引言
在数据仓库设计中,传统的星型和雪花型模型有着各自的优势和劣势。随着数据量的增大和数据源的多样化,Data Vault(数据仓库)建模方法逐渐受到关注和应用。Data Vault建模是一种灵活、可扩展、适应性强的建模方法,特别适用于复杂和动态的数据环境。本文将介绍Data Vault建模的基本概念、组成部分以及如何在实际项目中应用,并附带详细示例。
目录
Data Vault建模概述
Data Vault由丹·林斯塔德(Dan Linstedt)在1990年代后期提出,是一种适应大规模数据整合的建模方法。它的主要特点包括:

- 高扩展性:适应快速增长的数据量和多变的数据源。
- 高灵活性:易于应对业务规则和数据源的变化。
- 历史数据保留:完整记录数据变化历史。
Data Vault模型由三类主要实体组成:
- Hub(中心表):存储业务主键及其唯一标识符。
- Link(链接表):存储不同Hub之间的关系。
- Satellite(卫星表):存储Hub或Link的属性和时间戳信息。
Hub(中心表)
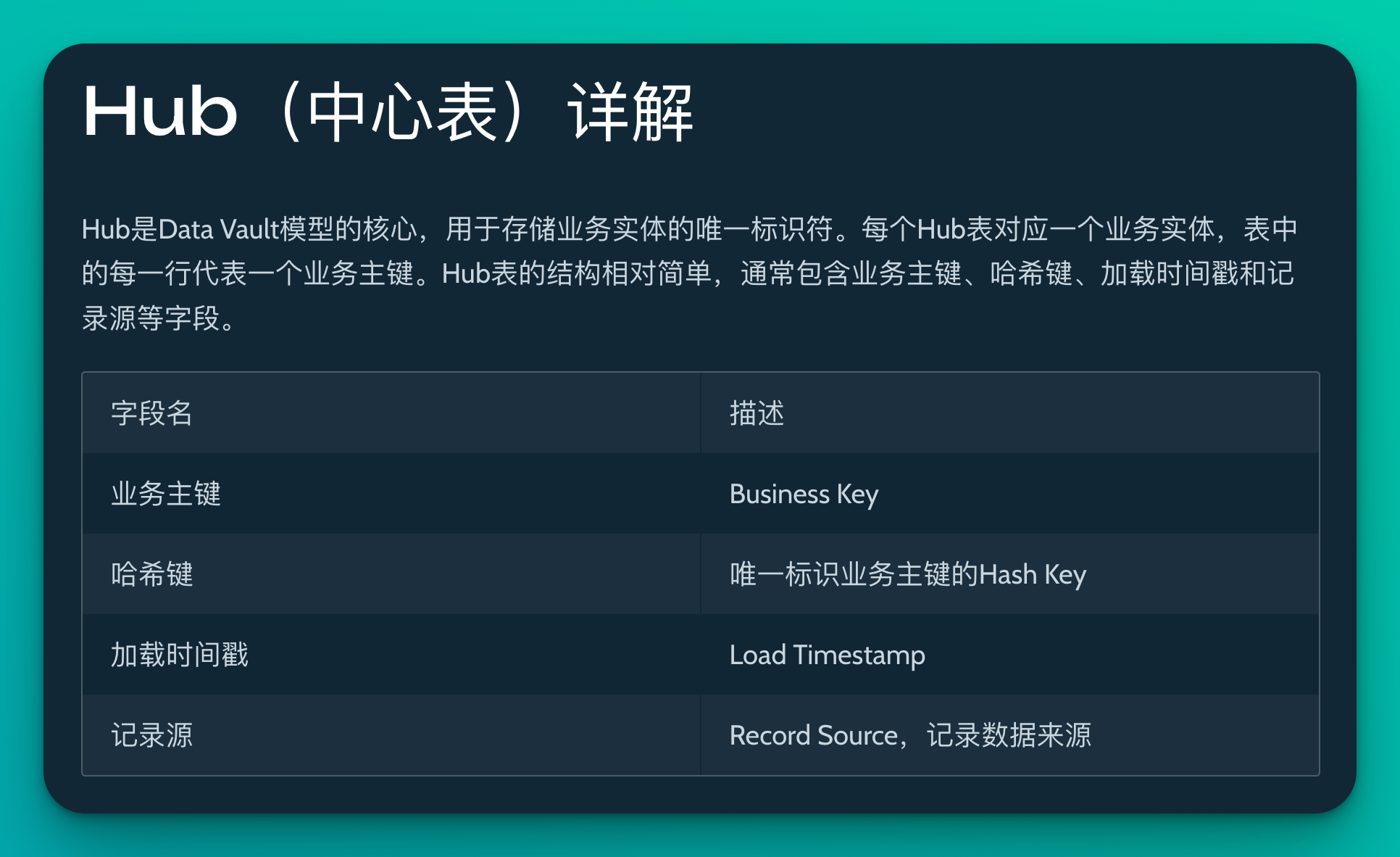
Hub是Data Vault模型的核心,用于存储业务实体的唯一标识符。每个Hub表对应一个业务实体,表中的每一行代表一个业务主键。Hub表的结构相对简单,通常包含以下字段:
- 业务主键(Business Key)
- 哈希键(Hash Key):用来唯一标识业务主键
- 加载时间戳(Load Timestamp)
- 记录源(Record Source):记录数据来源
示例:
sql
CREATE TABLE Hub_Customer (
Customer_HashKey CHAR(32) PRIMARY KEY,
Customer_BusinessKey VARCHAR(255),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);Link(链接表)
Link用于定义Hub之间的关系。每个Link表对应一种业务关系,表中的每一行代表一个关系实例。Link表的字段通常包括:
- 哈希键(Hash Key):唯一标识Link
- 外键(Foreign Key):指向相关的Hub
- 加载时间戳(Load Timestamp)
- 记录源(Record Source)

