励模型
-
以sft模型初始化Reference和Actor模型,以奖励模型初始化Critic模型。其中,Actor与Critic模型权重可训练,Reference与Reward冻结权重,全程不更新。
-
rlhf-ppo执行过程分析(对应上图的step 3):
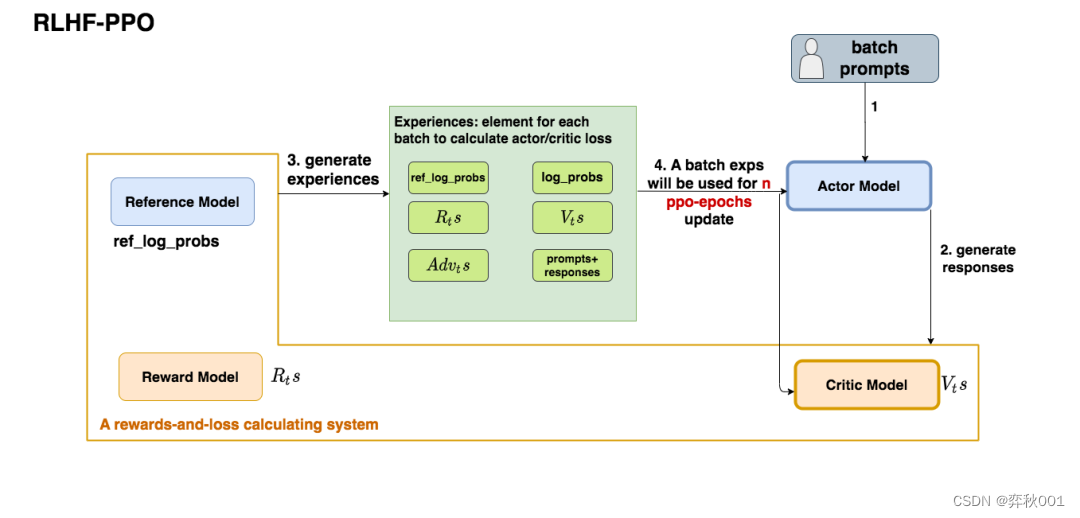
-
第一步,我们准备一个batch的prompts
-
第二步,我们将这个batch的prompts喂给Actor模型,让它生成对应的responses
-
第三步,我们把prompt+responses喂给我们的Critic/Reward/Reference模型,让它生成用于计算actor/critic loss的数据,按照强化学习的术语,我们称这些数据为经验(experiences)。
-
第四步,我们根据这些经验,实际计算出actor/critic loss,然后更新Actor和Critic模型。
涉及的损失函数:

至此, 我们对RLHF-PPO工作原理已经有了清晰的认知. 若觉得上述文字不过瘾, 可以看我列出的几篇参考文献, 对ppo复杂的原理有深刻解读.
二 代码实践
2.1 数据准备: 需要准备sft指令微调和reward奖励模型的数据.
- sft数据格式
python
[
{
"instruction": "<question>:查看备案有效期在今天之后的委托信息\nCREATE TABLE 委托备案信息 (序号 FLOAT,\n委托企业名称 VARCHAR(255),\n公司地址 VARCHAR(255),\n被委托企业名称 VARCHAR(255),\n委托产品名称 VARCHAR(255),\n备案日期 VARCHAR(255),\n备案有效期 VARCHAR(255));",
"input": "",
"output": "\nSELECT * FROM 委托备案信息 WHERE TO_DATE(备案有效期, 'YYYY-MM-DD') > NOW();\n"
},
{
"instruction": "<question>:哪些镇名拥有重点旅游村?\nCREATE TABLE 镇名休闲农业园区休闲农庄重点旅游村 (镇名 VARCHAR(255),\n休闲农业园区 VARCHAR(255),\n休闲农庄 VARCHAR(255),\n重点旅游村 VARCHAR(255));",
"input": "",
"output": "\nSELECT DISTINCT 镇名 FROM 镇名休闲农业园区休闲农庄重点旅游村 WHERE 重点旅游村 IS NOT NULL;\n"
},
...
