文章目录
- [第一部分 优化](#第一部分 优化)
- [第二部分 模型](#第二部分 模型)
-
- [第零章 预测考题](#第零章 预测考题)
- [第一章 神经网络(MLP, BP, CNN, GNN, and Attention)](#第一章 神经网络(MLP, BP, CNN, GNN, and Attention))
-
- [1.1 神经网络基础](#1.1 神经网络基础)
-
- [1.1.1 高次非线性函数](#1.1.1 高次非线性函数)
- [1.1.2 感知器与神经网络](#1.1.2 感知器与神经网络)
- [1.1.3 联结主义模型](#1.1.3 联结主义模型)
- [1.1.4 动机------为什么每个人都在谈论深度学习?](#1.1.4 动机——为什么每个人都在谈论深度学习?)
- [1.1.5 背景](#1.1.5 背景)
- [1.1.6 神经网络架构](#1.1.6 神经网络架构)
- [1.1.7 激活函数](#1.1.7 激活函数)
- [1.1.8 神经网络的目标函数](#1.1.8 神经网络的目标函数)
- [1.2 卷积神经网络(CNN ,Convolution neural network)](#1.2 卷积神经网络(CNN ,Convolution neural network))
-
- [1.2.1 Convolution Layer【卷积层】](#1.2.1 Convolution Layer【卷积层】)
- [1.2.2 Feature Maps【特征图】](#1.2.2 Feature Maps【特征图】)
- [1.2.3 More Filters【更多过滤器】](#1.2.3 More Filters【更多过滤器】)
- [1.3 图神经网络(GNN ,Graph neural network)](#1.3 图神经网络(GNN ,Graph neural network))
-
- [1.3.1 邻域聚合](#1.3.1 邻域聚合)
- [1.3.1 训练模型](#1.3.1 训练模型)
- [1.4 循环神经网络与注意力机制](#1.4 循环神经网络与注意力机制)
-
- [1.4.1 根据过程序列分类的RNN](#1.4.1 根据过程序列分类的RNN)
- [1.4.2 RNN](#1.4.2 RNN)
- [1.4.3 注意力机制](#1.4.3 注意力机制)
- [第二章 模糊逻辑系统](#第二章 模糊逻辑系统)
-
- [2.1 概述](#2.1 概述)
- [2.2 模糊逻辑](#2.2 模糊逻辑)
- [2.3 Fuzzy Sets vs Crisp Sets【模糊集与二元集】](#2.3 Fuzzy Sets vs Crisp Sets【模糊集与二元集】)
- [2.4 函数建模或近似:曲线或曲面拟合](#2.4 函数建模或近似:曲线或曲面拟合)
-
- [2.4.1 曲线拟合的标准数学方法(或多或少令人满意的拟合)](#2.4.1 曲线拟合的标准数学方法(或多或少令人满意的拟合))
- [2.4.2 使用模糊规则(面片)进行曲线拟合。2个输入或超曲面(3个或更多输入)的曲面近似](#2.4.2 使用模糊规则(面片)进行曲线拟合。2个输入或超曲面(3个或更多输入)的曲面近似)
- [2.5 模糊逻辑系统](#2.5 模糊逻辑系统)
- [2.6 例子](#2.6 例子)
- [第三章 特征选择与提取](#第三章 特征选择与提取)
-
- [3.1 特征选择](#3.1 特征选择)
-
- [3.1.1 分类的特征选择](#3.1.1 分类的特征选择)
- [3.1.2 两类问题的救济算法](#3.1.2 两类问题的救济算法)
-
- [3.1.2.1 基于属性重要性的属性约简算法](#3.1.2.1 基于属性重要性的属性约简算法)
- [3.1.2.2 最小冗余最大相关性(mRMR)特征选择](#3.1.2.2 最小冗余最大相关性(mRMR)特征选择)
- [3.1.2.3 对比](#3.1.2.3 对比)
- [3.2 特征提取(无监督的)](#3.2 特征提取(无监督的))
-
- [3.2.1 Subspace representation【子空间表示】](#3.2.1 Subspace representation【子空间表示】)
- [3.2.2 Matrix Decomposition【矩阵分解】(一种子空间方法)](#3.2.2 Matrix Decomposition【矩阵分解】(一种子空间方法))
- [3.2.3 PCA method【主成分分析方法】](#3.2.3 PCA method【主成分分析方法】)
- [3.2.4 Kernel PCA【核的主成分分析】](#3.2.4 Kernel PCA【核的主成分分析】)
- [3.2.5 Manifold Learning【流形学习】](#3.2.5 Manifold Learning【流形学习】)
- [3.2.6 Locally Linear Embedding (LLE)【局部线性嵌入】](#3.2.6 Locally Linear Embedding (LLE)【局部线性嵌入】)
- [第四章 数据表示学习(Data representation)](#第四章 数据表示学习(Data representation))
-
- [4.1 Sparse Learning【稀疏学习】](#4.1 Sparse Learning【稀疏学习】)
- [4.2 自动编码器](#4.2 自动编码器)
-
- [4.2.1 自动编码器(Autoencoder)](#4.2.1 自动编码器(Autoencoder))
- [4.2.2 可变自动编码器(Variational Autoencoder, VAE)](#4.2.2 可变自动编码器(Variational Autoencoder, VAE))
- [4.2.3 图形自动编码器(Graph Autoencoder, GAE)](#4.2.3 图形自动编码器(Graph Autoencoder, GAE))
- [4.2.4 变分图自动编码器(Variational Graph Autoencoder, VGAE)](#4.2.4 变分图自动编码器(Variational Graph Autoencoder, VGAE))
- [4.2.5 小结](#4.2.5 小结)
- [4.4 生成对抗性网络](#4.4 生成对抗性网络)
- [4.5 对比学习](#4.5 对比学习)
- [4.6 强化学习(Reinforcement Learning)](#4.6 强化学习(Reinforcement Learning))
-
- [4.6.1 强化学习](#4.6.1 强化学习)
- [4.6.2 DQN(Deep Q-Network)](#4.6.2 DQN(Deep Q-Network))
- [4.6.3 优缺点](#4.6.3 优缺点)
- [4.6.4 应用场景](#4.6.4 应用场景)
- [第五章 注意力机制和 Transformer](#第五章 注意力机制和 Transformer)
-
- [5.1 注意力机制(Attention Mechanism)](#5.1 注意力机制(Attention Mechanism))
- [5.2 Transformer](#5.2 Transformer)
- [第六章 生成模型(Autoregressive models, VAE, GAN)](#第六章 生成模型(Autoregressive models, VAE, GAN))
-
- [6.1 生成模型概述](#6.1 生成模型概述)
- [6.2 PixelRNN](#6.2 PixelRNN)
- [6.3 PixelCNN](#6.3 PixelCNN)
- [6.3 Variational Autoencoders (VAE)](#6.3 Variational Autoencoders (VAE))
- [6.4 Generative Adversarial Networks (GANs)](#6.4 Generative Adversarial Networks (GANs))
- [第七章 生成模型(diffusion and probabilistic graph models)](#第七章 生成模型(diffusion and probabilistic graph models))
-
- [7.1 Diffusion Model](#7.1 Diffusion Model)
- [7.2 Probabilistic Graphical Models (PGMs)](#7.2 Probabilistic Graphical Models (PGMs))
- [7.3 RBM【受限玻尔兹曼机】](#7.3 RBM【受限玻尔兹曼机】)
-
- [7.3.1 结构](#7.3.1 结构)
- [7.3.2 训练 RBM](#7.3.2 训练 RBM)
- [7.3.3 优缺点](#7.3.3 优缺点)
- [7.3.4 用途](#7.3.4 用途)
- [7.3.5 训练细节与优化技巧](#7.3.5 训练细节与优化技巧)
- [7.3.6 总结](#7.3.6 总结)
- [7.4 深度学习](#7.4 深度学习)
-
- [7.4.1 基本概念](#7.4.1 基本概念)
- [7.4.2 模型](#7.4.2 模型)
- [7.4.3 工作原理](#7.4.3 工作原理)
- [7.4.4 优缺点](#7.4.4 优缺点)
- [7.4.5 用途](#7.4.5 用途)
- [7.4.6 总结](#7.4.6 总结)
- [7.5 Greedy Training【贪心训练】](#7.5 Greedy Training【贪心训练】)
-
- [7.5.1 方案步骤](#7.5.1 方案步骤)
- [7.5.2 具体实现](#7.5.2 具体实现)
- [7.5.3 为什么Greedy Training可以生效](#7.5.3 为什么Greedy Training可以生效)
- [7.5.4 总结](#7.5.4 总结)
- [第八章 提示工程和学习(Prompt Engineering and Learning)](#第八章 提示工程和学习(Prompt Engineering and Learning))
-
- [8.1 主要内容](#8.1 主要内容)
-
- [1. 语言模型的"规模战争"](#1. 语言模型的“规模战争”)
- [2. Prompting 方法分类](#2. Prompting 方法分类)
- [3. 新范式对比传统"预训练+微调"](#3. 新范式对比传统“预训练+微调”)
- [4. Chain-of-Thought (CoT) Prompting](#4. Chain-of-Thought (CoT) Prompting)
- [5. 生成知识提示(Generated Knowledge Prompting)](#5. 生成知识提示(Generated Knowledge Prompting))
- [6. 思维树(Tree of Thoughts, ToT)](#6. 思维树(Tree of Thoughts, ToT))
- [7. Prompt 学习的挑战和进展](#7. Prompt 学习的挑战和进展)
- 结论
第一部分 优化
燕云十八骑
-
简述岭回归、Lasso、Elastic 之间的联系与区别?
答 :
联系 :岭回归、Lasso 和 Elastic Net 都是用于线性回归的正则化方法,通过添加惩罚项来防止过拟合并提升模型的泛化能力。
区别 :①岭回归通过在损失函数中添加 L2 正则化项来限制回归系数的大小。使用 L2 正则化,这意味着惩罚项是回归系数的平方和。岭回归不会导致系数完全为零,因此它不能用于特征选择。
②Lasso 通过在损失函数中添加 L1 正则化项来约束回归系数。使用 L1 正则化,这意味着惩罚项是回归系数的绝对值和。Lasso 可以导致某些系数变为零,因此它可以进行特征选择。
③Elastic Net 结合了岭回归和 Lasso 的正则化方法,通过同时使用 L1 和 L2 正则化项。Elastic Net 同时包含 L1 和 L2 正则化项,因此可以在特征选择和模型稳定性之间找到平衡。当特征高度相关时,Elastic Net 比单独使用 Lasso 或岭回归更有效。
-
为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令w = 0, b =0?
答 :如果所有权重初始化为零,反向传播时每个权重的梯度也会相同,导致每次更新时权重保持相同的变化。这样的模型无法有效学习数据的复杂结构。随机初始化权重可以打破对称性,使每个神经元在训练开始时有不同的输出,从而确保网络能够学习到不同的特征。
随机初始化使得初始权重分布在一个小的范围内,有助于网络更快地探索损失函数的表面,从而加速收敛。如果权重初始化为零,计算的梯度可能会陷入局部最小值或者梯度消失/爆炸问题,更难以有效训练。
所以采用随机参数初始化而不是直接令 w=0 和 b=0,可以有效地避免对称性破坏问题,加速模型收敛,并防止梯度消失或爆炸,从而提升模型的训练效果和性能。
-
以 Logistic 激活函数 σ ( x ) \sigma(x) σ(x) 为例,简述什么是梯度消失?如何避免梯度消失问题?
答 :

由于 Logistic 函数的输出范围在 (0, 1) 之间,对应的导数值也在 (0, 0.25) 之间。当输入值较大或较小时,导数值会非常小,这就导致梯度在反向传播过程中逐层减小,出现梯度消失的问题。
通过选择合适的激活函数、使用适当的权重初始化方法、应用正则化技术和优化网络结构设计,可以有效地缓解或避免梯度消失问题,从而提升深层神经网络的训练效果。
-
简述反向传播算法?
答 :BP 算法是一种有监督式的学习算法,其主要思想是:输入学习样本,使用反向传播算法对网络的权值和偏差进行反复的调整训练,使输出的向量与期望向量尽可能地接近,当网络输出层的误差平方和小于指定的误差时训练完成,保存网络的权值和偏差。
-
在BP算法中,如果权值更新中的
ω ( k + 1 ) = ω ( k ) − α k ∇ E ( ω ( k ) ) , ∇ E ( ω ( k ) ) ≠ 0 \omega^{(k+1)}= \omega^{(k)}- \alpha_k \nabla E(\omega^{(k)}),\nabla E(\omega^{(k)})\ne 0 ω(k+1)=ω(k)−αk∇E(ω(k)),∇E(ω(k))=0
的步长(学习率) α k \alpha_k αk 的选择满足: α k = a r g m i n α > 0 E ( ω ( k ) − α k ∇ E ( ω ( k ) ) ) \alpha_k = arg\;min_{\alpha >0}E( \omega^{(k)}- \alpha_k \nabla E(\omega^{(k)})) αk=argminα>0E(ω(k)−αk∇E(ω(k))),请证明
∇ E ( ω ( k + 1 ) ) T ∇ E ( ω ( k ) ) = 0 \nabla E(\omega^{(k+1)})^T\nabla E(\omega^{(k)})=0 ∇E(ω(k+1))T∇E(ω(k))=0
也即前后两次的梯度方向相互垂直,产生ZigZag(之字形)的搜索路径。
解 :
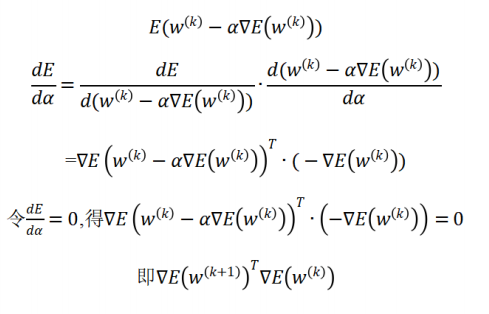
-
试推导软间隔SVM 问题
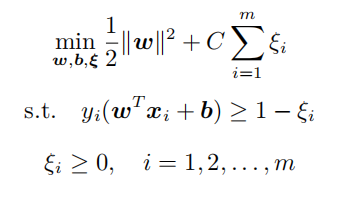
的KKT条件
解 :①构造拉格朗日函数
L ( w , b , ξ , α , μ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n ξ i + ∑ i = 1 n α i ( 1 − ξ i − y i ( w T x i + b ) ) − ∑ i = 1 n u i ξ i L(w,b,\xi,\alpha,\mu)=\frac{1}{2}||w||^2+C\sum^n_{i=1}\xi_i+\sum^n_{i=1}\alpha_i(1-\xi_i-y_i(w^Tx_i+b))-\sum^n_{i=1}u_i\xi_i L(w,b,ξ,α,μ)=21∣∣w∣∣2+C∑i=1nξi+∑i=1nαi(1−ξi−yi(wTxi+b))−∑i=1nuiξi②求 min w , b , ξ L ( w , b , ξ , α , μ ) \min\limits_{w,b,\xi}\;L(w,b,\xi,\alpha,\mu) w,b,ξminL(w,b,ξ,α,μ)
将 L ( w , b , ξ , α , μ ) L(w,b,\xi,\alpha,\mu) L(w,b,ξ,α,μ) 分别对 w , b , ξ i w,b,\xi_i w,b,ξi 求导,并令其=0,得
w − ∑ i = 1 n α i y i x i = 0 ∑ i = 1 n α i y i = 0 C − α i − u i = 0 , i = 1 , 2 , . . . , n w-\sum^n_{i=1}\alpha_iy_ix_i=0 \\ \; \\ \sum^n_{i=1}\alpha_iy_i=0 \\ \; \\ C-\alpha_i-u_i=0,\;i=1,2,...,n w−i=1∑nαiyixi=0i=1∑nαiyi=0C−αi−ui=0,i=1,2,...,n则 min w , b , ξ L ( w , b , ξ , α , μ ) = − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j + ∑ i = 1 n α i \min\limits_{w,b,\xi}\;L(w,b,\xi,\alpha,\mu)=-\frac12\sum^n_{i=1}\sum^n_{j=1}\alpha_i\alpha_jy_iy_jx_i^Tx_j+\sum^n_{i=1}\alpha_i w,b,ξminL(w,b,ξ,α,μ)=−21i=1∑nj=1∑nαiαjyiyjxiTxj+i=1∑nαi
③求 max α , u min w , b , ξ L ( w , b , ξ , α , μ ) \max\limits_{\alpha,u}\;\min\limits_{w,b,\xi}\;L(w,b,\xi,\alpha,\mu) α,umaxw,b,ξminL(w,b,ξ,α,μ)

等价于
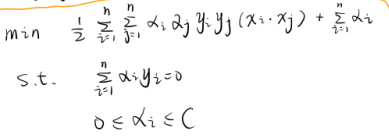
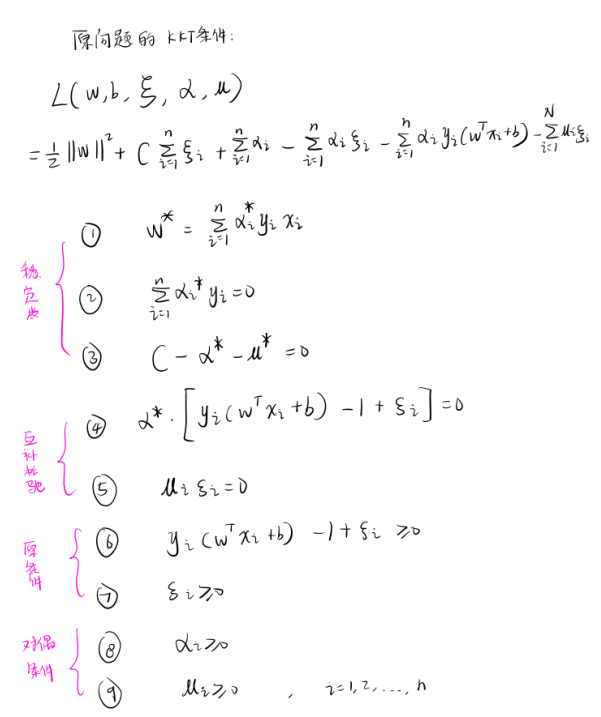
-
简述拉格朗日法与增广拉格朗日法之间的差别?对于LASSO问题
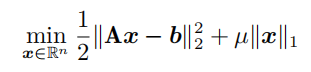
写出它的增广拉格朗日函数法。
答 :拉格朗日法通过引入拉格朗日乘子,将约束优化问题转化为无约束优化问题,对于一个具有等式约束的优化问题,拉格朗日函数的形式为:

其中,𝑓(𝑥)是目标函数,𝑔(𝑥) = 0是约束条件,λ 是拉格朗日乘子。通过对拉格朗日函数分别对 x 和 λ 求导,并令导数为零,得到关于 x 和 λ 的拉格朗日方程组,求解该方程组,即可找到满足约束条件的最优解。
增广拉格朗日法在拉格朗日法的基础上,引入了罚函数(penalty term),以提高收敛性和鲁棒性。对于等式约束优化问题,增广拉格朗日函数的形式为:

其中,ρ是罚参数, ∣ ∣ g ( x ) ∣ ∣ 2 ||g(x)||^2 ∣∣g(x)∣∣2是罚函数项,用于惩罚违反约束条件的解。接着,需要通过多次迭代,每次迭代交替更新x、λ和ρ来优化增广拉格朗日函数,以此逐步逼近最优解,直到满足收敛条件。
为了使用增广拉格朗日法处理 LASSO 问题,我们可以将其转化为一个等价的约束优化问题:
min x 1 2 ∣ ∣ z − b ∣ ∣ 2 2 + μ ∣ ∣ x ∣ ∣ 1 , s . t . A x − z = 0 \min\limits_{x} \frac12||z-b||_2^2+\mu||x||_1,\\ \;\\ s.t.\;\;\;\; Ax-z=0 xmin21∣∣z−b∣∣22+μ∣∣x∣∣1,s.t.Ax−z=0则其增广拉格朗日函数为:
L σ ( x , z , λ ) = 1 2 ∣ ∣ z − b ∣ ∣ 2 2 + μ ∣ ∣ x ∣ ∣ 1 + λ T ( A x − z ) + 1 2 σ ∣ ∣ A x − z ∣ ∣ 2 2 L_\sigma(x,z,\lambda)=\frac12||z-b||_2^2+\mu||x||_1+\lambda^T(Ax-z)+\frac12\sigma||Ax-z||_2^2 Lσ(x,z,λ)=21∣∣z−b∣∣22+μ∣∣x∣∣1+λT(Ax−z)+21σ∣∣Ax−z∣∣22迭代基本框架为:

不断迭代求解,逐步逼近LASSO问题的解。
-
写出线性规划问题
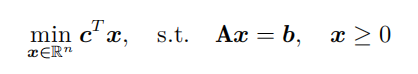
的增广拉格朗日函数法。
答 :线性规划问题的增广拉格朗日函数为:
L σ ( x , λ ) = c T x + λ T ( A x − b ) + 1 2 σ ∣ ∣ A x − b ∣ ∣ 2 2 , x ≥ 0 L_\sigma(x,\lambda)=c^Tx+\lambda^T(Ax-b)+\frac12\sigma||Ax-b||_2^2,\;\;\;\;x\ge0 Lσ(x,λ)=cTx+λT(Ax−b)+21σ∣∣Ax−b∣∣22,x≥0迭代基本框架为:

