端到端自动驾驶系列(一):自动驾驶综述解析

Abstract
Abstract---The autonomous driving community has witnessed a rapid growth in approaches that embrace an end-to-end algorithm framework, utilizing raw sensor input to generate vehicle motion plans, instead of concentrating on individual tasks such as detection and motion prediction. End-to-end systems, in comparison to modular pipelines, benefit from joint feature optimization for perception and planning. This field has flourished due to the availability of large-scale datasets, closed-loop evaluation, and the increasing need for autonomous driving algorithms to perform effectively in challenging scenarios. In this survey, we provide a comprehensive analysis of more than 270 papers, covering the motivation, roadmap, methodology, challenges, and future trends in end-to-end autonomous driving. We delve into several critical challenges, including multi-modality, interpretability, causal confusion, robustness, and world models, amongst others. Additionally, we discuss current advancements in foundation models and visual pre-training, as well as how to incorporate these techniques within the end-to-end driving framework. We maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/OpenDriveLab/End-to-end-Autonomous-Driving.
摘要:自动驾驶社区见证了采用端到端算法框架的方法的快速增长,这些方法利用原始传感器输入生成车辆运动计划,而不是专注于检测和运动预测等单个任务。与模块化管道相比,端到端系统受益于感知和规划的联合特征优化。由于大规模数据集的可用性、闭环评估以及对自动驾驶算法在具有挑战性的场景中有效执行的需求不断增加,该领域蓬勃发展。在本次调查中,我们对 270 多篇论文进行了全面分析,涵盖了端到端自动驾驶的动机、路线图、方法论、挑战和未来趋势。我们深入研究了几个关键挑战,包括多模态、可解释性、因果混乱、稳健性和世界模型等。此外,我们还讨论了基础模型和视觉预训练方面的当前进展,以及如何将这些技术整合到端到端驾驶框架中。我们在 https://github.com/OpenDriveLab/End-to-end-Autonomous-Driving维护着一个活跃的存储库,其中包含最新的文献和开源项目。
端到端算法框架 (end-to-end algorithm framework):这种方法指的是从输入(如传感器数据)直接输出(如车辆运动计划)的整个过程都由一个统一的算法处理,而不是将过程分成多个独立的步骤(如检测、跟踪、预测等)。
多模态 (multi-modality):这是指使用多种不同类型的数据或传感器输入(如视觉、雷达、激光雷达等)来提供全面的信息。
可解释性 (interpretability):这是指模型的结果或行为能够被人类理解和解释,尤其在自动驾驶中,这对于安全性和信任度至关重要。
因果混乱 (causal confusion):这是指在建模过程中混淆了因果关系,导致模型在预测时误解了变量之间的实际因果关系。
稳健性 (robustness):这是指算法在面对噪声、异常值或其他不可预见的情况时仍然能够表现良好。
世界模型 (world models):这些是用于模拟和预测环境变化的模型,帮助自动驾驶系统更好地理解和应对周围环境。
基础模型 (foundation models):这些是经过大规模训练、能够执行多种任务的模型,通常用作其他特定任务的基础。
视觉预训练 (visual pre-training):这是指在大量图像数据上预先训练模型,以便在特定视觉任务上获得更好的性能。
闭环评估 (closed-loop evaluation):这是指在评估算法时,将其输出重新反馈到系统中以模拟实际应用场景的过程。这种评估方式更接近于真实环境下的表现。
1 INTRODUCTION
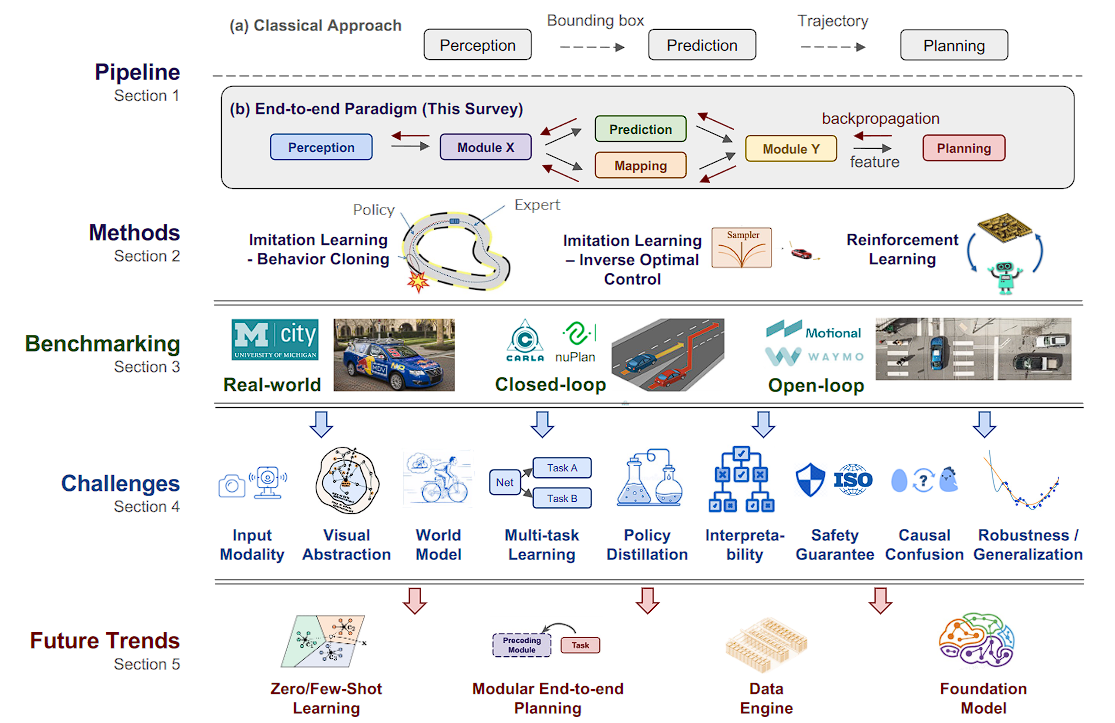
Fig. 1: Survey at A Glance. (a) Pipeline and Methods. We define end-to-end autonomous driving as a learning-based algorithm framework with raw sensor input and planning/control output. We deepdive into 270+ papers and categorize into imitation learning (IL) and reinforcement learning (RL). (b) Benchmarking. We group popular benchmarks into closed-loop and open-loop evaluation, respectively. We cover various aspects of closed-loop simulation and the limitations of open-loop evaluation for this problem. © Challenges. This is the main section of our work. We list key challenges from a wide range of topics and extensively analyze why these concerns are crucial. Promising resolutions to these challenges are covered as well. (e) Future Trends. We discuss how end-to-end paradigm could benefit by aid of the rapid development of foundation models, visual pre-training, etc. Partial photos by courtesy of online resources.
图 1:调查概览。 (a) 流程和方法。我们将端到端自动驾驶定义为一种基于学习的算法框架,具有原始传感器输入和规划/控制输出。我们深入研究了 270 多篇论文,并将其分为模仿学习 (IL) 和强化学习 (RL)。 (b) 基准测试。我们将流行的基准测试分别分为闭环和开环评估。我们涵盖了闭环仿真的各个方面以及该问题的开环评估的局限性。 © 挑战。这是我们工作的主要部分。我们列出了来自广泛主题的主要挑战,并广泛分析了为什么这些问题至关重要。还涵盖了应对这些挑战的有希望的解决方案。 (e) 未来趋势。我们讨论端到端范式如何受益于基础模型、视觉预训练等的快速发展。部分照片由在线资源提供。
Pipeline(管道)
- (a) Classical Approach(经典方法)
- 描述了传统自动驾驶系统的模块化方法,包括感知(Perception)、映射(Mapping)、预测(Prediction)、规划(Planning)、控制(Control)等阶段。每个阶段处理不同的任务,例如感知阶段负责解释传感器数据,规划阶段负责生成行驶路径等。
- (b) End-to-end Paradigm(端到端范式)
- 描述了端到端方法的架构,它通过直接从感知数据到控制决策的转换简化了流程。这种方法强调了模块间的信息反馈(例如,从规划到感知的特征反馈),以及通过模块X和Y的交互来优化性能。
Methods(方法)
- Imitation Learning - Behavior Cloning(模仿学习 - 行为克隆)
- 通过观察专家或优化的驾驶行为来学习驾驶策略。
- Imitation Learning - Inverse Optimal Control(模仿学习 - 逆向最优控制)
- 不仅模仿行为,还试图理解底层的目标和约束。
- Reinforcement Learning(强化学习)
- 通过与环境的交互,自我实验和从错误中学习,不断优化驾驶策略。
Benchmarking(基准测试)
- Real-world(现实世界)
- 在真实环境中测试和验证自动驾驶技术。
- Closed-loop(闭环)
- 在模拟环境中循环测试,以考察系统的反应和调整。
- Open-loop(开环)
- 在模拟环境中的单向测试,不考虑系统输出对输入数据的影响。
Challenges(挑战)
- Input Modality(输入模态)
- Visual Abstraction(视觉抽象)
- World Model(世界模型)
- Multi-task Learning(多任务学习)
- Policy Distillation(策略蒸馏)
- Interpretability(可解释性)
- Safety Guarantee(安全保证)
- Causal Confusion(因果混淆)
- Robustness / Generalization(鲁棒性/泛化)
Future Trends(未来趋势)
- Zero/Few-Shot Learning(零次/少次学习)
- Modular End-to-end Planning(模块化端到端规划)
- Foundation Model(基础模型)
1.1 Motivation of an End-to-end System 端到端系统的动机
In the classical pipeline, each model serves a standalone component and corresponds to a specific task (e.g., traffic light detection). Such a design is beneficial in terms of interpretability and ease of debugging. However, since the optimization objectives across modules are different, with detection pursuing mean average precision (mAP) while planning aiming for driving safety and comfort, the entire system may not be aligned with a unified target, i.e., the ultimate planning/control task. Errors from each module, as the sequential procedure proceeds, could be compounded and result in an information loss. Moreover, compared to one end-to-end neural network, the multi-task, multi-model deployment which involves multiple encoders and message transmission systems, may increase the computational burden and potentially lead to sub-optimal use of compute.
在经典管道中,每个模型都提供独立的组件并对应于特定的任务(例如交通灯检测)。这样的设计在可解释性和易于调试方面是有益的。然而,由于各个模块的优化目标不同,检测追求的是平均精度(mAP),而规划则以驾驶安全性和舒适性为目标,整个系统可能无法对准一个统一的目标,即最终的规划/控制任务。随着顺序过程的进行,每个模块的错误可能会加剧并导致信息丢失。此外,与一个端到端的神经网络相比,涉及多个编码器和消息传输系统的多任务、多模型部署可能会增加计算负担,并可能导致计算使用不理想。
In contrast to its classical counterpart, an end-to-end autonomous system offers several advantages. (a) The most apparent merit is its simplicity in combining perception, prediction, and planning into a single model that can be jointly trained. (b) The whole system, including its intermediate representations, is optimized towards the ultimate task. © Shared backbones increase computational efficiency. (d) Data-driven optimization has the potential to improve the system by simply scaling training resources.
与传统的对应系统相比,端到端自治系统具有多种优势。 (a) 最明显的优点是它简单地将感知、预测和规划结合到一个可以联合训练的模型中。 (b) 整个系统,包括其中间表示,针对最终任务进行了优化。 © 共享主干网提高了计算效率。 (d) 数据驱动的优化有可能通过简单地扩展培训资源来改进系统。
1.2 Roadmap 路线图
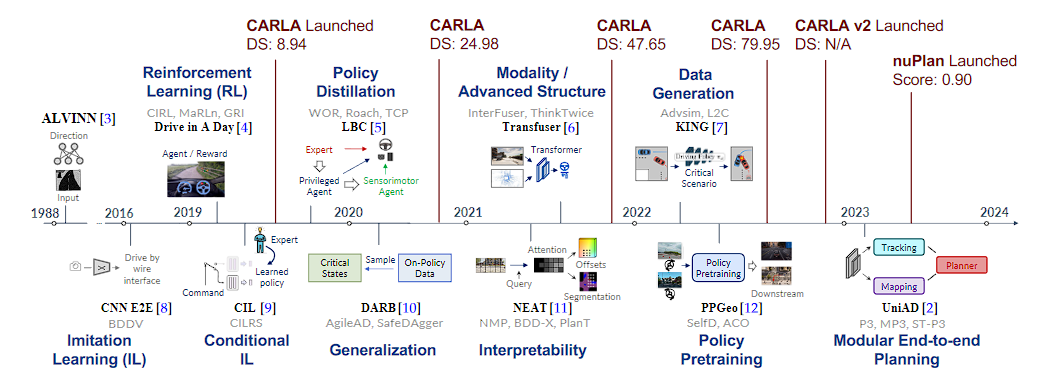
Fig. 2: Roadmap of End-to-end Autonomous Driving. We present the key milestones chronologically, grouping similar works under the same theme. The representative or first work is shown in bold with an illustration, while the date of the rest of the literature in the same theme may vary. We also display the score for each year's top entry in the CARLA leaderboard 13 (DS, ranging from 0 to 100) and the recent nuPlan challenge 14) (Score ranging from 0 to 1).