]- reward数据格式固定,不能随意更改, 经过断点调试发现, 所有模型的reward数据都遵循以下格式, 其中chosen期望偏好, rejected是负向偏好.
python
[
{
"conversations": [
{
"from": "human",
"value": "<question>:查看备案有效期在今天之后的委托信息\nCREATE TABLE 委托备案信息 (序号 FLOAT,\n委托企业名称 VARCHAR(255),\n公司地址 VARCHAR(255),\n被委托企业名称 VARCHAR(255),\n委托产品名称 VARCHAR(255),\n备案日期 VARCHAR(255),\n备案有效期 VARCHAR(255));"
}
],
"chosen": {
"from": "gpt",
"value": "\nSELECT * FROM 委托备案信息 WHERE TO_DATE(备案有效期, 'YYYY-MM-DD') > NOW();\n"
},
"rejected": {
"from": "gpt",
"value": "SELECT * FROM 委托备案信息 WHERE 备案有效期 > NOW()"
}
},
{
"conversations": [
{
"from": "human",
"value": "<question>:哪些镇名拥有重点旅游村?\nCREATE TABLE 镇名休闲农业园区休闲农庄重点旅游村 (镇名 VARCHAR(255),\n休闲农业园区 VARCHAR(255),\n休闲农庄 VARCHAR(255),\n重点旅游村 VARCHAR(255));"
}
],
"chosen": {
"from": "gpt",
"value": "\nSELECT DISTINCT 镇名 FROM 镇名休闲农业园区休闲农庄重点旅游村 WHERE 重点旅游村 IS NOT NULL;\n"
},
"rejected": {
"from": "gpt",
"value": "SELECT DISTINCT 镇名 FROM PG库 WHERE 重点旅游村 IS NOT NULL;"
}
},
...
]2.2 训练代码
新版llama-factory不再使用shell脚本传参, 而是通过yaml文件完成, 之后通过以下代码, 根据传入yaml文件不同执行对应的训练任务.
python
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from src.llamafactory.train.tuner import run_exp
import yaml
def main(yaml_path_):
with open(yaml_path_, 'r', encoding='utf-8') as f:
param = yaml.safe_load(f)
run_exp(param)
if __name__ == "__main__":
#1.sft指令微调
# yaml_path = '../examples/yblir_configs/qwen2_lora_sft.yaml'
# 2.奖励模型训练
# yaml_path = '../examples/yblir_configs/qwen2_lora_reward.yaml'
# 3.rlhf-ppo训练
yaml_path = '../examples/yblir_configs/qwen2_lora_ppo.yaml'
main(yaml_path)sft 超参: qwen2_lora_sft.yaml