-
列举几类步长搜索的方法?写出使用次梯度方法求解 LASSO 问题:
答 :几类步长搜索的方法:

使用次梯度方法求解 LASSO 问题:

-
简述使用梯度类算法面临的困难有哪些?
答:
局部极小值 :梯度下降可能会陷入局部极小值,而不是全局最小值。局部极小值可能导致算法陷入局部最优解而无法找到全局最优解。
鞍点 :在高维空间中,鞍点比局部极小值更常见。梯度在鞍点处为零,但并不是最优解,导致梯度下降算法停滞在这些点上。
梯度消失和梯度爆炸 :在深层神经网络中,梯度在反向传播过程中可能会变得非常小(梯度消失)或非常大(梯度爆炸)。梯度消失会导致学习速度变慢甚至停止,梯度爆炸则会导致参数更新过大,从而使得模型不稳定。
学习率选择 :合适的学习率对于算法的收敛至关重要。学习率过高损失函数会爆炸增长,学习率过低则可能使收敛速度非常慢。
超参数调优 :梯度类算法中有多个超参数(如学习率、动量等)需要调优,这通常是一个耗时且需要经验的过程。
非凸优化问题 :许多实际问题的目标函数是非凸的,存在多个局部最优解和鞍点,使得找到全局最优解更加困难。
计算成本 :对于大规模数据集和高维度问题,计算梯度和更新参数的过程可能会非常耗时和耗资源。
数据依赖性 :梯度类算法对输入数据的分布非常敏感,数据的缩放、归一化等预处理步骤对优化效果有显著影响。
噪声和不稳定性:在实际应用中,数据中可能存在噪声,导致梯度的估计不准确,从而影响优化效果。梯度下降在这样的情况下可能会表现出不稳定性。
-
写出使用 Newton 方法求解二分类逻辑回归问题:【课本P239】
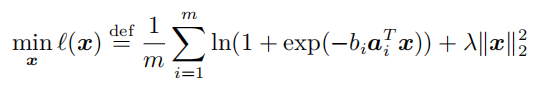
解 :根据向量值函数求导法,得:


当变量规模不是很大时,可以利用正定矩阵得Cholesky分解来求解牛顿方程;当变量规模较大时,可以使用共轭梯度法进行不精确求解。
-
计算常用激活函数 Logistic 函数、Tanh 函数、LeakyReLU 函数、Swish 函数的导数。
解 :

-
如果对线性最小二乘问题的目标函数增加正则项使之变为
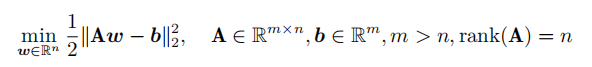
的目标函数数增加正则项使之变为
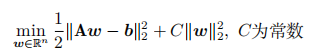
(a)请问能否给出新问题的解析解(即显式表达式)?如果能,请给出具体推导过程,如果不存在,请说明理由,并给出一种迭代求解方法。
(b)将上述解析表达式或者迭代方法应用于线性回归问题,给出具体的表达式或者迭代公式。
解 :(a )能,

(b )对于目标函数


整理得:
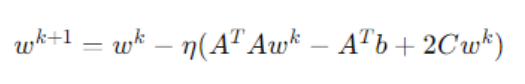
-
写出利用 ADMM 算法优化 LASSO 问题的过程:
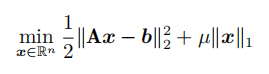
解 :将LASSO问题写成ADMM标准问题形式:

拉格朗日函数为:

-
利用ADMM算法求解全局一致性问题:
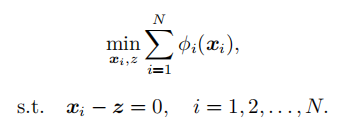
解 :


-
利用ADMM 算法求解非负矩阵分解和补全问题:
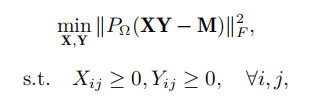
其中,Q 表示矩阵M中的已知元素的下标集合, P Ω ( A ) P_\Omega(A) PΩ(A) 表示得到一个新的矩阵 A',其下标在集合 Ω \Omega Ω 中的所对应的元素等于矩阵 A 的对应元素,其下标不在集合 Ω \Omega Ω 中的所对应的元素为 0。
解 :





-
用近似点梯度方法求解LASSO问题:
解 :

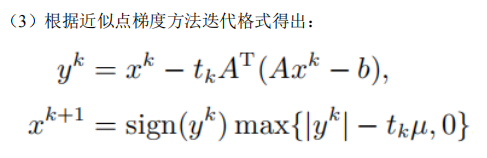
(4)迭代直到以下条件之一满足:参数更新 ∣ ∣ x k + 1 − x k ∣ ∣ ||x^{k+1}-x^k|| ∣∣xk+1−xk∣∣ 足够小或达到预设的最大迭代次数。
-
什么是监督学习中的过拟合现象,造成过拟合现象的主要原因是什么?
答 :过拟合是指机器学习模型过度学习训练数据的细节和噪声,在训练数据上表现很好,但在新数据上表现一般,泛化能力较差。
主要原因:
(1)训练数据不足:有限的数据样本难以涵盖整个数据分布,导致模型过度拟合特定样本。
(2)模型复杂度过高:模型对训练数据的局部特征过于敏感,而无法泛化到新的数据。
(3)特征选择不当:选择不适当的特征或使用过多的特征也可能导致过拟合。当特征过多或特征之间存在冗余时,模型可能过于依赖这些特征并在训练数据上过度拟合。
(4)训练时间过长:训练时间过长,模型可能开始记住训练数据的细节和噪声,而不是学习其潜在的模式和规律。
(5)噪声干扰:数据中存在的随机噪声可能被模型错误地视为真实模式,从而导致过拟合。
(6)缺乏正则化:未使用或使用不当的正则化方法,无法有效限制模型复杂度,导致模型过度拟合训练数据。
第二部分 模型
第零章 预测考题
- 在生成模型中,为什么所有的生成都是从白噪声开始?
答 :
①随机性和多样性:白噪声包含所有频率的均匀分布,确保模型能探索所有可能的模式。
②便于训练:白噪声的简单统计性质使得生成过程在数学和计算上更为简洁和可控。
③采样简单:白噪声通常是一个简单的高斯分布或均匀分布,这种简单的分布使得采样过程变得非常直接和高效。
④实际效果:在生成对抗网络(GANs)、变分自编码器(VAEs)和扩散模型等等模型的生成任务中表现出色。
第一章 神经网络(MLP, BP, CNN, GNN, and Attention)
1.1 神经网络基础
1.1.1 高次非线性函数
f : X → Y f: X\rightarrow Y f:X→Y
- f 可能是非线性函数
- X(向量)连续和/或离散变量
- Y(向量)连续和/或离散变量
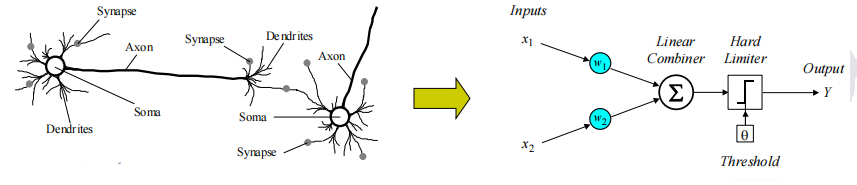
1.1.2 感知器与神经网络
- 从生物神经元到人工神经元(感知器)
- 激活函数
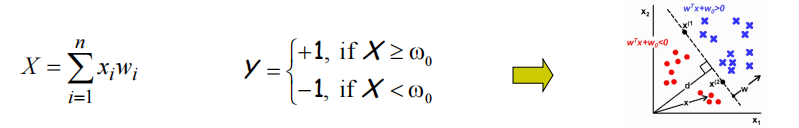
- 人工神经元网络
- 监督学习
- 梯度下降
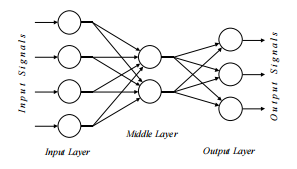
1.1.3 联结主义模型
- 以人类为例:
- 神经元切换时间约0.001秒
- 神经元数量 1010
- 每个神经元的连接 104-5
- 场景识别时间约0.1秒
- 100个推理步骤似乎还不够 → \rightarrow →大量并行计算
- 人工神经网络(ANN)的性质
- 许多神经元样阈值切换单元
- 单元之间的许多加权互连
- 高度并行、分布式的流程
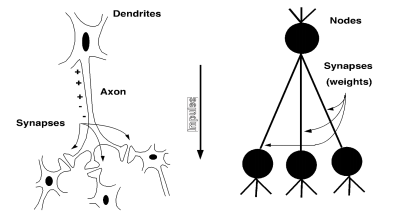
1.1.4 动机------为什么每个人都在谈论深度学习?
- 因为在这上面投入了很多钱...
- DeepMind:被谷歌以400百万美元收购
- DNNResearch:三人创业(包括Geoff Hinton)被谷歌收购
- Enlitic、Ersatz、MetaMind、Nervana、Skylab:深度学习初创公司获得数百万风险投资,因为它登上了《纽约时报》的头版
- 深度学习:
- 赢得了无数的模式识别比赛
- 只需最少的功能工程即可实现
事实并非总是如此!自20世纪80年代以来:模型的形式没有太大变化,但有很多新的技巧...
- 更多隐藏单元
- 更好的(在线)优化
- 新的非线性函数(ReLU)
- 更快的计算机(CPU和GPU)
1.1.5 背景
机器学习的配方
- 给定的训练数据 { x i , y i } i = 1 N \{ x_i,y_i\}^N_{i=1} {xi,yi}i=1N
- 选择函数
2.1 决策函数 y ^ = f θ ( x i ) \hat{y}=f_{\theta}(x_i) y^=fθ(xi)
今天的目标:① 探索一类新的决策函数(神经网络);② 考虑此配方的变体进行训练
2.2 损失函数 l ( y ^ , y i ) ∈ R l(\hat{y},y_i)\in R l(y^,yi)∈R - 设定目标 θ ∗ = a r g m i n ∑ i = 1 N l ( f θ ( x i ) , y i ) \theta^*=arg\; min \sum^N_{i=1}l(f_\theta(x_i),y_i) θ∗=argmin∑i=1Nl(fθ(xi),yi)
- 使用SGD进行训练 (在梯度对面迈出小步): θ ( t + 1 ) = θ ( t ) − η t ∇ l ( f θ ( x i ) , y i ) \theta^{(t+1)}=\theta^{(t)}-\eta_t\nabla l(f_\theta(x_i),y_i) θ(t+1)=θ(t)−ηt∇l(fθ(xi),yi)
∇ \nabla ∇------ 梯度,反向传播可以计算出这个梯度!这是一种更通用的算法的特例,称为反向模式自动微分,它可以有效地计算任何可微函数的梯度!
1.1.6 神经网络架构
即使对于基本的神经网络,也有许多设计决策需要做出:
- 隐藏层数(深度)
- 每个隐藏层的单元数(宽度)
- 激活函数类型(非线性)
- 目标函数的形式
1.1.7 激活函数
到目前为止,我们已经假设激活函数(非线性)总是S形函数,一个新的变化------修改非线性
- 逻辑在现代人工神经网络中没有广泛使用
t a n h ( x ) tanh(x) tanh(x)------类似于逻辑功能,但转移到范围-1,+1
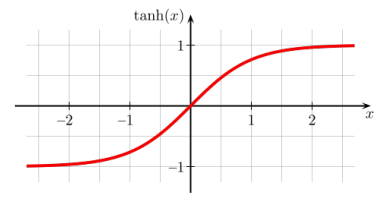
- reLU(整流线性单元)经常用于视觉任务
-
m a x ( 0 , z ) max(0,z) max(0,z)------截断为零的线性(实现:通过零时剪裁渐变)
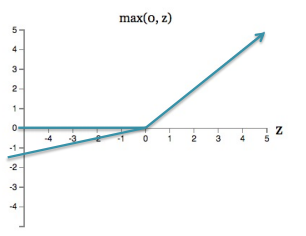
-
软版本: l o g ( e x p ( x ) + 1 ) log(exp(x)+1) log(exp(x)+1)
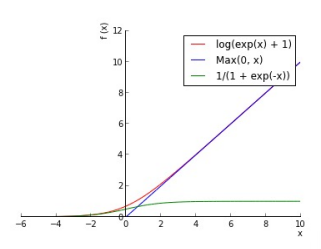
- 不饱和(在一端)
- 稀疏输出
- 有助于消除渐变
-
1.1.8 神经网络的目标函数
- 回归:
- 使用与线性回归相同的目标
- 二次损失(即均方误差)
- 分类:
- 使用与逻辑回归相同的目标
- 交叉熵(即负对数似然)
- 这需要概率,因此我们在网络末端添加了一个额外的"softmax"层
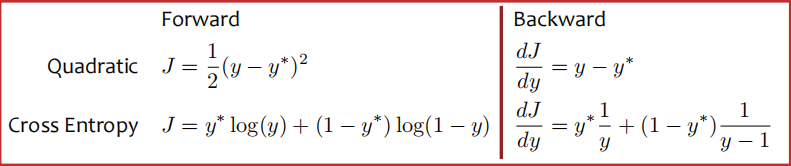
匹配测验:假设你有一个神经网络,只有一个输出y和一个隐藏层。
1) 最小化误差平方和...
2) 最小化平方误差之和加上权重的平方欧几里得范数...
3) 最小化交叉熵...
4) 最大限度地减少铰链损失...
5) ...假设目标遵循伯努利,参数由输出值给定,则权重的MLE估计
6) ......假设权重先验为零均值高斯的权重的MAP估计
7) ...在训练数据上有很大差距的估计
8) ...假设输出值上的平均高斯噪声为零的权重的MLE估计
1.2 卷积神经网络(CNN ,Convolution neural network)
1.2.1 Convolution Layer【卷积层】
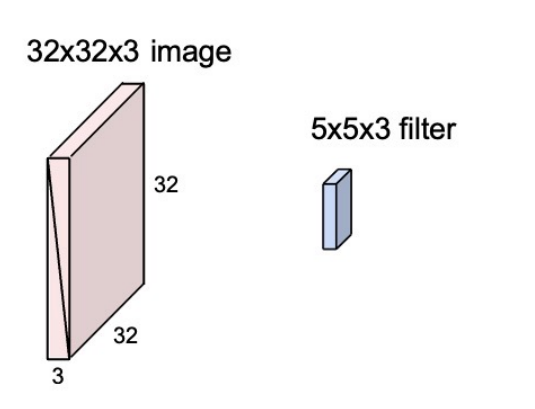
将过滤器器与图像卷积,即"在图像上进行空间滑动,计算点积"
1.2.2 Feature Maps【特征图】
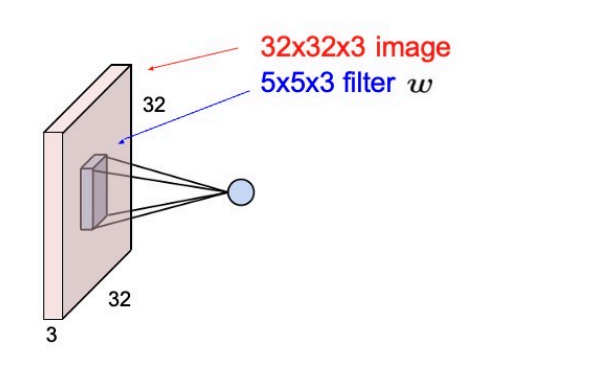
提取一个特征(1个数字):在滤波器和图像的5x5x3小块之间取点积的结果(即 5 ∗ 5 ∗ 3 = 75 5*5*3=75 5∗5∗3=75维点积+偏差) ω T x + b \omega ^Tx+b ωTx+b
1.2.3 More Filters【更多过滤器】
例如,如果我们有6个5x5过滤器,我们将获得6个单独的激活图
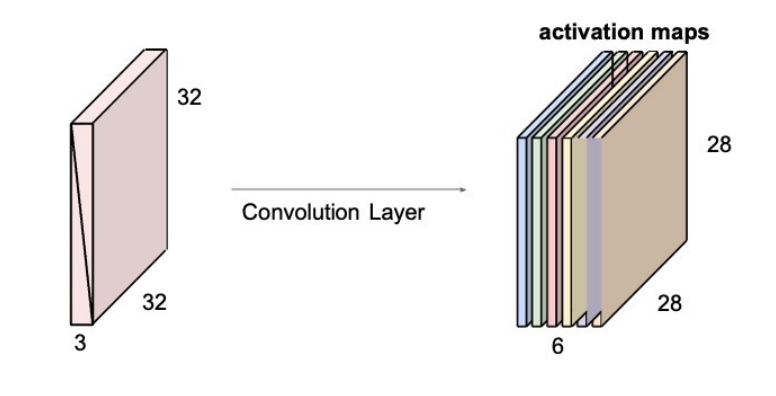
我们把这些叠起来,得到一张尺寸为28x28x6的"新图像"!
1.3 图神经网络(GNN ,Graph neural network)
1.3.1 邻域聚合
- 关键思想:基于局部邻域生成节点嵌入。
- 意图:
- 节点使用神经网络聚合来自邻居的信息
- 网络邻域定义计算图------每个节点都定义了一个唯一的计算图!
- 节点在每一层都有嵌入。
- 模型可以是任意深度。
- 节点u的"第0层"嵌入是其输入特征,即xu。
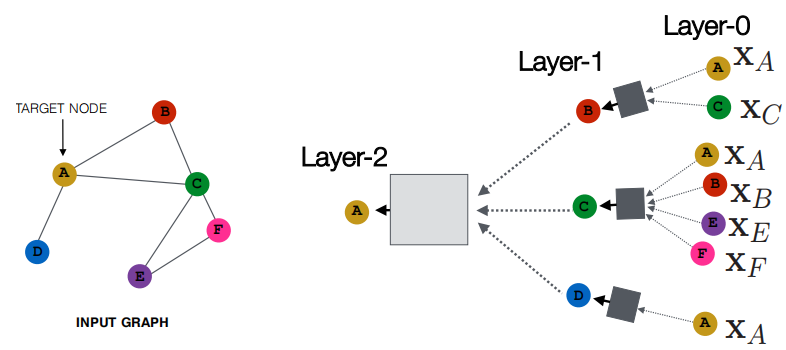
-
邻域"卷积"------邻域聚合可以被视为中心环绕滤波器。
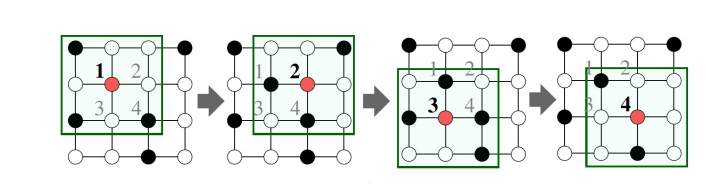
-
关键区别在于不同的方法如何跨层聚合信息。
基本方法:平均邻居信息并应用神经网络。
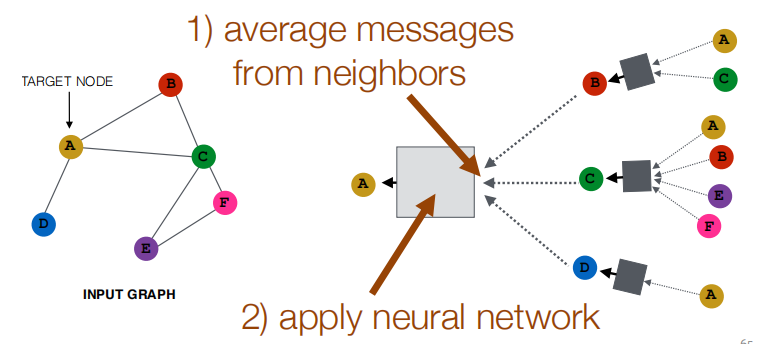
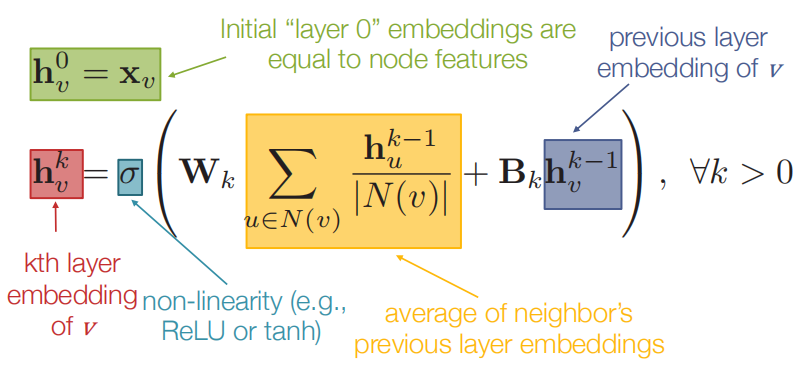
1.3.1 训练模型
我们如何训练模型以生成"高质量"的嵌入?
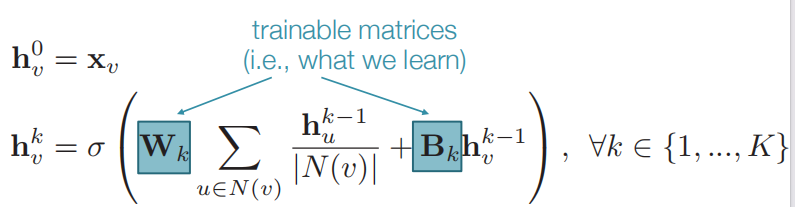
Z v = h v K Z_v=h^K_v Zv=hvK------在邻域聚合的K层之后,我们得到每个节点的输出嵌入。
- 我们可以将这些嵌入馈送到任何损失函数中,并运行随机梯度下降来训练聚合参数。
- 仅使用图结构以无监督的方式进行训练。
- 无监督损失函数可以是上一节中的任何内容,例如,基于
- 随机行走(node2vec、DeepWalk)
- 图分解
- 对比学习,训练模型,使"相似"节点具有相似的嵌入。
1.4 循环神经网络与注意力机制
1.4.1 根据过程序列分类的RNN
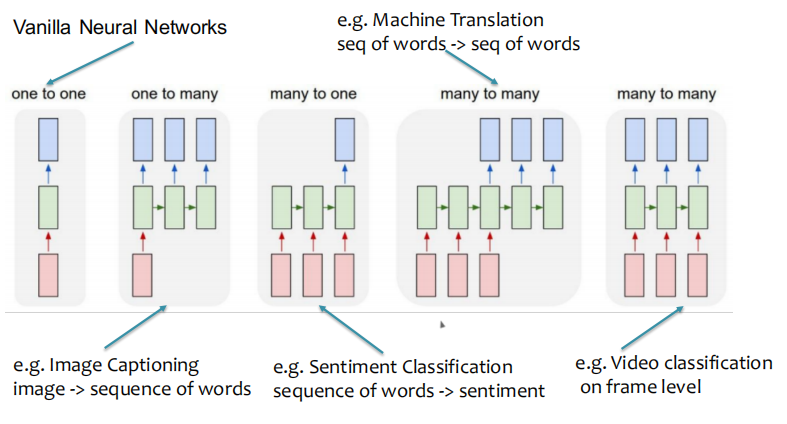
- 原始神经网络
- 机器翻译【单词序列->单词序列】
- 图像字幕【图像->单词序列】
- 情绪分类【单词顺序->情绪】
- 帧级别的视频分类
1.4.2 RNN
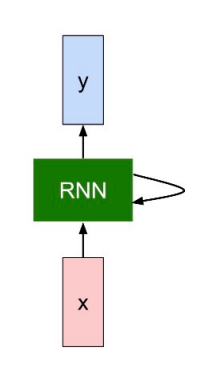
我们可以通过在每个时间步长应用递推公式来处理向量x的序列:

