任务描述
电信数据生产是一个完整且严密的体系,这样可以保证数据的鲁棒性。在本项目的数据生产模块中,我们来模拟生产一些电信数据。同时,我们必须清楚电信数据的格式和数据结构,这样才能在后续的数据产生、存储、分析和展示环节中正确使用数据,避免可能出现的问题。
任务指导
使用Java代码模拟后续处理需要的数据,此处使用IDEA创建Maven项目在pom.xml文件中引入需要使用的类库和插件。
编写producer.ProductLog类动态生成需要的数据,并将程序打包后测试输出的数据。
任务实现
1、 数据结构
在项目中我们使用HBase来存储数据,HBase中存储的信息包括:两个电话号码,通话开始时间,通话持续时间,以及一个flag作为判断第一个电话号码是否为主叫,姓名字段的存储可以放置在另外一张表中做关联查询,也可以在同一个表中。
| 列名 | 说明 | 示例 |
|---|---|---|
| call1 | 第一个手机号码 | 15933445689 |
| call1_name | 第一个手机号码人的姓名 | 李四 |
| call2 | 第二个手机号码 | 18644889345 |
| call2_name | 第二个手机号码人的姓名 | 张三 |
| date_time | 建立通话的时间 | 201806291136 |
| date_time_ts | 建立通话的时间(时间戳) | |
| duration | 通话持续时间(秒) | 600 |
| flag | 标记本次通话第一个字段(call1)是主叫还是被叫 | 1 主叫;2 被叫; |
2、 编写代码
在这里我们创建一个Java项目,来模拟电信客服务产生的数据,步骤如下:
1) 激活IDEA
在master1的桌面双击桌面的IDEA Ultimate

