240629_昇思学习打卡-Day11-Transformer中的self-Attention
根据昇思课程顺序来看呢,今儿应该看Vision Transformer图像分类这里了,但是大概看了一下官方api,发现我还是太笨了,看不太明白。正巧昨天学SSD的时候不是参考了太阳花的小绿豆-CSDN博客大佬嘛,今儿看不懂就在想,欸,这个网络大佬讲没讲,就去翻了下,结果还真给我找到了,还真讲过,还有b站视频,讲的贼好,简直就是茅厕顿开,这里附大佬的b站首页霹雳吧啦Wz的个人空间-霹雳吧啦Wz个人主页-哔哩哔哩视频 (bilibili.com),强烈建议去看,附本期链接Transformer中Self-Attention以及Multi-Head Attention详解_哔哩哔哩_bilibili,记得给大佬三连,有能力的给大佬充充电(本人已充)。
本文就大佬所讲内容、查阅资料、昇思api及结合自己理解进行记录。
前言
在了解Vision Transformer之前,我们需要先了解一下Transformer,Transformer最开始是应用在NLP领域的,拿过来用到Vision中就叫Vision Transformer。而这里要提到的,就是Transformer中的self-Attention(自注意力)和Multiple-Head Attention(多头注意力)。
用在NLP领域中用到的注意力机制举例,一般为Encoder-Decoder框架,比如中英翻译,输入的英文是Source,我们要获取到的是Target(中文翻译),Attention机制就发生在Target的元素Query和Source中的所有元素之间,其同时关注自身和目标值。
而这里说的自注意力机制只关注自身,比如Source中会有一个注意力机制,Target中会有一个注意力机制,他两是没有关系的。
还是用中英翻译举例,注意力机制的查询和键分别来自于英文和中文,通过查询(Query)英文单词,去匹配中文汉字的键(Key),自注意力机制只关注自己一个语言,可以理解为:"我喜欢"后面可以跟"你",也可以跟"吃饭"。
1)如果查询和键是同一组内的特征,并且相互做注意力机制,则称为自注意力机制或内部注意力机制。
2)多头注意力机制的多头表示对每个Query和所有的Key-Value做多次注意力机制。做两次,就是两头,做三次,就是三头。这样做的意义在于获取每个Query和所有的Key-Value的不同的依赖关系。
3)自注意力机制的优缺点简记为【优点:感受野大。缺点:需要大数据。】
以下是关于这两个自注意力机制的官方公式,很复杂也很难理解,但现在别盯着他不放,先慢慢往下看,这篇就是说明这个公式及其过程:

Self-Attention
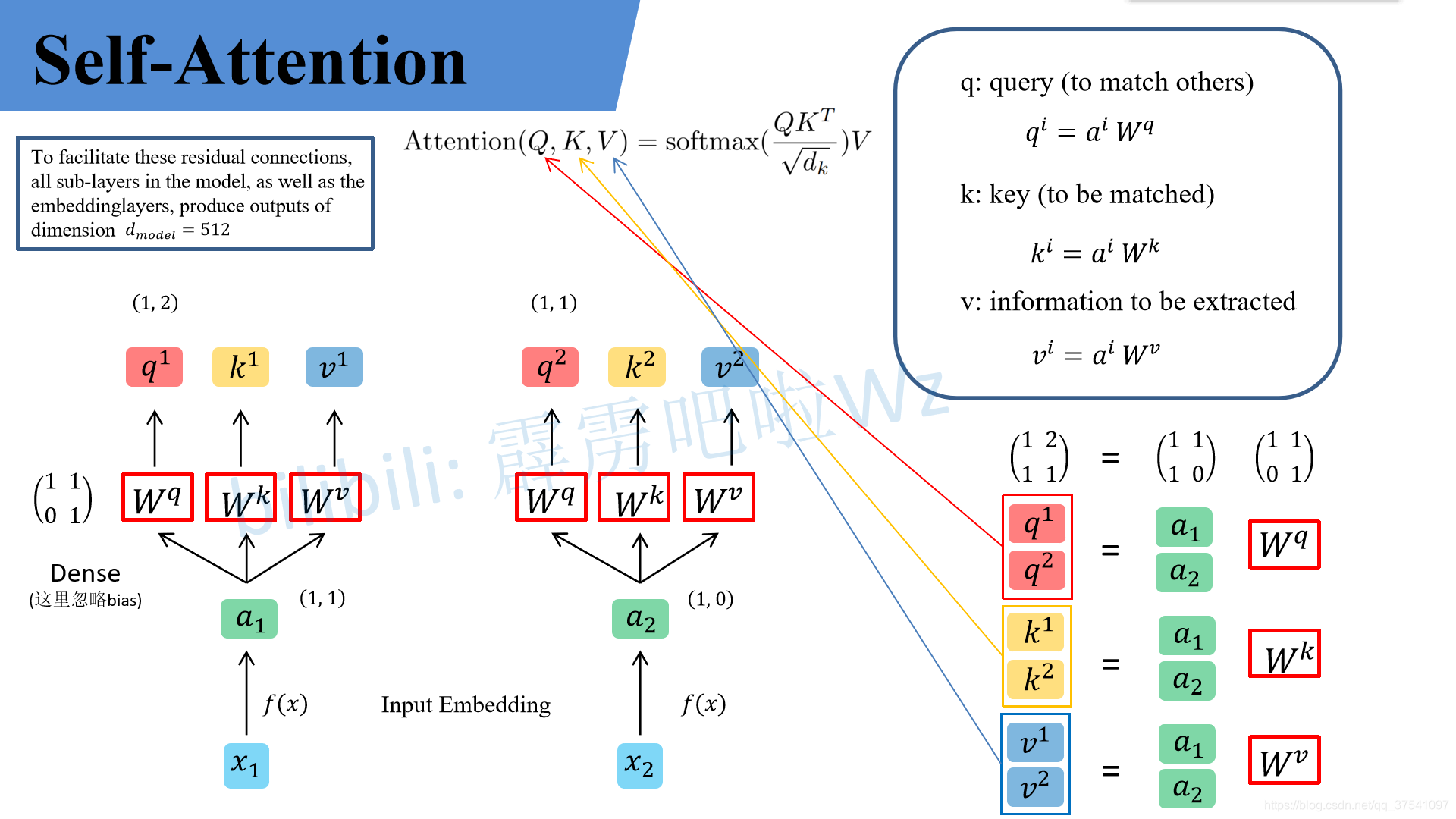
我们先说明白这里面这些符号都是干啥的,或者求出来用来干啥的,避免看半天还一头雾水:
q代表query,后续会去和每一个k进行匹配