图2:端到端自动驾驶路线图。我们按时间顺序呈现关键里程碑,将类似的作品分组在同一主题下。代表性作品或第一部作品以粗体显示并配有插图,而同一主题的其余文献的日期可能有所不同。我们还显示了每年 CARLA 排行榜 13(DS,范围从 0 到 100)和最近的 nuPlan 挑战 14(分数范围从 0 到 1)中顶级条目的分数。
CARLA 用于自动驾驶研究的开源模拟器https://carla.org
Introduction:CARLA has been developed from the ground up to support development, training, and validation of autonomous driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely. The simulation platform supports flexible specification of sensor suites, environmental conditions, full control of all static and dynamic actors, maps generation and much more.
CARLA从头开始开发,以支持自动驾驶系统的开发、培训和验证。除了开源代码和协议之外,CARLA还提供了为此目的而创建的开放数字资产(城市布局、建筑物、车辆),这些资产可以自由使用。仿真平台支持传感器套件的灵活规格,环境条件,所有静态和动态演员的完全控制,地图生成等等。
驾驶评分 (Driving Score) :这是排行榜的主要指标,计算方法是路线完成度和违规惩罚的乘积。具体计算公式为 R i × P i R_i \times P_i Ri×Pi,其中 R i R_i Ri 是第 i i i 条路线的完成百分比, P i P_i Pi是第 i i i 条路线的违规惩罚。
路线完成度 (Route Completion):代理完成的路线距离百分比。
违规惩罚 (Infraction Penalty):基于代理触发的违规行为,所有违规行为以几何级数聚合。代理初始得分为1.0,每次违规都会减少得分。
其他违规行为:包括与行人碰撞、与其他车辆碰撞、闯红灯、越线行驶等,每种违规行为都有不同的惩罚系数。
Average driving proficiency score.This metric combines the average route completion percentage with the average infraction factor.Higher is better.
平均驾驶熟练度分数。该指标结合了平均路线完成百分比和平均违规系数。越高越好。
时间线部分
时间线从1988年到2024年,标记了端到端自动驾驶研究的重要年份和方法。
- 1988年
- ALVINN 3: 早期的自动驾驶研究,使用神经网络进行方向控制。输入是图像,输出是方向。
- 2016年
- 模仿学习 (IL)
- CNN E2E 8: 使用卷积神经网络(CNN)进行端到端的学习。
- BBDV: 基于模仿学习的驾驶。
- 模仿学习 (IL)
- 2019年
- 条件模仿学习 (Conditional IL)
- CIL 9: 基于条件的模仿学习。
- CILRS: 基于强化学习的条件模仿学习。
- 条件模仿学习 (Conditional IL)
- 2020年
- 强化学习 (RL) :
- CIRL, MaRLn, GRI: 不同的强化学习方法。
- Drive in a Day 4: 使用强化学习在一天内训练驾驶模型。
- 策略蒸馏 (Policy Distillation) :
- WOR, Roach, TCP: 不同的策略蒸馏方法。
- LBC 5: 学习基于专家数据的策略,图中展示了专家和传感器代理的关系。
- 通用化 (Generalization) :
- DARB 10: 自适应对抗模仿学习。
- AgileAD, SafeDagger: 不同的自适应对抗学习方法。
- 强化学习 (RL) :
- 2021年
- 模式/高级结构 (Modality/Advanced Structure)
- InterFuser, ThinkTwice, Transfer 6: 不同的多模态和高级结构方法。
- 使用了Transformer网络来处理输入数据。
- 模式/高级结构 (Modality/Advanced Structure)
- 2022年
- 数据生成 (Data Generation)
- Advsim, L2C, KING 7: 不同的数据生成方法。
- 生成关键场景来提升模型的训练效果。
- 数据生成 (Data Generation)
- 2023年
- 策略预训练 (Policy Pretraining)
- PPGeo 12: 基于地理信息的策略预训练。
- SelfD, ACO: 自我监督和对抗性预训练。
- 策略预训练 (Policy Pretraining)
- 2024年
- 模块化端到端规划 (Modular End-to-end Planning)
- UniAD 2: 统一的自动驾驶方法。
- P3, MP3, ST-P3: 不同的规划方法,整合了跟踪、映射和规划模块。
- 模块化端到端规划 (Modular End-to-end Planning)
上部数据
- CARLA Launched : 指的是自动驾驶模拟平台CARLA的发布,后续标记了不同版本的CARLA发布年份。
- DS (Difficulty Score): 表示不同年份的CARLA挑战赛的得分,从8.94到79.95不等。
- nuPlan Launched: 2024年发布的新计划模拟平台,得分为0.90。
下部注释
- 关键里程碑按时间顺序排列,并按相同主题分组。
- 图中的粗体字表示首次工作并配有插图,而同一主题的其他文献日期可能会有所不同。
- 显示了每年CARLA排行榜上的最高分数(DS,从0到100)和最近的nuPlan挑战赛得分(范围从0到1)。
关键术语
- RL (Reinforcement Learning): 强化学习。
- IL (Imitation Learning): 模仿学习。
- Conditional IL: 条件模仿学习。
- Policy Distillation: 策略蒸馏。
- Generalization: 通用化。
- Modality/Advanced Structure: 模态/高级结构。
- Data Generation: 数据生成。
- Policy Pretraining: 策略预训练。
- Modular End-to-end Planning: 模块化端到端规划。
1.3 Comparison to Related Surveys 与同类综述的比较
We would like to clarify the difference between our survey and previous related surveys 40, 41, 42, 43, 44, 45, 46, 47, 48. Some prior surveys 40, 41, 42, 43 cover content similar to ours in the sense of an end-to-end system. However, they do not cover new benchmarks and approaches that arose with the significant recent transition in the field, and place a minor emphasis on frontiers and challenges. The others focus on specific topics in this domain, such as imitation learning 44, 45, 46 or reinforcement learning 47, 48. In contrast, our survey provides up-to-date information on the latest developments in this field, covering a wide span of topics and providing in-depth discussions of critical challenges.
我们想澄清我们的调查与之前的相关调查之间的差异40,41,42,43,44,45,46,47,48。一些先前的调查40,41,42,43涵盖了与我们在端到端系统意义上相似的内容。然而,它们并未涵盖随着该领域近期重大转变而出现的新基准和方法,并且较少强调前沿和挑战。其他人则专注于该领域的特定主题,例如模仿学习 44, 45, 46 或强化学习 47, 48。相比之下,我们的调查提供了有关该领域最新发展的最新信息,涵盖广泛的主题,并对关键挑战进行了深入讨论。
1.4 Contributions 贡献
To summarize, this survey has three key contributions: (a) We provide a comprehensive analysis of end-to-end autonomous driving for the first time, including high-level motivation, methodologies, benchmarks, and more. Instead of optimizing a single block, we advocate for a philosophy to design the algorithm framework as a whole, with the ultimate target of achieving safe and comfortable driving. (b) We extensively investigate the critical challenges that concurrent approaches face. Out of the more than 250 papers surveyed, we summarize major aspects and provide in-depth analysis, including topics on generalizability, language-guided learning, causal confusion, etc. © We cover the broader impact of how to embrace large foundation models and data engines. We believe that this line of research and the large scale of high-quality data it provides could significantly advance this field. To facilitate future research, we maintain an active repository updated with new literature and open-source projects.
总而言之,这项调查有三个关键贡献:
(a)我们首次提供了端到端自动驾驶的全面分析,包括高层动机、方法论、基准等。我们倡导的不是对单个模块的优化,而是整体设计算法框架的理念,最终目标是实现安全舒适的驾驶。
(b) 我们广泛调查并发方法面临的关键挑战。在调查的 250 多篇论文中,我们总结了主要方面并提供了深入的分析,包括普遍性、语言引导学习、因果混淆等主题。
© 我们涵盖了如何拥抱大型基础模型的更广泛影响和数据引擎。我们相信,这一领域的研究及其提供的大规模高质量数据可以显着推动这一领域的发展。为了促进未来的研究,我们维护一个活跃的存储库,更新新文献和开源项目。
2 METHODS

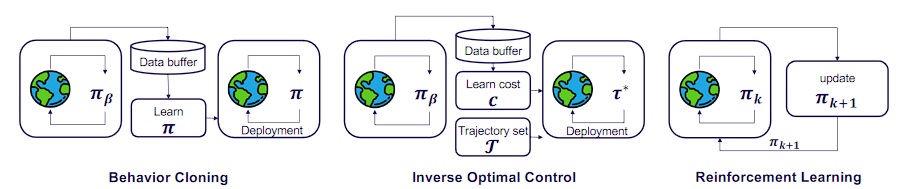
Fig. 3: Overview of methods in end-to-end autonomous driving. We illustrate three popular paradigms, including two imitation learning frameworks (behavior cloning and inverse optimal control), as well as online reinforcement learning.
图 3:端到端自动驾驶方法概述。我们说明了三种流行的范式,包括两种模仿学习框架(行为克隆和逆最优控制)以及在线强化学习。
The policy π \pi π can output planned trajectories or control signals.策略π可以输出规划轨迹或控制信号。
2.1 Imitation Learning 模仿学习
2.1.1 Behavior Cloning 行为克隆
行为克隆是一种直接模仿人类驾驶行为的技术。图中的流程如下:
- 数据采集:从现实世界中收集驾驶数据,存储在数据缓冲区中。
- 学习策略 π \pi π :使用数据缓冲区中的数据来训练策略 π \pi π,该策略试图模仿人类驾驶员的行为。
- 部署 :将训练好的策略 p i pi pi 部署到自动驾驶系统中,使其能够在现实世界中驾驶。
这种方法的优点是简单直接,但缺点是可能会学习到人类驾驶员的错误行为,并且在遇到未见过的情况时表现不佳。
2.I.2 nverse Optimal Control 逆最优控制
逆最优控制试图通过观察人类驾驶行为来推断出潜在的成本函数,然后基于该成本函数来优化驾驶策略。图中的流程如下:
- 数据采集:从现实世界中收集驾驶数据,存储在数据缓冲区中。
- 学习成本 C C C :分析数据缓冲区中的数据,学习出一个成本函数 C C C,该成本函数描述了人类驾驶员在驾驶时考虑的权衡因素。
- 优化策略 τ ∗ \tau^* τ∗ :使用学习到的成本函数 C C C 优化出最优轨迹 τ ∗ \tau^* τ∗,然后基于这些轨迹训练策略 π \pi π。
- 部署 :将训练好的策略 π \pi π 部署到自动驾驶系统中。
逆最优控制能够更好地理解人类驾驶员的决策过程,从而在复杂环境中表现更好。
2.2 Reinforcement Learning 强化学习
强化学习通过试错来学习最优策略。图中的流程如下:
- 初始策略 π k \pi_k πk :使用初始策略 π k \pi_k πk 与环境交互,收集反馈。
- 更新策略 π k + 1 \pi_{k+1} πk+1:根据从环境中获得的反馈更新策略,目标是最大化长期回报。
- 重复:不断重复上述过程,逐步改进策略,直到收敛到最优策略。
强化学习的优势在于能够通过不断试探和学习适应不同的环境,但其训练过程可能需要大量的计算资源和时间。
总结
- 行为克隆:简单直接,但在新环境中可能表现不佳。就像小孩看着大人开车,模仿他们的操作来学习开车。
- 逆最优控制:能够理解人类决策过程,但需要复杂的成本函数推断。分析大人开车的方式,找到背后的"秘诀"或"原则",再根据这些原则来教电脑开车。
- 强化学习:适应性强,但训练时间长且计算资源消耗大。像小孩自己试着开车,通过不断尝试和犯错,最终学会如何开车。
对于强化学习来说,作者提到强化学习会执行不安全的操作,这在现实环境中是巨大挑战,因此一般都是模拟技术,此外RL方法在自动驾驶中的局限性。
RL requires an environment that allows potentially unsafe actions to be executed, to collect novel data (e.g., via random actions). Additionally, RL requires significantly more data to train than IL. For this reason, modern RL methods often parallelize data collection across multiple environments 76. Meeting these requirements in the real world presents great challenges. Therefore, almost all papers that use RL in driving have only investigated the technique in simulation. Most use different extensions of DQN. The community has not yet converged on a specific RL algorithm.