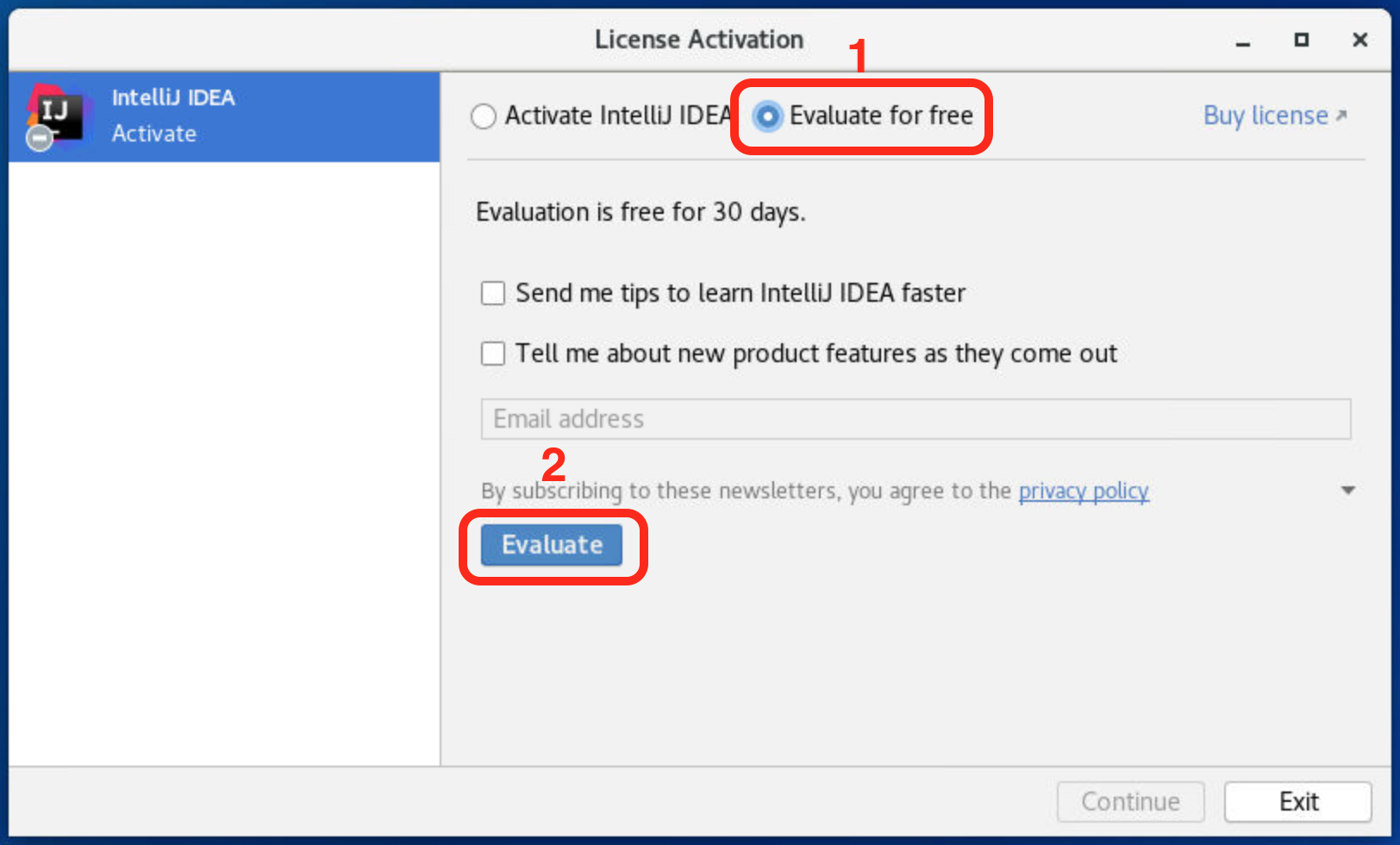
如图依次选择【Evaluate for free】=> 【Evaluate】,激活IDEA的30天免费使用权限
再次打开IDEA进入欢迎界面
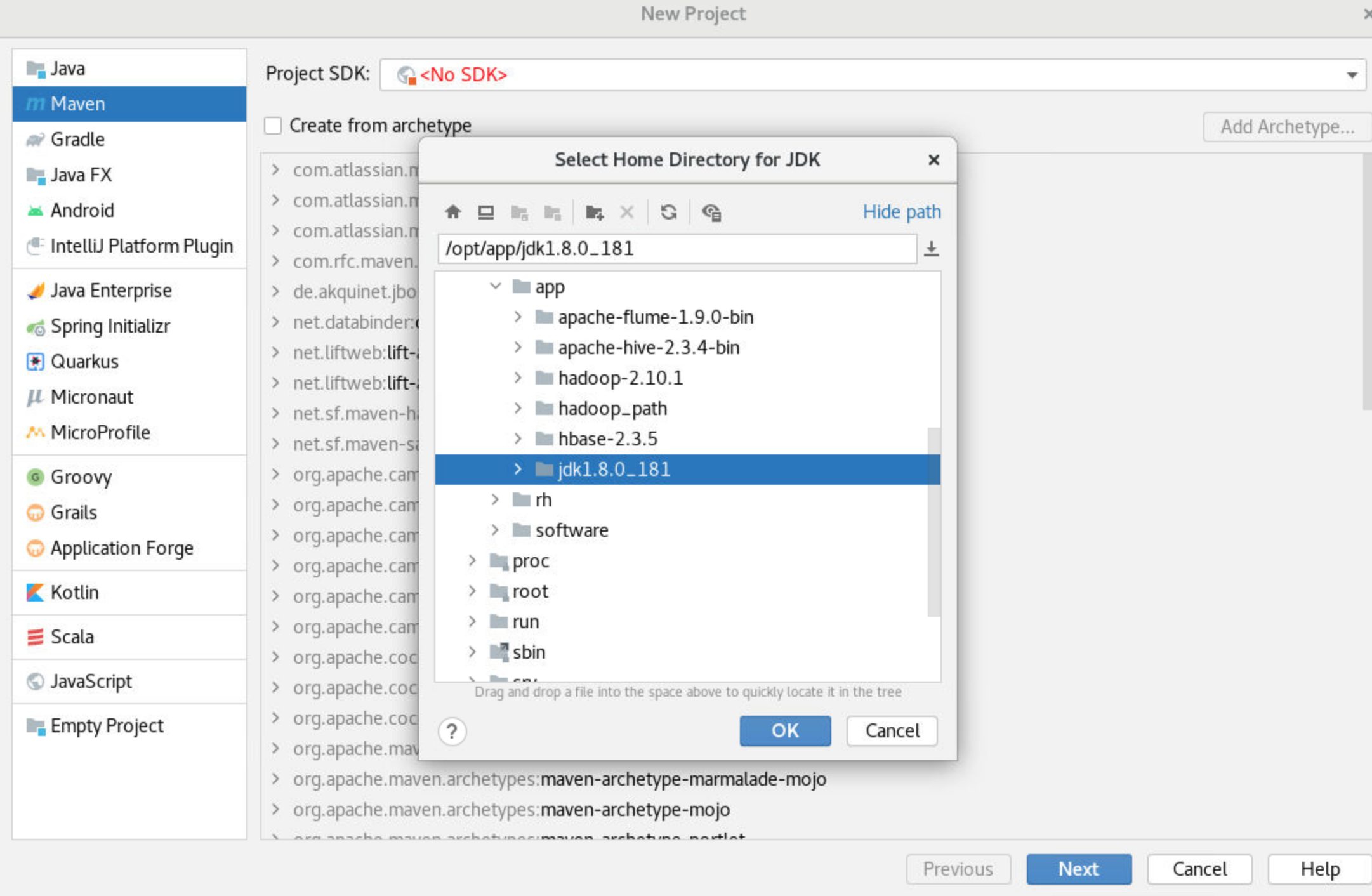
2) 创建ct_producer项目
点击"New Project"新建一个Java的Maven项目,在"New Project"左侧选择"Maven"后为项目选择所需的"Project SDK"
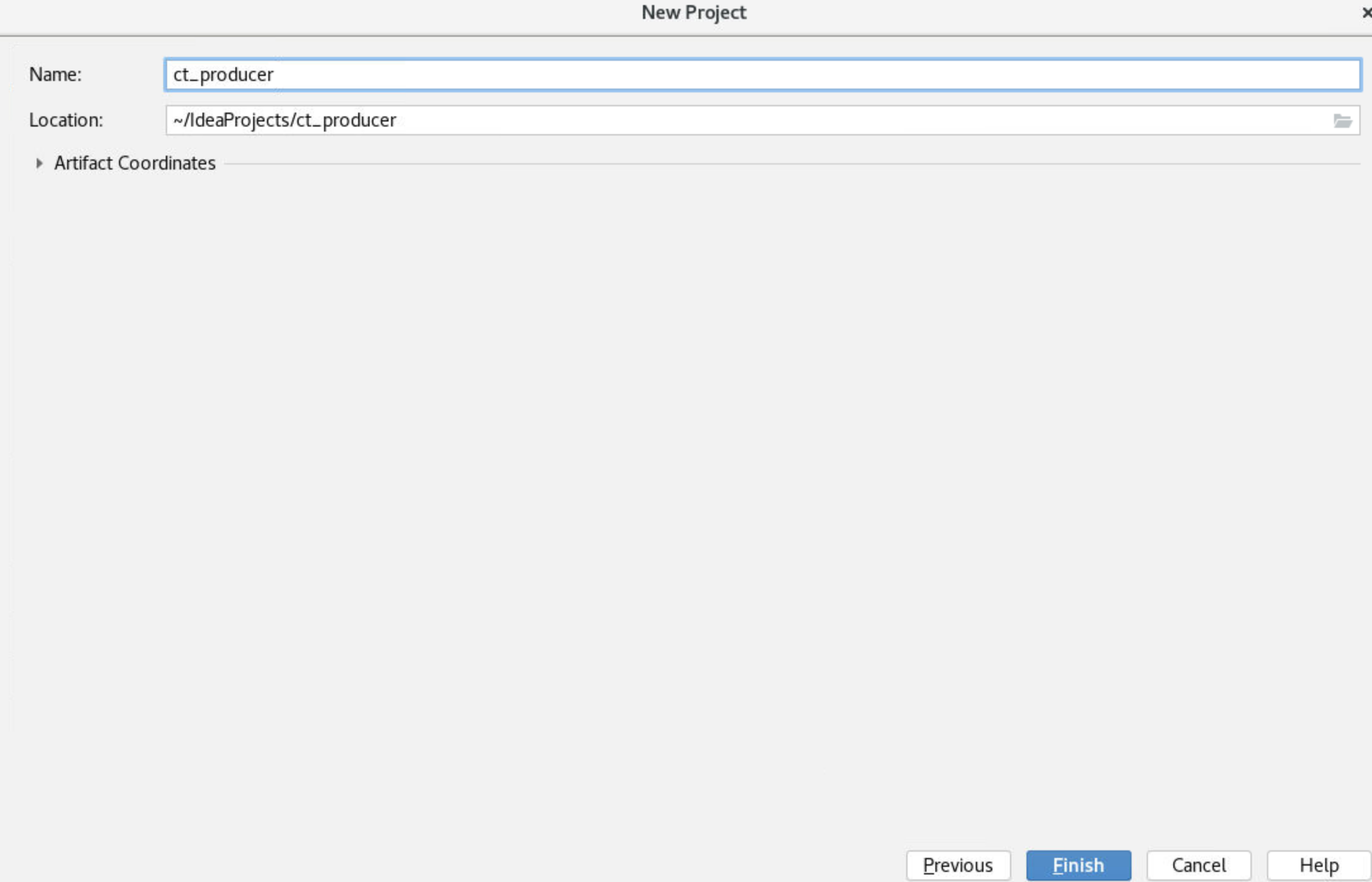
点击"Next"按钮后在"Name"文本框中输入项目名称"ct_producer"后点击"Finish"按钮。
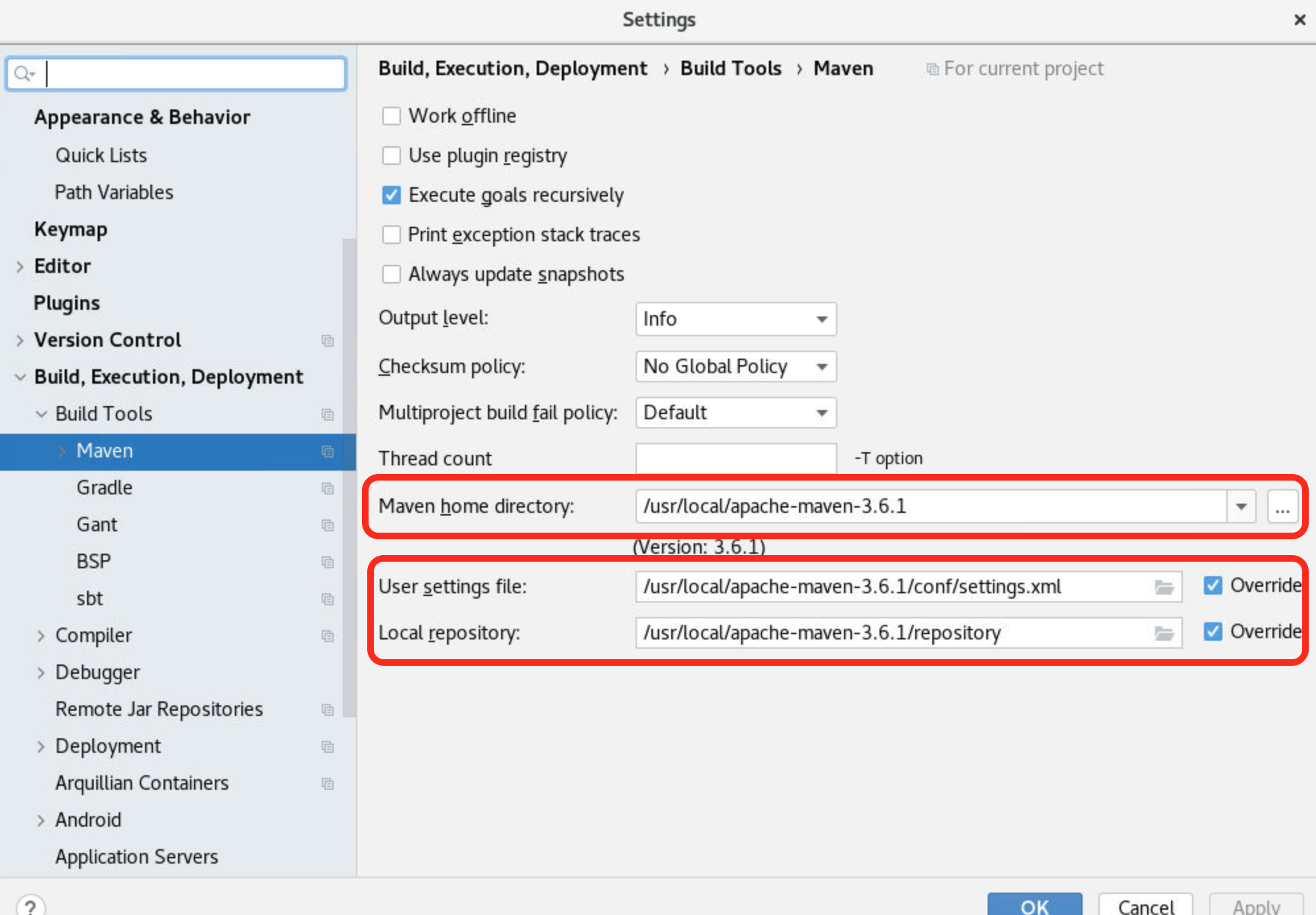
依次点击"File"->"Settings"进入"Settings"界面,如图为项目制定Maven的相关配置
打开项目的pom.xml文件配置对其进行配置,pom.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ct_producer</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12.4</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
</build>
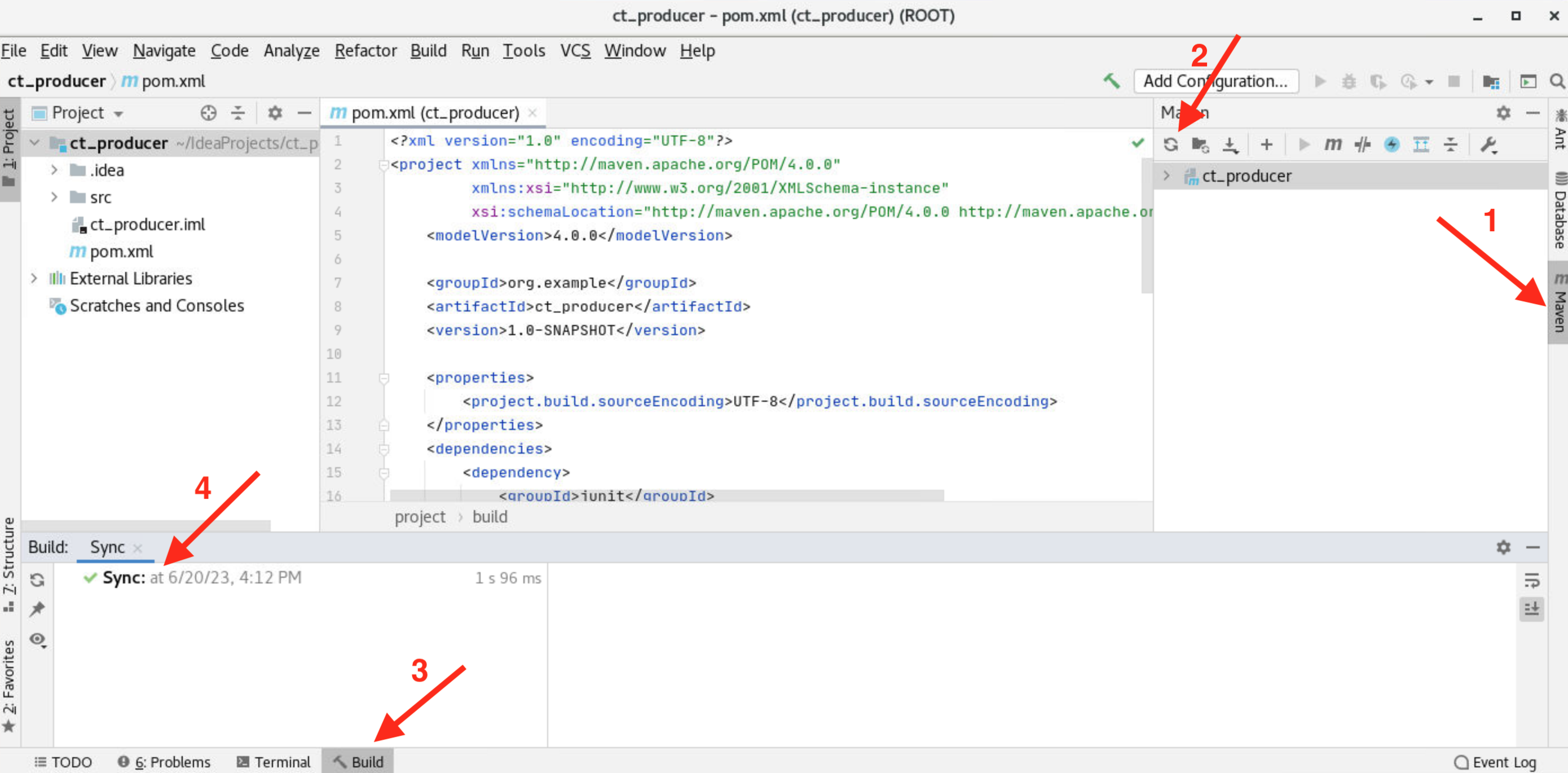
</project>如图依次点击"Maven"->"Reload all Maven Projects"后,等待"Build"标签同步(Sync)完成。
3) 完成生产者代码
创建producer包,并在此包创建ProductLog类
