1、概念
多租户对应的是单租户,本篇文章重点讲解多租户,单租户为了解内容。
1.1 多租户
多租户技术或称多重租赁技术,简称SaaS,是一种软件架构技术,是实现如何在多用户环境下(此处的多用户一般是面向企业用户)共用相同的系统或程序组件,并且可确保各用户间数据的隔离性。简单讲:在一台服务器上运行单个应用实例,它为多个租户(客户)提供服务。从定义中我们可以理解:多租户是一种架构,目的是为了让多用户环境下使用同一套程序,且保证用户间数据隔离。
1.2 单租户
单租户与多租户架构区别在于,单租户是为每个用户单独创建各自的软件应用和支撑环境。单租户SaaS被广泛引用在客户需要支持定制化的应用场合,而这种定制或者是因为地域,抑或是他们需要更高的安全控制。通过单租户的模式,每个客户都有一份分别放在独立的服务器上的数据库和操作系统,或者使用强的安全措施进行隔离的虚拟网络环境中。
1.3 单租户和多租户的区别
- 安全管控等级不同。多租户数据库存储来自多个独立租户的数据,虽然设置了安全隔离,但安全控制级别仍然高于单租户。由于单个租户拥有独立的软硬件环境,数据库也只存储一个租户的数据,技术上杜绝了数据泄露的可能,单租户架构有时更适合某些需要安全控制甚至法律合规性要求的行业。
- 数据备份复杂程度不同。单租户拥有独立的数据库,客户数据库的备份和恢复非常容易。而多租户是共用一个数据库,租户的数据既有隔离又有共享,系统不能每天自动执行企业的独立备份。
- 控制升级时间不同。多租户的系统维护成本低,多租户系统升级时,只需更新一次。维护人员不需要对每个用户更新,节省了大量运维成本。这对于所有客户都在做同样事情的系统来说是很有用的。但倘若系统升级时间是在企业特别忙碌的时候出现,势必会对企业用户造成影响。
应用场景:多租户适合同一集团(公司)下的,多个不同公司(部门),即使数据泄露也不会泄露到外面。
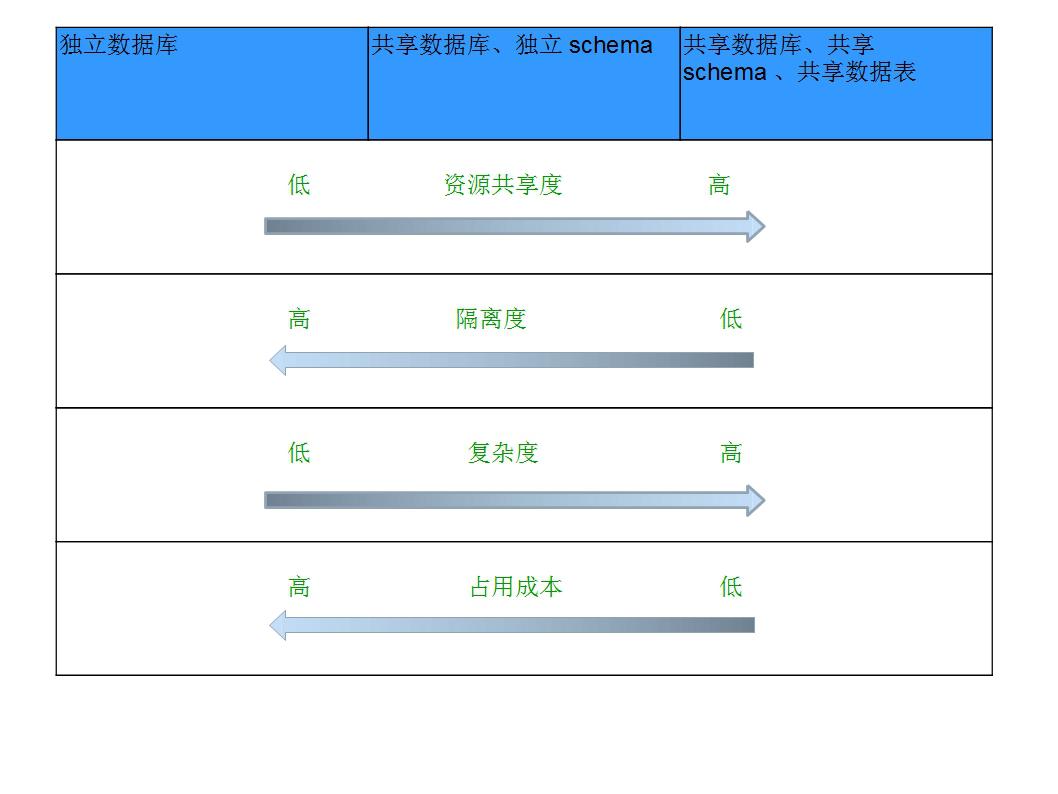
2、多租户数据隔离方案
- 独立数据库
- 共享数据库、独立Schema
- 共享数据库、共享Schema、共享数据表
2.1 独立数据库
这是第一种方案,即一个租户一个数据库,这种方案的用户数据隔离级别最高,安全性最好,但成本较高。
- 优点:为不同的租户提供独立的数据库,有助于简化数据模型的扩展设计,满足不同租户的独特需求;如果出现故障,恢复数据比较简单。
- 缺点: 增多了数据库的安装数量,随之带来维护成本和购置成本的增加。
这种方案与传统的一个客户、一套数据、一套部署类似,差别只在于软件统一部署在运营商那里。如果面对的是银行、医院等需要非常高数据隔离级别的租户,可以选择这种模式,提高租用的定价。如果定价较低,产品走低价路线,这种方案一般对运营商来说是无法承受的。
2.2 共享数据库,独立 Schema
这是第二种方案,即多个或所有租户共享Database,但是每个租户一个Schema(也可叫做一个user)。底层库比如是:DB2、ORACLE等,一个数据库下可以有多个SCHEMA
- 优点: 为安全性要求较高的租户提供了一定程度的逻辑数据隔离,并不是完全隔离;每个数据库可支持更多的租户数量。
- 缺点: 如果出现故障,数据恢复比较困难,因为恢复数据库将牵涉到其他租户的数据; 如果需要跨租户统计数据,存在一定困难。
2.3 共享数据库,共享 Schema,共享数据表
这是第三种方案,即租户共享同一个Database、同一个Schema,但在表中增加TenantID多租户的数据字段。这是共享程度最高、隔离级别最低的模式 。
即每插入一条数据时都需要有一个客户的标识。这样才能在同一张表中区分出不同客户的数据。
- 优点:三种方案比较,第三种方案的维护和购置成本最低,允许每个数据库支持的租户数量最多。
- 缺点: 隔离级别最低,安全性最低,需要在设计开发时加大对安全的开发量; 数据备份和恢复最困难,需要逐表逐条备份和还原。如果希望以最少的服务器为最多的租户提供服务,并且租户接受牺牲隔离级别换取降低成本,这种方案最适合。
2.4 总结
在SaaS实施过程中,有一个显著的考量点,就是如何对应用数据进行设计,以支持多租户,而这种设计的思路,是要在数据的共享、安全隔离和性能间取得平衡。三种模式的特点可以用一张图来概括