yaml
# model
model_name_or_path: E:\PyCharm\PreTrainModel\qwen2_7b
#model_name_or_path: /media/xk/D6B8A862B8A8433B/data/qwen2_05b
# method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
# dataset
dataset: train_clean
dataset_dir: ../data
template: qwen
cutoff_len: 1024
#max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 2
# output
output_dir: E:\PyCharm\PreTrainModel\qwen2_7b_sft
logging_steps: 10
save_steps: 100
plot_loss: true
overwrite_output_dir: true
# train
per_device_train_batch_size: 4
gradient_accumulation_steps: 2
learning_rate: 1.0e-5
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_steps: 0.1
fp16: true
# eval
val_size: 0.1
per_device_eval_batch_size: 4
evaluation_strategy: steps
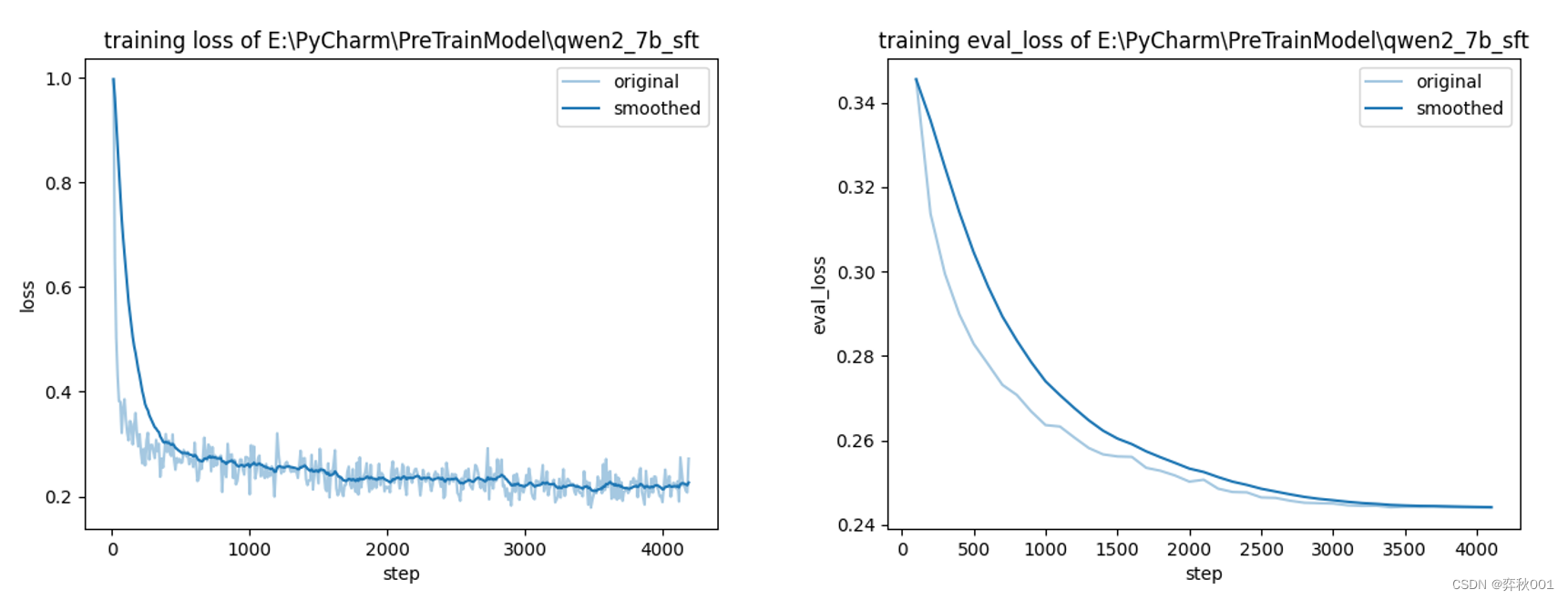
eval_steps: 100sft训练效果:
rm模型训练参数: qwen2_lora_reward.yaml
yaml
# 训练奖励模型
### model
model_name_or_path: /mnt/e/PyCharm/PreTrainModel/qwen2_7b
### method
stage: rm
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: rw_data
dataset_dir: ../data
template: qwen
cutoff_len: 1024
max_samples: 3000
overwrite_cache: true
preprocessing_num_workers: 1
### output
output_dir: /mnt/e/PyCharm/PreTrainModel/qwen2_7b_rm
logging_steps: 10
save_steps: 100
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 2
gradient_accumulation_steps: 2
learning_rate: 1.0e-5
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
fp16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 2
eval_strategy: steps
eval_steps: 500rm训练效果:
python
***** eval metrics *****
epoch = 3.0
eval_accuracy = 1.0
eval_loss = 0.0