ProductLog.java类代码如下
package producer;
import java.util.*;
import java.io.*;
import java.text.DecimalFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
public class ProductLog {
private String startTime = "2023-01-01";
private String endTime = "2023-12-31";
//生产数据
//用于存放待随机的电话号码
private List<String> phoneList = new ArrayList<String>();
private Map<String, String> phoneNameMap = new HashMap<String, String>();
public void initPhone() {
phoneList.add("17078388295");
phoneList.add("13980337439");
phoneList.add("14575535933");
phoneList.add("19902496992");
phoneList.add("18549641558");
phoneList.add("17005930322");
phoneList.add("18468618874");
phoneList.add("18576581848");
phoneList.add("15978226424");
phoneList.add("15542823911");
phoneList.add("17526304161");
phoneList.add("15422018558");
phoneList.add("17269452013");
phoneList.add("17764278604");
phoneList.add("15711910344");
phoneList.add("15714728273");
phoneList.add("16061028454");
phoneList.add("16264433631");
phoneList.add("17601615878");
phoneList.add("15897468949");
phoneNameMap.put("17078388295", "李雁");
phoneNameMap.put("13980337439", "卫艺");
phoneNameMap.put("14575535933", "仰莉");
phoneNameMap.put("19902496992", "陶欣悦");
phoneNameMap.put("18549641558", "施梅梅");
phoneNameMap.put("17005930322", "金虹霖");
phoneNameMap.put("18468618874", "魏明艳");
phoneNameMap.put("18576581848", "华贞");
phoneNameMap.put("15978226424", "华啟倩");
phoneNameMap.put("15542823911", "仲采绿");
phoneNameMap.put("17526304161", "卫丹");
phoneNameMap.put("15422018558", "戚丽红");
phoneNameMap.put("17269452013", "何翠柔");