k 代表key,后续会被每个q匹配
v 代表从a中提取得到的信息,后续会和q和k的乘积进行运算
d是k的维度
后续q 和k匹配的过程可以理解成计算两者的相关性,相关性越大对应v的权重也就越大
简单来说,最初的输入向量首先会经过Embedding层映射成Q(Query),K(Key),V(Value)三个向量,由于是并行操作,所以代码中是映射成为dim x 3的向量然后进行分割,换言之,如果你的输入向量为一个向量序列(𝑥1,𝑥2,𝑥3),其中的𝑥1,𝑥2,𝑥3都是一维向量,那么每一个一维向量都会经过Embedding层映射出Q,K,V三个向量,只是Embedding矩阵不同,矩阵参数也是通过学习得到的。这里大家可以认为,Q,K,V三个矩阵是发现向量之间关联信息的一种手段,需要经过学习得到,至于为什么是Q,K,V三个,主要是因为需要两个向量点乘以获得权重,又需要另一个向量来承载权重向加的结果,所以,最少需要3个矩阵。
后续我们要用q*k得到v的权重,然后进行一定缩放(除以根号d),再乘上v,就是第一个公式。
从数值上理解
wk我悟了,用引用的话行内公式不会乱
假设 a 1 = ( 1 , 1 ) a_1=(1,1) a1=(1,1), a 2 = ( 1 , 0 ) a_2=(1,0) a2=(1,0), W q = ( 1 1 0 1 ) W^q=\binom{1 \ \ \ 1}{0 \ \ \ 1} Wq=(0 11 1),那么根据以上的说法,我们可以计算出 q 1 q^1 q1、 q 2 q^2 q2。
