Day08-kafka集群搭建,集群原理,压力测试及filebeat和logstash结合kafak实战案例
- 0、昨日内容回顾:
- 1、修改zookeeper的堆内存大小
- 2、部署kafka集群
- 3、kafka的常用术语
- 4、topic管理
- 5、kafka堆内存调优
- 6、kafka开源监控组件-kafka-eagle
- 7、kafka集群压力测试
-
- [7.1 什么叫压力测试](#7.1 什么叫压力测试)
- [7.2 为什么要进行压力测试](#7.2 为什么要进行压力测试)
- [7.3 实战案例](#7.3 实战案例)
- [7.4 kafka生产环节测试截图](#7.4 kafka生产环节测试截图)
- [7.5 压力测试注意点](#7.5 压力测试注意点)
- 8、kafka优化
- 9、filebeat将数据写入到Kafka实战
- 10、logstash从kafka拉取数据并解析json格式案例
0、昨日内容回顾:
- Kibana的RBAC的管理
- filebeat,logstash,kibana,postman,es-head,连接ES加密集群
bash
[root@elk101 ~]# curl -u elastic:123456 10.0.0.101:9200/_cat/nodes
10.0.0.103 52 91 1 0.40 0.17 0.14 cdfhilmrstw - elk103.oldboyedu.com
10.0.0.101 72 64 1 0.00 0.02 0.05 cdfhilmrstw * elk101.oldboyedu.com
10.0.0.102 60 50 2 0.17 0.08 0.06 cdfhilmrstw - elk102.oldboyedu.com- zookeeper单点部署
- zookeeper的集群部署
- zookeeper集群管理脚本
- zookeeper的命令行管理方式
- create
-s
-e - get
- delete
- deleteall
- set
- ls
- stat
- create
- zookeeper的zkWeb管理方式
- kafka的单点部署
1、修改zookeeper的堆内存大小
温馨提示: 修改zookeeper的堆内存大小,一般情况下,生产环境给到2G足以,如果规模较大可以适当调大到4G。
(1)查看zk默认的堆内存大小为1GB。
bash
[root@elk101.oldboyedu.com ~]# jmap -heap `jps | awk '/QuorumPeerMain/{print $1}'`(2)配置ZK的堆内存
bash
[root@elk101.oldboyedu.com ~]# cat > /oldboyedu/softwares/zk/conf/java.env << 'EOF'
export JAVA_HOME=/oldboyedu/softwares/jdk1.8.0_291
export JVMFLAGS="-Xms256m -Xmx256m $JVMFLAGS"
EOF(3)将配置文件同步到集群的其他zk节点上
bash
[root@elk101.oldboyedu.com ~]# data_rsync.sh /oldboyedu/softwares/zk/conf/java.env(4)重启ZK集群
bash
[root@elk101.oldboyedu.com ~]# zkManager.sh restart(5)验证堆内存
bash
[root@elk101.oldboyedu.com ~]# jmap -heap `jps | awk '/QuorumPeerMain/{print $1}'`2、部署kafka集群
(1)停止kafka单点服务
bash
[root@elk101.oldboyedu.com ~]# kafka-server-stop.sh (2)修改配置文件
bash
[root@elk101.oldboyedu.com ~]# yy /oldboyedu/softwares/kafka/config/server.properties
...
# 唯一标识kafka节点的数字编号,随便写,同一个集群中节点的id编号不重复即可。
broker.id=101
# 指定kafka的数据存储路径。
log.dirs=/oldboyedu/data/kafka
# kafka连接zookeeper集群地址
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181/oldboyedu-linux85-kafka321(3)同步kafka软件包相关文件
bash
[root@elk101.oldboyedu.com ~]# data_rsync.sh /oldboyedu/softwares/kafka
[root@elk101.oldboyedu.com ~]# data_rsync.sh /oldboyedu/softwares/kafka_2.13-3.2.1/
[root@elk101.oldboyedu.com ~]# data_rsync.sh /etc/profile.d/kafka.sh (4)其他2个节点修改配置文件
bash
[root@elk102.oldboyedu.com ~]# vim /oldboyedu/softwares/kafka/config/server.properties
...