eval_runtime = 0:00:16.73
eval_samples_per_second = 17.923
eval_steps_per_second = 8.961
[INFO|modelcard.py:450] 2024-06-26 23:02:36,246 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}, 'metrics': [{'name': 'Accuracy', 'type': 'accuracy', 'value': 1.0}]}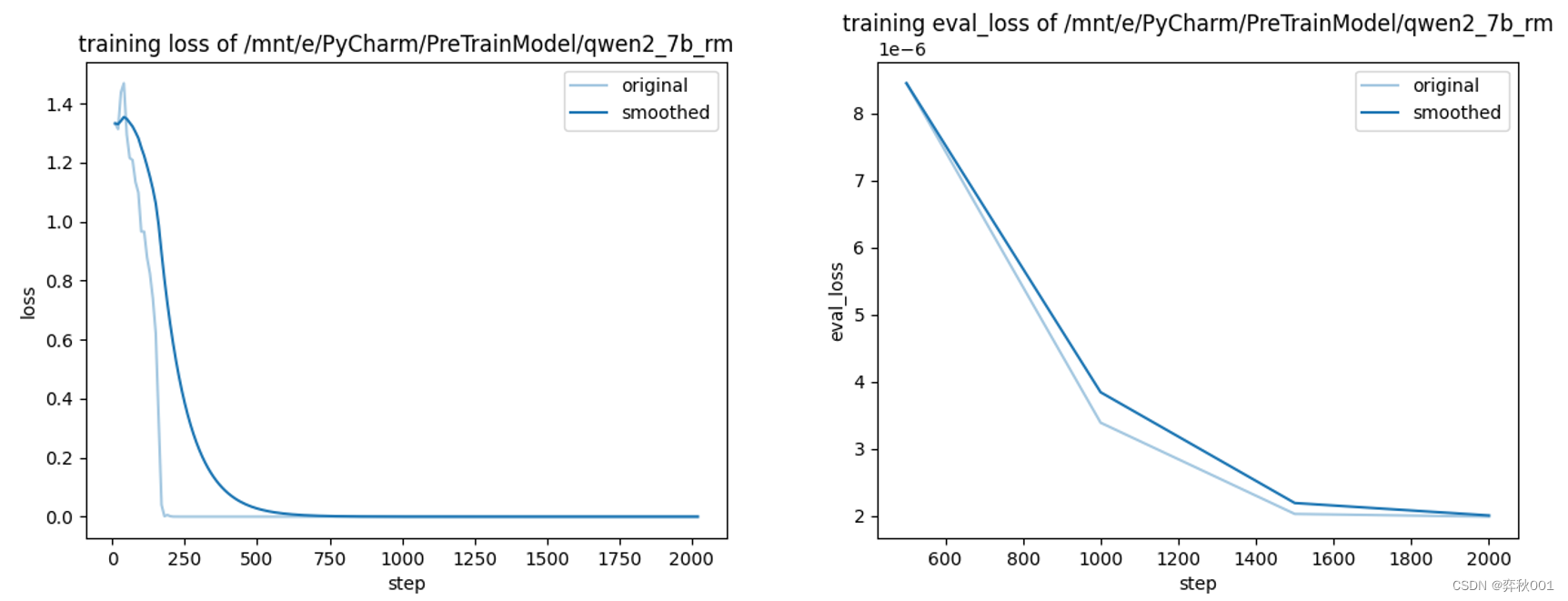
sft训练完成后,要先merge 才能进行下一步ppo训练.
merge代码及配置文件:
python
# -*- coding: utf-8 -*-
# @Time : 2024/5/17 23:21
# @Author : yblir
# @File : lyb_merge_model.py
# explain :
# =======================================================
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import yaml
from src.llamafactory.train.tuner import export_model
if __name__ == "__main__":
with open('../examples/yblir_configs/qwen2_lora_sft_merge.yaml', 'r', encoding='utf-8') as f:
param = yaml.safe_load(f)
export_model(param)qwen2_lora_sft_merge.yaml
yaml
# Note: DO NOT use quantized model or quantization_bit when merging lora adapters
# model
model_name_or_path: E:\PyCharm\PreTrainModel\qwen2_7b
adapter_name_or_path: E:\PyCharm\PreTrainModel\qwen2_7b_sft
#model_name_or_path: /media/xk/D6B8A862B8A8433B/data/qwen2_05b
#adapter_name_or_path: /media/xk/D6B8A862B8A8433B/data/qwen2_15b_rw
template: qwen
finetuning_type: lora
# export
export_dir: /mnt/e/PyCharm/PreTrainModel/qwen2_7b_sft_merge
export_size: 2
export_device: cpu
# 为true,保存为safetensors格式
export_legacy_format: trueppo训练: 使用merge后的sft模型. reward_model参数是rm训练的lora参数, 这样做的好处是节约显存, 不然24G显存根本没法训练7B大小的模型. 而弊端就是, 四个子模型的基座是同一个模型. 只有全量的full训练才能选择不同的模型. 目前看, 都用同一个模型也没发现什么问题.
ppo涉及数据采样, 训练很慢, 4090显卡, 对于以下参数, 显存占用约18G, 耗时约4.5小时才训练完.