q 1 = ( 1 , 2 ) ( 1 1 0 1 ) = ( 1 , 2 ) , q 2 = ( 1 , 0 ) ( 1 1 0 1 ) = ( 1 , 1 ) q^1=(1,2)\binom{1 \ \ \ 1}{0 \ \ \ 1}=(1,2),q^2=(1,0)\binom{1 \ \ \ 1}{0 \ \ \ 1}=(1,1) q1=(1,2)(0 11 1)=(1,2),q2=(1,0)(0 11 1)=(1,1)此时可以并行化,就是把 q 1 q^1 q1和 q 2 q^2 q2在拼接起来,拼成 ( 1 1 1 0 ) \binom{1 \ \ \ 1}{1 \ \ \ 0} (1 01 1),在与 W q W^q Wq进行运算,结果不会发生改变
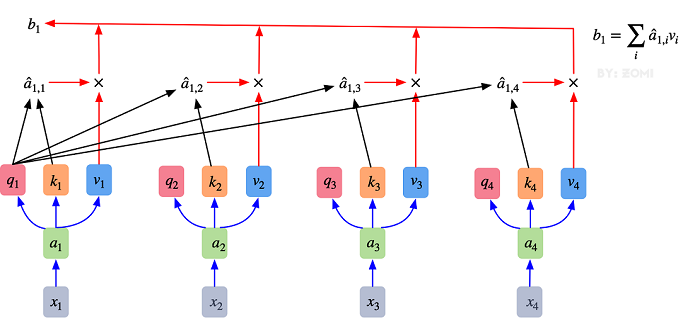
( q 1 q 2 ) = ( 1 1 1 0 ) ( 1 1 0 1 ) = ( 1 2 1 1 ) \binom{q^1}{q^2}=\binom{1 \ \ \ 1}{1 \ \ \ 0}\binom{1 \ \ \ 1}{0 \ \ \ 1}=\binom{1 \ \ \ 2}{1 \ \ \ 1} (q2q1)=(1 01 1)(0 11 1)=(1 11 2)同理可以得到 ( k 1 k 2 ) \binom{k^1}{k^2} (k2k1)和 ( v 1 v 2 ) \binom{v^1}{v^2} (v2v1),求得的这些数值依次是q(Query),k(Key),v(Value)。