注意:在每个时间步长使用相同的函数和相同的参数集。
1.4.3 注意力机制
更一般的定义:
- 给定一组向量值和一个查询向量,注意力机制是一种根据查询计算值的加权和的技术。
- 加权和是对值中包含的信息的选择性汇总,其中查询确定要使用哪些值。
例如,在 seq2seq+attention 模型中,每个解码器隐藏状态(查询)关注所有编码器隐藏状态(值)
更正式的定义:
- 对于查询向量q,关键向量 k i k_i ki 表示值 v i v_i vi
s i s_i si是 q 和 k i k_i ki 之间的相似性得分 - 将相似性得分归一化为 p i = S o f t m a x ( s i ) p_i=Softmax(s_i) pi=Softmax(si)
- 计算 z 为值向量 v i v_i vi 的加权和,值向量 v i v_i vi 由其得分 p i p_i pi 加权。
z = ∑ i = 1 L p i v i z=\sum^L_{i=1}p_iv_i z=∑i=1Lpivi - 在机器翻译和图像字幕中,键和值是相同的。但是,它们可能会有所不同。
第二章 模糊逻辑系统
2.1 概述
- 什么是模糊逻辑?
模糊逻辑是一种嵌入知识和推理(经验、专业知识、启发式)的工具。 - 为什么是模糊逻辑?
- 人类的知识是模糊的:用"模糊"的语言术语表达,例如,年轻、年老、庞大、廉价。
示例:温度表示为冷、暖或热。 - 没有数量意义。
- 人类的知识是模糊的:用"模糊"的语言术语表达,例如,年轻、年老、庞大、廉价。
- 何时以及为什么应用模糊逻辑?
- 人类知识可用
- 数学模型未知或无法获得
- 过程基本上是非线性的
- 缺乏精确的传感器信息
- 在更高层次的控制系统中
- 在决策过程中
- 推断的证据和解释以及需要。
- 如何将人类知识转化为模型?
- 知识应结构化。
- 可能的缺点:
- 知识是主观的
- "专家"可能会在极端观点之间摇摆不定:
- 在构建知识方面存在问题,或者
- 过于了解其专业知识,或
- 倾向于隐藏"知识",或者。。。
- 解决方案:找一位"好"专家。
2.2 模糊逻辑
- 模糊逻辑试图对人脑的推理方式进行建模。
- 几乎所有的知识都可以用 IF-THEN 规则的形式表达。
- 人类的推理普遍是近似的、非数量的、语言的和处置的(意思是,通常是确定的)。
2.3 Fuzzy Sets vs Crisp Sets【模糊集与二元集】
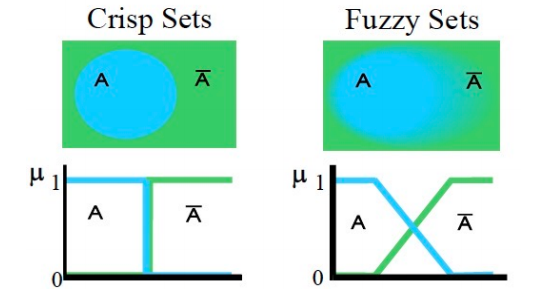
μ------隶属度、可能性分布、归属度
2.4 函数建模或近似:曲线或曲面拟合
2.4.1 曲线拟合的标准数学方法(或多或少令人满意的拟合)

2.4.2 使用模糊规则(面片)进行曲线拟合。2个输入或超曲面(3个或更多输入)的曲面近似

例如:
考虑用模糊规则对两个不同的函数进行建模
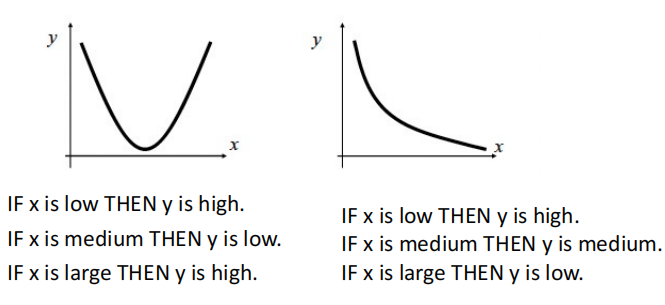
两个原始函数(两个图中的实线)由 IF-THEN 规则产生的三个补丁覆盖,并由两个可能的逼近器(虚线和虚线)建模。
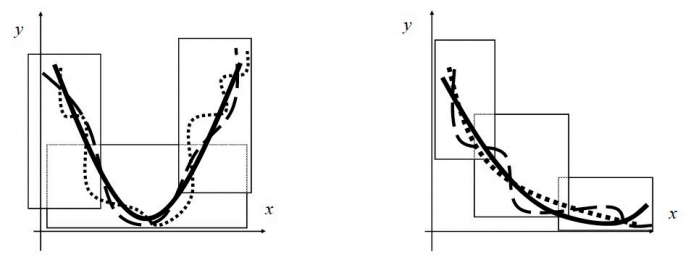
汽车示例
两车间距的模糊控制
输入:D=距离,v=速度
输出:B=制动力
分析给定距离D和不同速度v的规则,即: B = f ( v ) B=f(v) B=f(v)
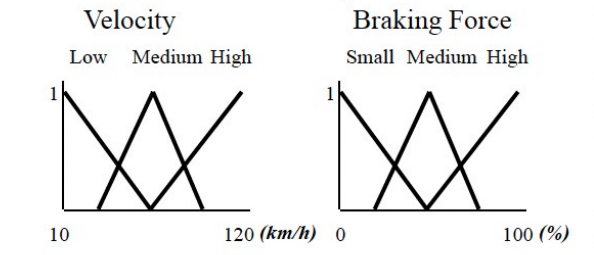
如果速度较低,则制动力较小
如果速度为中等,则制动力为中等
如果速度较高,则制动力较高
2.5 模糊逻辑系统
模糊集边界
- 设 X 是话语的宇宙,其元素表示为 x。在经典集合论中,X 的清晰集 A 被定义为函数 χ A \chi_A χA,称为 A 的特征函数。
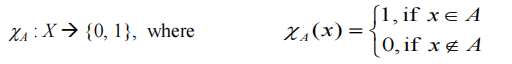
这个集合将宇宙 X 映射到一个由两个元素组成的集合。对于宇宙 X 的任何元素 x,如果 x 是集合 A 的元素,则特征函数 χ A ( x ) \chi_A(x) χA(x) 等于1,如果 x 不是 A 的元素则特征函数等于 0。 - 在模糊理论中,宇宙 X 的模糊集 A 由称为集 A 的隶属函数的函数 µ A µ_A µA 定义
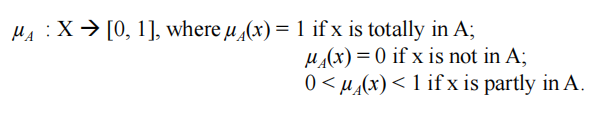
集合的定义允许一系列可能的选择。对于宇宙 X 的任何元素 x,隶属度函数 µ A ( x ) µ_A(x) µA(x) 等于 x 是集合 A 的元素的程度。这个程度是0到1之间的值,表示元素 x 在集合 A 中的隶属度,也称为隶属度值。
模糊集形式定义:X 中的模糊集 A 表示为一组有序对:

- 模糊隶属函数(FMF)
- 所有模糊集的关键问题之一是如何确定模糊隶属函数
- 隶属函数提供了元素与模糊集相似程度的度量
- 成员身份函数可以采取任何形式,但在实际应用程序中出现了一些常见的示例
- Trapezoidal Membership Function【梯形隶属函数】
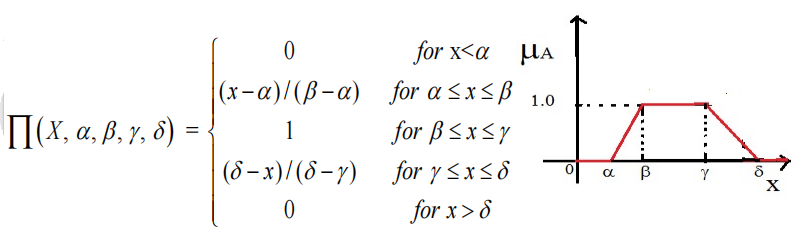
- Triangular Membership Function【三角隶属函数】
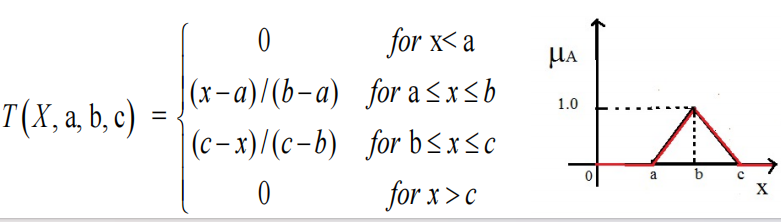
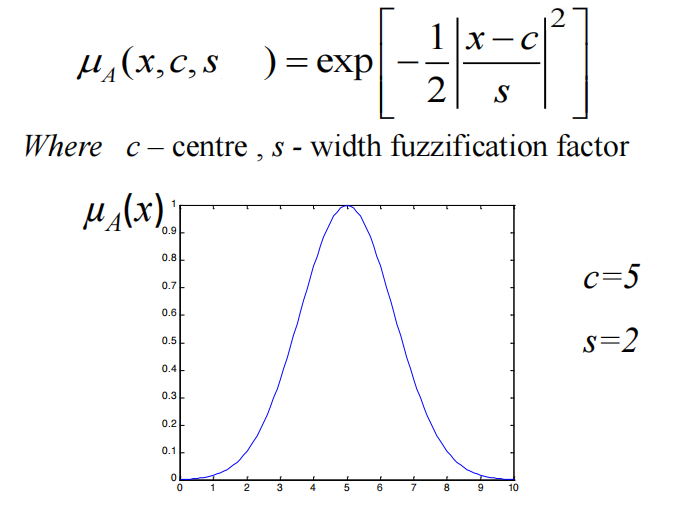
- Gaussian membership function【高斯隶属函数】
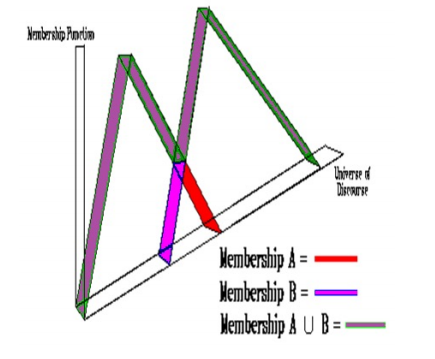
- Trapezoidal Membership Function【梯形隶属函数】
并集、交集和互补的模糊集运算是根据隶属函数定义的,如下所示:
- 并集 µ A ∪ B ( x ) = m a x ( µ A ( x ) , µ B ( x ) ) µ_{A∪B}(x) = max(µ_A(x), µ_B(x)) µA∪B(x)=max(µA(x),µB(x))
- 交集 µ A ∩ B ( x ) = m i n ( µ A ( x ) , µ B ( x ) ) µ_{A∩B}(x) = min(µ_A(x), µ_B(x)) µA∩B(x)=min(µA(x),µB(x))
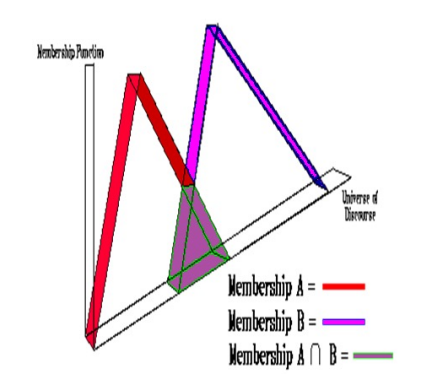
- 互补 µ n o t A ( x ) = 1 − µ A ( x ) µ_{not\;A}(x) = 1- µ_A(x) µnotA(x)=1−µA(x)
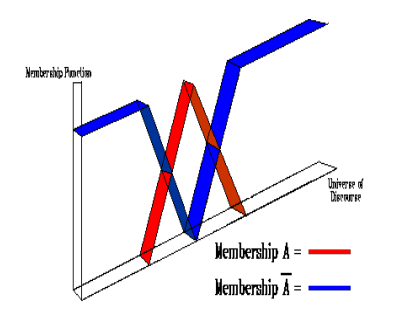
模糊集其他运算:
- Max membership principle【最大隶属值原则】
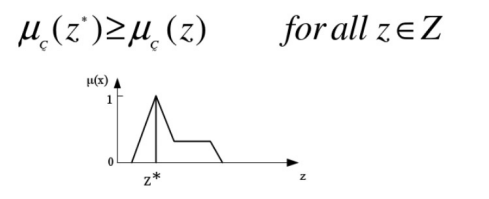
- Centroid method【质心法】
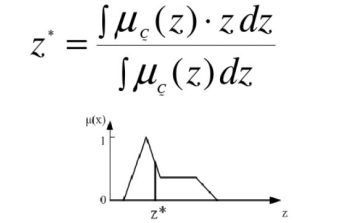
模糊规则分类器的推理:
为了简单起见,让规则库包含9个模糊IF-THEN规则并且具有如下的两个输入x和y:

规则1:如果输入1为A1,输入2为B1,则输出为C1
规则2:如果输入1为A1,输入2为B2,则输出为C2
规则3:如果输入1为A1,输入2为B3,则输出为C3
规则4:如果输入1为A2,输入2为B1,则输出为C4
规则5:如果输入1为A2,输入2为B2,则输出为C1
规则6:如果输入1为A2,输入2为B3,则输出为C6
规则7:如果输入1为A3,输入2为B1,则输出为C7
规则8:如果输入1为A3,输入2为B2,则输出为C8
规则9:如果输入1为A3,输入2为B3,则输出为C6
实际:输入1是x0,输入2是y0
结果:输出为C
规则的激发级别,表示为 α i \alpha_i αi,i=1,2,...,9,通过以下公式计算:
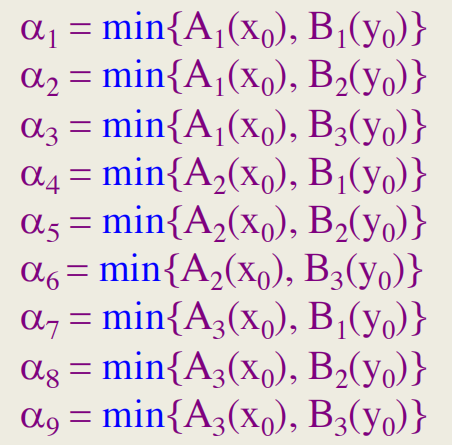
如果几个模糊规则具有相同的结果类,则必须将它们的激发强度组合起来。通常使用OR运算。
单个规则输出的计算方式如下:
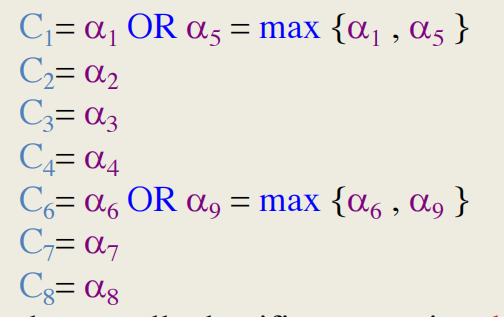
整体分类器输出由选择

2.6 例子
模糊逻辑的一个简单例子
控制风扇:
- 传统型号------如果温度>X,运行风扇,否则停止风扇
- 模糊系统:
- 如果温度=高温,则全速运转风扇
- 如果温度=温热,则以中等速度运行风扇
- 如果温度=舒适,保持风扇转速
- 如果温度=冷却、慢速风扇
- 如果温度=冷,则停止风扇
高个子男人例子:
模糊集合中的经典例子是"高个子男人"。模糊集合"高个子"的元素都是男人,但他们的隶属度取决于他们的身高。
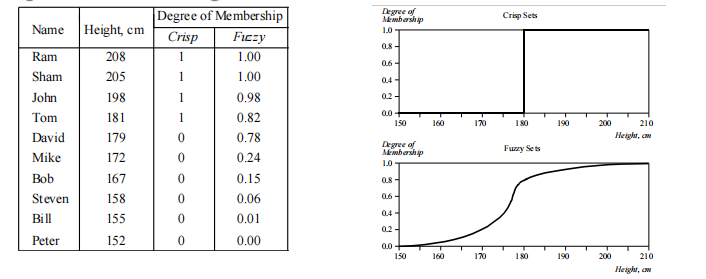
x 轴代表话语的宇宙------所有可能价值的范围。适用于选定的变量。在我们的例子中,变量是人的身高。根据这一表述,男性身高的宇宙由所有高个子男性组成。y 轴表示模糊集的隶属度值。在我们的例子中,"高个子"的模糊集合将身高值映射为相应的成员值。
模糊集表示
- 首先,我们确定成员函数。在我们的"高个子男人"例子中,我们可以定义高个子、矮个子和普通男人的模糊集合。
- 三个定义的模糊集合的话语宇宙由男性身高的所有可能值组成。
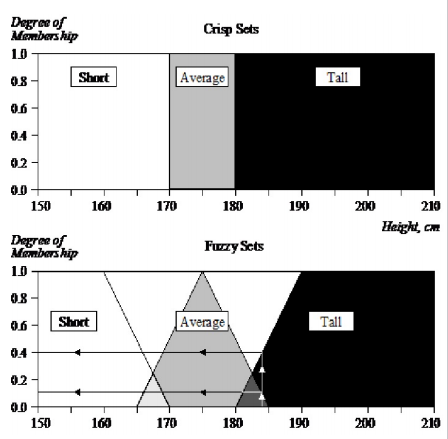
例如,身高184厘米的男子是0.1度的普通男子组的成员,同时,他也是0.4度的高个子男子组的一员
图像边缘检测

