本章节学习一个基本实践--基于Mindspore实现BERT对话情绪识别
自然语言处理任务的应用很广泛,如预训练语言模型例如问答、自然语言推理、命名实体识别与文本分类、搜索引擎优化、机器翻译、语音识别与合成、情感分析、聊天机器人与虚拟助手、文本摘要与生成、信息抽取与知识图谱、个性化推荐等等很多方面。
BERT模型是比较基础的典型的语言模型,创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
1、在用Masked Language Model方法训练BERT的时候,随机把语料库 中15%的单词做Mask操作。
2、对于这15%的单词做Mask操作分为三种情况:80%的单词直接用Mask替换、10%的单词直接替换成另一个新的单词、10%的单词保持不变。
Next Sentence Prediction:训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,BERT模型预测B是不是A的下一句。因为涉及到Question Answering (QA) 和 Natural Language Inference (NLI)之类的任务,增加了Next Sentence Prediction预训练任务,目的是让模型理解两个句子之间的联系。
对话情绪识别(Emotion Detection,简称EmoTect):识别智能对话场景中用户的情绪。针对智能对话场景中的用户文本,自动判断该文本的情绪类别并给出相应的置信度,情绪类型分为积极、消极、中性。 对话情绪识别适用于聊天、客服等多个场景,能够帮助企业更好地把握对话质量、改善产品的用户交互体验,也能分析客服服务质量、降低人工质检成本。
安装mindnlp库并查看相关信息

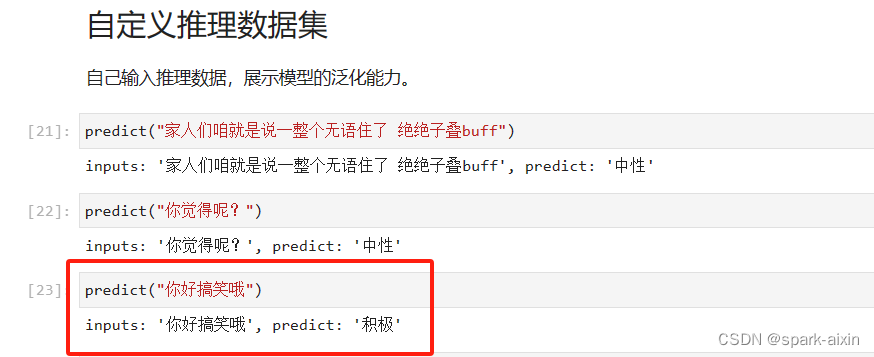
训练完测试了2个,感觉第二个好像不太对,可能有些词看语境和语调吧,模型只能看表象
此章节学习到此结束,感谢昇思平台。