强化学习需要一个允许执行潜在不安全操作的环境,以收集新数据(例如,通过随机操作)。此外,强化学习需要比 IL 多得多的数据进行训练。因此,现代强化学习方法通常会跨多个环境并行数据收集76。在现实世界中满足这些要求提出了巨大的挑战。因此,几乎所有在驾驶中使用强化学习的论文都只研究了模拟技术。大多数使用 DQN 的不同扩展。社区尚未就特定的强化学习算法达成一致。
RL has successfully learned lane following on a real car on an empty street 4. Despite this encouraging result, it must be noted that a similar task was already accomplished by IL three decades prior 3. To date, no report has shown results for end-to-end training with RL that are competitive with IL. The reason for this failure likely is that the gradients obtained via RL are insufficient to train deep perception architectures (i.e., ResNet) required for driving. Models used in benchmarks like Atari, where RL succeeds, are relatively shallow, consisting of only a few layers 77.
RL 已经成功地在空荡荡的街道上学习了真实汽车的车道跟踪 4。尽管取得了这一令人鼓舞的结果,但必须指出的是,IL 在三十年前就已经完成了类似的任务 3。迄今为止,还没有报告显示 RL 的端到端训练结果可以与 IL 相媲美。这种失败的原因可能是通过强化学习获得的梯度不足以训练驾驶所需的深度感知架构(即 ResNet)。 RL 取得成功的 Atari 等基准测试中使用的模型相对较浅,仅由几个层组成 77。
A challenge in the field is to transfer the findings from simulation to the real world. In RL, the objective is expressed as reward functions, and many algorithms require them to be dense and provide feedback at each environment step. Current works typically use simple objectives, such as progress and collision avoidance. These simplistic designs potentially encourage risky behaviors 80. Devising or learning better reward functions remains an open problem. Another direction would be to develop RL algorithms that can handle sparse rewards, enabling the optimization of relevant metrics directly. RL can be effectively combined with world models 82, 83, 84, though this presents specific challenges (See Sec. 4.3). Current RL solutions for driving rely heavily on low-dimensional representations of the scene, and this issue is further discussed in Sec. 4.2.2.
该领域的一个挑战是将模拟结果转移到现实世界。在强化学习中,目标被表示为奖励函数,许多算法要求它们是密集的并在每个环境步骤提供反馈。当前的工作通常使用简单的目标,例如进度和避免碰撞。这些简单化的设计可能会鼓励危险行为80。设计或学习更好的奖励函数仍然是一个悬而未决的问题。另一个方向是开发可以处理稀疏奖励的强化学习算法,从而直接优化相关指标。强化学习可以有效地与世界模型结合82,83,84,尽管这带来了特定的挑战(参见第 4.3 节)。当前的 RL 驾驶解决方案严重依赖于场景的低维表示,这个问题将在第 2 节中进一步讨论。 4.2.2.
在强化学习(RL)中,密集奖励是指在每一步环境交互中都会给予反馈的奖励函数。也就是说,代理(agent)在每次采取行动后,都会收到一个即时的奖励信号。这种密集奖励设计有以下特点:
- 频繁反馈:每一步都提供奖励,有助于代理快速了解哪些行为是有益的,哪些是无益的。
- 短期目标优化:代理可以通过不断调整每一步的行为来最大化即时奖励,从而逐步优化整体策略。
密集奖励虽然提供了频繁的反馈,但如果设计不当,可能会导致以下问题:
- 过度优化短期目标 :
- 问题:代理可能会为了最大化每一步的即时奖励,而忽视长期安全和策略的整体合理性。
- 例子:如果奖励函数主要关注进度和避免碰撞,代理可能会选择一些快速但潜在危险的路径来快速完成任务,忽视其他安全因素。
- 奖励设计简单化 :
- 问题:简单的奖励设计往往只能捕捉一些基本行为(如避免碰撞),但不能全面反映复杂的驾驶环境和决策需求。
- 例子:仅仅奖励进度和避免碰撞,可能会导致代理忽略其他重要因素,如行驶平稳性、乘客舒适度、遵守交通规则等。
- 激励危险行为 :
- 问题:在某些情况下,简单的奖励函数可能会意外地激励危险行为,因为代理在尝试最大化即时奖励时,可能会采取一些高风险高回报的行动。
- 例子:如果代理认为在接近碰撞的情况下快速通过某个路段能获得更高的进度奖励,它可能会选择这种高风险行为,从而增加碰撞的风险。
3 BENCHMARKING
Autonomous driving systems require a comprehensive evaluation to ensure safety. Researchers must benchmark these systems using appropriate datasets, simulators, metrics, and hardware to accomplish this. This section delineates three approaches for benchmarking end-to-end autonomous driving systems: (1) real-world evaluation, (2) online or closedloop evaluation in simulation, and (3) offline or open-loop evaluation on driving datasets. We focus on the scalable and principled online simulation setting and summarize realworld and offline assessments for completeness.
自动驾驶系统需要进行全面评估以确保安全。研究人员必须使用适当的数据集、模拟器、指标和硬件对这些系统进行基准测试才能实现这一目标。本节描述了对端到端自动驾驶系统进行基准测试的三种方法:(1)真实世界评估,(2)模拟中的在线或闭环评估,以及(3)驾驶数据集的离线或开环评估。我们专注于可扩展且有原则的在线模拟设置,并总结现实世界和离线评估的完整性。

3.1 Real-world Evaluation 真实世界评估
Early efforts on benchmarking self-driving involved realworld evaluation. Notably, DARPA initiated a series of races to advance autonomous driving. The first event offered $1M in prize money for autonomously navigating a 240km route through the Mojave desert, which no team achieved 85. The final series event, called the DARPA Urban Challenge, required vehicles to navigate a 96km mock-up town course, adhering to traffic laws and avoiding obstacles 86. These races fostered important developments in autonomous driving, such as LiDAR sensors. Following this spirit, the University of Michigan established MCity 87, a large controlled real-world environment designed to facilitate testing autonomous vehicles. Besides such academic ventures, industries with the resources to deploy fleets of driverless vehicles also rely on real-world evaluation to benchmark improvements in their algorithms.
自动驾驶基准测试的早期工作涉及现实世界的评估。值得注意的是,DARPA 发起了一系列竞赛来推进自动驾驶。第一项赛事提供了 100 万美元的奖金,奖励自动驾驶穿越莫哈韦沙漠 240 公里的路线,但没有任何团队实现这一目标 85。最后的系列活动称为 DARPA 城市挑战赛,要求车辆在 96 公里的模拟城镇路线上行驶,遵守交通法规并避开障碍物 86。这些比赛促进了自动驾驶领域的重要发展,例如激光雷达传感器。秉承这种精神,密歇根大学建立了 MCity 87,这是一个大型受控现实世界环境,旨在促进自动驾驶汽车的测试。除了此类学术冒险之外,拥有部署无人驾驶车队资源的行业也依赖现实世界的评估来衡量其算法的改进。
3.2 Online/Closed-loop Simulation 在线/闭环仿真
Conducting tests of self-driving systems in the real world is costly and risky. To address this challenge, simulation is a viable alternative 14, 88, 89, 90, 91, 92. Simulators facilitate rapid prototyping and testing, enable the quick iteration of ideas, and provide low-cost access to diverse scenarios for unit testing. In addition, simulators offer tools for measuring performance accurately. However, their primary disadvantage is that the results obtained in a simulated environment do not necessarily generalize to the real world (Sec. 4.9.3).
在现实世界中对自动驾驶系统进行测试成本高昂且存在风险。为了应对这一挑战,模拟是一种可行的替代方案14,88,89,90,91,92。模拟器有助于快速原型设计和测试,实现想法的快速迭代,并为单元测试提供对不同场景的低成本访问。此外,模拟器还提供了准确测量性能的工具。然而,它们的主要缺点是在模拟环境中获得的结果不一定能推广到现实世界(第 4.9.3 节)。
Closed-loop evaluation involves building a simulated environment that closely mimics a real-world driving environment. The evaluation entails deploying the driving system in simulation and measuring its performance. The system has to navigate safely through traffic while progressing toward a designated goal location. There are four main sub-tasks involved in developing such simulators: parameter initialization, traffic simulation, sensor simulation, and vehicle dynamics simulation. We briefly describe these subtasks below, followed by a summary of currently available open-source simulators for closed-loop benchmarks.
闭环评估涉及构建一个密切模仿真实驾驶环境的模拟环境。评估需要在模拟中部署驱动系统并测量其性能。系统必须在交通中安全导航,同时朝着指定的目标位置前进。开发此类模拟器涉及四个主要子任务:参数初始化、交通模拟、传感器模拟和车辆动力学模拟。我们在下面简要描述这些子任务,然后总结当前可用的闭环基准测试开源模拟器。
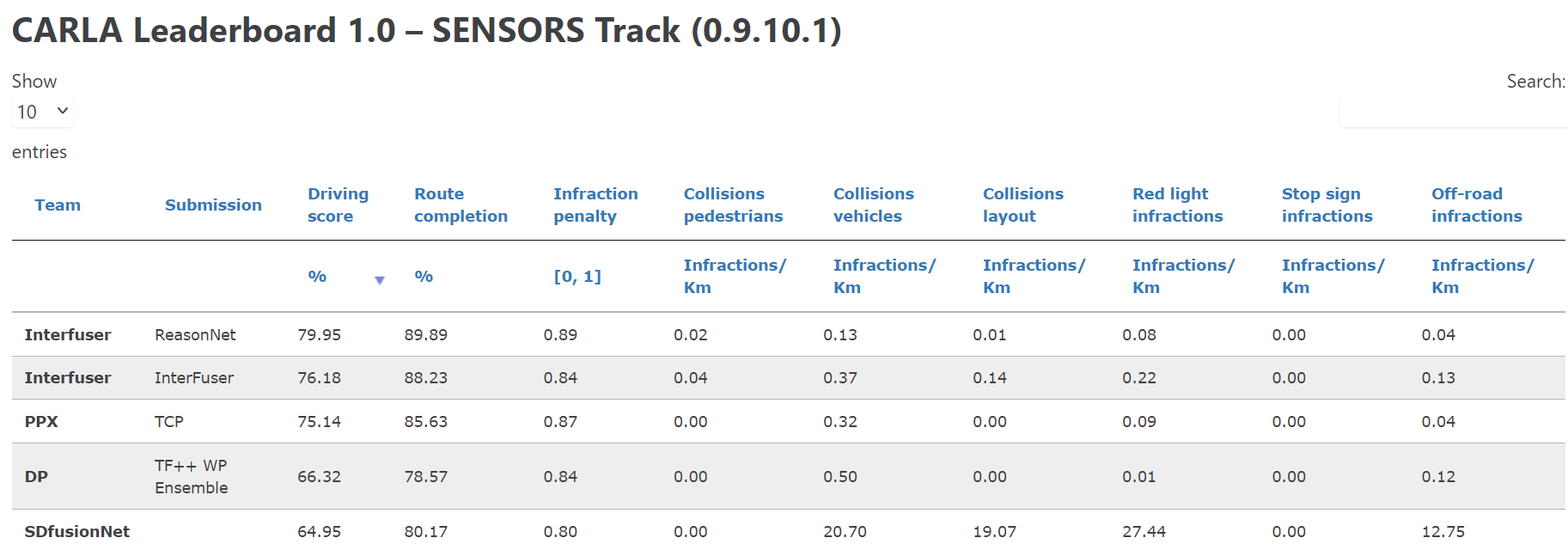
We give a succinct overview of end-to-end driving benchmarks available up to date in Table 1. In 2019, the original benchmark released with CARLA 90 was solved with nearperfect scores 5. The subsequent NoCrash benchmark 123 involves training on a single CARLA town under specific weather conditions and testing generalization to another town and set of weathers. Instead of a single town, the Town05 benchmark 6 involves training on all available towns while withholding Town05 for testing. Similarly, the LAV benchmark trains on all towns except Town02 and Town05, which are both reserved for testing. Roach 21 uses a setting with 3 test towns, albeit all seen during training, and without the safety-critical scenarios in Town05 and LAV. Finally, the Longest6 benchmark 28 uses 6 test towns. Two online servers, the leaderboard (v1 and v2) 13, ensure fair comparisons by keeping evaluation routes confidential. Leaderboard v2 is highly challenging due to the long route length (over 8km on average, as opposed to 1-2km on v1) and a wide variety of new traffic scenarios.