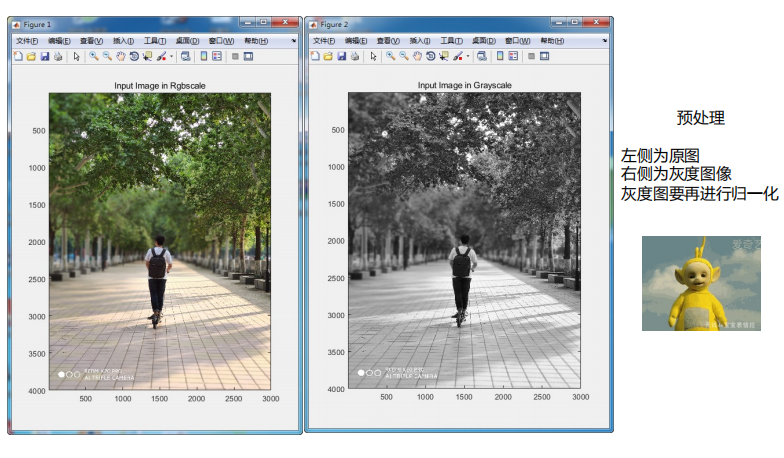
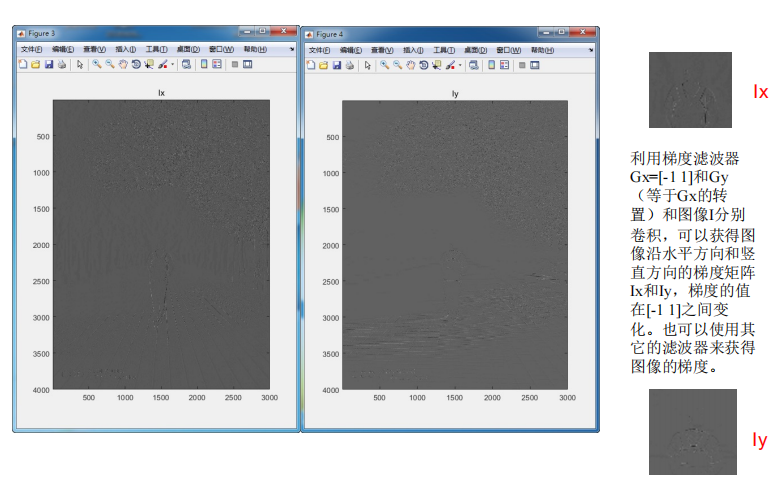
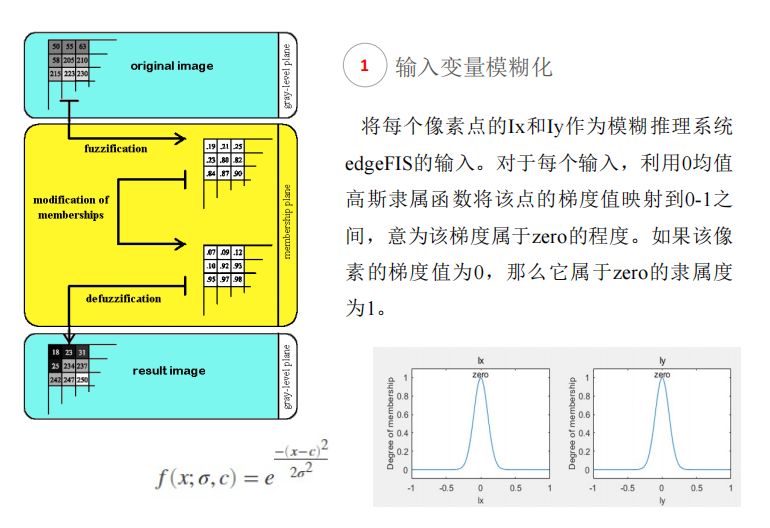

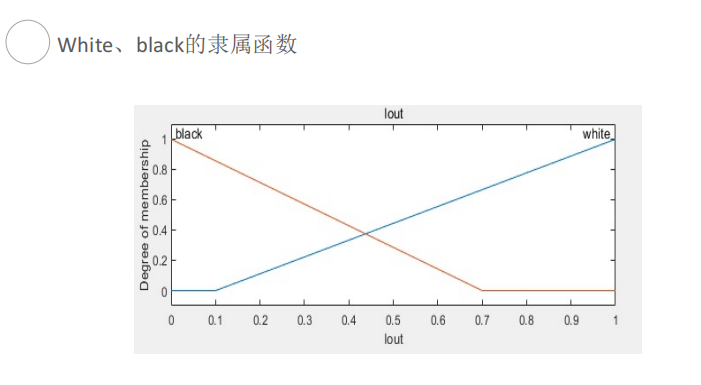
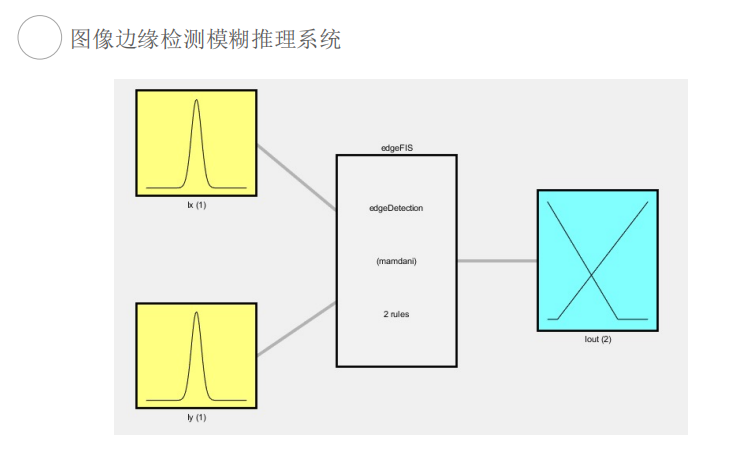

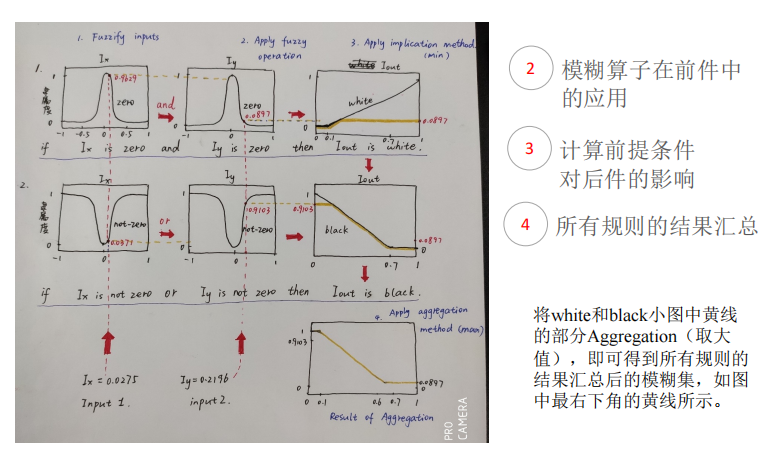
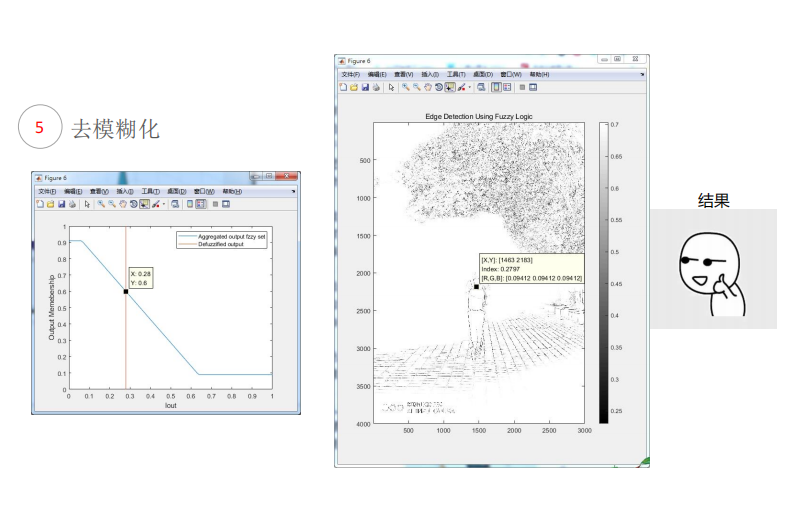
第三章 特征选择与提取
在实践中,一组数据可能包含大量冗余或与分类无关的原始特征。由于维数灾难,用这样的数据训练模型通常在计算上是困难的,更糟糕的是,训练的模型通常具有较差的泛化能力,具有较大的方差或过拟合问题。
因此,在训练模型或对数据集进行聚类之前,有必要进行降维处理。降维包括两种不同的方法:特征选择和特征提取。
特征选择与特征提取
- 特征选择只是返回原始特征的子集;
- 特征提取从原始特征的函数中创建新的特征(变量);
例如在最简单的情况下原始特征的线性组合。【特征提取通常产生比特征选择小得多的特征子集,但通常在物理上没有意义,因此很难解释。】
注意:特征选择可以被视为特征提取的一种特殊情况,在这种情况下不会创建新的特征。
3.1 特征选择
根据原始数据集标签信息的利用方式,特征选择算法可以分为有监督、半监督、无监督、自监督和对抗性。
特征选择方法的四个主要步骤
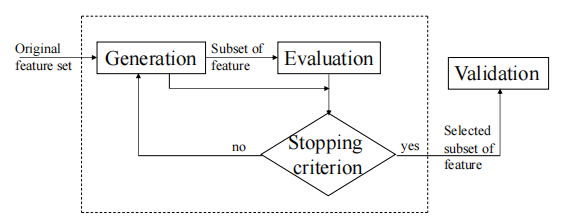
Generation【生成】------ 选择候选特征子集。
Evaluation【评价】 ------ 计算子集的相关性值。
Stopping criterion【停止条件】 ------ 确定子集是否相关。
Validation【验证】------ 验证子集的有效性。
3.1.1 分类的特征选择
- 过滤器方法
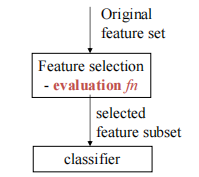
评估 fn:独立于分类器,因此更通用。
忽略了所选子集对分类器性能的影响。 - 包装器方法
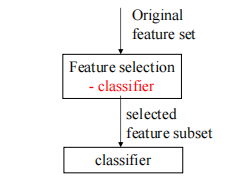
评估 fn = 分类器
将分类器考虑在内。
失去一般性。
高度准确。 - 嵌入式方法
关于评估的更多信息
- 确定生成的候选特征子集与分类任务的相关性。
- 5种主要类型的评估功能。

距离(欧几里得距离度量)
信息(熵、信息增益等)
依赖性(相关系数)
一致性(最小特征偏差)
分类器错误率(分类器本身)
分类器错误率
- 包装方法。
error_rate = 分类器(候选特征子集)
如果(error_rate < 预定义阈值),则选择特征子集 - 特征选择失去了一般性,但在分类任务中获得了准确性。
- 计算成本非常高。
不同的视角
- 决策树方法
在训练集上跑C4.5。所选的特征(属性)是C4.5生成的修剪决策树中所有特征的并集。随机森林算法也是一种特征选择方法。 - 粗糙集方法
寻找约简实际上是一个特征选择的过程 - 正则化方法
假设 H 由 { g ( β T x ) } \{g(\beta^Tx)\} {g(βTx)} 是某个函数组成, C ( H ) C(H) C(H) 由 ∣ ∣ β ∣ ∣ ||\beta|| ∣∣β∣∣ 定义。如果最优 β ∗ \beta^* β∗(给定h*)具有多个零分量,那么它相当于去除了特征向量 x 中的对应分量,从而完成了特征选择任务。
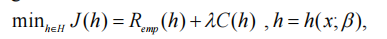
x:特征向量, β \beta β:要优化的参数向量
备注:
前两种方法都不直接参考分类的错误率,以特征子集结束,同时以基于规则的决策模型结束(前者是树,后者是可立即提取规则的简化表)。因此,它们是基于过滤器的方法,或多或少也是嵌入式方法。
第三种方法有两个目的(即学习模型 h 和选择特征),是基于包装的风格,因为它取决于 h(假设空间)和错误率 R e m h R_{emh} Remh
3.1.2 两类问题的救济算法
3.1.2.1 基于属性重要性的属性约简算法
给定属于两个已知类的n个实例的p维(即p个特征)训练数据集D。
基本思路:
属于同一类的实例应该比属于不同类的实例更紧密地联系在一起。查找要素与 w.r.t 类的相关性级别。
救济算法:
- 设置一个正阈值 τ \tau τ 集合 S=selected_subset={};初始化所有特征 w(i) = 0
- 重复以下过程m次
①从训练数据集D中随机选择一个实例 x = ( x 1 , x 2 , ... , x p ) T x=(x_1, x_2, ..., x_p)^T x=(x1,x2,...,xp)T;
②在D中计算其接近命中 H:最接近的同类实例;
③在D中计算其未遂 M:=最接近的不同类实例;
④更新所有要素的权重:
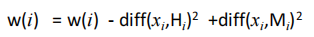
- for i=1 to p
如果 w ( i ) / m > τ w(i)/m>\tau w(i)/m>τ,则将第 i 个特征添加到 S 。
注意:如果任何给定特征在同一类的附近实例中与该特征的差异大于另一类的邻近实例,则该特征的权重会降低,反之则会增加。
利弊
- 缺点:
- 仅适用于二进制类问题。
- 训练不足的例子会导致愚蠢的救济。
- 如果大多数特征都是相关的,则救济选择所有特征(即使没有必要)。
- 由于功能重复,无法删除冗余
- 优点:
- 线性时间,非常快
- 噪声耐受性。
- 不受特征交互的影响(权重是累积的,共同决定)。
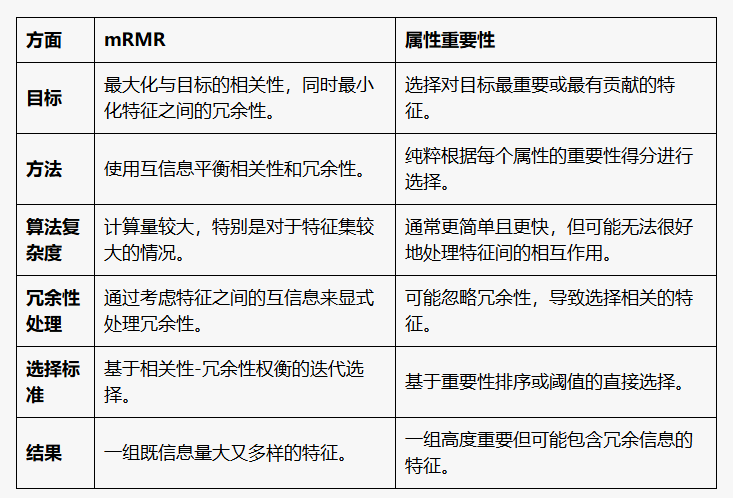
3.1.2.2 最小冗余最大相关性(mRMR)特征选择
两个离散随机变量X和Y的互信息可以定义为
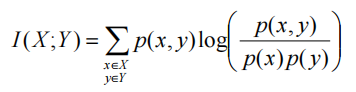
p(X,Y)是Xand Y的联合概率分布函数,p(X)和p(Y)分别是X和Y的边际概率分布函数。
类别 c 的特征集 S 的相关性由个体特征 f i f_i fi 和类别 c 之间的所有互信息值的平均值定义如下:
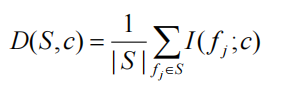
集合 S 中所有特征的冗余度是特征 f i f_i fi 和特征 f j f_j fj 之间的所有互信息值的平均值:
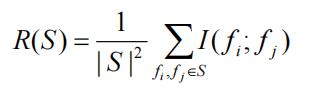
特征选择的mRMR标准: m a x D ( S , c ) & m i n R ( S ) max\;D(S,c)\;\&\;min\;R(S) maxD(S,c)&minR(S),这是一个多目标优化问题。
替代方案(转换为单一目标):
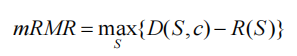
可以证明:
I ( x , y ) = E n t r o p y ( y ) − E n t r o p y ( y ∣ x ) = g a i n ( x ) I(x, y) = Entropy(y) - Entropy(y | x) = gain (x) I(x,y)=Entropy(y)−Entropy(y∣x)=gain(x)
= E n t r o p y ( x ) − E n t r o p y ( x ∣ y ) = g a i n ( y ) = Entropy(x) - Entropy(x | y) = gain (y) =Entropy(x)−Entropy(x∣y)=gain(y)
如果我们在ID3算法中将一个变量视为决策属性,将另一个视为测试属性。因此,两个变量(属性)之间的相关性或依赖性相当于一个变量相对于另一个变量引起的分区的纯度(或重叠)。或者,条件熵实际上是对条件概率的度量。
设xi为特征fi的集合隶属度指标函数,i=1,...,n,然后,mRMR可以重写为
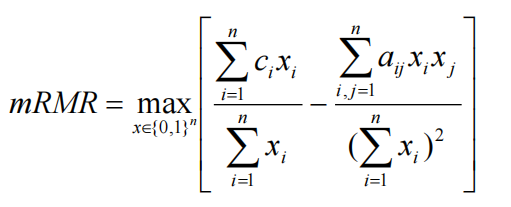
一个非线性组合优化问题,很难在多项式时间内精确求解。
实现 mRMR 准则的简化贪心替代:
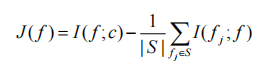
J(f) 的值量化了给定特征 f 与分类任务的相关性,该分类任务因 f 和其他特征之间的冗余而受到惩罚。
设F为全特征集。设置一个正整数 k 作为阈值。然后,基于 mRMR 准则的近似算法进行如下:
- 初始化S为空;
- 选择 F 或 S 中使J(f)最大化的特征 f,并设置
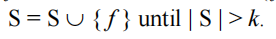
3.1.2.3 对比
3.2 特征提取(无监督的)
- 线性变换(变量级别)
原始变量向量 x = ( x 1 , x 2 , . . . , x p ) T x=(x_1, x_2, ..., x_p)^T x=(x1,x2,...,xp)T,即 p 个特征;
提取的变量向量 z = ( z 1 , z 2 , . . . , z d ) T z=(z_1, z_2, ..., z_d)^T z=(z1,z2,...,zd)T,即 d 个特征,d<p
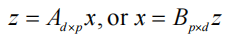
其中 A d × p A_{d\times p} Ad×p 或 B p × d B_{p\times d} Bp×d 是满足某些条件的矩阵 - 线性变换(数据级)
给定 R p R^p Rp 中的一组样本: X 1 , X 2 , . . . , X n X_1, X_2, ..., X_n X1,X2,...,Xn,设 X p × n = ( X 1 , X 2 , . . . , X n ) X_{p\times n}=(X_1, X_2, ..., X_n) Xp×n=(X1,X2,...,Xn)
求矩阵 A p × d A_{p\times d} Ap×d 和 R d × n = ( r 1 , r 2 , . . . , r n ) ( d < p ) R_{d\times n} =(r_1, r_2, ..., r_n)\;(d<p) Rd×n=(r1,r2,...,rn)(d<p),使得
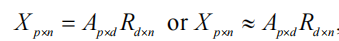
A p × d A_{p\times d} Ap×d 满足某些条件 ⟹ X i \Longrightarrow X_i ⟹Xi 简化为 d 维向量 r i , i = 1 , ... , n r_i,i=1,...,n ri,i=1,...,n
没有提取出明确的新特征,但生成了新的低维数据 - 非线性变换(变量级别)
原始变量向量 x = ( x 1 , x 2 , . . . , x p ) T x=(x_1, x_2, ..., x_p)^T x=(x1,x2,...,xp)T,即 p 个特征;
提取的变量向量 z = ( z 1 , z 2 , . . . , z d ) T z=(z_1, z_2, ..., z_d)^T z=(z1,z2,...,zd)T,即 d 个特征,d<p
z=F(x),其中F是满足某些条件的非线性映射 - 非线性变换(数据级)
给定 R p R^p Rp 中的一组样本: X 1 , X 2 , . . . , X n X_1, X_2, ..., X_n X1,X2,...,Xn,找到一个非线性映射 F : R P → R d , d < p F: R^P\rightarrow R^d,\;d<p F:RP→Rd,d<p,满足某些条件并且 r i = F ( X i ) , i = 1 , ... , n r_i=F(X_i),i=1,...,n ri=F(Xi),i=1,...,n 是缩减的 d 维向量。
没有提取出明确的新特征,但生成了新的低维数据
3.2.1 Subspace representation【子空间表示】
- 观察
高维空间中的数据点通常大多位于低维子空间或流形上。 - 思想
找到最接近数据的子空间和一组跨越该子空间的基向量。然后,原始数据点可以(近似地)由这组向量表示,并用其相应的表示系数向量来代替每个,该表示系数向量的维数是子空间的维数(或基向量的数量)。从而进行了降维。 - 注记
这种方法非常类似于将数据点投影到适当的较低维度子空间上,这样在投影后可以尽可能多地保持数据的一些固有特性,或者可以尽可能小地保持总体投影误差
LDA(Fisher判别式)是一种典型的子空间方法,其中所有数据点都投影到一条线上(1-D),因此任何高维数据点 x 都被减少到实数wTx 代替,w 表示平行于该线的方向矢量。
3.2.2 Matrix Decomposition【矩阵分解】(一种子空间方法)
-
给定维度 p 的 n 个观测 X 1 , X 2 , ... , X n X_1,X_2,...,X_n X1,X2,...,Xn(即在p个变量的向量上)
-
让数据矩阵为
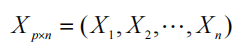
-
矩阵分解试图找到满足某些条件(例如满秩或正交性)的p-by-d(d<p)基矩阵A和解决最小化问题的d-by-n表示矩阵R:
-
然后,最优数据替换原始数据X,实现降维
-
最小化过程可以被视为找到A和R,使得以下矩阵分解(几乎)成立
X ≈ A R X≈AR X≈AR,其中
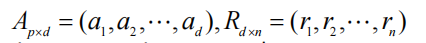
-
然后以矢量方式,我们
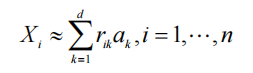
-
换言之,原始 p 维数据点可以用 d 个线性独立向量 { a k , k = 1 , ... , d } \{a_k,k=1,...,d\} {ak,k=1,...,d}表示,将原始X替换为R:
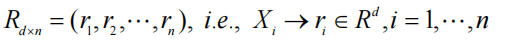
-
矩阵分解方法在数据层面起作用;没有明确的提取特征可用;
-
降维后的数据点由表示系数组成,完全没有任何语义或物理意义,即每个维度(或特征)都很难解释。
-
对于原始空间中的新样本x,必须计算表示系数,以获得其减少的低维对应物r,即,x=Ar 或 m i n ∣ ∣ x − A r ∣ ∣ min||x-Ar|| min∣∣x−Ar∣∣ 或通过某种方法。
矩阵分解评述
- d的选择至关重要;
- 显然,秩 ( A R ) ≤ d (AR)\le d (AR)≤d。因此,如果秩 ( X ) > d (X)>d (X)>d,则精确分解X=AR永远不成立!
- 对于太小的d,最小的可能误差 ∣ ∣ X − A R ∣ ∣ ||X-AR|| ∣∣X−AR∣∣ 可能很大,导致较差的降维结果(就聚类或分类而言)。
- 如果将一些正则项添加到矩阵分解目标函数中,例如,对于常数 α>0
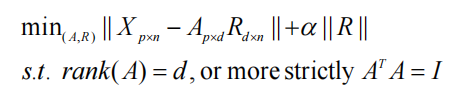
则第一项旨在最小化分解误差,而第二项旨在获得稀疏表示矩阵,其中α作为两项之间的折衷。 - 目标函数中涉及的范数 ∣ ∣ ∣ ∣ ||\;|| ∣∣∣∣理论上可以是任何Lp型(或Frobenius范数),但具有不同程度的实际可解性困难。
3.2.3 PCA method【主成分分析方法】
- 主成分分析(PCA),由 Karl Pearson 于1901年发明
- 一种统计程序,使用正交变换将一组可能相关变量的观测值转换为一组线性不相关变量的值,称为主成分。
- 这种转换的定义方式是,第一主成分具有最大的可能方差,第二主成分具有第二大的可能方差等。
- 主成分分析可以从不同的角度进行一些解释,从而获得其表达的不同方式。
给定在p的向量上的n个观测值 X 1 , X 2 , ... , X n X_1,X_2,...,X_n X1,X2,...,Xn的样本变量
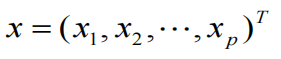
计算样本平均值:
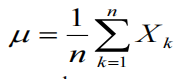
样本的协方差矩阵:
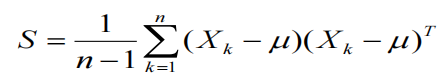
让
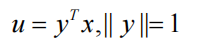
u 是 x 在单位向量 y 生成的线上的投影。然后,样本中变量 u 的方差为
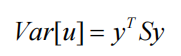
PC的代数定义
样品的第一个主要成分
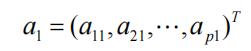
是以下各项的最佳解决方案:
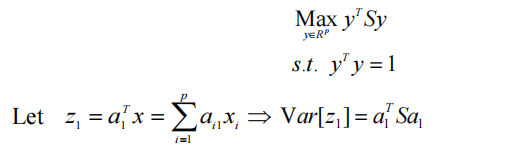
第一个PC在样本中保留了最大的变化量。换句话说,样本 x 在由 a1 生成的线上的投影具有最大的方差。
通常,将样本的第k个PC
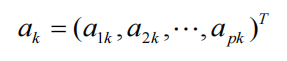
定义为最大化问题的最优解
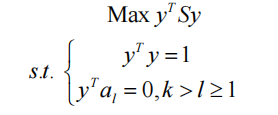
样品在ak上的投影:
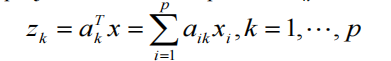
然后,
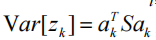
在与第一个k-1主分量正交的子空间内给出样本中的最大方差
让 λ 1 ≥ λ 2 ≥ . . . ≥ λ p ≥ 0 \lambda_1 \ge \lambda_2 \ge ... \ge \lambda_p \ge 0 λ1≥λ2≥...≥λp≥0 为 S 的特征值,
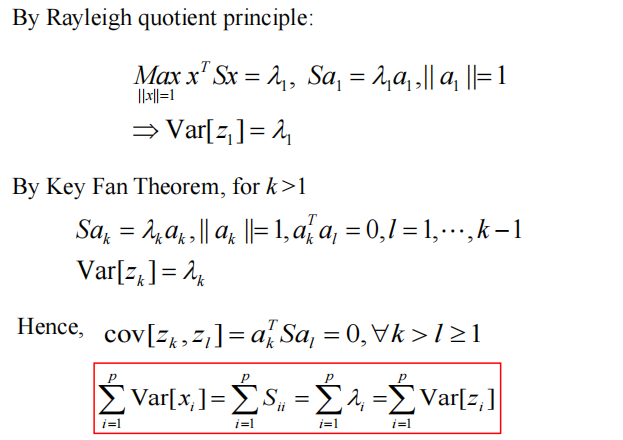
A = ( a 1 , a 2 , ... , a n ) A=(a_1,a_2,...,a_n) A=(a1,a2,...,an) 然后 A T A = I ⟹ A^TA=I \Longrightarrow ATA=I⟹ A 是正交矩阵 ⟺ \Longleftrightarrow ⟺在 R p R^p Rp 中形成正交基
在这个正交变换之后,新变量z有一个不同的方差分布。
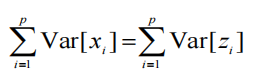
和 V a r ( z i ) Var(z_i) Var(zi) 已经按降序排列。因此,如果我们只保留前d(<p)个变换变量作为我们提取的特征 z ′ = ( z 1 , z 2 , ... , z d ) z'=(z1,z2,...,zd) z′=(z1,z2,...,zd)(即,对应于前d个PC),则降维是在样本方差方面的一些信息损失的情况下进行的,样本方差由样本协方差矩阵的第一(p-d)个最小特征值之和界定。

