初始

"我们需要走得更深"这句台词出自电影《盗梦空间》。这是在讨论深入梦境更深层次时说的,暗示需要探索梦境的更深层次。虽然这似乎是不可能的,但它传达的理念是,要创造一个新的世界,就必须冒险进入更深的层次。
电影《盗梦空间》为深度学习提供了一个生动的比喻。
角色"菲舍尔"代表网络的输入数据。我们用原始输入数据训练网络,以实现预期结果(摧毁他父亲的帝国)。能让他们留在梦中的催梦药与激活函数相似(事实上,没有激活函数,深度网络就无法实现)。
柯布的妻子"Mal"是电影中的主要挑战之一,扰乱了运营;我们可以将"Mal"视为消失的不稳定梯度 或损失函数。我们努力计算并最小化网络中的损失函数。深度网络中消失的不稳定梯度使权重(W)的导数更接近零,阻碍权重更新,造成中断,甚至停止网络。
"彼得叔叔"可以被认为是网络的偏见,因为它的缺失可能会导致一些神经元保持不活跃状态(想象一下根据神经元活动找到安全且令人信服的菲舍尔执行的组合)。
"Cobb" 和他的团队代表网络架构,因为他们的方法决定了任务的进度和执行。
梦境层类似于网络层;我们越深入,层数就越多。本质上,我们钻研得越深,遇到的问题就越多,但我们也可以从中得出必要的结果。
整部电影可以看作是前馈阶段,在此阶段确定权重、偏差和输出,然后是梦境阶段,类似于反向传播,在此阶段更新权重和偏差,从而导致在菲舍尔的脑海中植入摧毁父亲帝国的想法的预期结果。
在本文中,我们旨在更深入地探究神经网络的深度,并更好地理解其功能。和我一起开始吧。
本文分为三部分:
第一部分:人工智能的历史以及简单神经网络的工作原理。
第二部分:深度神经网络中的学习机制(学习类型、激活函数和反向传播)。
第三部分:深度神经网络的主要架构(RNN/LSTM/CNN)。
在这三部分中,我们将讨论以下主题:什么是人工神经网络,它们如何工作,什么是深度学习,深度网络中如何进行学习,以及学习方法的类型有哪些。深度网络的主要架构是什么?人工神经网络的功能是否与人类神经网络相似,还是仅仅受到它们的启发?神经网络有哪些应用,以及它们的缺点是什么?
概述
现在你正在阅读这篇文章,信息正通过你的眼睛,使用复杂的神经网络和神经元,被发送到你的大脑。大脑的不同部分,包括海马体、额叶、顶叶、颞叶等,正在并行 、分层(顺序)地处理信息。当然,大脑中发生的信息处理过程要复杂得多。
神经网络的历史
神经元
神经元是神经系统的主要细胞,它们相互之间以及与身体其他部位之间传递信息。可以说,人类的神经系统中有大约1000 亿个神经元;事实上,信息交换和身体连贯性都依赖于神经元。19 世纪初,人们对神经元及其功能进行了广泛的研究。目标是探索机器学习的潜力。
开始
1943 年,神经生理学家Warren McCulloch和年轻数学家Walter Pitts开发出第一个神经网络模型,这是人工神经网络的第一步。他们发表了一篇题为《神经活动中内在思想的逻辑演算》的论文,提出了一个假设,即神经活动可以看作是一个逻辑过程(能够执行 AND、OR 和 NOT 等逻辑运算的电路)。本质上,他们的模型的结果是简单的逻辑函数,具有神经活动的"全有或全无"特征。
感知器
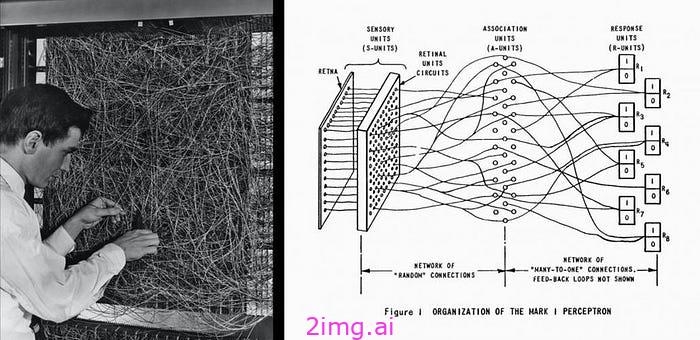
1957 年,美国心理学家Frank Rosenblatt在康奈尔航空实验室制造了第一台可操作的感知机 Mark I。1958 年,他发表了一篇论文,题为"感知机:大脑中信息存储和组织的概率模型"。Rosenblatt 的感知机是一个二元单神经元模型,被认为是第一代神经网络。它的主要局限性是无法解决非线性可分离问题。
艾达琳(ADALINE)
ADALINE(自适应线性神经元或后来的自适应线性元素)是继感知器之后开发的下一个模型。它由斯坦福大学的Bernard Widrow教授和他的博士生Ted Hoff于 1960 年创建。ADALINE 采用具有线性激活函数(使用最小均方学习规则)的感知器。它是一个具有多个节点的单层神经网络,每个节点接受多个输入并产生一个输出。ADALINE 与标准 McCulloch-Pitts 感知器之间的主要区别在于学习过程:ADALINE 可以学习线性函数,而标准感知器只能学习非线性函数。
冬天来了...