我们在表 1 中简要概述了最新可用的端到端驾驶基准。2019 年,与 CARLA 90 一起发布的原始基准得到了近乎完美的分数 5。随后的 NoCrash 基准 123 涉及在特定天气条件下对单个 CARLA 城镇进行训练,并测试对另一个城镇和一组天气的泛化。 Town05 基准 6 不是针对单个城镇,而是对所有可用城镇进行培训,同时保留 Town05 进行测试。同样,LAV 基准测试在除 Town02 和 Town05 之外的所有城镇进行,这两个城镇都保留用于测试。 Roach 21 使用了包含 3 个测试城镇的设置,尽管它们都是在训练期间看到的,并且没有 Town05 和 LAV 中的安全关键场景。最后,Longest6 基准28使用了 6 个测试城镇。两个在线服务器,即排行榜(v1 和 v2)13,通过对评估路线保密来确保公平比较。由于路线长度较长(平均超过 8 公里,而 v1 为 1-2 公里)和各种新的交通场景,Leaderboard v2 极具挑战性。

TABLE 1: Open-source Simulators with active benchmarks for closed-loop evaluation of autonomous driving.
表 1:具有用于自动驾驶闭环评估的主动基准的开源模拟器。
3.3 Offline/Open-loop Evaluation 离线/开环评估
Open-loop evaluation mainly assesses a system's performance against pre-recorded expert driving behavior. This method requires evaluation datasets that include (1) sensor readings, (2) goal locations, and (3) corresponding future driving trajectories, usually obtained from human drivers. Given sensor inputs and goal locations as inputs, performance is measured by comparing the system's predicted future trajectory against the trajectory in the driving log. Systems are evaluated based on how closely their trajectory predictions match the human ground truth, as well as auxiliary metrics such as the collision probability with other agents. The advantage of open-loop evaluation is that it is easy to implement using realistic traffic and sensor data, as it does not require a simulator. However, the key disadvantage is that it does not measure performance in the actual test distribution encountered during deployment. During testing, the driving system may deviate from the expert driving corridor, and it is essential to verify the system's ability to recover from such drift (Sec. 4.9.2). Furthermore, the distance between the predicted and the recorded trajectories is not an ideal metric in a multi-modal scenario. For example, in the case of merging into a turning lane, both the options of merging immediately or later could be valid, but open-loop evaluation penalizes the option that was not observed in the data. Therefore, besides measuring collision probability and prediction errors, a few metrics were proposed to cover more comprehensive aspects such as traffic violations, progress, and driving comfort 125.
开环评估主要根据预先记录的专家驾驶行为来评估系统的性能。该方法需要评估数据集,其中包括(1)传感器读数、(2)目标位置和(3)相应的未来驾驶轨迹(通常从人类驾驶员那里获得)。给定传感器输入和目标位置作为输入,通过将系统预测的未来轨迹与驾驶日志中的轨迹进行比较来衡量性能。根据系统的轨迹预测与人类地面真实情况的匹配程度以及辅助指标(例如与其他智能体的碰撞概率)来评估系统。开环评估的优点是可以使用真实的交通和传感器数据轻松实现,因为它不需要模拟器。然而,主要缺点是它不测量部署过程中遇到的实际测试分布的性能。在测试过程中,驾驶系统可能会偏离专家驾驶走廊,因此必须验证系统从这种漂移中恢复的能力(第4.9.2节)。此外,预测轨迹和记录轨迹之间的距离在多模态场景中并不是一个理想的度量。例如,在并入转弯车道的情况下,立即并道或稍后并道的选项都可能有效,但开环评估会惩罚数据中未观察到的选项。因此,除了测量碰撞概率和预测误差之外,还提出了一些指标来涵盖交通违规、进度和驾驶舒适度等更全面的方面125。
This approach requires comprehensive datasets of trajectories to draw from. The most popular datasets for this purpose include nuScenes 126, Argoverse 127, Waymo 128, and nuPlan 14. All of these datasets comprise a large number of real-world driving traversals with varying degrees of difficulty. However, open-loop results do not provide conclusive evidence of improved driving behavior in closedloop, due to the aforementioned drawbacks 123, 125, 129, 130. Overall, a realistic closed-loop benchmarking, if available and applicable, is recommended in future research.
这种方法需要综合的轨迹数据集来绘制。用于此目的的最流行的数据集包括 nuScenes 126、Argoverse 127、Waymo 128 和 nuPlan 14。所有这些数据集都包含大量具有不同难度的现实世界驾驶遍历。然而,由于上述缺点,开环结果并没有提供闭环驾驶行为改善的决定性证据123,125,129,130。总体而言,如果可行且适用,建议在未来的研究中采用现实的闭环基准测试。
这里面并不是一个理想的度量包含多个内容的解释。
动态环境缺失:开环评估使用静态数据集,而不考虑实际驾驶过程中环境的动态变化(如突然出现的障碍物、其他车辆的行为等)。在实际驾驶中,环境是不断变化的,驾驶系统需要实时做出反应。
缺乏实时反馈:在实际驾驶中,系统会根据实时反馈进行调整和优化,而开环评估中系统没有这种反馈机制,因此无法评估其在动态环境中的表现。
在实际假设中,各个代理之间都是需要交互的,静态的输入不能很好的反馈,并进行调整和优化,目前主流的数据集如下 nuScenes 126、Argoverse 127、Waymo 128 和 nuPlan 14。
总结
3.1 现实世界评估 (Real-world Evaluation)
- 定义:在真实世界中对自动驾驶系统进行测试。
- 过程:直接在现实世界的道路和环境中测试自动驾驶车辆的表现。例如,DARPA发起的竞赛和密歇根大学的MCity设施。
- 优点
- 提供最接近真实驾驶环境的测试,能验证系统在真实世界中的实际表现。
- 有助于发现模拟环境中无法预见的问题和挑战。
- 缺点
- 成本高昂,风险较大。
- 受限于现实世界的可控性和安全性,难以测试极端情况。
3.2 闭环评估 (Closed-loop Simulation)
- 定义:在模拟环境中进行动态、交互式的测试,尽可能模仿真实世界驾驶。
- 过程:在模拟器中部署驾驶系统,系统需在动态交通中导航并朝着目标前进。包括参数初始化、交通模拟、传感器模拟和车辆动力学模拟等子任务。
- 优点
- 低成本,安全性高。
- 可快速迭代和测试各种场景,包括极端情况。
- 缺点
- 模拟环境中的结果不一定能完全推广到现实世界,存在一定的现实差距。
3.3 开环评估 (Open-loop Evaluation)
- 定义:基于预录制的专家驾驶行为数据进行评估,不需要动态模拟器。
- 过程:使用包含传感器读数、目标位置和人类驾驶轨迹的评估数据集。系统预测未来轨迹并与人类驾驶日志进行比较。
- 优点
- 实现简单,使用真实的交通和传感器数据,不需要复杂的模拟器。
- 缺点
- 无法测量系统在实际测试分布中的性能。
- 预测轨迹和记录轨迹之间的距离在多模态场景中不是理想的度量标准。
小结
- 环境设置 :
- 现实世界评估:在真实道路和环境中进行测试。
- 闭环评估:在高度仿真的模拟环境中进行动态测试。
- 开环评估:基于预录制数据,不需要动态环境。
- 测试内容 :
- 现实世界评估:测试系统在真实环境中的实际表现,适用于全面验证。
- 闭环评估:测试系统在动态模拟环境中的表现,适用于快速迭代和验证。
- 开环评估:主要测试系统的轨迹预测能力,适用于基础验证。
- 实施难度 :
- 现实世界评估:高成本,高风险,实施难度大。
- 闭环评估:成本较低,安全性高,但需要复杂的模拟器。
- 开环评估:实现简单,成本低,不需要模拟器。
三种评估方法各有优缺点,适用于不同的测试需求。在实际应用中,通常需要结合这三种方法,以全面评估和优化自动驾驶系统的性能。现实世界评估提供最真实的验证,但成本高且有风险;闭环评估提供了安全、快速迭代的环境;开环评估则简单易实现,用于基础验证。
4 CHALLENGES

Following each topic illustrated in Fig. 1, we now walk through current challenges, related works or potential resolutions, risks, and opportunities. We start with challenges in handling different input modalities in Sec. 4.1, followed by a discussion on visual abstraction for efficient policy learning in Sec. 4.2. Further, we introduce learning paradigms such as world model learning (Sec. 4.3), multi-task frameworks (Sec. 4.4), and policy distillation (Sec. 4.5). Finally, we discuss general issues that impede safe and reliable end-to-end autonomous driving, including interpretability in Sec. 4.6, safety guarantees in Sec. 4.7, causal confusion in Sec. 4.8, and robustness in Sec. 4.9.
按照图 1 所示的每个主题,我们现在将介绍当前的挑战、相关工作或潜在的解决方案、风险和机遇。我们从处理不同输入方式的挑战开始。 4.1,然后是第 4.1 节中关于高效政策学习的视觉抽象的讨论。 4.2.此外,我们还介绍了学习范式,例如世界模型学习(第 4.3 节)、多任务框架(第 4.4 节)和策略蒸馏(第 4.5 节)。最后,我们讨论阻碍安全可靠的端到端自动驾驶的一般问题,包括第二节中的可解释性。 4.6、安全保障4.7,第 4 节中的因果混乱。 4.8,以及第 4.8 节的稳健性。 4.9.
4.1 Dilemma over Sensing and Input Modalities 传感和输入方式的困境
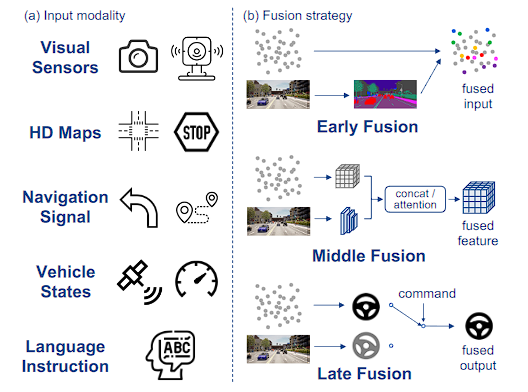
Fig. 4: Examples of input modality and fusion strategy. Different modalities have distinct characteristics, leading to the challenge of effective sensor fusion. We take point clouds and images as examples to depict various fusion strategies.
图 4:输入模式和融合策略的示例。不同的模式具有不同的特征,导致有效的传感器融合面临挑战。我们以点云和图像为例来描述各种融合策略。
Sensing: Though early work 8 successfully achieved following a lane with a monocular camera, this single input modality cannot handle complex scenarios. Therefore, various sensors in Fig. 4 have been introduced for recent selfdriving vehicles. Particularly, RGB images from cameras replicate how humans perceive the world, with abundant semantic details; LiDARs or stereo cameras provide accurate 3D spatial knowledge. Emerging sensors like mmWave radars and event cameras excel at capturing objects' relative movement. Additionally, vehicle states from speedometers and IMUs, together with navigation commands, are other lines of input that guide the driving system. However, various sensors possess distinct perspectives, data distributions, and huge price gaps, thereby posing challenges in effectively designing the sensory layout and fusing them to complement each other for autonomous driving.