在计算PC之前,通常通过以下方式定义标准化变量是有用的
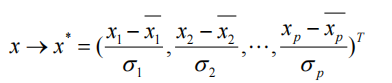
通过这种方式,S*=S,得到的PC将是无量纲的。主成分分析最大的问题是在语义上解释 PC 和 z' 的困难;它们在实践中可能毫无意义,尤其是当PC同时包含正条目和负条目时。
例如,x1表示"尺寸",x2表示"头发颜色",x3表示"眼睛颜色",如果第一主成分显示:
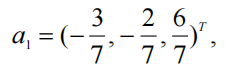
则新变量z1可能在语义上毫无意义。
主成分分析(Principal Component Analysis,PCA)是一种线性降维技术,用于数据预处理、特征提取和数据压缩。PCA 通过将高维数据投影到一个低维空间,保留数据的主要信息,从而实现降维。以下是对PCA的详细介绍。
什么是PCA Method
PCA 是一种统计方法,通过线性变换将数据集从高维空间映射到低维空间。其目标是找到数据方差最大化的方向(即主成分),这些方向是数据的主要变化趋势。PCA 是一种无监督学习方法,不需要标签数据。
工作原理
- 数据标准化:对数据进行标准化处理,使其均值为0,方差为1。
- 计算协方差矩阵:计算数据的协方差矩阵,以衡量特征之间的关系。
- 特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量。
- 选择主成分:选择前 k 个最大的特征值对应的特征向量作为主成分。
- 数据投影:将数据投影到选定的主成分上,得到降维后的数据。
优缺点
- 优点
- 降低维度:有效减少数据的维度,减少计算成本和存储需求。
- 去除冗余:通过去除相关性高的特征,保留数据的主要信息。
- 数据可视化:将高维数据投影到二维或三维空间,便于数据的可视化和理解。
- 简化模型:降维后的数据可以提高机器学习模型的性能,减少过拟合风险。
- 缺点
- 线性假设:PCA 假设数据是线性可分的,对于非线性数据效果较差。
- 信息损失:降维过程中可能会丢失一些重要信息,尤其是当主成分数较少时。
- 解释性差:降维后的特征(主成分)往往缺乏直观的物理意义,难以解释。
- 敏感性:对异常值和噪声较为敏感,可能影响结果的准确性。
解决的问题
PCA 主要用于以下几类问题:
- 数据降维:将高维数据降维到低维空间,以便进行数据处理和分析。
- 特征提取:从高维数据中提取有用的特征,用于分类、回归等机器学习任务。
- 数据压缩:减少数据的维度,降低存储和计算成本。
- 去除噪声:通过去除方差较小的特征,减少数据中的噪声。
常见应用场景
- 图像处理:用于图像降维和特征提取,如人脸识别中的特征提取。
- 信号处理:用于压缩和降噪,如音频信号的压缩。
- 金融分析:用于降维和特征提取,如股票价格数据的分析。
- 文本处理:用于文本数据的降维和特征提取,如文档分类和聚类。
小结
PCA 是一种经典且广泛应用的线性降维技术,通过找到数据方差最大化的方向,将高维数据投影到低维空间,保留数据的主要信息。尽管其假设数据是线性可分的,且在降维过程中可能会丢失一些信息,但其在数据预处理、特征提取和数据压缩等领域表现出色。
3.2.4 Kernel PCA【核的主成分分析】
Kernel Principal Component Analysis (Kernel PCA) 是一种非线性降维技术,它通过引入核方法(Kernel Method)扩展了传统的主成分分析(PCA)。
什么是Kernel PCA
Kernel PCA 是一种基于核方法的降维技术,用于处理非线性数据。它通过将数据映射到一个高维的特征空间,在这个高维空间中进行线性PCA,从而捕捉到数据的非线性特征。
工作原理
- 选择核函数:选择一个合适的核函数 k(x,y),如线性核、多项式核、高斯径向基函数(RBF)核等。
- 计算核矩阵:计算核矩阵 K,其中 K i j = k ( x i , x j ) K_{ij}=k(x_i,x_j) Kij=k(xi,xj)
- 中心化:对核矩阵进行中心化处理。
- 特征值分解:对中心化后的核矩阵进行特征值分解,得到特征值和特征向量。
- 降维:选择前 d 个最大的特征值对应的特征向量,将数据投影到这些特征向量上,得到降维后的数据。
优缺点
- 优点
- 处理非线性结构:Kernel PCA 能够捕捉数据的非线性结构,这一点是传统PCA无法做到的。
- 灵活性:通过选择不同的核函数,Kernel PCA 可以适应各种不同类型的数据分布和结构。
- 无需显式映射:无需显式计算高维空间中的坐标,直接通过核函数计算内积,避免了高维计算的复杂性。
- 缺点
- 计算复杂度高:计算核矩阵和进行特征值分解的时间复杂度较高,尤其是对于大规模数据集。
- 参数选择困难:选择合适的核函数和其参数(如RBF核中的带宽参数)可能比较困难,需要经验和实验。
- 解释性差:降维后的特征在原始空间中没有直观的解释,难以理解具体的物理意义。
解决的问题
Kernel PCA 主要用于以下几类问题:
- 非线性降维:用于将高维非线性数据降维,以便进行数据可视化或进一步的分析。
- 特征提取:在模式识别和机器学习中,Kernel PCA 可以用于提取数据中的非线性特征。
- 数据预处理:在应用其他机器学习算法前,使用Kernel PCA对数据进行预处理,以提高模型的性能。
常用核函数
- 线性核: k ( x , y ) = x T y k(x,y)=x^Ty k(x,y)=xTy
- 多项式核: k ( x , y ) = ( x T y + c ) d k(x,y)=(x^Ty+c)^d k(x,y)=(xTy+c)d
- 高斯RBF核: k ( x , y ) = e x p ( − ∥ x − y ∥ 2 2 σ 2 ) k(x,y)=exp(-\frac{∥x−y∥^2}{2σ^2}) k(x,y)=exp(−2σ2∥x−y∥2)
小结
Kernel PCA 是一种强大的工具,特别适用于处理非线性数据结构。尽管其计算复杂度较高且参数选择具有挑战性,但它在许多实际应用中都表现出色,尤其在需要非线性特征提取的场景中。
3.2.5 Manifold Learning【流形学习】
Manifold Learning(流形学习)是一类非线性降维技术,旨在发现高维数据中潜在的低维流形结构。流形学习假设高维数据实际上是嵌入在一个低维流形中的,通过揭示这种低维结构,可以更好地理解和处理数据。
什么是Manifold Learning
流形学习假设高维数据点分布在一个低维的流形上,即高维数据可以通过一个低维的嵌入空间来表示。流形学习算法通过寻找这种低维嵌入空间,为数据降维,从而揭示数据的内在结构。
常见的Manifold Learning算法
- 等距映射(Isomap):
基于测地距离(Geodesic Distance)来保留数据在流形上的全局几何结构。 - 局部线性嵌入(LLE):
通过保持局部邻域内数据点的线性关系来找到低维表示。 - 拉普拉斯特征映射(Laplacian Eigenmaps):
通过构建数据点的图并计算拉普拉斯矩阵的特征向量来找到低维嵌入。 - t-分布随机邻域嵌入(t-SNE):
通过最小化高维空间中数据点对和低维空间中数据点对的相似性差异来实现降维,特别适用于高维数据的可视化。
优缺点
- 优点
- 揭示非线性结构:Manifold Learning 能够捕捉数据中的非线性结构,比线性降维方法(如PCA)更强大。
- 数据可视化:特别适用于高维数据的可视化,帮助理解数据的内在结构。
- 灵活性:适用于各种类型的数据,包括图像、文本和时间序列数据等。
- 缺点
- 计算复杂度高:许多流形学习算法在处理大规模数据集时计算量大,内存需求高。
- 参数选择困难:选择合适的参数(如邻居数、核函数参数等)往往需要经验和实验。
- 对噪声敏感:某些算法对数据中的噪声较为敏感,可能影响结果的稳定性。
- 非常规数据处理:对于某些非典型的数据分布,流形学习可能无法有效捕捉底层结构。
解决的问题
Manifold Learning 主要用于以下几类问题:
- 非线性降维:将高维数据降维到低维空间,以便进行数据可视化或进一步分析。
- 特征提取:从高维数据中提取低维特征,用于分类、聚类或其他机器学习任务。
- 数据可视化:将高维数据映射到二维或三维空间中,帮助理解数据的结构和模式。
- 异常检测:通过识别低维流形上的异常点,进行异常检测和数据清洗。
常见应用场景
- 图像处理:在图像分类和识别中,流形学习可以帮助提取有用的特征。
- 自然语言处理:用于文本数据的降维和特征提取。
- 生物信息学:用于基因表达数据的分析和可视化。
小结
Manifold Learning 是一种强大的非线性降维技术,通过发现高维数据中的低维流形结构,可以有效地进行数据降维、特征提取和可视化。尽管其计算复杂度较高且参数选择具有挑战性,但在处理复杂数据结构时,流形学习表现出了显著的优势。
3.2.6 Locally Linear Embedding (LLE)【局部线性嵌入】
局部线性嵌入(Locally Linear Embedding, LLE)是一种非线性降维算法,旨在保留高维数据中的局部几何结构。LLE 假设数据在局部邻域内是线性的,并通过保持这些局部关系来找到低维嵌入。以下是对 LLE 的详细介绍。
什么是 Locally Linear Embedding (LLE)
LLE 是一种流形学习方法,它通过分析数据点在其局部邻域中的线性关系,找到数据的低维表示。LLE的核心思想是,虽然数据在全局上可能是非线性的,但在局部上可以近似为线性。
工作原理
- 确定邻居:对于每个数据点,找到其最近的 (K) 个邻居。
- 局部线性重构 :对每个数据点 (x_i),用其邻居的线性组合来重构该点。具体地,计算重构权重 (W_{ij}),使得误差最小:
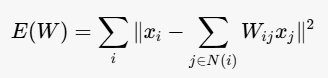
其中 N(i) 是数据点 x i x_i xi 的邻居集合。 - 低维嵌入 :在低维空间中找到点 (y_i),使得这些点的重构权重保持不变,即:
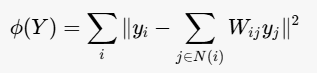
通过求解该优化问题,得到低维嵌入 Y。
优缺点
优点
- 保留局部结构:LLE 能够很好地保留数据的局部几何结构,使得降维后的数据在低维空间中保持原有的局部关系。
- 无参数非线性降维:LLE 不需要选择核函数等参数,直接通过局部线性关系进行降维。
- 适用于非线性数据:LLE 能够处理非线性的高维数据,揭示其内在的低维流形结构。
缺点
- 计算复杂度高:LLE 需要计算每个数据点的邻居,并求解特征值问题,计算复杂度较高,尤其在大规模数据集上。
- 对噪声敏感:对数据中的噪声较为敏感,噪声可能会影响局部重构权重的准确性。
- 参数选择:需要选择邻居数 (K),不同的 (K) 值可能会影响结果,需要进行调参。
PPT给的
主要优点:
1) 能够学习任何维度的局部线性低维流形。
2) 该算法简化为稀疏矩阵特征分解,计算复杂度相对较小,易于实现。
3)它可以处理非线性数据并降维。
主要缺点:
1) 样本集必须密集。
2)该算法对最近邻样本的数量很敏感。不同的这样的数字对最终的尺寸缩减结果有很大的影响。
3) 选择适当的d值并不简单
解决的问题
LLE 主要用于以下几类问题:
- 非线性降维:将高维非线性数据降维到低维空间,以便进行数据可视化或进一步分析。
- 特征提取:从高维数据中提取低维特征,用于分类、聚类或其他机器学习任务。
- 数据可视化:将高维数据映射到二维或三维空间中,帮助理解数据的结构和模式。
常见应用场景
- 图像处理:用于图像降维和特征提取,如人脸识别中的特征提取。
- 生物信息学:用于基因表达数据的降维和可视化。
- 文本处理:用于文本数据的降维和特征提取,如文档分类和聚类。
小结
局部线性嵌入(LLE)是一种强大的非线性降维技术,通过保留数据的局部几何结构,实现高维数据的低维表示。尽管其计算复杂度较高且对噪声较为敏感,但在处理复杂的非线性数据时,LLE 能够揭示数据的内在结构,适用于多种数据分析和机器学习任务。
第四章 数据表示学习(Data representation)
4.1 Sparse Learning【稀疏学习】
Sparse Learning(稀疏学习)是一类机器学习方法,其目标是在高维数据中寻找少量重要特征,从而简化模型,增强可解释性,并提高泛化能力。稀疏学习通过引入稀疏性约束,使得模型参数中大部分为零,仅保留少量非零参数。
什么是 Sparse Learning
稀疏学习是一种强调模型稀疏性的机器学习技术,通过在模型训练过程中引入稀疏性约束(如L1正则化),来减少模型的复杂度和防止过拟合。常见的稀疏学习方法包括Lasso回归、稀疏编码、稀疏字典学习等。
工作原理
稀疏学习通常通过优化包含稀疏性正则化项的目标函数来实现。以Lasso回归为例,其目标函数为:
其中,μ 是正则化参数,用于控制稀疏性程度,x 是模型参数。通过优化这个目标函数,可以得到一个稀疏的权重向量 x,其中许多元素为零。
优缺点
- 优点
- 特征选择:稀疏学习能够自动选择重要特征,减少特征数量,提高模型的可解释性。
- 防止过拟合:通过引入稀疏性约束,可以减少模型的复杂度,防止过拟合,提高泛化性能。
- 提高计算效率:稀疏模型中只有少量非零参数,计算和存储成本较低。
- 可解释性:稀疏模型更容易解释,因为它们只使用了少量重要特征。
- 缺点
- 模型复杂度:稀疏学习方法的实现和优化可能比较复杂,尤其在高维数据上。
- 参数选择:需要选择合适的正则化参数 μ,不同的参数对稀疏性的影响较大。
- 计算成本:虽然稀疏模型计算效率较高,但在训练过程中引入稀疏性约束的优化问题可能计算成本较高。
- 对数据分布敏感:稀疏学习方法对数据分布较为敏感,可能需要进行数据预处理和归一化。
解决的问题
稀疏学习主要用于以下几类问题:
- 特征选择:从高维数据中选择重要特征,减少特征数量,提高模型性能。
- 异常检测:通过稀疏表示发现数据中的异常点。
- 信号处理:在信号处理和压缩感知中,稀疏学习用于信号重构和降噪。
- 图像处理:用于图像压缩、去噪和特征提取。
常见应用场景
- 基因数据分析:在生物信息学中,用于从高维基因表达数据中选择重要基因。
- 文本处理:在自然语言处理(NLP)中,用于从大量特征中选择重要的词汇或短语。
- 图像识别:在计算机视觉中,用于图像特征提取和压缩。
- 金融分析:在金融数据分析中,用于选择重要的金融指标和特征。
小结
稀疏学习是一种强大的机器学习技术,通过引入稀疏性约束,可以从高维数据中选择重要特征,简化模型,提高可解释性和泛化能力。尽管其实现和优化可能较为复杂,但在特征选择、异常检测、信号处理和图像处理等领域表现出色。
4.2 自动编码器
自动编码器(Autoencoder)是一类无监督学习模型,旨在学习数据的低维表示。不同类型的自动编码器在结构和应用上有各自的特点。
4.2.1 自动编码器(Autoencoder)
自动编码器是一种神经网络,通常由编码器(Encoder)和解码器(Decoder)组成。编码器将输入数据压缩到低维潜在空间,解码器则将低维表示重构回原始数据。其目标是最小化重构误差,即输入数据与重构数据之间的差异。
结构
- 编码器:输入层到潜在空间层的神经网络,通常是一个压缩过程。
- 潜在空间(Latent Space):也称为编码,表示数据的低维特征。
- 解码器:从潜在空间层到输出层的神经网络,通常是一个解压过程。
优点
- 学习数据的低维表示。
- 可用于数据降噪、特征提取等任务。
缺点
- 通常只适用于相对简单的数据分布。
- 对噪声和异常值敏感。
4.2.2 可变自动编码器(Variational Autoencoder, VAE)
可变自动编码器(VAE)是在传统自动编码器基础上引入概率模型,通过潜在变量的分布来生成数据。VAE 不仅可以重构输入数据,还可以生成新的数据样本。
结构
- 编码器:输出潜在变量的均值和方差。
- 潜在空间:从高斯分布中采样的潜在变量。
- 解码器:将采样的潜在变量解码回原始数据。
优点
- 能生成新数据样本,具有生成模型的能力。
- 提供潜在变量的概率分布,更具鲁棒性。
缺点
- 训练过程较为复杂,需要优化变分下界。
- 对于高维数据生成效果可能不佳。
4.2.3 图形自动编码器(Graph Autoencoder, GAE)
图形自动编码器(GAE)是一种用于图结构数据(如社交网络、分子结构等)的自动编码器。其目标是学习图节点的低维表示,同时保留图的拓扑结构。
结构
- 编码器:通常采用图卷积网络(GCN)等图神经网络,将图节点嵌入到低维空间。
- 潜在空间:表示图节点的低维嵌入。
- 解码器:重构图的拓扑结构或节点属性。
优点
- 能处理复杂的图结构数据。
- 有效捕捉图的拓扑信息和节点特征。
缺点
- 计算复杂度较高,尤其在大规模图数据上。
- 需要设计合适的图神经网络结构。
4.2.4 变分图自动编码器(Variational Graph Autoencoder, VGAE)
变分图自动编码器(VGAE)结合了VAE和GAE的优点,用于图结构数据的生成和表示学习。它通过引入潜在变量的概率分布,增强了图数据的生成能力。
结构
- 编码器:输出潜在变量的均值和方差,通常采用图神经网络。
- 潜在空间:从高斯分布中采样的潜在变量,表示图节点的低维嵌入。
- 解码器:重构图的拓扑结构或节点属性。
优点
- 能生成新图数据样本,具有生成模型的能力。
- 提供潜在变量的概率分布,更具鲁棒性。
缺点
- 训练过程较为复杂,需要优化变分下界。
- 对于大规模图数据,计算复杂度较高。
4.2.5 小结
不同类型的自动编码器在数据表示和生成上各有优势。自动编码器适用于数据降维和特征提取,VAE 提供生成模型能力,GAE 处理图结构数据,而 VGAE 则结合了概率模型和图结构数据的优势,适用于复杂图数据的生成和表示学习。
4.4 生成对抗性网络
生成对抗网络(Generative Adversarial Networks, GANs)是一种由 Ian Goodfellow 等人在 2014 年提出的深度学习模型。GANs 的核心思想是通过两个神经网络的对抗过程来生成逼真的数据。这两个网络分别是生成器(Generator)和判别器(Discriminator)。
- 生成器(Generator):生成器试图从随机噪声中生成逼真的数据。它的目标是欺骗判别器,使其认为生成的数据是真实的。
- 判别器(Discriminator):判别器的任务是区分真实数据和生成数据。它通过不断学习来提高区分真假数据的能力。
GANs 的训练过程可以描述为一个零和博弈(Zero-Sum Game):
- 生成器生成假数据:生成器从随机噪声中生成数据样本,并将其输入判别器。
- 判别器鉴别数据真假:判别器同时接收真实数据和生成器生成的数据,并尝试区分它们。
- 更新判别器:根据判别器的判断结果,更新判别器的参数,以便更好地识别生成数据。
- 更新生成器:生成器根据判别器的反馈,调整自身参数,以生成更逼真的数据,从而更好地欺骗判别器。
GANs 的目标是找到生成器和判别器之间的平衡点,即生成器生成的数据足够逼真,以至于判别器无法区分真假数据。
生成对抗性网络(GANs)的优势:
- 合成数据生成:GANs可以生成类似于某些已知数据分布的新的合成数据,这对于数据增强、异常检测或创造性应用非常有用。
- 高质量结果:GANs可以在图像合成、视频合成、音乐合成和其他任务中产生高质量、逼真的结果。
- 无监督学习:GANs可以在没有标记数据的情况下进行训练,使其适合于无监督学习任务,因为标记数据很少或难以获得。
- 通用性:GANs可应用于广泛的任务,包括图像合成、文本到图像合成、图像到图像传输、异常检测、数据增强等。
生成对抗性网络(GANs)的缺点:
- 训练不稳定性:GANs可能很难训练,有不稳定、模式崩溃或无法收敛的风险。
- 计算成本:GANs可能需要大量的计算资源,并且训练速度较慢,尤其是对于高分辨率图像或大型数据集。
- 过拟合:GANs会对训练数据进行过拟合,产生与训练数据过于相似且缺乏多样性的合成数据。
- 偏见和公平性:GANs可以反映训练数据中存在的偏见和不公平性,导致歧视性或有偏见的合成数据。
- 可解释性和问责制:GANs可能不透明,难以解释或解释,因此难以确保其应用程序的问责制、透明度或公平性。
4.5 对比学习
对比学习(Contrastive Learning)是一种自监督学习方法,通过对比样本之间的相似性和差异性来学习数据的表示。该方法的核心思想是将相似的样本拉近,将不相似的样本推远,从而使模型能够学习到更加有意义的特征表示。
对比学习的模型
对比学习通常包括以下几个组成部分:
- 数据增强(Data Augmentation):对一个样本进行不同的变换(如旋转、裁剪、颜色抖动等),生成一对正样本(positive pair)。
- 编码器(Encoder):通过一个神经网络(如卷积神经网络)将输入样本编码为特征向量。
- 投影头(Projection Head):通常是一个小的神经网络,用于将编码器输出的特征向量投射到对比学习的特征空间中。
- 对比损失函数(Contrastive Loss Function) :最常用的是 InfoNCE 损失函数,它的目标是最大化正样本对的相似度,最小化负样本对的相似度。

