任务描述
任务内容为安装和配置Flume,并测试收集流式数据。
任务指导
Flume常被用作实时收集数据的工具,可以将收集的数据存储到HDFS或者像Kafka这样的消息队列中
具体安装步骤如下:
-
解压缩Flume的压缩包
-
配置Flume的环境变量
-
修改Flume的配置文件,Flume的配置文件存放在Flume安装目录下的conf中
-
通过远程登录方式获得Flume收集的数据
-
将Flume收集的数据存储到HDFS中
任务实现
1. 安装Flume
可以在/opt/software/目录中找到该安装包,解压该安装包并把该安装包复制到/opt/app目录中
在master1上执行:
[root@master1 ~]# cd /opt/software/
[root@master1 software]# tar -xzf apache-flume-1.9.0-bin.tar.gz -C /opt/app/2. 设置Flume的环境变量
编辑/etc/profile文件,声明Flume的home路径和在path加入bin的路径:
export FLUME_HOME=/opt/app/apache-flume-1.9.0-bin
export PATH=$PATH:$FLUME_HOME/bin加载配置文件/etc/profile,并确认生效
[root@master1 ~]# source /etc/profile
[root@master1 ~]# echo $FLUME_HOME3、设置flume-env.sh配置文件
在$FLUME_HOME/conf 下复制改名flume-env.sh.template为flume-env.sh,修改conf/flume-env.sh配置文件
[root@master1 ~]# cd $FLUME_HOME/conf
[root@master1 conf]# cp flume-env.sh.template flume-env.sh
[root@master1 conf]# vi flume-env.sh在配置文件末尾追加如下内容 :
JAVA_HOME=/opt/app/jdk1.8.0_181
JAVA_OPTS="-Xms100m -Xmx200m -Dcom.sun.management.jmxremote"4、 验证安装(telnet)
修改flume-conf配置文件
在$FLUME_HOME/conf目录下修改flume-conf.properties.template文件,复制并改名为flume-conf.properties
[root@master1 ~]# cd $FLUME_HOME/conf
[root@master1 conf]# cp flume-conf.properties.template flume-conf.properties
[root@master1 conf]# vi flume-conf.properties修改flume-conf配置文件内容如下:
# The configuration file needs to define the sources, the channels and the sinks.
# Sources, channels and sinks are defined per agent, in this case called 'a1'
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# For each one of the sources, the type is defined
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#The channel can be defined as follows.
a1.sources.r1.channels = c1