传感:虽然早期的工作8成功地实现了使用单目摄像头跟踪车道,但这种单一输入模式无法处理复杂的场景。因此,最近的自动驾驶车辆引入了图 4 中的各种传感器。特别是,相机的 RGB 图像复制了人类感知世界的方式,具有丰富的语义细节; LiDAR 或立体相机提供准确的 3D 空间知识。毫米波雷达和事件相机等新兴传感器擅长捕捉物体的相对运动。此外,车速表和 IMU 的车辆状态以及导航命令是指导驾驶系统的其他输入线。然而,各种传感器具有不同的视角、数据分布和巨大的价格差距,从而对有效设计传感器布局并融合它们以实现自动驾驶相互补充提出了挑战。
Multi-sensor fusion has predominantly been discussed in perception-related fields, e.g., object detection 131, 132 and semantic segmentation 133, 134, and is typically categorized into three groups: early, mid, and late fusion. Endto-end autonomous driving algorithms explore similar fusion schemes. Early fusion combines sensory inputs before feeding them into shared feature extractors, where concatenation is a common way for fusion 32, 135, 136, 137, 138. To resolve the view discrepancy, some works project point clouds on images 139 or vice versa (predicting semantic labels for LiDAR points 52, 140). On the other hand, late fusion combines multiple results from multi-modalities. It is less discussed due to its inferior performance 6, 141. Contrary to these methods, middle fusion achieves multi-sensor fusion within the network by separately encoding inputs and then fusing them at the feature level. Naive concatenation is also frequently adopted 15, 22, 30, 142, 143, 144, 145, 146. Recently, works have employed Transformers 27 to model interactions among features 6, 28, 29, 147, 148. The attention mechanism in Transformers has demonstrated great effectiveness in aggregating the context of different sensor inputs and achieving safer end-to-end driving.
多传感器融合主要在感知相关领域进行讨论,例如目标检测131, 132和语义分割133, 134,通常分为三组:早期融合、中期融合和晚期融合。端到端自动驾驶算法探索类似的融合方案。早期融合在将感觉输入输入共享特征提取器之前将其组合起来,其中串联是融合的常见方式32,135,136,137,138。为了解决视图差异,一些作品在图像上投影点云139,反之亦然(预测 LiDAR 点的语义标签52, 140)。另一方面,后期融合结合了多模态的多个结果。由于其性能较差,因此讨论较少6, 141。与这些方法相反,中间融合通过单独编码输入然后在特征级别融合它们来实现网络内的多传感器融合。朴素串联也经常被采用15,22,30,142,143,144,145,146。最近,有研究采用 Transformers 27 来模拟特征之间的交互6,28,29,147,148。Transformers中的注意力机制在聚合不同传感器输入的上下文和实现更安全的端到端驾驶方面表现出了巨大的有效性。
在多传感器融合领域,尤其是感知相关领域(如目标检测和语义分割),多传感器融合通常被分为三类:早期融合(Early Fusion)、中期融合(Middle Fusion)和晚期融合(Late Fusion)。
早期融合 (Early Fusion)
- 定义:在将传感器输入送入共享特征提取器之前,将其组合在一起。
- 方法:一种常见的方法是将不同传感器的数据串联起来。为了解决视图差异,一些研究将点云投影到图像上,或者反之亦然(如预测LiDAR点的语义标签)。
- 优点:能够在特征提取的早期阶段融合多种感知信息,可能提高整体感知性能。
- 示例:参考文献32, 135, 136, 137, 138讨论了这种方法。点云投影到图像上的方法见参考文献139,预测LiDAR点的语义标签见参考文献52, 140。
中期融合 (Middle Fusion)
- 定义:在网络内部通过单独编码输入,然后在特征级别融合不同传感器的数据。
- 方法:经常采用朴素串联的方法将不同传感器的特征融合在一起。最近的研究中,Transformers被用来模拟特征之间的交互。
- 优点:能够更灵活地处理来自不同传感器的数据,利用中期特征融合提高系统的整体表现。
- 示例:参考文献15, 22, 30, 142, 143, 144, 145, 146讨论了这种方法。Transformers的应用见参考文献6, 27, 28, 29, 147, 148。
晚期融合 (Late Fusion)
- 定义:将来自多模态的多个结果进行组合。
- 方法:较少讨论的一种方法,因为其性能通常不如早期或中期融合。
- 优点:结构简单,易于实现。
- 缺点:性能相对较差,难以充分利用多传感器数据的互补信息。
- 示例:参考文献6, 141讨论了这种方法。
4.2 Dependence on Visual Abstraction 对视觉抽象的依赖
End-to-end autonomous driving systems roughly have two stages: encoding the state into a latent feature representation, and then decoding the driving policy with intermediate features. In urban driving, the input state, i.e., the surrounding environment and ego state, is much more diverse and high-dimensional compared to common policy learning benchmarks such as video games 18, 174, which might lead to the misalignment between representations and necessary attention areas for policy making. Hence, it is helpful to design "good" intermediate perception representations, or first pre-train visual encoders using proxy tasks. This enables the network to extract useful information for driving effectively, thus facilitating the subsequent policy stage. Furthermore, this can improve the sample efficiency for RL methods.
端到端自动驾驶系统大致有两个阶段:将状态编码为潜在特征表示,然后用中间特征解码驾驶策略。在城市驾驶中,输入状态,即周围环境和自我状态,与视频游戏等常见的政策学习基准相比更加多样化和高维度18, 174,这可能导致表征和自我状态之间的错位。政策制定的必要关注领域。因此,设计"好的"中间感知表示,或者首先使用代理任务预训练视觉编码器是有帮助的。这使得网络能够提取有效驾驶的有用信息,从而促进后续的政策阶段。此外,这可以提高 RL 方法的样本效率。
端到端自动驾驶系统大致包含两个主要策略:
- 状态编码 (State Encoding):将输入状态编码为潜在特征表示。
- 驾驶策略解码 (Driving Policy Decoding):利用中间特征来解码并生成驾驶策略。
状态编码 (State Encoding):状态编码阶段将车辆周围的环境信息和自身状态转化为潜在的特征表示。这些潜在特征表示能够提取输入数据中的关键信息,使系统能够理解当前驾驶环境。
驾驶策略解码 (Driving Policy Decoding):在解码阶段,系统利用编码阶段生成的中间特征来制定驾驶策略。这一步涉及从潜在特征中提取决策信息,以实现安全有效的驾驶。
4.3 Complexity of World Modeling for Model-based RL 基于模型的强化学习的世界建模的复杂性
Besides the ability to better abstract perceptual representations, it is essential for end-to-end models to make reasonable predictions about the future to take safe maneuvers. In this section, we mainly discuss the challenges of current model-based policy learning works, where a world model provides explicit future predictions for the policy model.
除了更好地抽象感知表示的能力之外,端到端模型对未来做出合理的预测以采取安全的操作也至关重要。在本节中,我们主要讨论当前基于模型的政策学习工作的挑战,其中世界模型为政策模型提供了明确的未来预测。
Deep RL typically suffers from the high sample complexity, which is pronounced in autonomous driving. Modelbased reinforcement learning (MBRL) offers a promising direction to improve sample efficiency by allowing agents to interact with the learned world model instead of the actual environment. MBRL methods employ an explicit world (environment) model, which is composed of transition dynamics and reward functions. This is particularly helpful in driving, as simulators like CARLA are relatively slow.
深度强化学习通常面临样本复杂度高的问题,这在自动驾驶中尤为明显。基于模型的强化学习(MBRL)通过允许代理与学习的世界模型而不是实际环境进行交互,为提高样本效率提供了一个有前途的方向。 MBRL 方法采用显式世界(环境)模型,该模型由过渡动力学和奖励函数组成。这对于驾驶特别有帮助,因为像 CARLA 这样的模拟器相对较慢。
4.4 Reliance on Multi-Task Learning 对多任务学习的依赖
Multi-task learning (MTL) involves jointly performing several related tasks based on a shared representation through separate heads. MTL provides advantages such as computational cost reduction, the sharing of relevant domain knowledge, and the ability to exploit task relationships to improve model's generalization ability 207. Consequently, MTL is well-suited for end-to-end driving, where the ultimate policy prediction requires a comprehensive understanding of the environment. However, the optimal combination of auxiliary tasks and appropriate weighting of losses to achieve the best performance presents a significant challenge.
多任务学习(MTL)涉及通过单独的头基于共享表示联合执行多个相关任务。 MTL 具有降低计算成本、共享相关领域知识以及利用任务关系来提高模型泛化能力等优势207。因此,MTL非常适合端到端驾驶,其中最终的政策预测需要对环境的全面了解。然而,辅助任务的最佳组合和适当的损失权重以实现最佳性能提出了重大挑战。
In contrast to common vision tasks where dense predictions are closely correlated, end-to-end driving predicts a sparse signal. The sparse supervision increases the difficulty of extracting useful information for decision-making in the encoder. For image input, auxiliary tasks such as semantic segmentation 28, 31, 139, 208, 209, 210 and depth estimation 28, 31, 208, 209, 210 are commonly adopted in endto-end autonomous driving models. Semantic segmentation helps the model gain a high-level understanding of the scene; depth estimation enables the model to capture the 3D geometry of the environment and better estimate distances to critical objects. Besides auxiliary tasks on perspective images, 3D object detection 28, 31, 52 is also useful for LiDAR encoders. As BEV becomes a natural and popular representation for autonomous driving, tasks such as BEV segmentation are included in models 11, 23, 28, 29, 30, 31, 52, 148 that aggregate features in BEV space. Moreover, in addition to these vision tasks, 29, 208, 211 also predict visual affordances including traffic light states, distances to opposite lanes, etc. Nonetheless, constructing large-scale datasets with multiple types of aligned and high-quality annotations is non-trivaial for real-world applications, which remain as a great concern due to current models' reliance on MTL.
与密集预测紧密相关的常见视觉任务相反,端到端驱动预测稀疏信号。稀疏监督增加了编码器中提取用于决策的有用信息的难度。对于图像输入,端到端自动驾驶模型中通常采用语义分割28,31,139,208,209,210和深度估计28,31,208,209,210等辅助任务。语义分割帮助模型获得对场景的高级理解;深度估计使模型能够捕获环境的 3D 几何形状并更好地估计到关键物体的距离。除了透视图像上的辅助任务之外,3D 对象检测 28,31,52 对于 LiDAR 编码器也很有用。随着 BEV 成为自动驾驶的自然且流行的代表,BEV 分割等任务被包含在聚合 BEV 空间中特征的模型 11,23,28,29,30,31,52,148中。此外,除了这些视觉任务之外,29,208,211还预测视觉可供性,包括交通灯状态、到对面车道的距离等。尽管如此,构建具有多种类型的对齐和高质量注释的大规模数据集是很困难的。对于现实世界的应用来说,这一点并不重要,由于当前模型对 MTL 的依赖,这仍然是一个令人高度关注的问题。
4.5 Inefficient Experts and Policy Distillation 低效的专家和政策蒸馏
As imitation learning, or its predominant sub-category, behavior cloning, is simply supervised learning that mimics expert behaviors, corresponding methods usually follow the "Teacher-Student" paradigm. There lie two main challenges:
由于模仿学习或其主要子类别行为克隆只是模仿专家行为的监督学习,因此相应的方法通常遵循"师生"范式。存在两个主要挑战:
(1) Teachers, such as the handcrafted expert autopilot provided by CARLA, are not perfect drivers, though having access to ground-truth states of surrounding agents and maps. (2) Students are supervised by the recorded output with sensor input only, requiring them to extract perceptual features and learn policy from scratch simultaneously.
(1) 教师,例如 CARLA 提供的手工制作的专家自动驾驶仪,尽管可以访问周围智能体和地图的真实状态,但并不是完美的驾驶员。 (2)学生仅通过传感器输入的记录输出进行监督,要求他们同时提取感知特征并从头开始学习策略。
A few studies propose to divide the learning process into two stages, i.e., training a stronger teacher network and then distilling the policy to the student. In particular, Chen et al. 5, 52 first employ a privileged agent to learn how to act with access to the state of the environment, then let the sensorimotor agent (student) closely imitate the privileged agent with distillation at the output stage. More compact BEV representations as input for the privileged agent provide stronger generalization abilities and supervision than the original expert. The process is depicted in Fig. 5.
