概念
聚类是按照某个特定标准把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性尽可能大
聚类的过程
- 数据准备:特征标准化和降维
- 特征选择:从最初的特征中选择最有效的特征,并将其存储在向量中
- 特征提取:通过对选择的特征进行转换形成新的突出特征
- 聚类:基于某种距离函数 进行相似度度量,获取簇
- 聚类结果评估:分析聚类结果,如距离误差和等
聚类方法
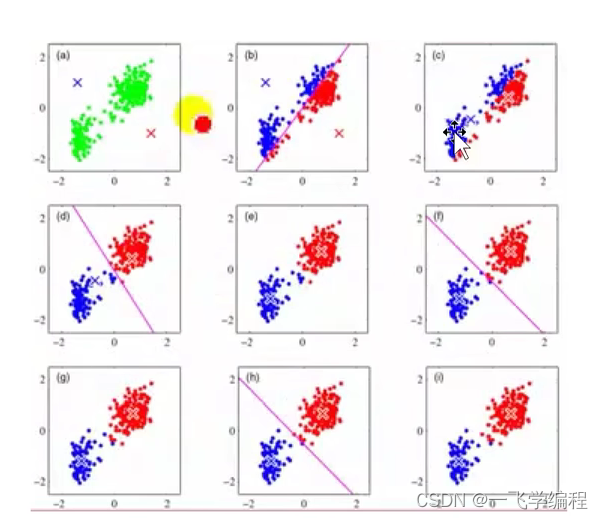
1.划分类聚类方法
代表:k-means算法
基本思想:对于给定的类别数据k首先给出初始划分 ,通过迭代 改变样本和簇的隶属关系,使得每一次改进后的划分方法都比前一次更好
优点:简单快速;当簇近似于高斯分布时效果好
缺点:在簇的平均值 可被定义时才能使用;对初值敏感
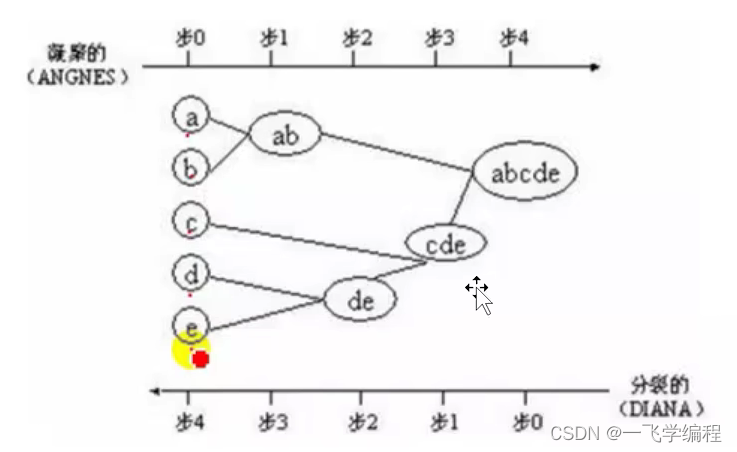
2.层次聚类方法 :对给定的数据集进行层次的分解 ,直到满足某种条件为止
如下图所示,由于a、b某特征有相似之处,将他们聚类一类,以此类推
特征:对噪声敏感
3.基于密度的聚类方法

典型算法:DBSCAN算法
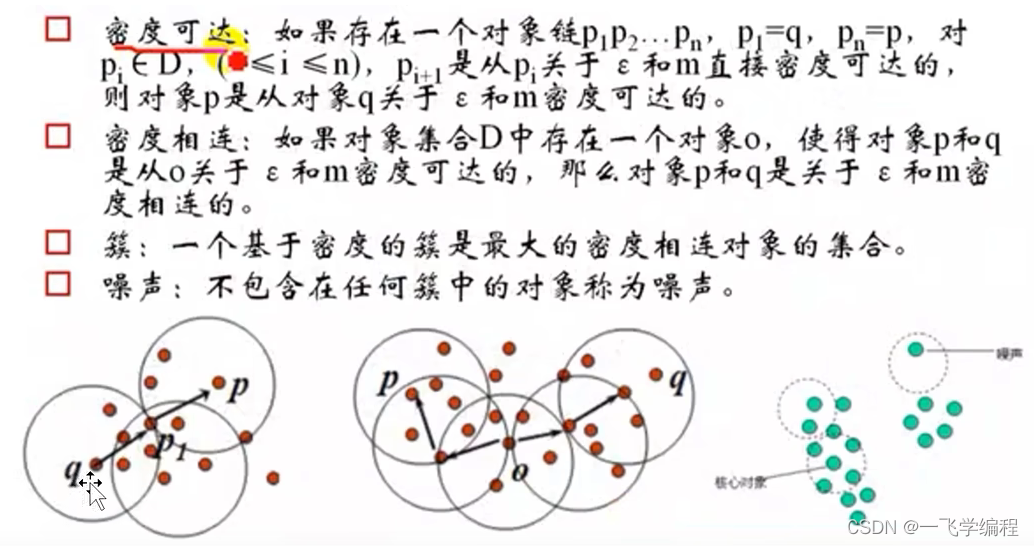
特点:抗噪效果好;性能一般
聚类算法效果评判
- 均一性:聚类结果的一致性或者稳定性
- 完整性:聚类结果 与真实类别或标签之间的一致性
- V-measure:综合考虑了均一性 和完整性
- ARI:比较了聚类结果与真实类别之间的一致性,考虑了分类中的随机性因素
- AMI:聚类结果与真实类别之间的一致性,同时考虑了类别分布的随机性
- 轮廓系数:结合了聚类的紧密度(密度 )和分离度(分散度)