由 DALEE-3 生成
第一个人工智能寒冬是人工智能研究投资和兴趣减少的时期,从 20 世纪 60 年代末持续到 80 年代中期。1969 年,明斯基和帕普特撰写了一本名为《感知器:计算几何学导论》的书,作为诋毁人工智能研究运动的一部分。他们概括了一些基本问题,例如单层感知器的局限性。尽管作者们很清楚,强大的感知器有多层,而罗森布拉特最初的感知器有三层,但他们将感知器定义为只能处理线性可分问题的两层机器,例如,无法解决异或问题。
1973 年,一份评估人工智能学术研究的《莱特希尔报告》发布。在此之前,人工智能研究一直饱受批评,认为人工智能研究从根本上未能实现其崇高目标。这份报告导致英国停止了对人工智能的资金支持,标志着第一次人工智能寒冬的开始。
1956 年至 1974 年间,国防高级研究计划局 (DARPA) 继续资助一些项目,例如逐字机器翻译俄语到英语,以及使用由感知器组成的神经网络教计算机下跳棋(该神经网络模仿了人类大脑神经元的原始重复)。这些项目引起了大量人工智能炒作和广告。然而,随着人们对人工智能的关注度逐渐下降,可用预算也随之减少。
当时只有少数研究人员继续研究模式识别等问题。然而,这一时期的努力仍在继续。1972 年,克洛普夫 (Klopf) 根据生物学原理为人工神经元的学习奠定了基础。保罗·韦伯斯 ( Paul Werbos)于 1974 年开发了反向传播学习方法,尽管直到 1986 年人们才完全理解其重要性。福岛邦彦 (Kunihiko Fukushima)开发了一种逐步训练的多层神经网络,用于解释手写字符。他于 1975 年发表了论文" Cognitron:一种自组织的多层神经网络"。
重生......
20 世纪 80 年代发生的几件大事重新激发了人们对人工智能的兴趣。科霍宁在人工神经网络领域做出了重大贡献。他引入了一种人工神经网络,有时被称为科霍宁映射或科霍宁网络。
1982 年,约翰·霍普菲尔德发表了一篇题为"具有新兴集体计算能力的神经网络和物理系统"的论文。霍普菲尔德描述了一种充当内容可寻址存储系统的循环人工神经网络。他的工作说服了数百名高技能的科学家、数学家和技术人员加入新兴的神经网络领域。
1985 年,美国物理学会发起了一个研讨会,后来演变成年度会议------计算神经网络。1987 年,现代史上第一个关于神经网络的公开会议举行。IEEE 的国际神经网络联合会议在圣地亚哥举行,国际神经网络学会 (INNS) 成立。1988 年,INNS 神经网络杂志成立,随后 1989 年出版了神经计算杂志,1990 年出版了 IEEE 神经网络学报。
经过一段时间的复苏后,又出现了另一次衰退。这最终导致了从 20 世纪 80 年代末到 90 年代中期的又一次人工智能寒冬。很难准确指出这些人工智能寒冬的开始和结束时间,但很明显,研究和努力带来了新的信心,开启了人机交互的新时代。其中一个促成因素是专家系统,但专家系统是什么?它们在今天仍然有用吗?请继续关注......
第一个专家系统
第一个专家系统出现于 20 世纪 70 年代,并在 20 世纪 80 年代变得更加流行。但专家系统到底是什么?专家系统是模拟人类专家决策能力的计算机系统。它们使用知识库和一组规则来做出决策或解决特定领域的问题。主要挑战是创造能够像人类一样思考并做出重要决策的机器。这导致人们将重点转向让机器学习和做出决策。
专家系统面临的主要挑战之一是训练它们所需的数据的收集、准备和成本。它们的知识库需要大量数据,而这些数据不像今天这样容易获得。此外,这些系统没有为需要创造力和创新的问题提供解决方案。那么,解决方案是什么呢?
宗师败了!
"大师输了"!1997年震惊世界的新闻是,国际象棋世界冠军不是被另一位大师打败,而是被一台机器打败。深蓝,一个专家级的国际象棋系统,最初由卡内基梅隆大学开发,后来被IBM收购。1996年,卡斯帕罗夫成功击败了它,但在1997年,深蓝进行了升级,以2胜3平的成绩击败了卡斯帕罗夫。可以说,深蓝标志着人工智能的一个转折点,再次重塑了人们对机器学习和人工智能的看法。这一事件也彻底改变了游戏行业。
AlphaGo 是 DeepMind 开发的一款围棋计算机程序。2016 年,它击败了职业围棋选手李世石,并拍摄了一部名为" AlphaGo --- The Movie | 完整获奖纪录片"的纪录片。围棋游戏的一个显著特点是其可能性数量庞大,远远超过国际象棋。虽然国际象棋有大约 10¹²⁰ 种可能性,但据估计,围棋游戏中大约有 10⁷⁶¹ 种可能状态。
在本节中,我们将介绍各种类型的神经网络并讨论它们的一些不同应用。敬请关注!