以下是对比学习的基本流程:
- 对一个样本进行数据增强,生成两个视图(正样本对)。
- 通过编码器和投影头将这两个视图映射到特征空间。
- 使用对比损失函数计算正样本对和负样本对之间的相似度,并进行反向传播更新模型参数。
典型模型
- SimCLR(Simple Framework for Contrastive Learning of Visual Representations):这是一个经典的对比学习框架,包含数据增强、编码器、投影头和对比损失。
- MoCo(Momentum Contrast):通过使用动量编码器来缓解大批量训练的内存限制,同时保持一个动态更新的字典来存储负样本。
- BYOL(Bootstrap Your Own Latent):不需要负样本,通过引入一个目标网络来指导主网络的学习。
优缺点
优点:
- 无需大量标注数据:对比学习是一种自监督学习方法,可以在没有大量标注数据的情况下进行训练。
- 泛化能力强:对比学习通过学习数据的内在结构,使模型在下游任务中有更好的泛化能力。
- 灵活性高:可以适用于各种类型的数据,如图像、文本、音频等。
缺点:
- 计算资源需求高:对比学习通常需要大量的计算资源,尤其是在处理大规模数据集时。
- 依赖数据增强技巧:对比学习的效果很大程度上依赖于数据增强的质量和多样性。
- 难以选择负样本:在某些情况下,选择适当的负样本对可能比较困难,影响模型的效果。
应用场景
- 图像分类和检索:通过学习图像的特征表示,对比学习可以用于图像分类和相似图像检索。
- 自然语言处理:对比学习在文本表示、句子嵌入等任务中表现出色。
- 推荐系统:通过学习用户和物品的特征表示,对比学习可以提高推荐系统的性能。
- 音频处理:在语音识别、音乐分类等任务中,对比学习同样可以提供有效的特征表示。
4.6 强化学习(Reinforcement Learning)
4.6.1 强化学习
强化学习(Reinforcement Learning, RL) 是一种通过与环境交互来学习行为策略的机器学习方法。在强化学习中,智能体(Agent)通过采取行动从环境(Environment)中获得反馈,以最大化其累积奖励(Cumulative Reward)。
强化学习的基本概念
- 智能体(Agent):学习和决策的主体。
- 环境(Environment):智能体所处的外部系统。
- 状态(State):环境在某一时刻的具体情况。
- 动作(Action):智能体对环境所采取的操作。
- 奖励(Reward):环境对智能体动作的反馈信号。
- 策略(Policy):智能体选择动作的准则,可以是确定性策略或随机策略。
- 价值函数(Value Function):用于评估状态或状态-动作对的好坏程度。
强化学习的模型
强化学习的典型模型包括:
- 马尔可夫决策过程(Markov Decision Process, MDP):描述了环境的状态转移和奖励机制。
- Q-Learning:一种无模型的强化学习算法,通过学习状态-动作对的价值(Q值)来制定策略。
- 策略梯度方法(Policy Gradient Methods):直接优化策略函数,使得期望奖励最大化。
- 演员-评论家方法(Actor-Critic Methods):结合了值函数和策略函数的优点,通过两部分共同学习来优化策略。
4.6.2 DQN(Deep Q-Network)
DQN 是深度强化学习的一个重要里程碑,由 DeepMind 在 2015 年提出。DQN 结合了 Q-Learning 和深度神经网络,能够处理高维度的状态空间(如图像)。
DQN 的关键思想
- 使用深度神经网络逼近 Q 值:使用神经网络代替传统的 Q 表来逼近状态-动作对的 Q 值。
- 经验回放(Experience Replay):将智能体的经验存储在一个回放缓冲区中,随机抽取小批量经验进行训练,打破数据相关性,提高样本利用率。
- 目标网络(Target Network):引入一个目标网络,定期更新其参数,减少训练过程中的不稳定性。
DQN 的训练流程
- 智能体从环境中获取状态,并选择动作(使用 ε-greedy 策略)。
- 执行动作,获得新状态和奖励,将经验存储到回放缓冲区。
- 从回放缓冲区中随机抽取小批量经验,计算目标 Q 值。
- 使用神经网络逼近 Q 值,更新网络参数。
- 定期更新目标网络的参数。
4.6.3 优缺点
优点:
- 自动学习策略:无需明确编写规则,通过与环境交互自动学习最优策略。
- 适应性强:能够适应动态和复杂的环境。
- 广泛的应用范围:适用于游戏、机器人控制、推荐系统等领域。
缺点:
- 样本效率低:需要大量的交互数据来进行训练。
- 训练不稳定:特别是在高维状态空间中,训练过程可能会不稳定。
- 计算资源需求高:特别是深度强化学习方法,通常需要强大的计算资源。
4.6.4 应用场景
- 游戏:如 AlphaGo、Atari 游戏等,通过自我对弈和环境交互学习策略。
- 机器人控制:通过实时环境反馈优化控制策略,实现路径规划、操作任务等。
- 自动驾驶:通过模拟和真实世界数据训练,优化车辆的驾驶策略。
- 金融交易:通过市场数据学习交易策略,优化投资组合。
- 推荐系统:通过用户行为数据优化推荐策略,提高用户满意度。
第五章 注意力机制和 Transformer
5.1 注意力机制(Attention Mechanism)
注意力机制(Attention Mechanism) 是一种在处理序列数据(如自然语言处理和计算机视觉)时广泛应用的技术。其核心思想是让模型在处理数据时,更加关注那些对当前任务更重要的部分,从而提高模型的性能和效率。
注意力机制的基本思想
在传统的序列模型中,如 RNN 或 LSTM,随着序列长度的增加,模型可能会逐渐遗忘前面的信息。注意力机制通过计算输入序列中各个位置的权重,让模型在每个时间步都能动态地"关注"到与当前任务最相关的部分。
注意力机制的模型
注意力机制的关键步骤包括:
- 计算注意力权重:通过某种相似度度量(如点积、加法等)计算查询(Query)和键(Key)之间的相似度,得到注意力权重。
- 加权求和:使用注意力权重对值(Value)进行加权求和,得到最终的注意力输出。
数学表述
给定查询 (Q)、键 (K) 和值 (V),注意力输出 (A) 可表示为:
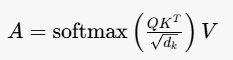
其中, d k d_k dk是键的维度,用于缩放点积结果。
注意力机制的类型
- 自注意力(Self-Attention):输入的查询、键和值都是同一个序列的不同表示,用于捕捉序列内部的依赖关系。
- 多头注意力(Multi-Head Attention):通过并行地计算多个注意力头,捕捉不同子空间的信息,提高模型的表达能力。
- 加性注意力(Additive Attention):通过一个前馈神经网络计算注意力权重,适用于处理不同维度的数据。
- 点积注意力(Dot-Product Attention):使用点积来计算相似度,是自注意力的常用实现。
优缺点
优点:
- 捕捉长距离依赖:能够有效捕捉序列中远距离元素之间的关系。
- 并行计算:特别是在自注意力机制中,可以实现并行计算,提高计算效率。
- 灵活性高:可以适用于多种任务,包括文本、图像、音频等。
缺点:
- 计算复杂度高:尤其是序列长度较长时,计算注意力权重的时间和空间复杂度较高。
- 需要大量数据:注意力机制通常需要大量数据进行训练,以充分学习到有效的权重分布。
用途
- 自然语言处理(NLP):用于机器翻译、文本生成、问答系统等任务。例如,Transformer 模型在机器翻译中的应用取得了显著的效果。
- 计算机视觉:用于图像识别、图像生成、目标检测等任务。例如,视觉 Transformer(ViT)在图像分类任务中表现优异。
- 语音处理:用于语音识别、语音合成等任务,通过捕捉语音信号中的重要特征提高模型性能。
- 推荐系统:用于捕捉用户行为中的关键模式,提高推荐的准确性和个性化程度。
5.2 Transformer
Transformer 是一种基于注意力机制的神经网络架构,最早由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。与传统的 RNN 和 LSTM 模型不同,Transformer 通过并行处理整个序列,解决了序列模型在处理长距离依赖时的效率和性能问题。
Transformer的模型架构
Transformer 的基本架构由编码器(Encoder)和解码器(Decoder)两部分组成。编码器用于将输入序列编码成上下文相关的表示,解码器则利用这些表示生成输出序列。
编码器
每个编码器层包含以下几个主要组件:
- 多头自注意力机制(Multi-Head Self-Attention Mechanism):并行计算多个注意力头,捕捉不同子空间的信息。
- 前馈神经网络(Feed-Forward Neural Network, FFN):每个位置上的向量独立通过一个前馈神经网络进行非线性变换。
- 残差连接(Residual Connection)和层归一化(Layer Normalization):在每个子层之后,添加残差连接和层归一化,帮助训练深层网络。
编码器的计算流程如下:
输入序列 -> 嵌入层(Embedding Layer) -> 位置编码(Positional Encoding) -> 多头自注意力 -> 残差连接和层归一化 -> 前馈神经网络 -> 残差连接和层归一化 -> 编码器输出
解码器
解码器层的结构与编码器类似,但增加了一层编码器-解码器注意力机制(Encoder-Decoder Attention):
- 多头自注意力机制:与编码器类似,但在计算时会屏蔽未来的信息(即掩码机制)。
- 编码器-解码器注意力机制:将解码器的输出与编码器的输出进行注意力计算。
- 前馈神经网络:与编码器相同。
- 残差连接和层归一化:与编码器相同。
解码器的计算流程如下:
目标序列 -> 嵌入层(Embedding Layer) -> 位置编码(Positional Encoding) -> 多头自注意力(掩码) -> 残差连接和层归一化 -> 编码器-解码器注意力 -> 残差连接和层归一化 -> 前馈神经网络 -> 残差连接和层归一化 -> 解码器输出
Transformer的类型
- 原始 Transformer:包括完整的编码器和解码器结构,常用于机器翻译等序列到序列任务。
- BERT(Bidirectional Encoder Representations from Transformers):仅使用编码器部分,通过双向训练来捕捉上下文信息,主要用于自然语言理解任务。
- GPT(Generative Pre-trained Transformer):仅使用解码器部分,主要用于文本生成任务。
- T5(Text-To-Text Transfer Transformer):使用完整的编码器-解码器结构,将所有 NLP 任务统一为文本到文本的转换问题。
优缺点
优点:
- 并行计算:由于不依赖于序列的顺序,Transformer 可以实现并行计算,提高训练效率。
- 长距离依赖:通过自注意力机制,能够有效捕捉序列中远距离元素之间的关系。
- 灵活性强:可以适用于各种序列到序列任务,包括 NLP、计算机视觉等领域。
缺点:
- 计算复杂度:自注意力机制的时间和空间复杂度较高,特别是序列长度较长时。
- 数据需求大:Transformer 通常需要大量数据进行训练,以充分学习到有效的特征表示。
- 内存消耗高:由于需要存储大量的中间计算结果,Transformer 对内存的需求较高。
用途
- 自然语言处理(NLP):用于机器翻译、文本生成、问答系统、文本分类等任务。例如,BERT 和 GPT 模型在各类 NLP 任务中取得了显著的效果。
- 计算机视觉:通过视觉 Transformer(ViT)应用于图像分类、目标检测、图像生成等任务。
- 语音处理:用于语音识别、语音合成等任务,通过
第六章 生成模型(Autoregressive models, VAE, GAN)
6.1 生成模型概述
生成模型(Generative Model) 是一种通过学习数据分布来生成与训练数据相似的新数据的模型。其核心思想是建模数据的概率分布 p(x) ,然后可以从该分布中采样生成新数据。
生成模型的目标
生成模型的主要目标是学习训练数据的分布,以便能够生成具有类似特征的新样本。具体目标包括:
- 建模数据的概率分布:通过学习数据的潜在结构,建模数据的真实分布 ( p(x) )。
- 生成新样本:从学到的分布中采样,生成与训练数据相似的新样本。
- 数据表示:学习数据的潜在表示或特征,用于降维、特征提取等任务。
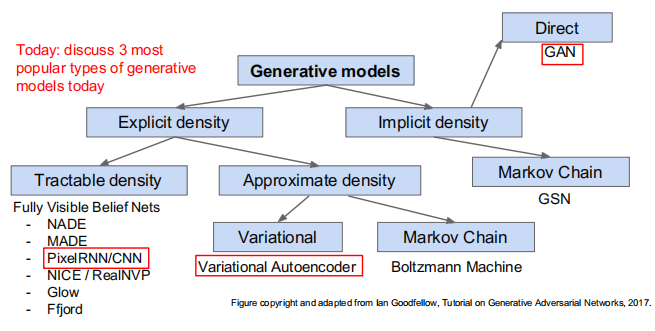
生成模型的分类
生成模型可以根据其实现方式和具体应用进行分类:
- 基于显式概率分布的生成模型
这些模型直接建模数据的概率分布,通常通过最大似然估计(MLE)来训练。
①高斯混合模型(Gaussian Mixture Models, GMM) :假设数据由多个高斯分布混合而成,通过期望最大化(EM)算法进行参数估计。
②隐马尔可夫模型(Hidden Markov Models, HMM) :用于序列数据建模,假设数据由隐状态序列生成,每个状态对应一个观测分布。
③自回归模型(Autoregressive Models):如 PixelRNN、PixelCNN,通过条件概率建模每个像素值。 - 基于隐变量的生成模型
这些模型假设数据生成过程涉及一些未观察到的隐变量,通过最大化边际似然或变分推断进行训练。
①变分自编码器(Variational Autoencoders, VAE) :通过引入隐变量 ( z ),使用变分推断方法近似后验分布 ( p(z|x) ),实现生成和重构数据。【离谱,有的人认为是显式,有的人认为是隐式,谁叫它既引入了隐变量,又使用了最大似然估计】
②生成对抗网络(Generative Adversarial Networks, GAN):由生成器(Generator)和判别器(Discriminator)组成,生成器生成假样本,判别器区分真样本与假样本,通过对抗训练使生成器生成真实样本。 - 基于能量函数的生成模型
这些模型定义一个能量函数,通过最小化能量或最大化效用来生成样本。
①玻尔兹曼机(Boltzmann Machines) :如受限玻尔兹曼机(RBM),通过最小化自由能来学习数据分布。
②能量基模型(Energy-Based Models, EBM):直接建模数据的能量函数,通过最小化能量差异生成样本。
生成模型的应用
生成模型在多个领域有广泛应用,包括但不限于:
- 图像生成:如通过 GAN 生成逼真的图像,应用于图像超分辨率、图像修复等任务。
- 文本生成:包括文本生成、机器翻译、文本摘要等任务,常用模型如 GPT 系列。
- 语音生成:如语音合成、语音转换,通过 VAE 或 GAN 生成自然的语音信号。
- 数据增强:通过生成新样本扩展训练数据集,提升模型的泛化能力。
- 半监督学习:利用生成模型在无标签数据上进行预训练,提升有标签数据上的任务性能。
- 异常检测:通过建模正常数据分布,检测异常数据点。
6.2 PixelRNN
PixelRNN 是一种基于自回归模型的生成模型,专门用于图像生成任务。其基本思想是将图像像素看作序列数据,通过建模每个像素值的条件概率分布来生成图像。具体来说,PixelRNN 通过逐个像素地生成图像的方式,依次生成每个像素值,条件概率分布依赖于之前已经生成的像素值。
PixelRNN 的模型架构
PixelRNN 的核心是使用循环神经网络(RNN)来对图像像素进行建模。模型架构主要由以下几个部分组成:
- 输入图像:图像被视为一个二维矩阵,每个位置的像素值是模型的输入。
- 掩码机制(Masking Mechanism) :为了确保生成每个像素时只依赖于之前生成的像素,PixelRNN 使用了掩码机制。掩码机制分为两种:
- 行掩码(Row Masking):确保生成当前行的像素时只依赖于当前行之前的像素和之前所有行的像素。
- 对角掩码(Diagonal Masking):确保生成当前像素时只依赖于之前所有像素,包括上方和左方的像素。
- RNN 层:使用 RNN(如 LSTM 或 GRU)来处理每一行或每一列的像素序列,以捕捉图像中的长距离依赖关系。
- 输出层:输出层生成每个像素的条件概率分布,通过采样生成最终的像素值。
PixelRNN 的计算流程
以下是 PixelRNN 的基本计算流程:
- 输入图像:将图像转化为像素序列。
- 掩码机制:应用行掩码或对角掩码,确保生成每个像素时只依赖于之前的像素。
- RNN 层:通过 RNN 处理像素序列,生成每个像素的条件概率分布。
- 输出层:从条件概率分布中采样,生成像素值。
- 生成图像:逐个像素生成图像,直到生成完整图像。
优缺点
优点:
- 长距离依赖:通过 RNN 处理像素序列,PixelRNN 能够捕捉图像中的长距离依赖关系。
- 高质量生成:生成的图像质量较高,特别适用于生成具有复杂结构的图像。
缺点:
- 计算复杂度高:由于逐个像素生成图像,PixelRNN 的计算复杂度较高,训练和生成过程中速度较慢。
- 序列依赖性:生成每个像素时依赖于之前所有像素,导致并行处理困难,影响生成效率。
用途
PixelRNN 主要用于以下几个领域:
- 图像生成:生成高质量的图像,应用于图像生成、图像修复等任务。
- 图像超分辨率:通过生成高分辨率的图像细节,用于图像超分辨率任务。
- 图像补全:用于图像中缺失部分的补全,通过生成模型填补缺失像素。
- 数据增强:通过生成新图像样本,扩展训练数据集,提升模型的泛化能力。
结论
PixelRNN 是一种强大的图像生成模型,通过逐个像素地建模图像的条件概率分布,能够生成高质量的图像。尽管其计算复杂度较高,但在需要高质量图像生成的任务中,PixelRNN 仍然表现出色。
6.3 PixelCNN
PixelCNN 是一种自回归生成模型,专门用于图像生成。与 PixelRNN 类似,PixelCNN 也通过逐像素建模图像生成过程,但它使用卷积神经网络(CNN)而非循环神经网络(RNN)。PixelCNN 的基本思想是通过建模每个像素的条件概率分布来生成图像,依次生成每个像素值,条件概率分布依赖于之前已经生成的像素值。
PixelCNN 的模型架构
PixelCNN 的核心是使用卷积神经网络(CNN)来处理图像像素。模型架构主要由以下几个部分组成:
- 输入图像:图像被视为一个二维矩阵,每个位置的像素值是模型的输入。
- 掩码机制(Masking Mechanism) :为了确保生成每个像素时只依赖于之前生成的像素,PixelCNN 使用了掩码卷积。掩码卷积分为两种:
- 垂直掩码卷积(Vertical Masked Convolution):确保生成当前像素时只依赖于当前像素上方的像素。
- 水平掩码卷积(Horizontal Masked Convolution):确保生成当前像素时只依赖于当前像素左侧的像素。
- 卷积层:使用掩码卷积层来处理图像像素,捕捉图像中的局部依赖关系。
- 输出层:输出层生成每个像素的条件概率分布,通过采样生成最终的像素值。
PixelCNN 的计算流程
以下是 PixelCNN 的基本计算流程:
- 输入图像:将图像转化为像素矩阵。
- 掩码卷积:应用掩码卷积,确保生成每个像素时只依赖于之前的像素。
- 卷积层:通过多层掩码卷积层处理图像像素,生成每个像素的条件概率分布。
- 输出层:从条件概率分布中采样,生成像素值。
- 生成图像:逐个像素生成图像,直到生成完整图像。
优缺点
优点:
- 并行化处理:与 PixelRNN 不同,PixelCNN 使用卷积操作,可以在训练过程中并行化处理,提高计算效率。
- 局部依赖:掩码卷积能够有效捕捉图像中的局部依赖关系,适合处理图像数据。
- 生成质量高:能够生成高质量的图像,特别适用于具有复杂结构的图像生成任务。
缺点:
- 生成过程慢:尽管训练过程可以并行化,但生成过程中仍需逐像素生成,速度较慢。
- 局部依赖限制:尽管能捕捉局部依赖关系,但对于长距离依赖关系的建模效果不如 PixelRNN。
用途
PixelCNN 主要用于以下几个领域:
- 图像生成:生成高质量的图像,应用于图像生成、图像修复等任务。
- 图像超分辨率:通过生成高分辨率的图像细节,用于图像超分辨率任务。
- 图像补全:用于图像中缺失部分的补全,通过生成模型填补缺失像素。
- 数据增强:通过生成新图像样本,扩展训练数据集,提升模型的泛化能力。
结论
PixelCNN 是一种强大的图像生成模型,通过逐像素建模图像的条件概率分布,能够生成高质量的图像。虽然生成过程速度较慢,但其训练过程中并行化处理的特性使其在处理大规模图像数据时具有优势。PixelCNN 在图像生成、图像超分辨率和图像补全等任务中表现出色。
6.3 Variational Autoencoders (VAE)
变分自编码器(Variational Autoencoders, VAE) 是一种生成模型,通过引入隐变量来建模数据的生成过程。VAE 结合了概率图模型和深度学习的优势,能够生成高质量的样本。其基本思想是学习一个潜在空间(latent space),使得从该空间中采样的点可以通过解码器生成类似于训练数据的样本。
VAE 的基本架构
VAE 的架构包括两个主要部分:
- 编码器(Encoder):将输入数据 ( x ) 编码为潜在变量 z 的分布参数(如均值和方差)。
- 解码器(Decoder) :将潜在变量 ( z ) 解码为重构数据 x ^ \hat{x} x^。
在 VAE 中,编码器和解码器通常由神经网络实现。
如何训练 VAE 模型
VAE 的训练目标是最大化数据的边际似然 p(x) 。由于直接计算和优化边际似然通常是不可行的,VAE 使用变分推断方法,通过最大化变分下界(Evidence Lower Bound, ELBO)来进行训练。
具体步骤如下:
-
定义潜在变量的先验分布 :通常选择标准正态分布 p ( z ) = N ( 0 , I ) p(z) = \mathcal{N}(0, I) p(z)=N(0,I)。
-
编码器(推断模型) :将输入数据 x 映射到潜在变量 z 的后验分布 q ( z ∣ x ) q(z|x) q(z∣x),通常假设这个分布是一个高斯分布 q ( z ∣ x ) = N ( μ ( x ) , σ 2 ( x ) ) q(z|x) = \mathcal{N}(\mu(x), \sigma^2(x)) q(z∣x)=N(μ(x),σ2(x)),其中 μ ( x ) \mu(x) μ(x) 和 σ ( x ) \sigma(x) σ(x) 由编码器神经网络输出。
-
采样潜在变量 :从后验分布 q ( z ∣ x ) q(z|x) q(z∣x)采样 z 。为了使采样过程可微分,使用 reparameterization trick,将采样过程表示为 z = μ ( x ) + σ ( x ) ⋅ ϵ z = \mu(x) + \sigma(x) \cdot \epsilon z=μ(x)+σ(x)⋅ϵ,其中 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)。
-
解码器 :将采样得到的 ( z ) 解码为重构数据 x ^ \hat{x} x^,即 p ( x ∣ z ) p(x|z) p(x∣z)。
-
优化目标 :最大化变分下界(ELBO),其定义为:
L ( x ) = E q ( z ∣ x ) log p ( x ∣ z ) − D KL ( q ( z ∣ x ) ∥ p ( z ) ) \mathcal{L}(x) = \mathbb{E}{q(z|x)}\left\\log p(x\|z)\\right - D{\text{KL}}\left(q(z|x) \| p(z)\right) L(x)=Eq(z∣x)logp(x∣z)−DKL(q(z∣x)∥p(z))其中,第一项是重构误差,衡量生成数据 x ^ \hat{x} x^ 与输入数据 x 之间的相似性;第二项是 Kullback-Leibler 散度,衡量近似后验分布 q ( z ∣ x ) q(z|x) q(z∣x) 与先验分布 p(z) 之间的差异。
优缺点
优点:
- 生成质量高:VAE 能够生成高质量的样本,特别是对于具有复杂结构的数据。
- 潜在空间的连续性:VAE 学习到的潜在空间是连续的,从而可以在潜在空间中插值生成新的样本。
- 概率解释:VAE 提供了一种概率解释,能够明确建模数据的生成过程。
缺点:
- 生成样本的多样性有限:由于重构误差和 KL 散度之间的权衡,VAE 生成样本的多样性可能受到限制。
- 训练复杂度高:模型需要同时优化两个分布(编码器和解码器),训练过程较为复杂。
- 计算复杂度:尽管 VAE 有效,但在处理高维数据时计算复杂度较高。
6.4 Generative Adversarial Networks (GANs)
生成对抗网络(Generative Adversarial Network, GAN) 是一种生成模型,由 Ian Goodfellow 等人在 2014 年提出。GAN 通过两个神经网络------生成器(Generator)和判别器(Discriminator)------之间的对抗性训练,来生成以假乱真的数据。其基本思想是让生成器学习生成看起来与真实数据非常相似的样本,而判别器则学习区分生成样本和真实样本。
GAN 的基本架构
GAN 的架构包括两个主要部分:
- 生成器(Generator, G):生成器接收一个随机噪声向量 ( z )(通常从标准正态分布中采样),并将其映射到数据空间,生成假样本 G(z) 。
- 判别器(Discriminator, D):判别器接收一个样本(可以是真实样本 ( x ) 或生成样本 G(z) 并输出一个标量值,表示该样本为真实样本的概率。
如何训练 GAN 模型
GAN 的训练目标是通过对抗性训练,使生成器生成的样本无法被判别器区分开来。具体训练过程如下:
-
初始化生成器和判别器的参数。
-
训练判别器:
- 从真实数据分布中采样一批真实样本 ( x )。
- 从噪声分布中采样一批随机噪声向量 ( z ),并通过生成器生成假样本 G(z)。
- 计算判别器对真实样本的输出 D(x) 和对假样本的输出 D(G(z)) 。
- 最大化判别器的损失函数:
L D = E x ∼ p data ( x ) log D ( x ) + E z ∼ p z ( z ) log ( 1 − D ( G ( z ) ) ) \mathcal{L}D = \mathbb{E}{x \sim p_{\text{data}}(x)}\\log D(x) + \mathbb{E}_{z \sim p_z(z)}\\log (1 - D(G(z))) LD=Ex∼pdata(x)logD(x)+Ez∼pz(z)log(1−D(G(z)))
-
训练生成器:
- 从噪声分布中采样一批随机噪声向量 z ,并通过生成器生成假样本 G(z) 。
- 计算判别器对假样本的输出 D(G(z)) 。
- 最小化生成器的损失函数(即最大化判别器对假样本判断错误的概率):
L G = E z ∼ p z ( z ) log ( 1 − D ( G ( z ) ) ) \mathcal{L}G = \mathbb{E}{z \sim p_z(z)}\\log (1 - D(G(z))) LG=Ez∼pz(z)log(1−D(G(z))) - 实际训练中,通常使用损失函数 L G = − E z ∼ p z ( z ) log D ( G ( z ) ) \mathcal{L}G = -\mathbb{E}{z \sim p_z(z)}\\log D(G(z)) LG=−Ez∼pz(z)logD(G(z)) 以避免梯度消失问题。