phoneNameMap.put("17764278604", "钱溶艳");
phoneNameMap.put("15711910344", "钱琳");
phoneNameMap.put("15714728273", "缪静欣");
phoneNameMap.put("16061028454", "焦秋菊");
phoneNameMap.put("16264433631", "吕访琴");
phoneNameMap.put("17601615878", "沈丹");
phoneNameMap.put("15897468949", "褚美丽");
}
/**
* 形式:15837312345,13737312345,2017-01-09 08:09:10,0360
*/
public String product() {
String caller = null;
String callee = null;
String callerName = null;
String calleeName = null;
//取得主叫电话号码
int callerIndex = (int) (Math.random() * phoneList.size());
caller = phoneList.get(callerIndex);
callerName = phoneNameMap.get(caller);
while (true) {
//取得被叫电话号码
int calleeIndex = (int) (Math.random() * phoneList.size());
callee = phoneList.get(calleeIndex);
calleeName = phoneNameMap.get(callee);
if (!caller.equals(callee)) break;
}
String buildTime = randomBuildTime(startTime, endTime);
//0000
DecimalFormat df = new DecimalFormat("0000");
String duration = df.format((int) (30 * 60 * Math.random()));
StringBuilder sb = new StringBuilder();
sb.append(caller + ",").append(callee + ",").append(buildTime + ",").append(duration);
return sb.toString();
}
/**
* 根据传入的时间区间,在此范围内随机通话建立的时间
* startTimeTS + (endTimeTs - startTimeTs) * Math.random();
*
* @param startTime
* @param endTime
*/
public String randomBuildTime(String startTime, String endTime) {
try {
SimpleDateFormat sdf1 = new SimpleDateFormat("yyyy-MM-dd");
Date startDate = sdf1.parse(startTime);
Date endDate = sdf1.parse(endTime);
if (endDate.getTime() <= startDate.getTime()) return null;
long randomTS = startDate.getTime() + (long) ((endDate.getTime() - startDate.getTime()) * Math.random());