yaml
### model
model_name_or_path: /mnt/e/PyCharm/PreTrainModel/qwen2_7b_sft_merge
reward_model: /mnt/e/PyCharm/PreTrainModel/qwen2_7b_rm
### method
stage: ppo
do_train: true
finetuning_type: lora
lora_target: all
### dataset
# dataset: identity,alpaca_en_demo
dataset: train_clean
dataset_dir: ../data
template: qwen
cutoff_len: 1024
max_samples: 2000
overwrite_cache: true
preprocessing_num_workers: 1
### output
output_dir: /mnt/e/PyCharm/PreTrainModel/qwen2_7b_sql_ppo_1_batch
logging_steps: 10
save_steps: 100
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-5
num_train_epochs: 2.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
fp16: true
ddp_timeout: 180000000
### generate
max_new_tokens: 512
top_k: 0
top_p: 0.9ppo训练效果
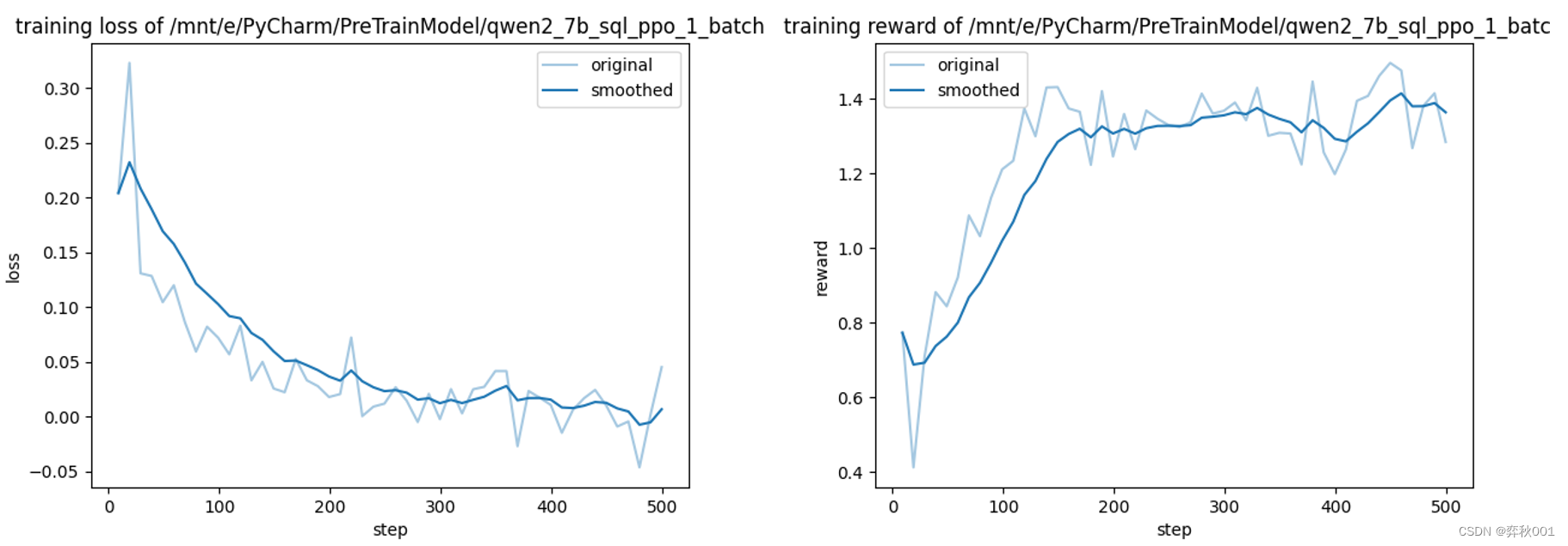
ppo训练后进行推理, 使用merge后的sft模型进行的ppo的推理的基座模型, ppo训练的finetuning_type是lora, 因此最终保存的也是lora参数,
lyb_qwen_sft_predict.yaml
python
# model
model_name_or_path: E:\PyCharm\PreTrainModel\qwen2_7b_sft_merge
adapter_name_or_path: E:\PyCharm\PreTrainModel\qwen2_7b_sql_ppo_1_batch
stage: sft
finetuning_type: lora
#lora_target: all
#quantization_bit: 8
#infer_backend: vllm
# dataset
template: qwen
#cutoff_len: 1024一个简单的推理代码, 注意模型的输入数据, 与ppo训练时入参格式一样, 本文ppo训练使用的数据与sft是同一份.