# Each sink's type must be defined
a1.sinks.k1.type = logger
#Specify the channel the sink should use
a1.sinks.k1.channel = c1
# Each channel's type is defined.
a1.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100在Flume的安装目录下运行
[root@master1 conf]# cd $FLUME_HOME
[root@master1 apache-flume-1.9.0-bin]# flume-ng agent -c ./conf/ -f ./conf/flume-conf.properties -n a1 -Dflume.root.logger=INFO,console再打开一个终端,输入如下命令:
[root@master1 ~]# telnet localhost 44444
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.在终端中输入如下内容:
Hello World注:在CentOS运行telnet提示"command not found",使用yum install telnet进行安装
在原来的终端上查看,可以收到来自于telnet发出的消息
2021-06-25 10:16:14,386 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
2021-06-25 10:17:08,388 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 48 65 6C 6C 6F 20 57 6F 72 6C 64 0D Hello World. }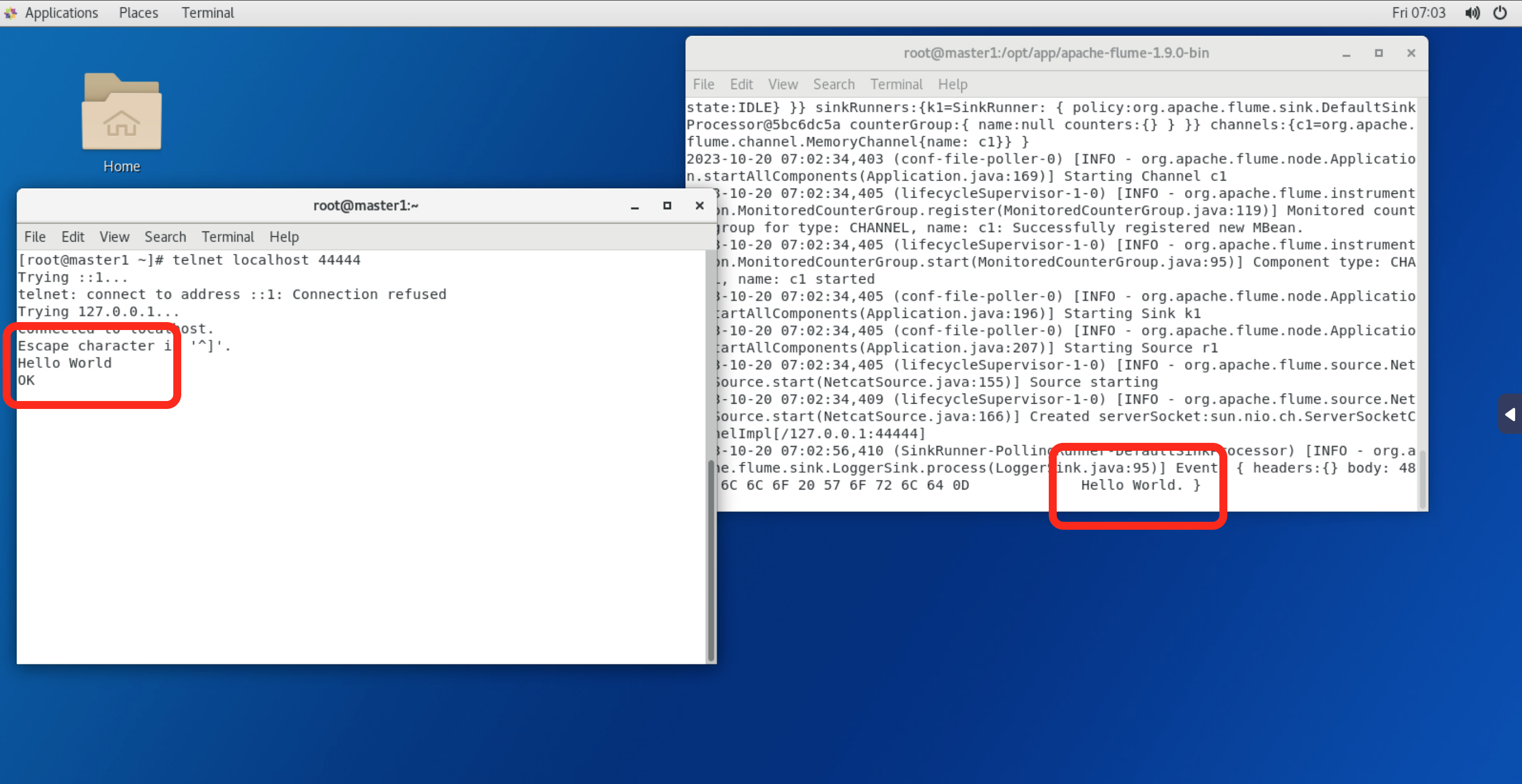
5. 测试收集日志到HDFS
在$FLUME_HOME/conf目录下新建hdfs-conf.properties文件
[root@master1 ~]# cd $FLUME_HOME/conf
[root@master1 conf]# touch hdfs-conf.properties修改hdfs-conf.properties文件内容如下,其中参数a1.sources.r1.command后的值为实时收集Hadoop的日志目录下的日志文件,这里需要根据真实情况修改文件名:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/app/hadoop-2.10.1/logs/hadoop-root-namenode-master1.novalocal.log
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://master1:9000/out_flume
a1.sinks.k1.hdfs.filePrefix=event
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1在Flume的安装目录下运行
[root@master1 conf]# cd $FLUME_HOME
[root@master1 apache-flume-1.9.0-bin]# flume-ng agent -c ./conf/ -f ./conf/hdfs-conf.properties -n a1 -Dflume.root.logger=INFO,console查看HDFS中/out_flume中的文件
# hdfs dfs -ls /out_flume
# hdfs dfs -cat /out_flume/event-*