一些研究建议将学习过程分为两个阶段,即训练更强大的教师网络,然后将政策提炼给学生。特别是,陈等人。 5, 52 首先使用特权代理来学习如何在访问环境状态的情况下采取行动,然后让感觉运动代理(学生)在输出阶段通过蒸馏来密切模仿特权代理。更紧凑的 BEV 表示作为特权代理的输入,提供比原始专家更强的泛化能力和监督。该过程如图5所示。
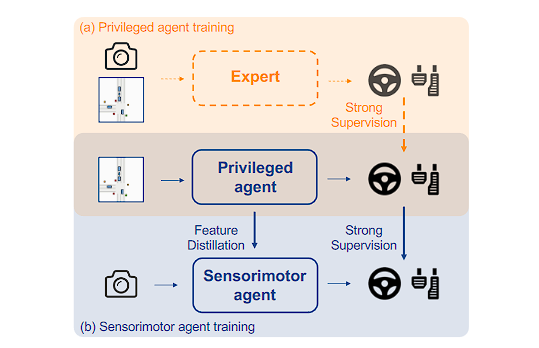
Fig. 5: Policy distillation. (a) The privileged agent learns a robust policy with access to privileged ground-truth information. The expert is labeled with dashed lines to indicate that it is not mandatory if the privileged agent is trained via RL. (b) The sensorimotor agent imitates the privileged agent through both feature distillation and output imitation.
图 5:政策蒸馏。 (a) 特权代理通过访问特权真实信息来学习稳健的策略。专家用虚线标记,表明如果特权代理通过 RL 进行训练,则不是强制性的。 (b) 感觉运动智能体通过特征蒸馏和输出模仿来模仿特权智能体。
策略蒸馏过程分析
第一阶段:训练特权代理(教师)
- 特权代理:在训练过程中,特权代理能够访问环境的真实状态(privileged ground-truth information),因此能够学习到一个更为稳健和强大的策略。这个阶段中的特权代理通过访问详细和准确的环境信息来提高其决策能力。
- 专家角色:专家(如图中的虚线框)可能用于训练特权代理。如果特权代理通过强化学习(RL)进行训练,专家并不是必需的。
- 训练目标:教师模型通过访问详细和准确的环境状态(特权信息),来学习稳健和高性能的驾驶策略。
- 特权信息:教师模型通常可以访问比学生模型更多的信息,如全局地图、精确的车辆位置和速度等。
- 训练方法:教师模型可以使用强化学习(RL)或其他高效的训练方法,通过大量的计算和数据来学习复杂的策略。
第二阶段:特征蒸馏和输出模仿(学生)
- 特征蒸馏:在这一阶段,感觉运动代理(学生)通过特征蒸馏(Feature Distillation)从特权代理中提取特征。这意味着学生模型不仅模仿特权代理的最终决策输出,还模仿其中间特征表示。
- 输出模仿:学生模型还通过模仿特权代理的输出行为来学习策略。这种模仿包括复制特权代理的动作和决策过程。
- 学习目标:学生模型的目标是通过模仿教师模型,学习到有效的驾驶策略。
- 输入限制:学生模型只能访问有限的感知输入(如摄像头、雷达等传感器数据),无法直接获得教师模型的特权信息。
- 训练方法:通过策略蒸馏,学生模型模仿教师模型的中间特征和输出行为,从而快速学习到有效的策略。
为什么使用策略蒸馏?
性能提升:
- 高效学习:通过模仿教师模型,学生模型能够快速学习到高性能的策略,而无需从头开始,这显著提升了学习效率。
- 复杂策略学习:教师模型通常通过访问更多的信息和更强大的计算资源来学习复杂的策略,学生模型可以直接受益于这些高质量的策略。
简化学习过程:
- 简化输入处理:学生模型只需要处理感知数据,而不是直接面对复杂的环境状态,通过蒸馏,学生模型可以学习到如何更好地解释和利用这些数据。
- 特征蒸馏:学生模型可以通过特征蒸馏,从教师模型中学习到有效的中间特征表示,这有助于简化学习过程,提高训练效率。
提高样本效率:
- 数据利用率:在模拟环境中训练教师模型,然后将知识传递给学生模型,这可以显著减少需要在现实环境中收集的数据量,降低训练成本和风险。
- 虚拟交互:通过在虚拟环境中进行大量的交互和学习,学生模型可以提高样本效率,快速适应不同的驾驶场景【Chen et al., 2021】。
增强泛化能力:
- 稳健策略:通过访问真实环境状态训练的教师模型能够学习到更稳健的策略,这些策略能够更好地处理不同的驾驶场景和突发情况。
- 特权信息:特权代理可以使用更丰富的输入信息,提供比原始专家更强的泛化能力和监督,从而使学生模型在不同驾驶场景中表现更佳。
降低训练成本:
- 减少计算资源:通过在虚拟环境中进行训练,可以显著减少实际环境中所需的计算资源和时间。
- 安全性提高:在虚拟环境中进行策略学习和优化,可以避免在现实世界中可能遇到的安全风险。
但是相较于视觉运动智能体来说仍有较大差距
Though huge efforts have been devoted to designing a robust expert and transferring knowledge at various levels, the teacher-student paradigm still suffers from inefficient distillation. For instance, the privileged agent has access to ground-truth states of traffic lights, which are small objects in images and thus hard to distill corresponding features. As a result, the visuomotor agents exhibit large performance gaps compared to their privileged agents. It may also lead to causal confusion for students (see Sec. 4.8). It is worth exploring how to draw more inspiration from general distillation methods in machine learning to minimize the gap.
尽管人们付出了巨大的努力来设计一个强大的专家并在各个层面上转移知识,但师生范式仍然存在提炼效率低下的问题。例如,特权代理可以访问交通灯的真实状态,它们是图像中的小物体,因此很难提取相应的特征。因此,视觉运动智能体与其特权智能体相比表现出巨大的性能差距。它还可能导致学生的因果混乱(参见第 4.8 节)。如何从机器学习中的通用蒸馏方法中汲取更多灵感来缩小差距,是值得探索的。
4.6 Lack of Interpretability 缺乏可解释性
Interpretability plays a critical role in autonomous driving 214. It enables engineers to better debug the system, provides performance guarantees from a societal perspective, and promotes public acceptance. Achieving interpretability for end-to-end driving models, which are often referred to as "black boxes", is more essential and challenging.
可解释性在自动驾驶中起着至关重要的作用214。它使工程师能够更好地调试系统,从社会角度提供性能保证,并促进公众接受。实现端到端驾驶模型(通常被称为"黑匣子")的可解释性更为重要且更具挑战性。
Given trained models, some post-hoc X-AI (explainable AI) techniques could be applied to gain saliency maps 208, 215, 216, 217, 218. Saliency maps highlight specific regions in the visual input on which the model primarily relies for planning. However, this approach provides limited information, and its effectiveness and validity are difficult to evaluate. Instead, we focus on end-to-end frameworks that directly enhance interpretability in their model design. We introduce each category of interpretability in Fig. 6 below
给定经过训练的模型,可以应用一些事后 X-AI(可解释的 AI)技术来获得显着性图 208,215,216,217,218。显着图突出显示视觉输入中模型主要依赖于规划的特定区域。然而,这种方法提供的信息有限,其有效性和有效性难以评估。相反,我们专注于直接增强模型设计可解释性的端到端框架。我们在下面的图6中介绍每个类别的可解释性
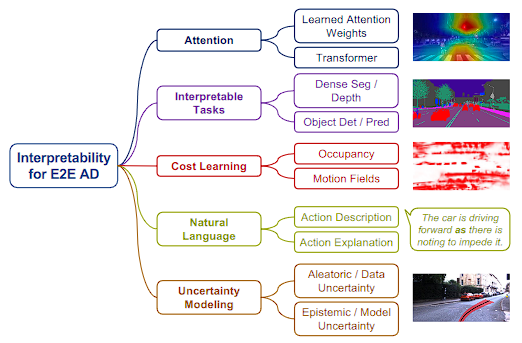
Fig. 6: Summary of the different forms of interpretability. They aid in human comprehension of decision-making processes of end-to-end models and the reliability of outputs.
图 6:不同形式的可解释性的总结。它们有助于人类理解端到端模型的决策过程和输出的可靠性。
注意力机制:可能应用于Transformer中,帮助模型关注输入数据的重要部分,例如驾驶场景中的关键特征。
可解释任务:
- 密集分割/深度估计:这些任务涉及将图像分割成有意义的部分或估计距离,对于理解驾驶场景至关重要。
- 目标检测/预测:识别并预测其他车辆、行人和障碍物的动态。
成本学习:学习与不同驾驶决策相关的成本,帮助评估不同行动的安全性和效率。
- 占用检测:确定环境中哪些区域被占用,哪些未被占用,这对路径规划至关重要。
- 运动场:分析环境中的运动模式,预测未来状态。
自然语言:
- 行动描述:用人类可以理解的术语描述行动。
- 行动解释:为采取某些行动提供解释,增强决策过程的透明度。
不确定性建模:
- 随机性/数据不确定性:理解并建模传感器数据中固有的可变性和噪声。
- 认知/模型不确定性:评估模型预测的不确定性,反映模型知识的局限性。
Attention Visualization 注意力可视化
Attention Visualization: The attention mechanism provides a certain degree of interpretability. In 33, 208, 211, 218, 219, a learned attention weight is applied to aggregate important features from intermediate feature maps. Attention weights can also adaptively combine ROI pooled features from different object regions 220 or a fixed grid 221. NEAT 11 iteratively aggregates features to predict attention weights and refine the aggregated feature. Recently, Transformer attention blocks are employed to better fuse different sensor inputs, and attention maps display important regions in the input for driving decisions 28, 29, 31, 147, 222. In PlanT 223, attention layers process features from different vehicles, providing interpretable insights into the corresponding action. Similar to post-hoc saliency methods, although attention maps offer straightforward clues about models' focus, their faithfulness and utility remain limited.
注意力可视化:注意力机制提供了一定程度的可解释性。在33,208,211,218,219中,应用学习到的注意力权重来聚合中间特征图中的重要特征。注意力权重还可以自适应地组合来自不同对象区域 220 或固定网格 221 的 ROI 池化特征。 NEAT 11 迭代聚合特征来预测注意力权重并细化聚合特征。最近,变压器注意力块被用来更好地融合不同的传感器输入,注意力图显示输入中用于驱动决策的重要区域28,29,31,147,222。在 PlanT 223 中,注意力层处理来自不同车辆的特征,为相应的动作提供可解释的见解。与事后显着性方法类似,尽管注意力图提供了有关模型焦点的直接线索,但它们的忠实度和实用性仍然有限。
Interpretable Tasks 可解释的任务
Interpretable Tasks: Many IL-based works introduce interpretability by decoding the latent feature representations into other meaningful information besides policy prediction, such as semantic segmentation 2, 11, 15, 28, 29, 31, 52, 139, 163, 208, 209, 210, 224, depth estimation 15, 28, 31, 208, 209, object detection 2, 28, 31, 52, affordance predictions 29, 208, 211, motion prediction 2, 52, and gaze map estimation 225. Although these methods provide interpretable information, most of them only treat these predictions as auxiliary tasks 11, 15, 28, 31, 139, 208, 209, 211, with no explicit impact on final driving decisions. Some 29, 52 do use these outputs for final actions, but they are incorporated solely for performing an additional safety check.
可解释的任务:许多基于IL的工作通过将潜在特征表示解码为除了策略预测之外的其他有意义的信息来引入可解释性,例如语义分割2,11,15,28,29,31,52,139,163,208,209 , 210, 224,深度估计 15, 28, 31, 208, 209,目标检测 2, 28, 31, 52,可供性预测 29, 208, 211,运动预测 2, 52,和注视图估计225。尽管这些方法提供了可解释的信息,但大多数仅将这些预测视为辅助任务11,15,28,31,139,208,209,211,对最终驾驶决策没有明确的影响。一些 29, 52 确实使用这些输出进行最终操作,但它们只是为了执行额外的安全检查而合并。
Rules Integration and Cost Learning 规则集成和成本学习
Rules Integration and Cost Learning: As discussed in Sec. 2.1.2, cost learning-based methods share similarities with traditional modular systems and thus exhibit a certain level of interpretability. NMP 32 and DSDNet 226 construct the cost volume in conjunction with detection and motion prediction results. P3 39 combines predicted semantic occupancy maps with comfort and traffic rules constraints to construct the cost function. Various representations, such as probabilistic occupancy and temporal motion fields 1, emergent occupancy 71, and freespace 70, are employed to score sampled trajectories. In 38, 125, 227, human expertise and pre-defined rules including safety, comfort, traffic rules, and routes based on perception and prediction outputs are explicitly included to form the cost for trajectory scoring, demonstrating improved robustness and safety.