人工神经网络(ANN)
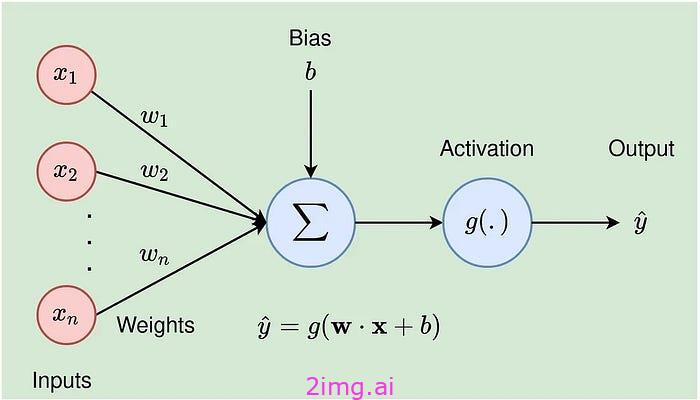
Medium 上一篇文章中图片的来源。
可以说,人工神经网络 (ANN) 或模拟神经网络 (SNN) 具有由输入数据、权重、偏差或阈值以及输出组成的一般结构。它们包括节点和层,包括输入层、一个或多个隐藏层以及输出层,这些层是相互通信并从训练数据中学习的互连层。它们形成一个网络,它们执行的计算最终表示输出中权重 (w) 最高的概率。下面是对人工神经网络组件的一般检查,其中可能包含更多组件,但最重要的是:
输入
它由一组输入到网络中的数据(即特征)组成。(根据问题的类型,这些数据可以是结构化数据或非结构化数据)。ANN 中的输入层是神经网络中唯一将所有接收到的信息不经任何处理就传输到下一层的层。
隐藏层
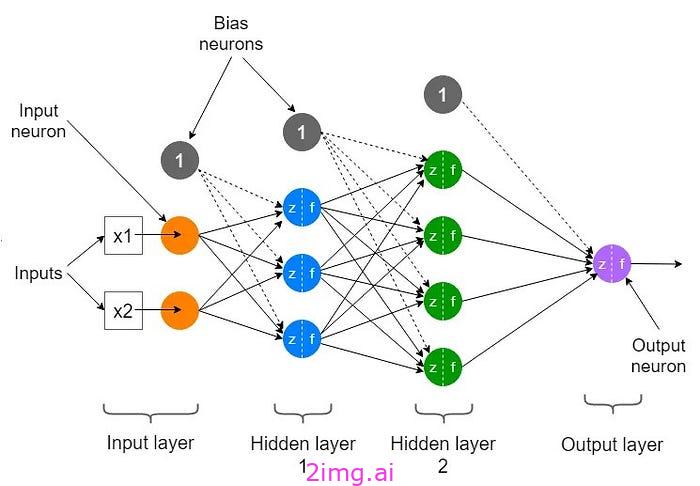
是的,深度神经网络中的隐藏层就像黑匣子。这意味着我们可能无法轻松解释或详细解释每个神经元或隐藏层的精确功能。事实上,深度学习和传统机器学习模型之间最重要的区别在于特征选择。在深度学习中,机器决定学习哪些特征并做出决策。我们几乎不知道机器如何选择这些特征以及为什么选择这些特征。这些是进行大多数计算的中间层,从数据中提取特征。
重量(W)
它们是基本参数,对人工网络的学习和预测能力起着至关重要的作用。权重是可变的,在网络的训练过程中可能会发生变化。权重是与神经元(或节点)之间的连接相关的数值,表示一个神经元对另一个神经元的影响的强度和方向(正或负),可以有正值或负值。负权重可以防止过度拟合,因为它们有助于网络减少不必要的信息并提取更一般的模式。
偏见
在神经网络中,偏差是分配给每个神经元并在训练过程中更新的可学习参数。实际上,它通过向输入添加一个常数(即给定的偏差)来改变激活函数。它在训练期间更新。神经网络中的偏差可以被认为类似于线性函数y = wx + b中的常数,其中 b 是添加的偏差值,有效地用常数值移动线。
除了防止归零之外,偏差还可以防止过度拟合。当神经网络与其训练数据过于兼容时,就会发生过度拟合,并允许神经网络从其训练数据中学习,而不仅仅是随机细节。
输出层
输出层是决定网络最终结果的地方,因此它是最重要的层。它使用从隐藏层获得的结果执行此任务。一般来说,无论激活函数是否递归,成本函数,它们都在输出层中,并且根据网络类型和我们期望从中得到的任务,输出层是非常决定性的。在具有反向传播的架构中,反向传播过程从输出层向输入层执行。