python
# -*- coding: utf-8 -*-
# @Time : 2024/6/16 20:50
# @Author : yblir
# @File : lyb_lora_inference.py
# explain :
# =======================================================
import yaml
import json
from loguru import logger
import time
import sys
from src.llamafactory.chat import ChatModel
if __name__ == '__main__':
with open('../examples/yblir_configs/lyb_qwen_sft_predict.yaml', 'r', encoding='utf-8') as f:
param = yaml.safe_load(f)
chat_model = ChatModel(param)
with open('../data/tuning_sample.json', 'r', encoding='utf-8') as f:
data = json.load(f)
# 预热
messages = [{"role": "user", "content": data[0]['instruction']}]
_ = chat_model.chat(messages)
predict_1000 = []
total_time = 0
for i, item in enumerate(data):
messages = [{"role": "user", "content": item['instruction']}]
t1 = time.time()
res = chat_model.chat(messages)
total_time += time.time() - t1
predict_1000.append(res[0].response_text)
#print('-------------------------------------------------')
print(i,'->',res[0].response_text)
# sys.exit()
if (i + 1) % 10 == 0:
# logger.info(f'当前完成: {i + 1}')
sys.exit()
if i + 1 == 300:
break
# json_data = json.dumps(predict_1000, indent=4, ensure_ascii=False)
# with open('saves2/qwen_7b_chat_lora_merge_vllm.json', 'w', encoding='utf-8') as f:
# f.write(json_data)
logger.success(f'写入完成, 总耗时:{total_time},平均耗时: {round((total_time / 300), 5)} s')sft与PPO部分推理结果比较, 具体指标要把sql放到数据库去跑一遍才知道, 结果在公司内网, 不再此列出了.
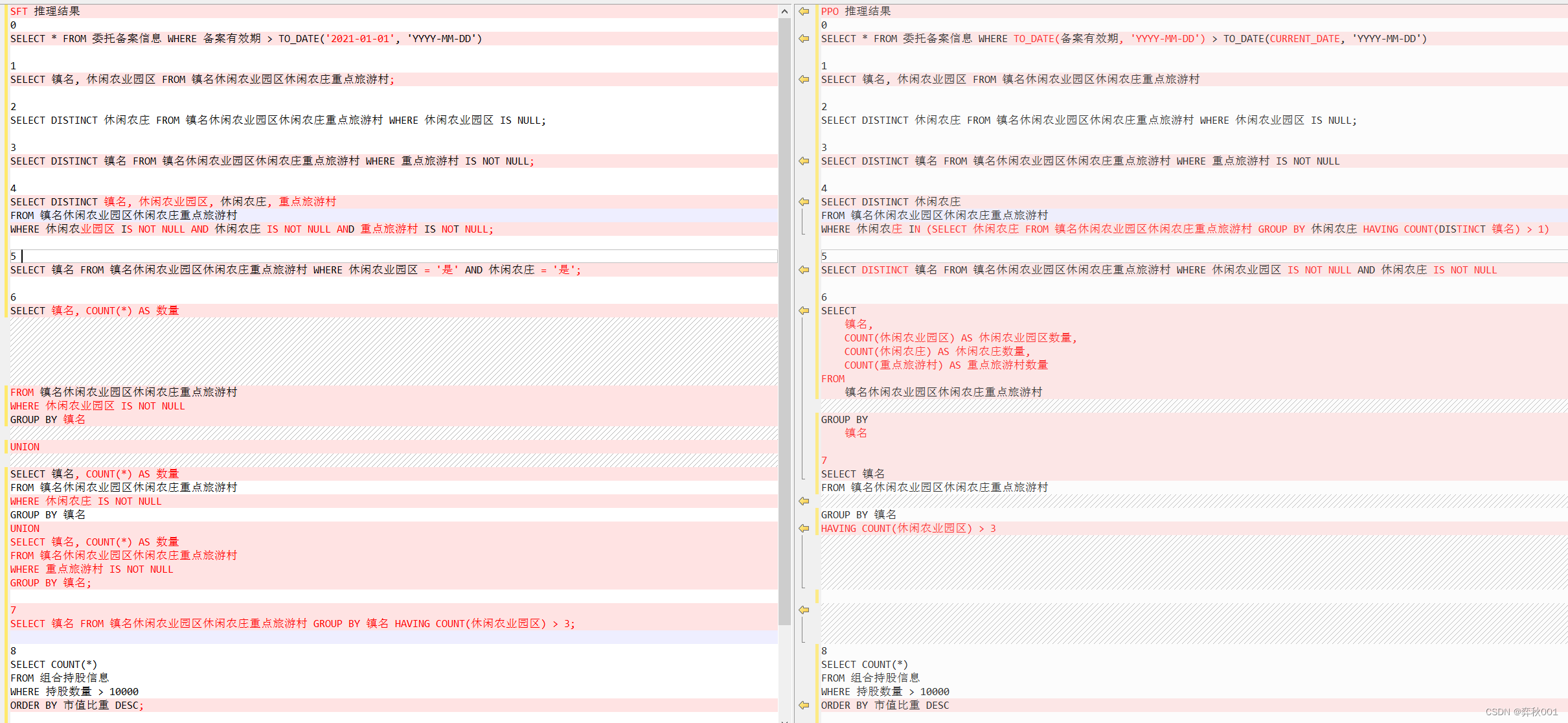
三 总结
除了ppo, dpo(Direct Preference Optimization:直接偏好优化)也是一种常见的调优手段, 不过多篇paper研究证明性能不如PPO, 在计算资源不足的情况下DPO也是个不过的选择,因为不需要训练奖励模型, 而且训练速度快,效果也比较稳定, 不像PPO那样很容易训崩.