规则集成和成本学习:如第 2 节中所述。 2.1.2,基于成本学习的方法与传统的模块化系统有相似之处,因此表现出一定程度的可解释性。 NMP 32 和 DSDNet 226 结合检测和运动预测结果构建成本量。 P3 39将预测的语义占用图与舒适度和交通规则约束相结合来构建成本函数。采用各种表示形式对采样轨迹进行评分,例如概率占用和时间运动场 1、紧急占用 71 和自由空间 70。在38,125,227中,明确包括人类专业知识和预定义规则,包括安全性、舒适性、交通规则以及基于感知和预测输出的路线,以形成轨迹评分的成本,从而证明了鲁棒性和安全性的提高。
Linguistic Explainability 语言可解释性
Linguistic Explainability: As one aspect of interpretability is to help humans understand the system, natural language is a suitable choice for this purpose. Kim et al. 33 and Xu et al. 228 develop datasets pairing driving videos or images with descriptions and explanations, and propose endto-end models with both control and explanation outputs. BEEF 229 fuses the predicted trajectory and the intermediate perception features to predict justifications for the decision. ADAPT 230 proposes a Transformer-based network to jointly estimate action, narration, and reasoning. Recently, 169, 171, 172 resort to the progress of multi-modality and foundation models, using LLMs/VLMs to provide decisionrelated explanations, as discussed in Sec. 4.1.2.
语言可解释性:可解释性的一个方面是帮助人类理解系统,因此自然语言是实现此目的的合适选择。金等人。 33 和徐等人。 228开发将驾驶视频或图像与描述和解释配对的数据集,并提出具有控制和解释输出的端到端模型。 BEEF 229融合预测轨迹和中间感知特征来预测决策的理由。 ADAPT 230提出了一个基于 Transformer 的网络来联合估计动作、叙述和推理。最近,169,171,172诉诸多模态和基础模型的进展,使用LLM/VLM来提供决策相关的解释,如第2节中所讨论的。 4.1.2.
Uncertainty Modeling 不确定性建模
Uncertainty Modeling: Uncertainty is a quantitative approach for interpreting the dependability of deep learning model outputs 231, 232, which can be helpful for designers and users to identify uncertain cases for improvement or necessary intervention. For deep learning, there are two types of uncertainty: aleatoric uncertainty and epistemic uncertainty. Aleatoric uncertainty is inherent to the task, while epistemic uncertainty is due to limited data or modeling capacity. In 233, authors leverage certain stochastic regularizations in the model to perform multiple forward passes as samples to measure the uncertainty. However, the requirement of multiple forward passes is not feasible in real-time scenarios. Loquercio et al. 232 and Filos et al. 234 propose capturing epistemic uncertainty with an ensemble of expert likelihood models and aggregating the results to perform safe planning. Regarding methods modeling aleatoric uncertainty, driving actions/planning and uncertainty (usually represented by variance) are explicitly predicted in 146, 235, 236. Such methods directly model and quantify the uncertainty at the action level as a variable for the network to predict. The planner would generate the final action based on the predicted uncertainty, either choosing the action with the lowest uncertainty from multiple actions 235 or generating a weighted combination of proposed actions based on the uncertainties 146. Currently, predicted uncertainty is mainly utilized in combination with hardcoded rules. Exploring better ways to model and utilize uncertainty for autonomous driving is necessary.
不确定性建模:不确定性是一种用于解释深度学习模型输出的可靠性的定量方法231, 232,这有助于设计者和用户识别不确定的情况以进行改进或必要的干预。对于深度学习来说,有两种类型的不确定性:任意不确定性和认知不确定性。任意不确定性是任务固有的,而认知不确定性是由于有限的数据或建模能力造成的。在233中,作者利用模型中的某些随机正则化来执行多次前向传递作为样本来测量不确定性。然而,多次前向传递的要求在实时场景中是不可行的。洛克尔西奥等人。 232和Filos等人。 234建议通过专家似然模型集合来捕获认知不确定性,并汇总结果以执行安全规划。关于建模任意不确定性的方法,146,235,236中明确预测了驾驶行为/规划和不确定性(通常用方差表示)。此类方法直接对行动层面的不确定性进行建模和量化,作为网络预测的变量。规划器将根据预测的不确定性生成最终操作,或者从多个操作中选择不确定性最低的操作235,或者根据不确定性生成建议操作的加权组合146。目前,预测的不确定性主要与硬编码规则结合使用。有必要探索更好的方法来建模和利用自动驾驶的不确定性。
4.7 Lack of Safety Guarantees 缺乏安全保障
Ensuring safety is of utmost importance when deploying autonomous driving systems in real-world scenarios. However, the learning-based nature of end-to-end frameworks inherently lacks precise mathematical guarantees regarding safety, unlike traditional rule-based approaches 237.
在现实场景中部署自动驾驶系统时,确保安全至关重要。然而,与传统的基于规则的方法不同,端到端框架的基于学习的本质本质上缺乏关于安全性的精确数学保证237。
Nevertheless, it should be noted that modular driving stacks have already incorporated specific safety-related constraints or optimizations within their motion planning or speed prediction modules to enforce safety 238, 239, 240. These mechanisms can potentially be adapted for integration into end-to-end models as post-process steps or safety checks, thereby providing additional safety guarantees. Furthermore, the intermediate interpretability predictions, as discussed in Sec. 4.6, such as detection and motion prediction results, can be utilized in post-processing procedures.
然而,应该指出的是,模块化驱动堆栈已经在其运动规划或速度预测模块中纳入了特定的安全相关约束或优化,以加强安全性238,239,240。这些机制可能适合集成到端到端模型中,作为后处理步骤或安全检查,从而提供额外的安全保证。此外,中间可解释性预测,如第 2 节中所讨论的。 4.6,例如检测和运动预测结果,可以在后处理程序中利用。
4.8 Causal Confusion 因果混乱
Driving is a task that exhibits temporal smoothness, which makes past motion a reliable predictor of the next action. However, methods trained with multiple frames can become overly reliant on this shortcut 241 and suffer from catastrophic failure during deployment. This problem is referred to as the copycat problem 57 in some works and is a manifestation of causal confusion 242, where access to more information leads to worse performance.
驾驶是一项表现出时间平滑性的任务,这使得过去的动作可以可靠地预测下一个动作。然而,使用多个帧训练的方法可能会过度依赖这种快捷方式241,并在部署过程中遭受灾难性的失败。这个问题在一些作品中被称为模仿问题57,是因果混乱的表现242,即访问更多信息会导致性能更差。
Causal confusion in imitation learning has been a persistent challenge for nearly two decades. One of the earliest reports of this effect was made by LeCun et al. 243. They used a single input frame for steering prediction to avoid such extrapolation. Though simplistic, this is still a preferred solution in current state-of-the-art IL methods 22, 28. Unfortunately, using a single frame makes it hard to extract the motion of surrounding actors. Another source of causal confusion is speed measurement 16. Fig. 7 showcases an example of a car waiting at a red light. The action of the car could highly correlate with its speed because it has waited for many frames where the speed is zero and the action is the brake. Only when the traffic light changes from red to green does this correlation break down.
近二十年来,模仿学习中的因果混乱一直是一个持续的挑战。 LeCun 等人最早报道了这种效应。 243。他们使用单个输入帧进行转向预测,以避免这种推断。尽管很简单,但这仍然是当前最先进的 IL 方法中的首选解决方案 22, 28。不幸的是,使用单帧很难提取周围演员的动作。因果混乱的另一个来源是速度测量16。图 7 显示了汽车等红灯的示例。汽车的动作可能与其速度高度相关,因为它已经等待了许多速度为零且动作为刹车的帧。只有当交通信号灯从红色变为绿色时,这种相关性才会被打破。
过度依赖过去的运动预测未来动作:当自动驾驶系统使用多帧数据训练时,它们可能过度依赖历史运动来预测未来动作。这种依赖可能导致系统在实际部署时出现灾难性失败,因为它忽略了环境中可能发生的突变。
简化输入导致的问题:为了避免过度推断,有些方法采用了单帧输入来预测驾驶动作。虽然这种方法比较简单,但它难以捕捉周围参与者的运动信息。
速度测量:速度与车辆的制动动作高度相关,特别是在交通灯情境中。例如,车辆在红灯时因速度为零而持续制动,当交通灯变为绿灯时,这种相关性才会被打破。这种情况说明,简单地依赖历史数据可能无法正确预测实际驾驶情况。
这里所指的"因果混乱"是一个统计和数据科学中的术语,用于描述当一个模型错误地将相关性识别为因果关系时所发生的情况。在自动驾驶系统中,这种混乱特别表现在系统过度依赖历史数据来预测未来行为,而忽视了实时变化或未被模型捕捉到的因素。
例如,如果一个模型学习到在红灯时车辆总是停止,并且与车速为零高度相关,它可能就会错误地认为速度为零是停车的原因,而不是红灯。这就忽略了真正的因果关系------红灯是导致车辆停止的原因。在多帧数据的使用和训练中,如果过分依赖于这种相关性而不是真正的因果关系,就可能在实际驾驶场景中遇到问题,因为实际道路情况可能会迅速变化,而这种变化是历史数据中未曾出现的。
这种问题在深度学习和模仿学习中尤为常见,因为模型可能会学习到伪相关性,而非真实的动态因果关系。解决这一问题的方法之一是通过设计去除或减少这种假设性相关性的训练策略,比如引入对抗训练、随机丢弃技术或增强关键决策帧的权重等。
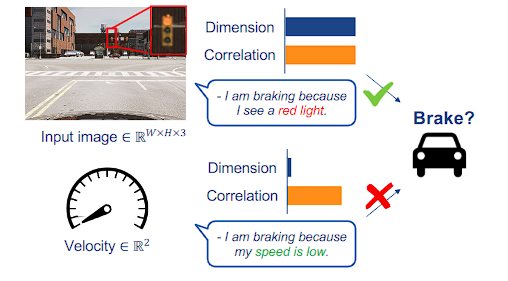
Fig. 7: Causal Confusion. The current action of a car is strongly correlated with low-dimensional spurious features such as the velocity or the car's past trajectory. End-to-End models may latch on to them leading to causal confusion.
图 7:因果混乱。汽车当前的动作与低维虚假特征(例如速度或汽车过去的轨迹)密切相关。端到端模型可能会抓住它们,导致因果混乱。
There are several approaches to combat the causal confusion problem when using multiple frames. In 57, the authors attempt to remove spurious temporal correlations from the bottleneck representation by training an adversarial model that predicts the ego agent's past action. Intuitively, the resulting min-max optimization trains the network to eliminate its past from intermediate layers. It works well in MuJoCo but does not scale to complex visionbased driving. OREO 59 maps images to discrete codes representing semantic objects and applies random dropout masks to units that share the same discrete code, which helps in confounded Atari. In end-to-end driving, ChauffeurNet 244 addresses the causal confusion issue by using the past ego-motion as intermediate BEV abstractions and dropping out it with a 50% probability during training. Wen et al. 58 propose upweighting keyframes in the training loss, where a decision change occurs (and hence are not predictable by extrapolating the past). PrimeNet 60 improves performance compared to keyframes by using an ensemble,where the prediction of a single-frame model is given as additional input to a multi-frame model. Chuang et al. 245 do the same but supervise the multi-frame network with action residuals instead of actions. In addition, the problem of causal confusion can be circumvented by using only LiDAR histories (with a single frame image) and realigning point clouds into one coordinate system. This removes egomotion while retaining information about other vehicles' past states. This technique has been used in multiple works 1, 32, 52, though it was not motivated this way.
使用多个框架时,有多种方法可以解决因果混淆问题。在57中,作者试图通过训练预测自我代理过去行为的对抗模型来消除瓶颈表示中的虚假时间相关性。直观地说,由此产生的最小-最大优化训练网络以消除中间层的过去。它在 MuJoCo 中运行良好,但无法扩展到复杂的基于视觉的驾驶。 OREO 59 将图像映射到代表语义对象的离散代码,并将随机丢弃掩码应用于共享相同离散代码的单元,这有助于混淆 Atari。在端到端驾驶中,ChauffeurNet 244 通过使用过去的自我运动作为中间 BEV 抽象并在训练期间以 50% 的概率将其丢弃来解决因果混淆问题。文等人。 58建议在训练损失中增加关键帧的权重,其中决策发生变化(因此无法通过推断过去来预测)。 PrimeNet 60 通过使用集成来提高与关键帧相比的性能,其中单帧模型的预测作为多帧模型的附加输入给出。庄等人。 245做同样的事情,但是用动作残差而不是动作来监督多帧网络。此外,可以通过仅使用 LiDAR 历史(具有单帧图像)并将点云重新对齐到一个坐标系来避免因果混乱的问题。这消除了自我情绪,同时保留了有关其他车辆过去状态的信息。该技术已在多个作品中使用1,32,52,尽管其动机并非如此。
However, these studies have used environments that are modified to simplify studying the causal confusion problem. Showing performance improvements in state-of-the-art settings as mentioned in Sec. 3.2.5 remains an open problem.