接着先拿 q 1 q^1 q1和每个k进行match,点乘操作,接着除以 d \sqrt{d} d ,得到对应的 α \alpha α,,其中 d d d代表向量 k i k^i ki的长度,此时等于2,除以 d \sqrt{d} d 的原因在论文中的解释是"进行点乘后的数值很大,导致通过softmax后梯度变的很小,所以通过除以 d \sqrt{d} d 来进行缩放,比如计算 α 1 , i \alpha_{1,i} α1,i:
α 1 , 1 = q 1 ⋅ k 1 d = 1 ∗ 1 + 2 ∗ 0 2 = 0.71 \alpha_{1,1}=\frac{{q^1} \cdot {k^1}}{\sqrt{d}}=\frac{1*1+2*0}{\sqrt2}=0.71 α1,1=d q1⋅k1=2 1∗1+2∗0=0.71α 1 , 2 = q 1 ⋅ k 2 d = 1 ∗ 0 + 2 ∗ 1 2 = 1.41 \alpha_{1,2}=\frac{{q^1} \cdot {k^2}}{\sqrt{d}}=\frac{1*0+2*1}{\sqrt2}=1.41 α1,2=d q1⋅k2=2 1∗0+2∗1=1.41
同理用 q 2 q^2 q2去匹配所有的k能得到 α 2 , i \alpha_{2,i} α2,i,统一写成矩阵乘法形式:
