1.通道注意力
通道注意力(Channel Attention)是在通道维度上对输入数据进行学习,再对不同的通道分配相应的权重表示重要性,从而达到"分配注意力"的效果。SENet(Squeeze and Excitation networks) 是一个典型的使用通道注意力的网络结构,其中核心部分SE模块如下图所示。它使用了压缩和激励机制,在压缩阶段额外引出一个分支,该分支压缩全局空间信息学习到特征权重,此权重可以视作不同通道所分配的"注意力",越重要的通道获得的权重越大,集中分配更多的资源训练学习。在激励阶段将这些特征权重和 主干分支特征进行元素相乘,提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道。
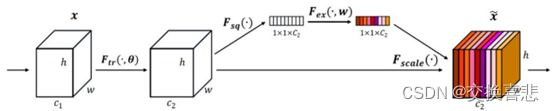
学习通道之间的相关性,自适应地重新校准通道地特征相应
SENet:
1.Squeeze :全局平均池化: C × H × W C \times H \times W C×H×W压缩为 C × 1 × 1 C \times 1 \times 1 C×1×1
2.Excitation: 两层全连接+sigmoid() 限制到 0,1
3.特征重标定:Exciation的结果作为权重乘到U上
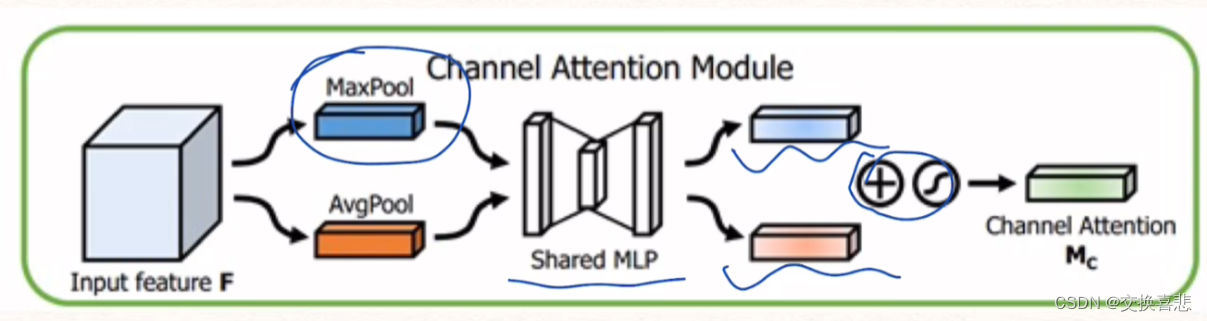
code:
python
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_planes, in_planes // ratio),
nn.ReLU(),
nn.Linear(in_planes // ratio, in_planes)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x).view(x.size(0), -1))
max_out = self.fc(self.max_pool(x).view(x.size(0), -1))
out = self.sigmoid(avg_out + max_out)
return out2.空间注意力(Spatial Attention)
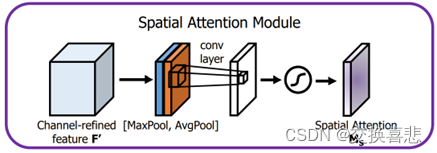
空间注意力对图片上不同的区域赋予不同的权重,致力于寻找图像中任务处理最关键的部分。空间注意力的实施主要有两个步骤,首先在特征不同的通道上进行平均池化或最大池化,对比不同通道之间的像素值,来获得该像素点不同通道上最重要的部分。第二个步骤是将生成后的特征描述作为神经网络中卷积层和激活层的输入,最终得到空间注意特征图。
code:
python
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size//2)
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.conv(out)
out = torch.sigmoid(out)
return out3.CBAM
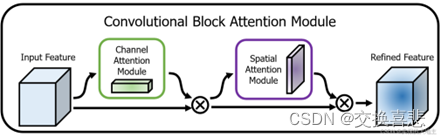
CBAM是一种用于增强卷积神经网络(CNN)性能的注意力机制模块。如上图所示,CBAM的主要目标是通过在CNN中引入绿色框所示的通道注意力和紫色框所示的空间注意力来提高模型的感知能力,从而在不增加网络复杂性的情况下改善性能。两个子模块的计算如下:
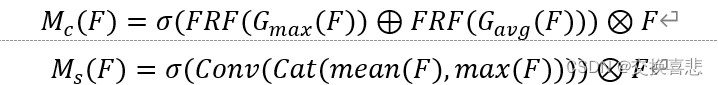
其中,F为输出,G_max (∙)和G_avg (∙)表示最大池化和平均池化,mean(F)和max(F)表示在通道维度上采用平均函数和最大值函数。FRF是一个多层感知机。CBAM就是将通道注意力模块和空间注意力模块的输出特征逐元素相乘,得到最终的注意力增强特征。这个增强的特征将用作后续网络层的输入,以在保留关键信息的同时,抑制噪声和无关信息。
code:
python
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
out = x * self.ca(x) # channel attention
out = out * self.sa(out) # spatial attention
return out