然而,这些研究使用了经过修改的环境,以简化因果混淆问题的研究。显示第 2 节中提到的最先进设置中的性能改进。 3.2.5 仍然是一个悬而未决的问题。
4.9 Lack of Robustness 缺乏鲁棒性
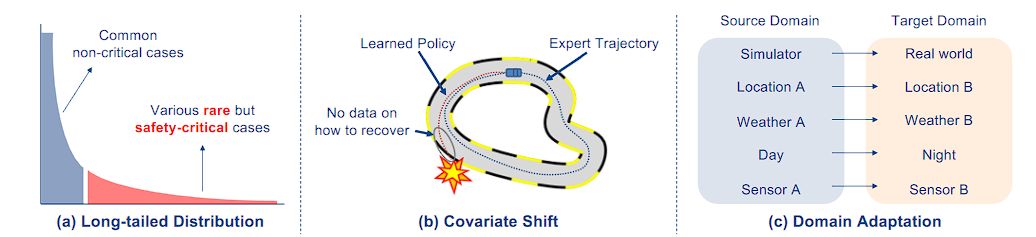
Fig. 8: Challenges in robustness. Three primary generalization issues arise in relation to dataset distribution discrepancies, namely long-tailed and normal cases, expert demonstration and test scenarios, and domain shift in locations, weather, etc.
图 8:稳健性方面的挑战。与数据集分布差异相关的三个主要泛化问题,即长尾和正常情况、专家演示和测试场景以及位置、天气等领域的转移。
4.9.1 Long-tailed Distribution 长尾分布
One important aspect of the long-tailed distribution problem is dataset imbalance, where a few classes make up the majority, as shown in Fig. 8 (a). This poses a big challenge for models to generalize to diverse environments. Various methods mitigate this issue with data processing, including over-sampling 246, 247, under-sampling 248, 249, and data augmentation 250, 251. Besides, weighting-based approaches 252, 253 are also commonly used.
长尾分布问题的一个重要方面是数据集不平衡,其中少数类别占大多数,如图8(a)所示。这对模型泛化到不同环境提出了巨大的挑战。各种方法通过数据处理来缓解这个问题,包括过采样246, 247、欠采样248, 249和数据增强250, 251。此外,基于加权的方法252, 253也常用。
4.9.2 Covariate Shift 协变量平移
As discussed in Sec. 2.1, one important challenge for behavior cloning is covariate shift. The state distributions from the expert's policy and those from the trained agent's policy differ, leading to compounding errors when the trained agent is deployed in unseen testing environments or when the reactions from other agents differ from training time. This could result in the trained agent being in a state that is outside the expert's distribution for training, leading to severe failures. An illustration is presented in Fig. 8 (b).
正如第 2 节中所讨论的。 2.1、行为克隆的一个重要挑战是协变量转变。专家策略的状态分布和经过训练的代理策略的状态分布不同,当经过训练的代理部署在看不见的测试环境中或当其他代理的反应与训练时间不同时,会导致复合错误。这可能会导致受过训练的代理处于专家训练分布之外的状态,从而导致严重的失败。图 8 (b) 给出了一个示例。
4.9.3 Domain Adaptation 领域适应
Domain adaptation (DA) is a type of transfer learning in which the target task is the same as the source task, but the domains differ. Here we discuss scenarios where labels are available for the source domain while there are no labels or a limited amount of labels available for the target domain.
领域适应(DA)是一种迁移学习,其中目标任务与源任务相同,但领域不同。在这里,我们讨论源域有可用标签而目标域没有标签或可用标签数量有限的场景。
As shown in Fig. 8 ©, domain adaptation for autonomous driving tasks encompasses several cases 261:
如图8(c)所示,自动驾驶任务的域适应包含几种情况261:
- Sim-to-real: the large gap between simulators used for training and the real world used for deployment. 模拟到真实:用于训练的模拟器与用于部署的现实世界之间存在巨大差距。
- Geography-to-geography: different geographic locations with varying environmental appearances. 地理到地理:不同的地理位置具有不同的环境外观。
- Weather-to-weather: changes in sensor inputs caused by weather conditions such as rain, fog, and snow. 天气变化:由雨、雾、雪等天气条件引起的传感器输入变化。
- Day-to-night: illumination variations in visual inputs. 白天到晚上:视觉输入的照明变化。
- Sensor-to-sensor: possible differences in sensor characteristics, e.g., resolution and relative position.传感器到传感器:传感器特性可能存在差异,例如分辨率和相对位置。
总结
长尾分布(Long-tailed Distribution):
- 这部分展示了常见的非关键情况和少数但安全关键的情况。长尾分布问题在于,许多稀有但关键的情况可能在数据集中表现不足,这使得模型难以在这些关键场合做出正确的决策。
协变量偏移(Covariate Shift):
- 描述了学习策略和专家轨迹之间的差异,特别是在遇到预料之外的情况时(如图中的红星表示的突发事件),学习策略可能无法有效地恢复或适应,因为在训练数据中没有这类恢复的信息。
域适应(Domain Adaptation):
- 指出了从源域到目标域的转变,比如从模拟器到现实世界,不同地点、不同天气条件、从白天到夜晚,或是不同传感器之间的转变。这些都是模型需要适应的不同域的变化,域适应的目标是使模型能够跨越这些差异,保持其性能和准确性。
5 FUTURE TRENDS
Considering the challenges and opportunities discussed, we list some crucial directions for future research that may have a broader impact in this field.
考虑到所讨论的挑战和机遇,我们列出了未来研究的一些关键方向,这些方向可能会在该领域产生更广泛的影响。

5.1 Zero-shot and Few-shot Learning 零样本和少样本学习
It is inevitable for autonomous driving models to eventually encounter real-world scenarios that lie beyond the training data distribution. This raises the question of whether we can successfully adapt the model to an unseen target domain where limited or no labeled data is available. Formalizing this task for the end-to-end driving domain and incorporating techniques from the zero-shot/few-shot learning literature are the key steps toward achieving this 269, 270.
自动驾驶模型最终不可避免地会遇到超出训练数据分布范围的现实场景。这就提出了一个问题:我们是否可以成功地将模型适应一个看不见的目标领域,其中可用的标记数据有限或没有。将这项任务形式化为端到端驱动领域并结合零样本/少样本学习文献中的技术是实现这一目标的关键步骤269, 270。
5.2 Modular End-to-end Planning 模块化端到端规划
The modular end-to-end planning framework optimizes multiple modules while prioritizing the ultimate planning task, which enjoys the advantages of interpretability as indicated in Sec. 4.6. This is advocated in recent literature 2, 271 and certain industry solutions (Tesla, Wayve, etc.) have involved similar ideas. When designing these differentiable perception modules, several questions arise regarding the choice of loss functions, such as the necessity of 3D bounding boxes for object detection, whether opting for BEV segmentation over lane topology for static scene perception, or the training strategies with limited modules' data.
模块化端到端规划框架优化多个模块,同时优先考虑最终规划任务,其具有可解释性的优势,如第 2 节所示。 4.6.最近的文献 2, 271 提倡这一点,某些行业解决方案(Tesla、Wayve 等)也涉及类似的想法。在设计这些可微分感知模块时,会出现一些关于损失函数选择的问题,例如用于目标检测的 3D 边界框的必要性,是否选择在车道拓扑上进行 BEV 分割以实现静态场景感知,或者使用有限模块的训练策略数据。
5.3 Data Engine 数据引擎
The importance of large-scale and high-quality data for autonomous driving can never be emphasized enough 272. Establishing a data engine with an automatic labeling pipeline 273 could greatly facilitate the iterative development of both data and models. The data engine for autonomous driving, especially modular end-to-end planning systems, needs to streamline the process of annotating highquality perception labels with the aid of large perception models in an automatic way. It should also support mining hard/corner cases, scene generation, and editing to facilitate the data-driven evaluations discussed in Sec. 3.2 and promote diversity of data and the generalization ability of models (Sec. 4.9). A data engine would enable autonomous driving models to make consistent improvements.
大规模、高质量数据对于自动驾驶的重要性怎么强调都不为过272。建立具有自动标记管道的数据引擎273可以极大地促进数据和模型的迭代开发。自动驾驶的数据引擎,特别是模块化的端到端规划系统,需要借助大型感知模型,以自动的方式简化高质量感知标签的标注过程。它还应该支持挖掘困难/极端情况、场景生成和编辑,以促进第 2 节中讨论的数据驱动评估。 3.2 促进数据的多样性和模型的泛化能力(第4.9节)。数据引擎将使自动驾驶模型能够持续改进。
5.4 Foundation Model 基础模型
Recent advancements in foundation models in both language 166, 167, 274 and vision 273, 275, 276 have proved that large-scale data and model capacity can unleash the immense potential of AI in high-level reasoning tasks. The paradigm of finetuning 277 or prompt learning 278, optimization in the form of self-supervised reconstruction 279 or contrastive pairs 165, etc., are all applicable to the end-to-end driving domain. However, we contend that the direct adoption of LLMs for driving might be tricky. The output of an autonomous agent requires steady and accurate measurements, whereas the generative output in language models aims to behave like humans, irrespective of its accuracy. A feasible solution to develop a "foundation" driving model is to train a world model that can forecast the reasonable future of the environment, either in 2D, 3D, or latent space. To perform well on downstream tasks like planning, the objective to be optimized for the model needs to be sophisticated enough, beyond frame-level perception.
语言166,167,274和视觉273,275,276基础模型的最新进展证明,大规模数据和模型能力可以释放人工智能在高级推理任务中的巨大潜力。微调277或即时学习278的范式、自监督重建279或对比对165形式的优化等都适用于端到端驾驶领域。然而,我们认为直接采用LLMs来驾驶可能会很棘手。自主代理的输出需要稳定且准确的测量,而语言模型中的生成输出旨在表现得像人类,无论其准确性如何。开发"基础"驾驶模型的一个可行解决方案是训练一个可以在 2D、3D 或潜在空间中预测环境的合理未来的世界模型。为了在规划等下游任务上表现良好,模型优化的目标需要足够复杂,超出帧级感知。
6 CONCLUSION AND OUTLOOK
In this survey, we provide an overview of fundamental methodologies and summarize various aspects of simulation and benchmarking. We thoroughly analyze the extensive literature to date, and highlight a wide range of critical challenges and promising resolutions.
在本次调查中,我们概述了基本方法,并总结了模拟和基准测试的各个方面。我们彻底分析了迄今为止的大量文献,并强调了广泛的关键挑战和有希望的解决方案。
Outlook. The industry has dedicated considerable effort over the years to develop advanced modular-based systems capable of achieving autonomous driving on highways. However, these systems face significant challenges when confronted with complex scenarios, e.g., inner-city streets and intersections. Therefore, an increasing number of companies have started exploring end-to-end autonomous driving techniques specifically tailored for these environments. It is envisioned that with extensive high-quality data collection, large-scale model training, and the establishment of reliable benchmarks, the end-to-end approach will soon surpass modular stacks in terms of performance and effectiveness. In summary, end-to-end autonomous driving faces great opportunities and challenges simultaneously, with the ultimate goal of building generalist agents. In this era of emerging technologies, we hope this survey could serve as a starting point to shed new light on this domain.
展望,多年来,该行业投入了大量精力来开发能够在高速公路上实现自动驾驶的先进模块化系统。然而,这些系统在面对复杂的场景(例如市中心街道和十字路口)时面临着巨大的挑战。因此,越来越多的公司开始探索专门针对这些环境定制的端到端自动驾驶技术。预计,通过广泛的高质量数据收集、大规模模型训练以及可靠基准的建立,端到端方法将很快在性能和有效性方面超越模块化堆栈。综上所述,端到端自动驾驶面临着巨大的机遇和挑战,最终目标是打造多面智能体。在这个新兴技术的时代,我们希望这项调查能够作为一个起点,为这一领域带来新的启示。