-
交替更新生成器和判别器的参数,直到达到平衡。
优缺点
优点:
- 生成样本质量高:GAN 能够生成非常逼真的样本,特别是在图像生成任务中表现出色。
- 无监督学习:GAN 不需要标注数据,适合无监督学习任务。
- 灵活性高:可以适用于多种数据类型,包括图像、文本和音频等。
缺点:
- 训练不稳定:GAN 的训练过程非常不稳定,需要仔细选择模型架构和超参数。
- 模式崩溃(Mode Collapse):生成器可能会陷入只生成少量模式的情况,导致生成样本的多样性不足。
- 难以评估:评估生成样本的质量是一个复杂的问题,缺乏统一的评估标准。
第七章 生成模型(diffusion and probabilistic graph models)
7.1 Diffusion Model
Diffusion Model 是一种生成模型,通过模拟数据的逐步去噪过程生成高质量样本。基本思想是将数据逐步添加噪声,直到变成纯噪声,然后训练一个反向过程模型来逐步去噪,恢复原始数据。这个过程可以视为一个马尔可夫链,其中每一步都模拟数据的微小变化。
Diffusion Model 的基本架构
Diffusion Model 主要由两个过程组成:
- 正向过程(Forward Process):将数据逐步添加噪声,直到变成纯噪声。
- 反向过程(Reverse Process):从纯噪声开始,逐步去除噪声,生成数据。
正向过程
正向过程将数据 x 0 x_0 x0 添加噪声,生成一系列逐步增加噪声的样本 x 1 , x 2 , ... , x T x_1, x_2, \ldots, x_T x1,x2,...,xT,其中 T 是步骤数。每一步的噪声添加可以表示为:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) q(xt∣xt−1)=N(xt;1−βt xt−1,βtI)
其中, β t \beta_t βt 是预定义的噪声调度参数。
反向过程
反向过程从纯噪声开始,逐步去除噪声,生成数据。反向过程的目标是学习每一步去噪的条件概率分布:
p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1} | x_t) pθ(xt−1∣xt)
其中, θ \theta θ 是模型参数。通常,反向过程由一个神经网络模型实现。
如何训练 Diffusion Model
训练 Diffusion Model 的目标是最大化数据的边际似然 p ( x 0 ) p(x_0) p(x0)。由于直接计算和优化边际似然是不可行的,通常通过变分推断方法,最大化变分下界(Evidence Lower Bound, ELBO)来进行训练。
具体步骤如下:
-
定义正向过程 :预定义噪声调度参数 β t \beta_t βt 并确定正向过程的转移概率 q ( x t ∣ x t − 1 ) q(x_t | x_{t-1}) q(xt∣xt−1)。
-
采样数据和噪声 :从数据分布中采样一个数据样本 x 0 x_0 x0,并从标准正态分布中采样噪声 ϵ \epsilon ϵ。
-
计算损失函数 :利用已知的正向过程计算损失函数,通常使用重构误差和 KL 散度的组合来表示:
L ( θ ) = ∑ t = 1 T E q D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) \mathcal{L}(\theta) = \sum_{t=1}^T \mathbb{E}_{q}\left D_{\\text{KL}}(q(x_{t-1} \| x_t, x_0) \\\| p_\\theta(x_{t-1} \| x_t)) \\right L(θ)=t=1∑TEqDKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt)) -
优化模型参数 :通过反向传播和梯度下降算法,优化反向过程模型的参数 θ \theta θ。
优缺点
优点:
- 生成质量高:Diffusion Model 能够生成高质量的样本,特别适用于图像生成任务。
- 稳定性好:相比于 GAN,Diffusion Model 的训练过程更加稳定,避免了模式崩溃等问题。
- 灵活性强:可以适用于多种数据类型,包括图像、文本和音频等。
缺点:
- 计算复杂度高:Diffusion Model 的训练和生成过程中涉及大量计算,尤其在高维数据上,计算复杂度较高。
- 生成速度慢:由于逐步去噪过程需要多次迭代,生成速度较慢。
用途
Diffusion Model 主要用于以下几个领域:
- 图像生成:生成高质量图像,应用于图像生成、图像修复、图像超分辨率等任务。
- 数据增强:生成新样本扩展训练数据集,提高模型的泛化能力。
- 图像补全(Image Inpainting):填补图像中的缺失部分。
- 文本生成:生成自然语言文本,应用于对话系统、文本生成等任务。
- 音频生成:生成高质量音频样本,应用于语音合成、音乐生成等领域。
7.2 Probabilistic Graphical Models (PGMs)
概率图模型(Probabilistic Graphical Models, PGMs) 是一种用于表示随机变量及其条件依赖关系的框架。PGMs 结合了概率论和图论,利用图结构来表示变量之间的依赖关系,通过图形化的方式简化了复杂概率分布的建模与推断。
PGMs 主要分为两类:
- 贝叶斯网络(Bayesian Network, BN):使用有向无环图(Directed Acyclic Graph, DAG)表示变量的条件依赖关系。
- 马尔可夫随机场(Markov Random Field, MRF):使用无向图表示变量之间的对称依赖关系。
PGM 的基本架构
(1) 贝叶斯网络
贝叶斯网络由节点和有向边构成:
- 节点:表示随机变量。
- 有向边:表示变量之间的条件依赖关系。
每个节点 X i X_i Xi 都有一个条件概率分布 P ( X i ∣ Parents ( X i ) ) P(X_i | \text{Parents}(X_i)) P(Xi∣Parents(Xi)),其中 Parents ( X i ) \text{Parents}(X_i) Parents(Xi) 表示节点 X i X_i Xi 的父节点集合。整个网络的联合概率分布可以分解为:
P ( X 1 , X 2 , ... , X n ) = ∏ i = 1 n P ( X i ∣ Parents ( X i ) ) P(X_1, X_2, \ldots, X_n) = \prod_{i=1}^n P(X_i | \text{Parents}(X_i)) P(X1,X2,...,Xn)=i=1∏nP(Xi∣Parents(Xi))
(2) 马尔可夫随机场
马尔可夫随机场由节点和无向边构成:
- 节点:表示随机变量。
- 无向边:表示变量之间的对称依赖关系。
马尔可夫随机场的联合概率分布可以表示为一组势函数(potential functions)的乘积:
P ( X 1 , X 2 , ... , X n ) = 1 Z ∏ C ∈ C ϕ C ( X C ) P(X_1, X_2, \ldots, X_n) = \frac{1}{Z} \prod_{C \in \mathcal{C}} \phi_C(X_C) P(X1,X2,...,Xn)=Z1C∈C∏ϕC(XC)
其中, C \mathcal{C} C 是图的团(clique)集合, ϕ C \phi_C ϕC 是团 C C C 的势函数,Z 是归一化常数。
如何训练 PGM 模型
训练 PGM 模型的目标是从数据中学习模型参数和结构。主要有以下几种方法:
-
参数学习:
- 最大似然估计(Maximum Likelihood Estimation, MLE):通过最大化训练数据的似然函数,估计模型参数。
- 贝叶斯估计(Bayesian Estimation):通过引入先验分布,结合数据进行参数估计。
-
结构学习:
- 贪心搜索(Greedy Search):通过添加、删除或反转边来优化模型结构,通常使用评分函数(如 BIC、AIC)进行评估。
- 约束算法(Constraint-Based Methods):通过条件独立性测试来确定模型结构。
-
推断:
- 精确推断:如变量消除(Variable Elimination)、信念传播(Belief Propagation)。
- 近似推断:如马尔可夫链蒙特卡罗(MCMC)、变分推断(Variational Inference)。
优缺点
优点:
- 直观性:通过图结构直观地表示变量之间的依赖关系。
- 灵活性:适用于各种类型的概率分布和数据结构。
- 模块化:可以模块化地构建和理解复杂的概率模型。
- 有效推断:提供了多种精确和近似推断方法。
缺点:
- 计算复杂度高:对大规模、高维数据进行推断和学习时计算复杂度较高。
- 结构学习复杂:结构学习问题一般是 NP 难问题,特别是对于大型网络。
- 数据需求大:需要大量数据才能准确估计模型参数和结构。
用途
PGMs 主要用于以下几个领域:
- 自然语言处理(NLP):如隐马尔可夫模型(HMM)用于词性标注、命名实体识别等任务。
- 计算生物学:如基因网络建模、蛋白质结构预测等。
- 计算机视觉:如图像分割、目标识别等任务中的马尔可夫随机场应用。
7.3 RBM【受限玻尔兹曼机】
受限玻尔兹曼机(Restricted Boltzmann Machine, RBM) 是一种能量基模型,属于概率图模型的一种。RBM 由 Geoffrey Hinton 提出,主要用于特征学习、降维和生成模型。RBM 的基本结构包括一个可见层(visible layer)和一个隐藏层(hidden layer),这两层之间的连接是对称的、无向的权重,没有层内连接。
7.3.1 结构
- 可见层(Visible Layer):表示输入数据,包含 ( v ) 个节点。
- 隐藏层(Hidden Layer):用于捕捉输入数据中的特征,包含 ( h ) 个节点。
- 权重矩阵(Weight Matrix, W ) :连接可见层和隐藏层的权重,维度为 v × h v \times h v×h。
RBM 的能量函数定义为:
E ( v , h ) = − ∑ i ∑ j v i w i j h j − ∑ i b i v i − ∑ j c j h j E(v, h) = - \sum_i \sum_j v_i w_{ij} h_j - \sum_i b_i v_i - \sum_j c_j h_j E(v,h)=−i∑j∑viwijhj−i∑bivi−j∑cjhj
其中, v i v_i vi 和 h j h_j hj 分别是可见层和隐藏层的节点, w i j w_{ij} wij 是连接权重, b i b_i bi 和 c j c_j cj 分别是可见层和隐藏层的偏置。
7.3.2 训练 RBM
训练 RBM 的目标是最大化数据的对数似然,通过最小化能量函数来优化模型参数。常用的训练算法是对比散度(Contrastive Divergence, CD),其步骤如下:
- 初始化参数
随机初始化权重矩阵 ( W ) 和偏置向量 ( b )、( c )。 - 正向传播
给定输入数据 ( v ),计算隐藏层节点的激活概率:
p ( h j = 1 ∣ v ) = σ ( ∑ i v i w i j + c j ) p(h_j = 1 | v) = \sigma \left( \sum_i v_i w_{ij} + c_j \right) p(hj=1∣v)=σ(i∑viwij+cj)
其中, σ \sigma σ 是 sigmoid 激活函数。 - 采样
根据激活概率对隐藏层节点进行采样,得到二值化的隐藏层状态 ( h )。 - 反向传播
使用隐藏层状态重新生成可见层节点:
p ( v i = 1 ∣ h ) = σ ( ∑ j h j w i j + b i ) p(v_i = 1 | h) = \sigma \left( \sum_j h_j w_{ij} + b_i \right) p(vi=1∣h)=σ(j∑hjwij+bi)
并根据此概率对可见层节点进行采样,得到重建的可见层状态 v ′ v' v′。 - 更新权重
根据以下梯度更新规则调整权重和偏置:
Δ w i j = η ( ⟨ v i h j ⟩ data − ⟨ v i h j ⟩ recon ) Δ b i = η ( ⟨ v i ⟩ data − ⟨ v i ⟩ recon ) Δ c j = η ( ⟨ h j ⟩ data − ⟨ h j ⟩ recon ) \Delta w_{ij} = \eta (\langle v_i h_j \rangle_{\text{data}} - \langle v_i h_j \rangle_{\text{recon}})\\ \;\\ \Delta b_i = \eta (\langle v_i \rangle_{\text{data}} - \langle v_i \rangle_{\text{recon}})\\ \;\\ \Delta c_j = \eta (\langle h_j \rangle_{\text{data}} - \langle h_j \rangle_{\text{recon}}) Δwij=η(⟨vihj⟩data−⟨vihj⟩recon)Δbi=η(⟨vi⟩data−⟨vi⟩recon)Δcj=η(⟨hj⟩data−⟨hj⟩recon)
其中, η \eta η 是学习率, ⟨ ⋅ ⟩ data \langle \cdot \rangle_{\text{data}} ⟨⋅⟩data表示数据期望, ⟨ ⋅ ⟩ recon \langle \cdot \rangle_{\text{recon}} ⟨⋅⟩recon 表示重建期望。 - 重复迭代
重复上述步骤,直到模型收敛或达到预设的迭代次数。
7.3.3 优缺点
优点:
- 特征学习能力强:RBM 能够有效捕捉输入数据的高阶特征,特别适用于无监督学习任务。
- 适用于多种数据类型:可以处理二值数据、实值数据(通过修改能量函数)等。
- 可堆叠:RBM 可以堆叠成深度信念网络(Deep Belief Network, DBN),用于更复杂的特征学习和生成任务。
缺点:
- 训练复杂度高:RBM 的训练涉及多次采样和更新,计算复杂度较高。
- 对超参数敏感:训练效果对学习率、权重初始化等超参数较为敏感,需仔细调参。
- 难以扩展:虽然 RBM 适用于中小规模数据,但在处理大规模数据时效果有限。
7.3.4 用途
RBM 在许多领域都有广泛的应用,以下是一些主要的应用场景:
- 特征学习与降维
RBM 可以用于从高维数据中提取有用的特征,常用于图像、音频等数据的降维。在图像处理中,RBM 可以学习到图像的潜在特征,如边缘、纹理等。 - 推荐系统
RBM 在推荐系统中被广泛应用,尤其是在协同过滤算法中。通过学习用户和物品的潜在特征,RBM 可以预测用户对未评分物品的偏好,从而实现个性化推荐。 - 图像生成
RBM 可以用于生成新图像。通过训练一个 RBM 模型,可以从模型中采样生成与训练数据分布相似的新图像。这在图像修复、图像生成等任务中有重要应用。 - 深度信念网络 (DBN)
RBM 是深度信念网络 (Deep Belief Network, DBN) 的基本构建模块。多个 RBM 堆叠在一起可以形成一个 DBN,通过逐层预训练和微调,DBN 能够在无监督和半监督学习中表现出色。 - 自然语言处理 (NLP)
在 NLP 任务中,RBM 可以用于词嵌入 (word embedding) 和文本生成。通过学习词语的潜在表示,RBM 能够捕捉词语之间的语义关系,应用于情感分析、文本分类等任务。
7.3.5 训练细节与优化技巧
- 对比散度 (Contrastive Divergence, CD)
最常用的训练算法是对比散度 (Contrastive Divergence, CD) 算法。CD 算法通过近似的方式计算梯度,显著加速了训练过程。常见的 CD-k 算法会进行 k 次 Gibbs 采样来近似重建数据。 - 参数初始化
权重和偏置的初始化对训练效果影响很大。通常,权重 (W) 会以小的随机值初始化,偏置 (b) 和 (c) 可以初始化为零或小的随机值。 - 学习率调整
合理的学习率是成功训练 RBM 的关键。学习率过大会导致训练不稳定,学习率过小则收敛缓慢。可以使用学习率衰减策略,根据训练进度逐步减小学习率。 - 正则化
为了防止过拟合,可以在训练过程中加入正则化项,如 L2 正则化。正则化项会对权重 (W) 进行约束,使其不会过大。 - 批量训练
使用小批量梯度下降 (Mini-Batch Gradient Descent) 可以提高训练速度和稳定性。每次更新参数时,使用一批数据而不是单个数据样本进行梯度计算。
7.3.6 总结
受限玻尔兹曼机 (RBM) 是一种强大的概率图模型,能够有效学习数据的潜在特征,并应用于多种任务。尽管训练复杂度较高,但通过合理的优化技巧和算法改进,RBM 在特征学习、推荐系统、图像处理、自然语言处理等领域展现出了巨大的潜力和应用价值。
7.4 深度学习
深度学习(Deep Learning)是机器学习的一个分支,基于多层神经网络结构来自动学习数据的表示和特征。与传统机器学习方法相比,深度学习能够从原始数据中自动提取高层次特征,减少了对特征工程的依赖。
7.4.1 基本概念
- 神经网络:深度学习的核心结构,包括输入层、隐藏层和输出层。每层由多个神经元(节点)组成,神经元之间通过权重连接。
- 激活函数:引入非线性,使神经网络能够拟合复杂函数。常用的激活函数有 ReLU、Sigmoid、Tanh 等。
- 前向传播:输入数据通过网络层层传递,最终得到输出。
- 反向传播:根据输出误差,通过链式法则计算梯度,调整网络权重,以最小化损失函数。
7.4.2 模型
- 前馈神经网络 (Feedforward Neural Network, FNN)
最基本的神经网络结构,数据从输入层经过若干隐藏层传递到输出层,信息单向流动。适用于分类、回归等任务。 - 卷积神经网络 (Convolutional Neural Network, CNN)
专为处理图像数据设计,通过卷积层、池化层提取局部特征,保留空间结构信息。广泛应用于图像分类、目标检测、图像分割等任务。 - 循环神经网络 (Recurrent Neural Network, RNN)
处理序列数据的模型,具有记忆功能,能够捕捉时间序列中的依赖关系。常用于自然语言处理、时间序列预测等。LSTM 和 GRU 是两种常见的改进型 RNN。 - 自编码器 (Autoencoder)
一种无监督学习模型,通过压缩和重建输入数据进行特征学习,常用于降维、去噪等任务。变分自编码器(VAE)是其一种生成模型变体。 - 生成对抗网络 (Generative Adversarial Network, GAN)
由生成器和判别器组成,生成器生成假数据,判别器区分真伪,通过对抗训练提高生成数据的质量。广泛用于图像生成、风格迁移等任务。 - 变分自编码器 (Variational Autoencoder, VAE)
一种生成模型,通过学习数据的潜在分布生成新数据。相比传统自编码器,VAE 引入了概率模型,更适合生成任务。 - Transformer
一种基于注意力机制的模型,能够并行处理序列数据,克服了 RNN 的长距离依赖问题。广泛应用于自然语言处理,特别是机器翻译、文本生成等任务。
7.4.3 工作原理
- 数据准备
数据预处理、归一化、数据增强等步骤,确保数据适合模型训练。 - 模型构建
根据任务选择合适的网络结构,设置超参数(如学习率、批量大小、层数等)。 - 前向传播
输入数据通过各层网络计算,得到输出。每层通过激活函数引入非线性。 - 损失计算
根据输出与真实标签计算损失函数(如交叉熵、均方误差等),衡量模型预测误差。 - 反向传播
通过链式法则计算损失函数对各层权重的梯度,调整权重以最小化损失。 - 模型评估
使用验证集评估模型性能,调整超参数以提高模型泛化能力。 - 模型部署
训练好的模型应用于实际任务,如预测、分类、生成等。
7.4.4 优缺点
优点:
- 自动特征学习:无需人工设计特征,能够自动从数据中提取高层次特征。
- 处理复杂任务:在图像、语音、自然语言处理等领域表现优异。
- 高效计算:利用 GPU 并行计算,大大提升训练速度。
缺点:
- 数据需求量大:需要大量标注数据进行训练,数据获取成本高。
- 计算资源需求高:训练深度模型需要大量计算资源,尤其是 GPU。
- 难以解释:黑箱模型,难以解释内部机制和决策过程。
- 超参数调优复杂:模型的性能依赖于多个超参数(如学习率、层数、神经元数量等),需要大量实验和经验进行调参。
- 容易过拟合:特别是在数据量不足或数据噪声较大时,深度模型容易过拟合,需要采用正则化、数据增强等技术来缓解。
7.4.5 用途
深度学习在各个领域都有广泛的应用,以下是一些主要的应用场景:
(1)计算机视觉
- 图像分类:使用 CNN 对图像进行分类,如手写数字识别、对象分类等。
- 目标检测:检测并定位图像中的目标,如自动驾驶中的行人检测。
- 图像分割:将图像分割成有意义的区域,如医学图像中的肿瘤分割。
- 图像生成:使用 GAN 生成逼真的图像,如人脸生成、图像修复等。
(2)自然语言处理 (NLP)
- 文本分类:对文本进行分类,如垃圾邮件检测、情感分析等。
- 机器翻译:使用 Transformer 模型进行语言翻译,如英语到法语。
- 文本生成:生成自然语言文本,如对话系统、文章生成等。
- 语音识别:将语音转换为文本,如语音助手中的语音输入。
(3)语音处理
- 语音识别:将语音转换为文本,如语音转写、语音命令识别。
- 语音合成:将文本转换为语音,如语音助手中的语音输出。
- 语音分离:从混合语音中分离出单个声源,如会议记录中的多声道分离。
(4)推荐系统
- 个性化推荐:根据用户历史行为推荐商品、电影、音乐等,如电商平台的商品推荐。
- 协同过滤:根据相似用户或相似物品进行推荐,如 Netflix 的电影推荐。
(5)医疗诊断
- 医学影像分析:通过分析医学图像(如 X 光片、CT 扫描)辅助诊断疾病。
- 基因分析:利用深度学习处理基因序列数据,预测基因突变和疾病风险。
(6)金融预测
- 股票价格预测:使用时间序列数据预测股票价格走势。
- 信用评分:通过分析用户金融行为数据进行信用评分。
(7)自动驾驶
- 环境感知:使用摄像头、激光雷达等传感器数据进行环境感知,如车道检测、障碍物识别。
- 决策控制:基于感知信息进行驾驶决策和控制,如路径规划、自动刹车。
7.4.6 总结
深度学习通过多层神经网络结构,自动学习数据的表示和特征,在计算机视觉、自然语言处理、语音处理、推荐系统、医疗诊断、金融预测、自动驾驶等领域展现了强大的应用潜力。尽管面临数据需求量大、计算资源高、难以解释等挑战,但其自动特征学习和处理复杂任务的能力,使其成为现代人工智能技术的重要组成部分。未来,随着算法优化、硬件进步和数据获取技术的发展,深度学习将继续推动各行业的智能化变革。
7.5 Greedy Training【贪心训练】
贪心训练(Greedy Training)是一种逐层训练深度神经网络的策略,特别适用于深层网络,如深度信念网络(Deep Belief Networks, DBNs)和堆叠自动编码器(Stacked Autoencoders)。该方法通过逐层预训练每一层网络,然后进行全局微调,从而使训练过程更加稳定和高效。
7.5.1 方案步骤
- 逐层预训练 :
- 第一层 :
- 将原始输入数据输入到第一层(如受限玻尔兹曼机(RBM)或自动编码器(Autoencoder))。
- 训练第一层,使其学到输入数据的特征。
- 将第一层的输出作为特征表示。
- 第二层及后续层 :
- 将上一层的输出作为当前层的输入。
- 训练当前层,使其学到上一层输出的特征。
- 重复这一过程,直到所有层都被预训练。
- 第一层 :
- 固定已训练层 :
- 每完成一层的预训练后,固定该层的参数,不再更新。
- 继续训练下一层时,以前一层的输出作为输入。
- 整体微调 :
- 所有层预训练完成后,将整个网络连接起来,形成完整的深度神经网络。
- 使用反向传播算法对整个网络进行微调(Fine-Tuning),调整所有层的参数以最小化全局损失函数。
7.5.2 具体实现
以下是贪心训练在堆叠自动编码器中的具体实现步骤:
- 训练第一个自动编码器 :
- 输入数据 ( X )。
- 训练第一个自动编码器,使其学到输入数据 ( X ) 的特征表示 H 1 H_1 H1。
- H 1 = f 1 ( W 1 X + b 1 ) H_1 = f_1(W_1 X + b_1) H1=f1(W1X+b1)。
- 训练第二个自动编码器 :
- 将 H 1 H_1 H1 作为输入数据,训练第二个自动编码器。
- 学到 H 1 H_1 H1 的特征表示 H 2 H_2 H2。
- H 2 = f 2 ( W 2 H 1 + b 2 ) H_2 = f_2(W_2 H_1 + b_2) H2=f2(W2H1+b2)。
- 重复以上步骤,直到所有自动编码器都被训练。
- 整体微调 :
- 将所有训练好的层连接起来,形成完整的堆叠自动编码器。
- 使用反向传播算法对整个网络进行微调,调整所有层的参数 ( W ) 和 ( b ),以最小化全局重建误差。
7.5.3 为什么Greedy Training可以生效
贪心训练之所以能够生效,主要是因为以下几个原因:
- 缓解梯度消失问题 :
- 在深度神经网络中,梯度消失问题使得训练过程变得困难。逐层预训练可以有效缓解这一问题,因为每一层的训练都是在一个较浅的网络上进行的,梯度传播更为稳定。
- 逐层优化特征表示 :
- 每一层的预训练使得网络能够逐步学到数据的更高层次特征表示。这种逐层优化的过程有助于提升网络的表示能力,使得最终的全局微调更为有效。
- 更好的参数初始化 :
- 每一层的预训练相当于为后续层提供了一个良好的参数初始化。相比于随机初始化,逐层预训练提供的初始化参数更加接近于最终的最优解,从而加速了训练过程。
- 降低训练难度 :
- 深度网络的端到端训练往往需要大量计算资源和时间。通过逐层预训练,每次只需训练一个较浅的子网络,降低了训练难度和计算开销。
- 局部最优解的进化 :
- 逐层训练过程中,每一层都会找到一个局部最优解,这些局部最优解逐步累积,有助于最终找到一个较好的全局最优解。尽管可能仍会陷入局部最优,但整体效果往往优于随机初始化的端到端训练。
7.5.4 总结
贪心训练通过逐层预训练和全局微调,使得深度神经网络的训练过程更加稳定、高效,并且能够缓解梯度消失问题,提供更好的参数初始化。这种方法在处理深层网络时表现出色,特别是在数据量有限或计算资源
第八章 提示工程和学习(Prompt Engineering and Learning)
8.1 主要内容
1. 语言模型的"规模战争"
- GPT-4 和 GPT-4o:1.76万亿参数
- ELMo:9300万参数,2层双向LSTM
- BERT-base:1.1亿参数,12层Transformer
- BERT-large:3.4亿参数,24层Transformer
- PaLM(Google):5400亿参数,118层,训练数据7800亿个token
- ChatGPT(OpenAI):参数、层数、维度和训练数据量未知,仅通过黑箱API提供
- LLaMa(Meta):650亿参数,80层,训练数据1.4万亿个token,模型参数公开
- GPT-4(OpenAI):参数、层数、维度和训练数据量未知,仅通过黑箱API提供
- Bard(Google):参数、层数、维度和训练数据量未知,仅通过黑箱API提供
2. Prompting 方法分类
- 零样本 :无需微调,直接使用预训练语言模型,加上简单的提示前缀即可。