( α 1 , 1 α 1 , 2 α 2 , 1 α 2 , 2 ) = ( q 1 q 2 ) ( k 1 k 2 ) T d \binom{\alpha_{1,1} \ \ \ \alpha_{1,2}}{\alpha_{2,1} \ \ \ \alpha_{2,2}}=\frac{\binom{q^1}{q^2}{\binom{k^1}{k^2}}^T}{\sqrt{d}} (α2,1 α2,2α1,1 α1,2)=d (q2q1)(k2k1)T然后对每一行即 ( α 1 , 1 , α 1 , 2 ) (\alpha_{1,1},\alpha_{1,2}) (α1,1,α1,2)分别进行softmax处理得到KaTeX parse error: Expected 'EOF', got '̂' at position 9: (\alpha ̲̂ _{1,1},\alpha ...,这里的\\alpha ̂ 相当于计算得到针对每个 相当于计算得到针对每个 相当于计算得到针对每个v 的权重,到这我们就完成了第一个公式( 的权重,到这我们就完成了第一个公式( 的权重,到这我们就完成了第一个公式(Attention(Q,K,V) )中的 )中的 )中的softmax(\\frac{QK\^T}{\\sqrt{d}})部分
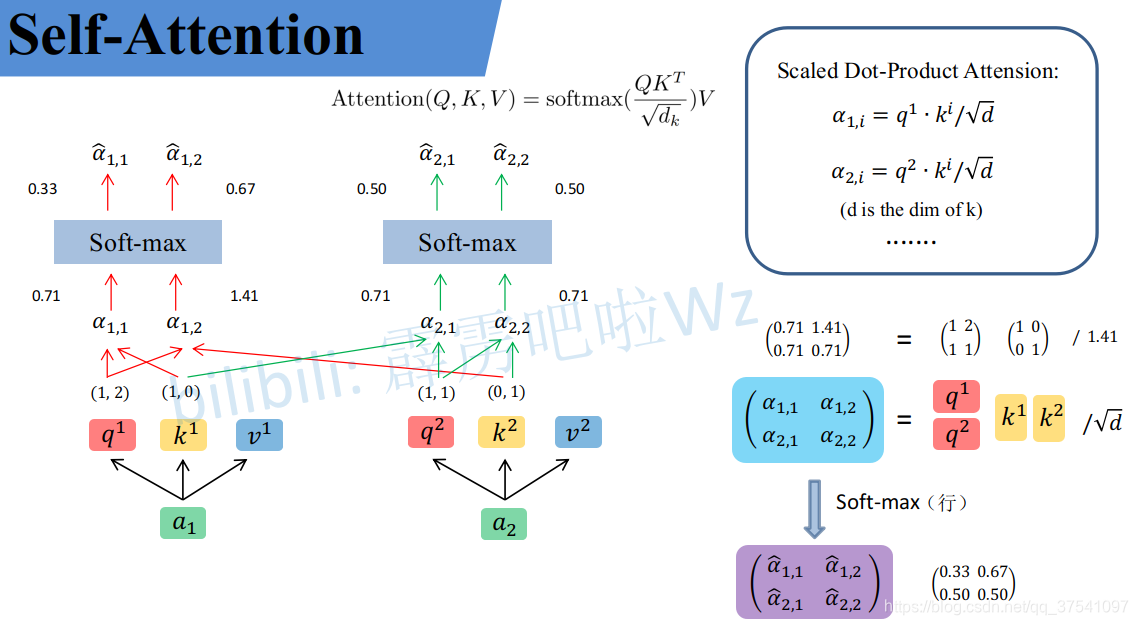