其他LLM偏好对齐训练技术还有ORPO,IPO,CPO以及效果看起来很棒的KTO.
还有最新发表的RLOO,看起来比PPO更好更易训练.
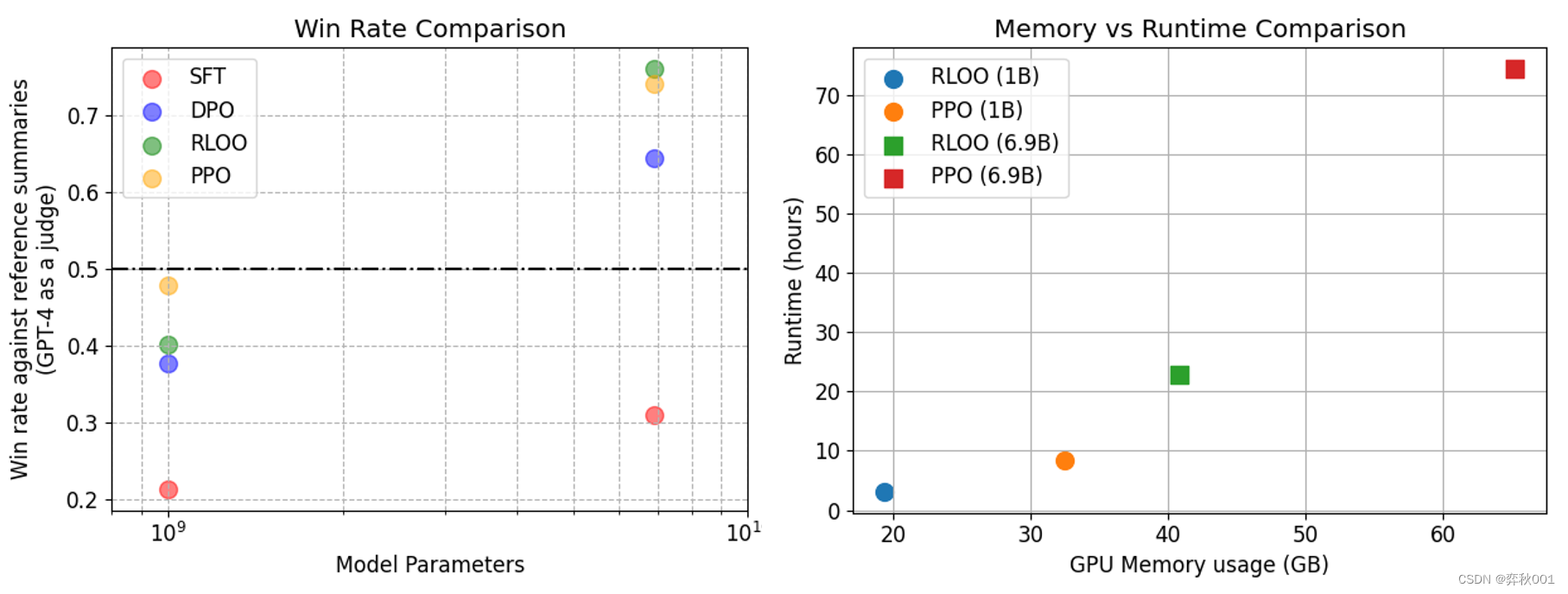
这个领域发展太快, 脑子快不够用了.

四 参考文献
https://blog.csdn.net/sinat_37574187/article/details/138200789
https://blog.csdn.net/2301_78285120/article/details/134888984
https://blog.csdn.net/qq_27590277/article/details/132614226
https://blog.csdn.net/qq_35812205/article/details/133563158