Date resultDate = new Date(randomTS);
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String resultTimeString = sdf2.format(resultDate);
return resultTimeString;
} catch (ParseException e) {
e.printStackTrace();
}
return null;
}
/**
* 将数据写入到文件中
*/
public void writeLog(String filePath) {
try {
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(filePath), "UTF-8");
while (true) {
Thread.sleep(500);
String log = product();
System.out.println(log);
osw.write(log + "\n");
//一定要手动flush才可以确保每条数据都写入到文件一次
osw.flush();
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e2) {
e2.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException {
if (args == null || args.length <= 0) {
System.out.println("no arguments");
return;
}
ProductLog productLog = new ProductLog();
productLog.initPhone();
productLog.writeLog(args[0]);
}
}4) 打包:在IDEA的Maven Project视图中进行打包:
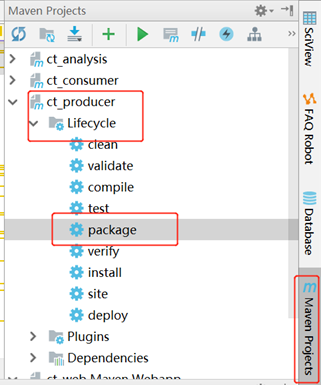
双击"LifeCycle ---package"对项目进行打包。
打包成功后日志消息回显示"BUILD SUCCESS",并在项目目录中生成target目录,此目录下包含了打包后的jar文件"ct_producer-1.0-SNAPSHOT.jar"
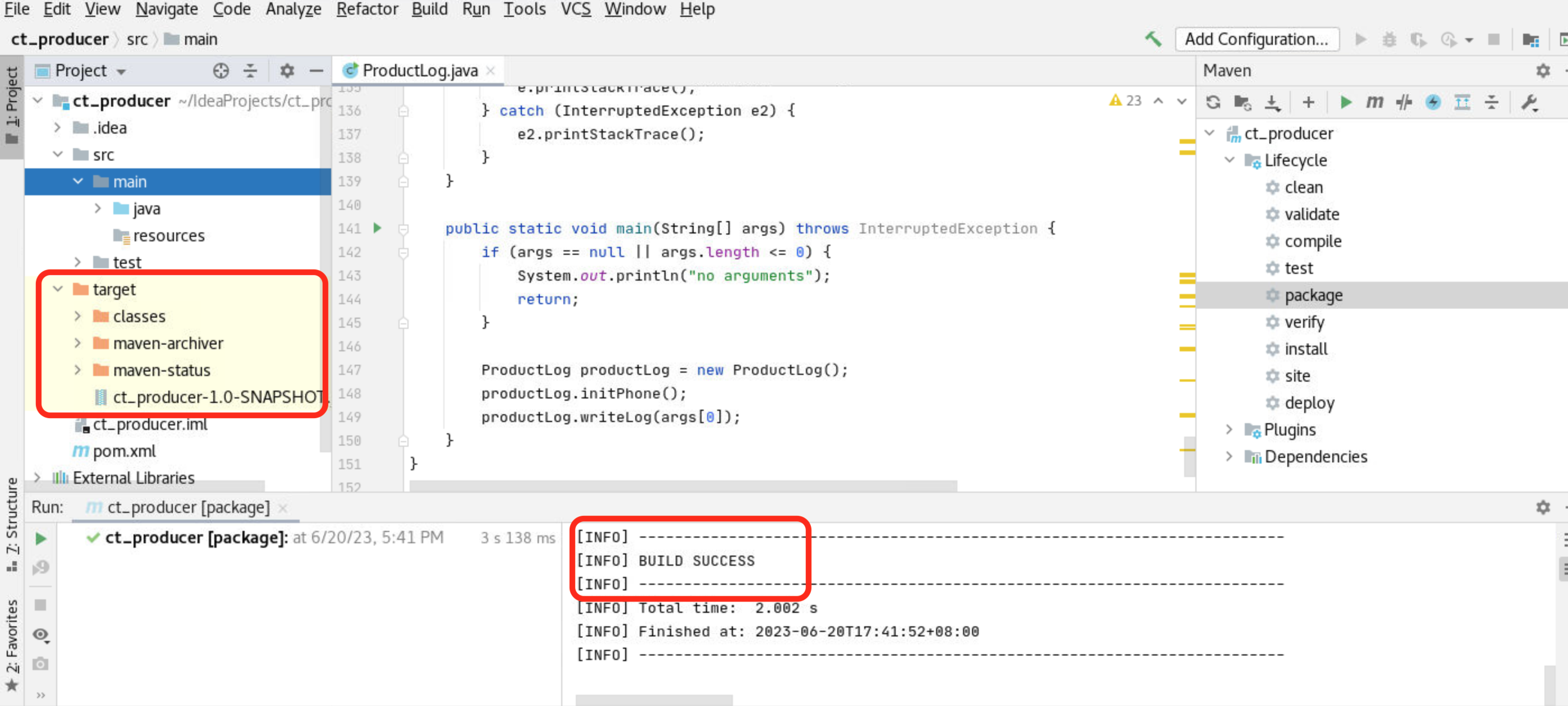
将"ct_producer-1.0-SNAPSHOT.jar"文件拷贝到/opt/app目录下,目录【/root/IdeaProjects/ct_producer/target】为创建项目时选择的默认目录,如进行了更改请根据实际目录进行操作。
[root@master1 ~]# cd /root/IdeaProjects/ct_producer/target
[root@master1 target]# cp ct_producer-1.0-SNAPSHOT.jar /opt/app/可以编写bash脚本,用于执行脚本生成日志。
创建/opt/app/productlog.sh文件
[root@master1 ~]# touch /opt/app/productlog.sh/opt/app/productlog.sh文件内容如下
#!/bin/bash
java -cp /opt/app/ct_producer-1.0-SNAPSHOT.jar producer.ProductLog /opt/app/callLog.csv