示例:
sql
CREATE TABLE Link_CustomerOrder (
CustomerOrder_HashKey CHAR(32) PRIMARY KEY,
Customer_HashKey CHAR(32),
Order_HashKey CHAR(32),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);Satellite(卫星表)
Satellite用于存储Hub或Link的属性及其变化历史。每个Satellite表与一个Hub或Link相关联,表中的每一行代表一个属性快照。Satellite表的字段通常包括:
- 哈希键(Hash Key):对应的Hub或Link的哈希键
- 属性字段(Attribute Fields)
- 加载时间戳(Load Timestamp)
- 记录源(Record Source)

示例:
sql
CREATE TABLE Sat_CustomerDetails (
Customer_HashKey CHAR(32),
Customer_Name VARCHAR(255),
Customer_Address VARCHAR(255),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);实践中的Data Vault建模
下面我们通过一个实际例子来展示如何在项目中应用Data Vault建模。假设我们有一个电商系统,需要整合客户、订单和产品等信息。

步骤一:定义Hub表
首先,我们为客户、订单和产品定义Hub表。
sql
-- 客户中心表
CREATE TABLE Hub_Customer (
Customer_HashKey CHAR(32) PRIMARY KEY,
Customer_BusinessKey VARCHAR(255),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);
-- 订单中心表
CREATE TABLE Hub_Order (
Order_HashKey CHAR(32) PRIMARY KEY,
Order_BusinessKey VARCHAR(255),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);
-- 产品中心表
CREATE TABLE Hub_Product (
Product_HashKey CHAR(32) PRIMARY KEY,
Product_BusinessKey VARCHAR(255),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);步骤二:定义Link表
接下来,我们定义Link表来表示客户和订单、订单和产品之间的关系。
sql
-- 客户与订单关系表
CREATE TABLE Link_CustomerOrder (
CustomerOrder_HashKey CHAR(32) PRIMARY KEY,
Customer_HashKey CHAR(32),
Order_HashKey CHAR(32),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);
-- 订单与产品关系表
CREATE TABLE Link_OrderProduct (
OrderProduct_HashKey CHAR(32) PRIMARY KEY,
Order_HashKey CHAR(32),
Product_HashKey CHAR(32),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);步骤三:定义Satellite表
最后,我们为每个Hub和Link定义Satellite表,用于存储相关的属性信息。
sql
-- 客户属性卫星表
CREATE TABLE Sat_CustomerDetails (
Customer_HashKey CHAR(32),
Customer_Name VARCHAR(255),
Customer_Address VARCHAR(255),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);
-- 订单属性卫星表
CREATE TABLE Sat_OrderDetails (
Order_HashKey CHAR(32),
Order_Date DATE,
Order_Amount DECIMAL(10, 2),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);
-- 产品属性卫星表
CREATE TABLE Sat_ProductDetails (
Product_HashKey CHAR(32),
Product_Name VARCHAR(255),
Product_Price DECIMAL(10, 2),
Load_Timestamp TIMESTAMP,
Record_Source VARCHAR(50)
);总结

Data Vault建模是一种灵活且扩展性强的数据仓库建模方法,特别适用于复杂和动态的数据环境。
它通过Hub、Link和Satellite表的组合,提供了一种结构化的方法来存储和管理大量的业务数据及其变化历史。
在实际应用中,Data Vault建模方法能够有效应对数据源和业务需求的变化,为企业提供稳定可靠的数据整合解决方案。
希望本文对您理解和应用Data Vault建模有所帮助。如果您在实际项目中遇到任何问题,欢迎留言讨论。