为啥这里又乱了。。

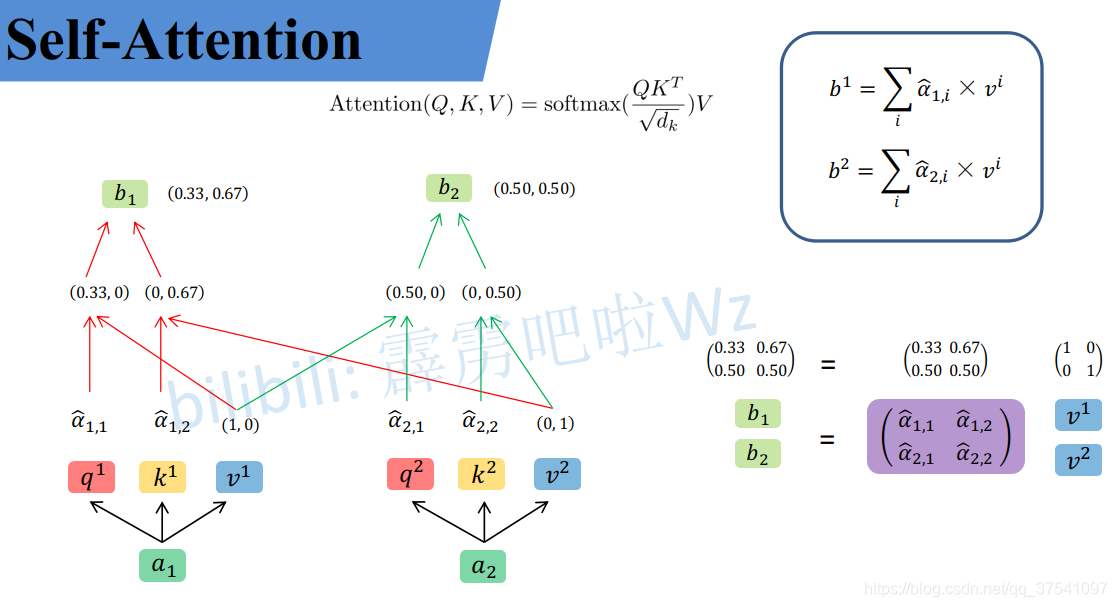
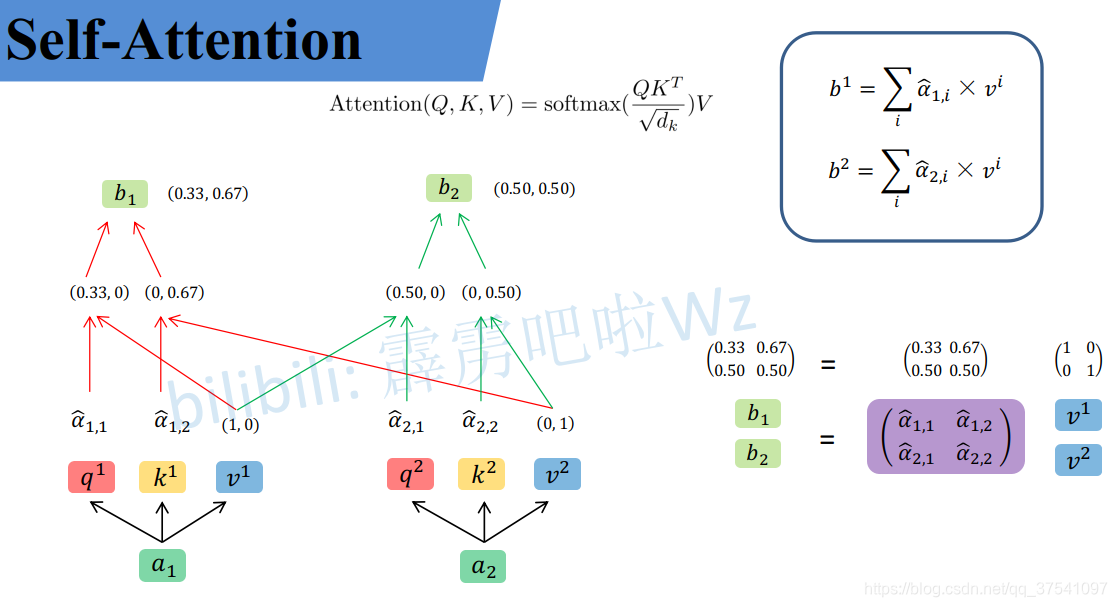
从维度上进行理解
我们假设载入的 x 1 x_1 x1经过Embedding后变为 a 1 a_1 a1维度为1X4, W q W^q Wq的维度为4X3,两者进行叉乘运算后就得到了维度为1X3的Query,k和v同理
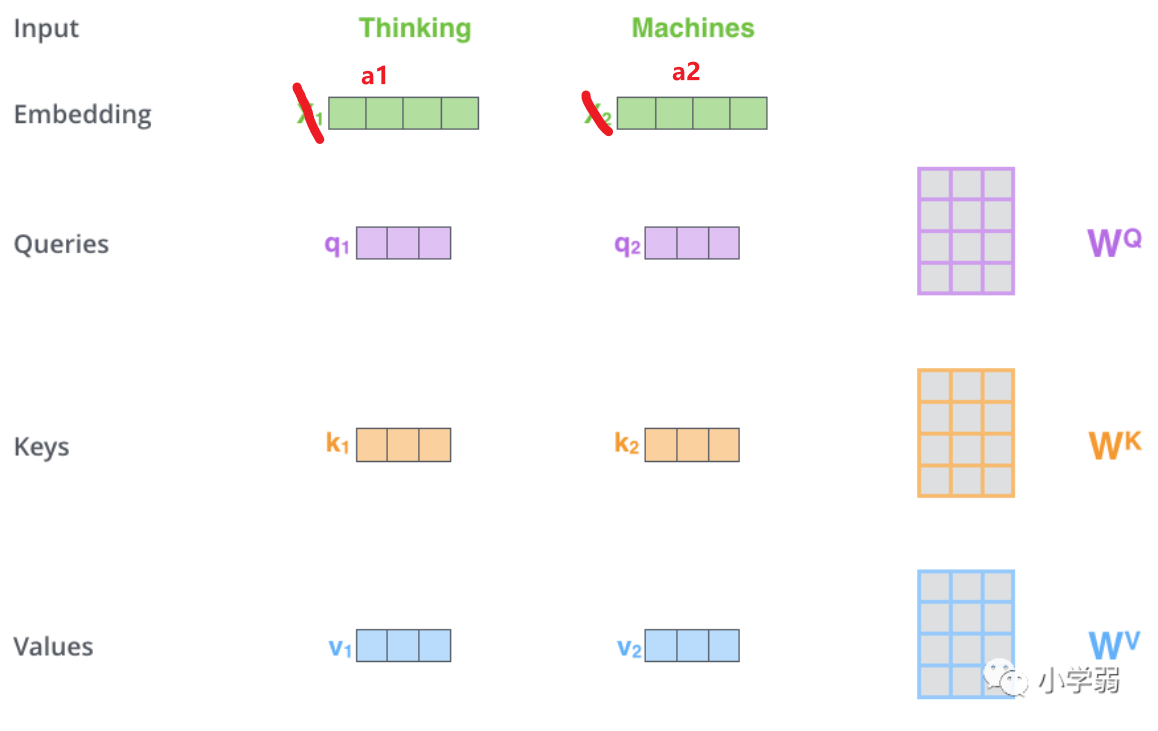
然后我们吧a1和a2并行起来
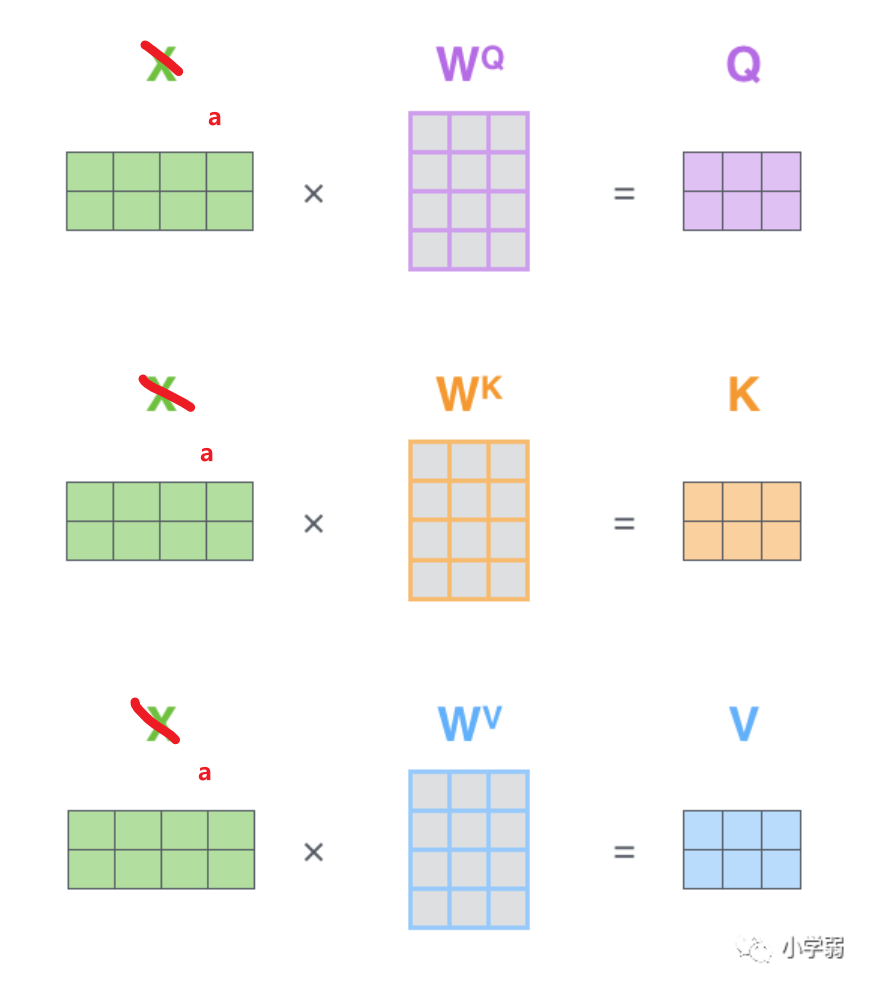
然后把公式中的式子也换成维度:
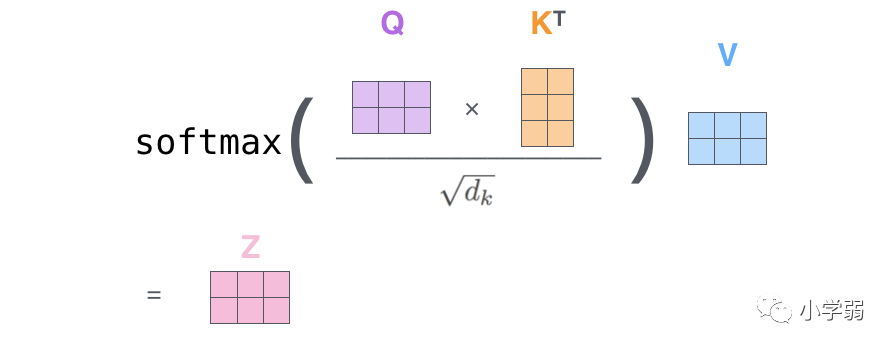
整个过程放在一张图上可以这么看:
这里暂时不附代码,Multiple-Head Attention下篇记录。
打卡图片:
参考博客:
11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili
详解Transformer中Self-Attention以及Multi-Head Attention_transformer multi head-CSDN博客
一文搞定自注意力机制(Self-Attention)-CSDN博客
以上图片均引用自以上大佬博客,如有侵权,请联系删除