- 单样本 :无需微调,提供一个示例,通过提示前缀引导模型。

- 少样本 :无需微调,提供少量示例,通过提示前缀引导模型,最多可提供100个示例。

3. 新范式对比传统"预训练+微调"
讨论了Prompt Engineering的新范式与传统预训练和微调方法的对比,指出Prompt Engineering在某些任务中表现出色,特别是在翻译和问答任务中。
4. Chain-of-Thought (CoT) Prompting
- CoT Prompting:通过中间推理步骤实现复杂推理能力。
- 零样本CoT Prompting:在原始提示中添加"让我们一步一步思考"。
- 自动CoT(Auto-CoT) :包括问题聚类和示例选择两个阶段,通过简单启发式方法生成推理链。
1)问题聚类:将给定数据集的问题划分为几个聚类
2)演示采样:从每个聚类中选择一个有代表性的问题,并使用简单启发式的Zero-ShotCoT生成其推理链 - 自洽性方法(Self-Consistency) :通过采样生成多样化的推理路径,并选择最一致的答案。
自洽方法包括三个步骤:(1)使用思维链提示来提示语言模型;(2) 通过从语言模型的解码器中采样来替换CoT提示中的"贪婪解码",以生成一组不同的推理路径;以及(3)通过在最终答案集中选择最一致的答案来边缘化推理路径并进行聚合。
5. 生成知识提示(Generated Knowledge Prompting)
通过少量示例生成与问题相关的知识陈述,然后使用第二个语言模型根据知识陈述进行预测,并选择置信度最高的预测。
6. 思维树(Tree of Thoughts, ToT)
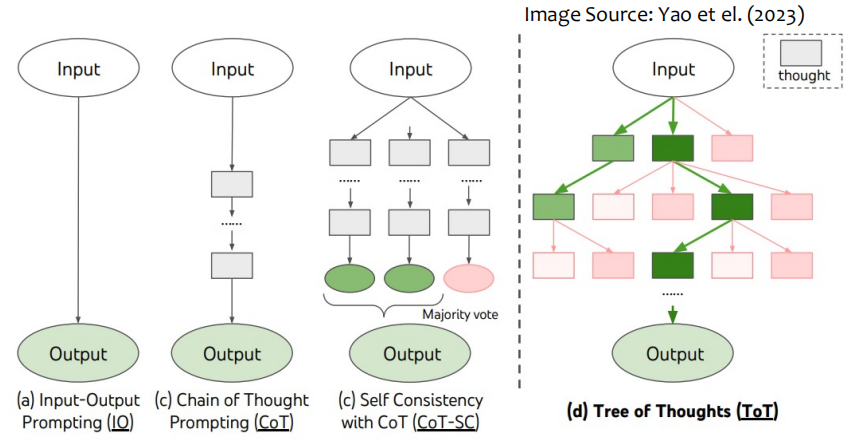
维护一个思维树,其中每个思维代表解决问题的中间步骤。
7. Prompt 学习的挑战和进展
-
大规模模型的挑战:成本高,难以共享和服务。
-
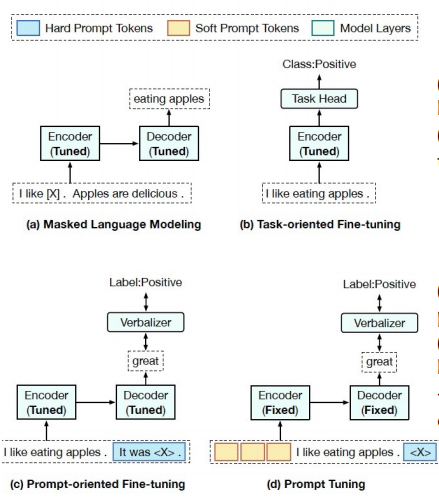
预训练提示微调(PPT) :用于少样本学习的预训练提示微调。
(a) 预训练的范式(掩蔽语言建模),
(b) 全模型调优:面向任务的微调
(c) 以提示为导向的微调)和提示调整。
(d) veralizer是一个将任务标签映射到具体单词的函数。 是指典型的预训练编码器-解码器模型的掩码.
-
前缀微调(Prefix Tuning):参数高效的提示微调方法,随着规模增加,提示微调变得更具竞争力。
结论
Prompt Engineering 和 Learning 是当前自然语言处理领域的重要研究方向,通过提示设计和优化,可以更高效地利用预训练语言模型执行各种任务。随着模型规模的增加和技术的进步,Prompt Engineering 将在实际应用中发挥越来越重要的作用。