broker.id=102
[root@elk103.oldboyedu.com ~]# vim /oldboyedu/softwares/kafka/config/server.properties
...
broker.id=103(5)所有节点启动kafka环境
bash
[root@elk101.oldboyedu.com ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk102.oldboyedu.com ~]# source /etc/profile.d/kafka.sh
[root@elk102.oldboyedu.com ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk103.oldboyedu.com ~]# source /etc/profile.d/kafka.sh
[root@elk103.oldboyedu.com ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties (6)查看zookeeper的源数据
bash
[root@elk101.oldboyedu.com ~]# zkCli.sh -server 10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
...
ls /oldboyedu-linux85-kafka321/brokers/ids
[zk: 10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181(CONNECTED) 0] ls /oldboyedu-linux85-kafka321/brokers/ids
[101, 102, 103]kafka架构
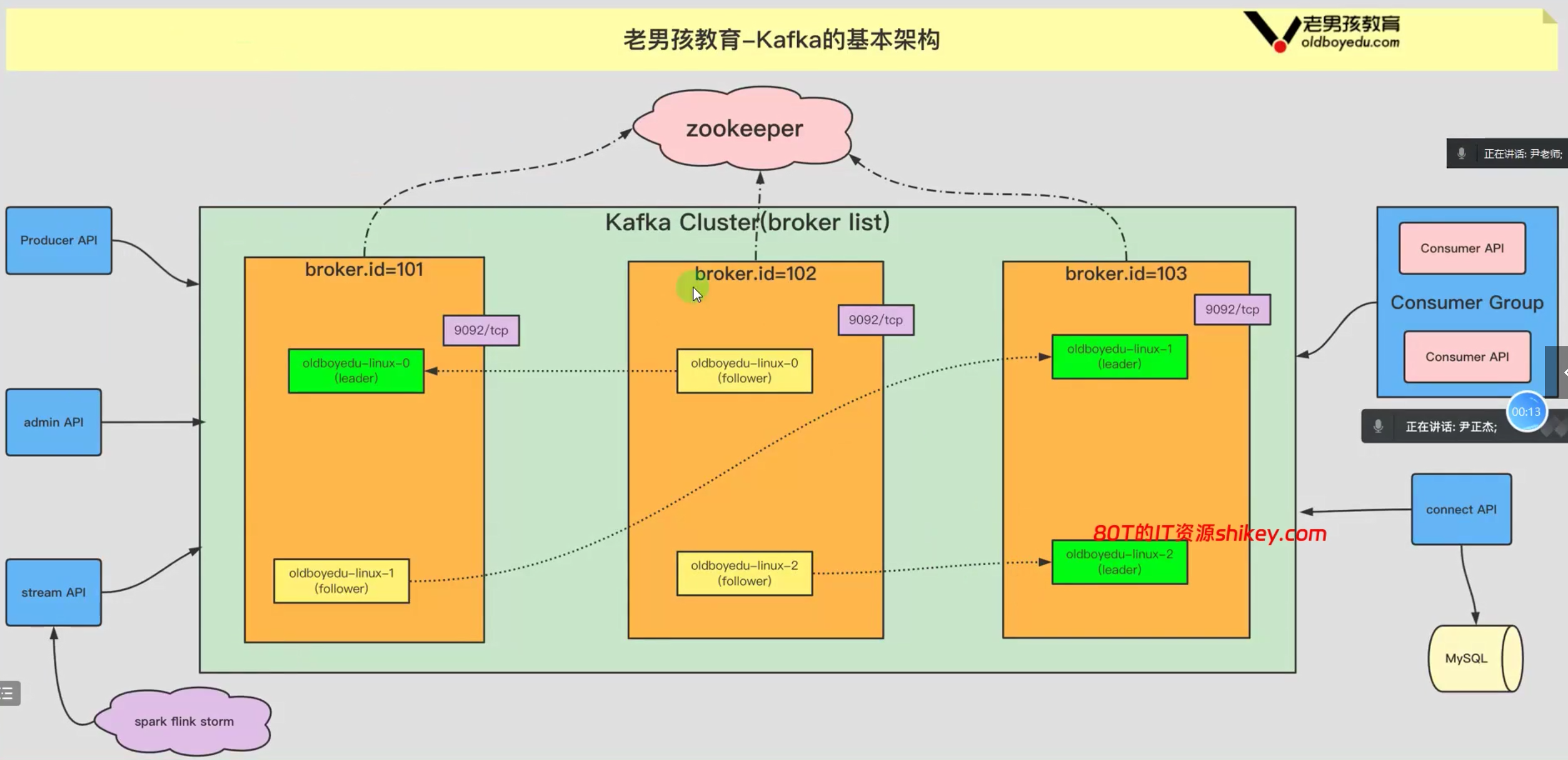
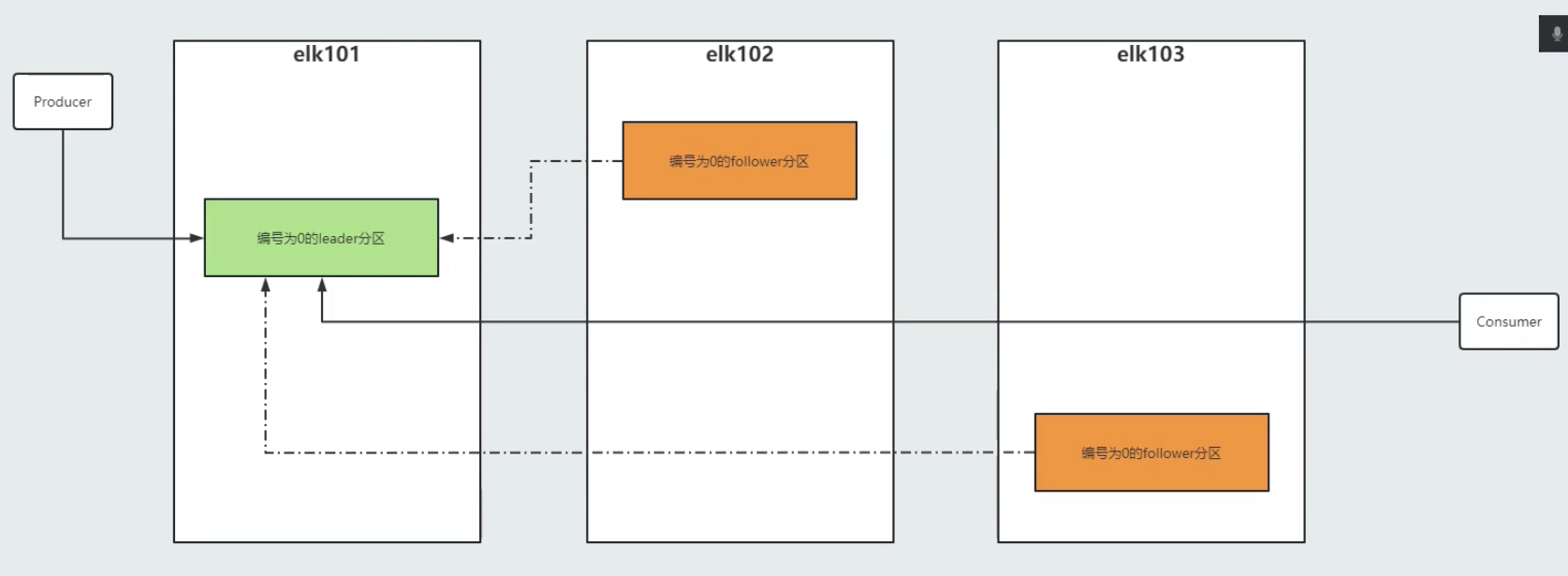
kafka消费组工作原理
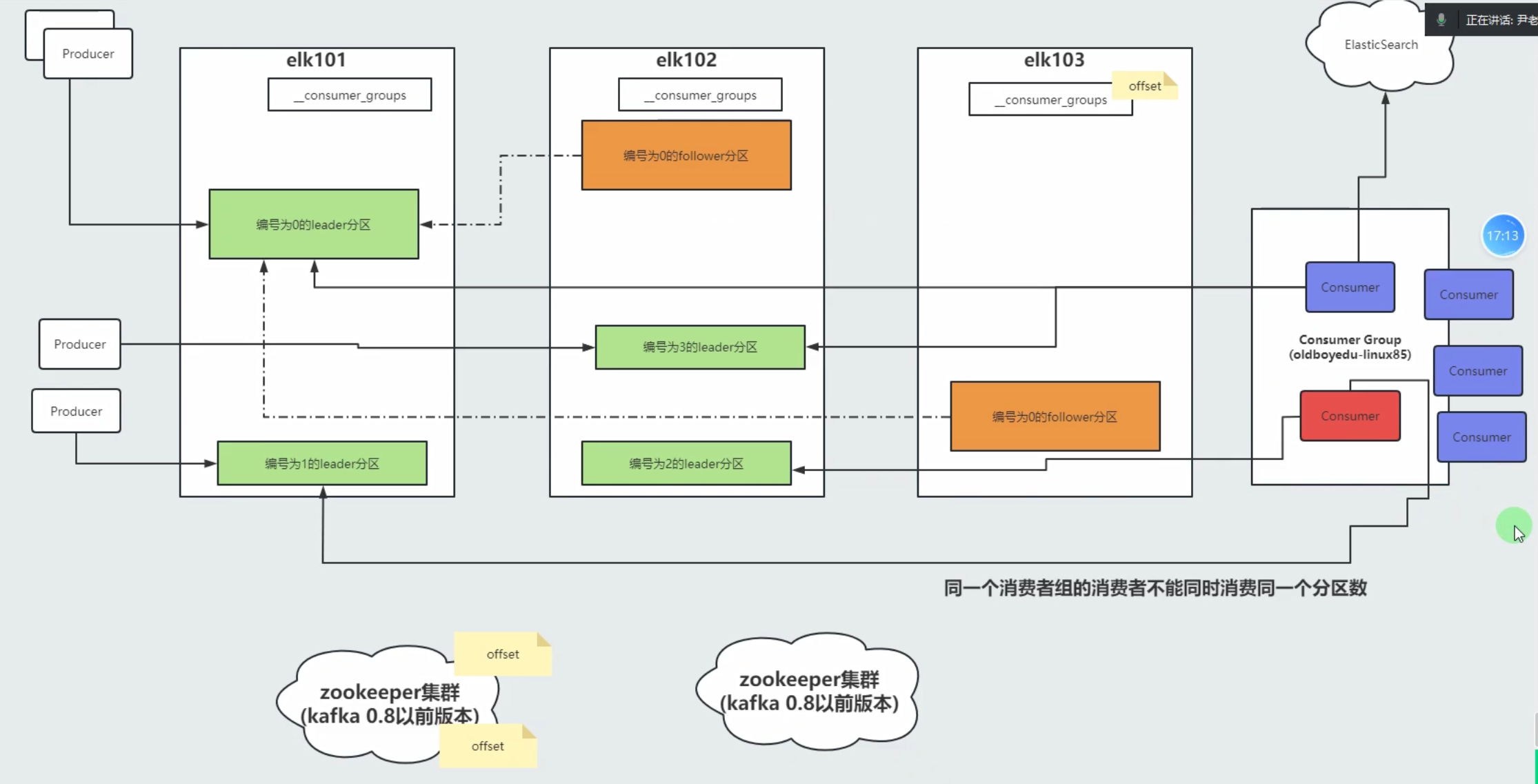
3、kafka的常用术语
bash
kafka cluster(broker list):
kafka集群。
kafka Server (broker):
指的是kafka集群的某个节点。
Producer:
生产者,即往kafka集群写入数据的角色。
Consumer:
消费者,即从kafka集群中读取数据的角色。一个消费者隶属于一个消费者组。
Concumer Group:
消费者组,里面有一个或多个消费者。
Topic:
主题,是一个逻辑概念,用于区分业务,一个主题最少要有1个分区和一个副本。
Partition:
分区,分区可以暂时理解为分区编号。
replica:
副本,副本是实际存储数据的地方,分为两种角色,即leader和follower。
leader:
负责读写。
follower:
负责从leader节点同步数据,无法对集群外部提供任何服务。当leader无法访问时,follower会接管leader的角色。
AR:
所有的副本,包含leader和follower副本。
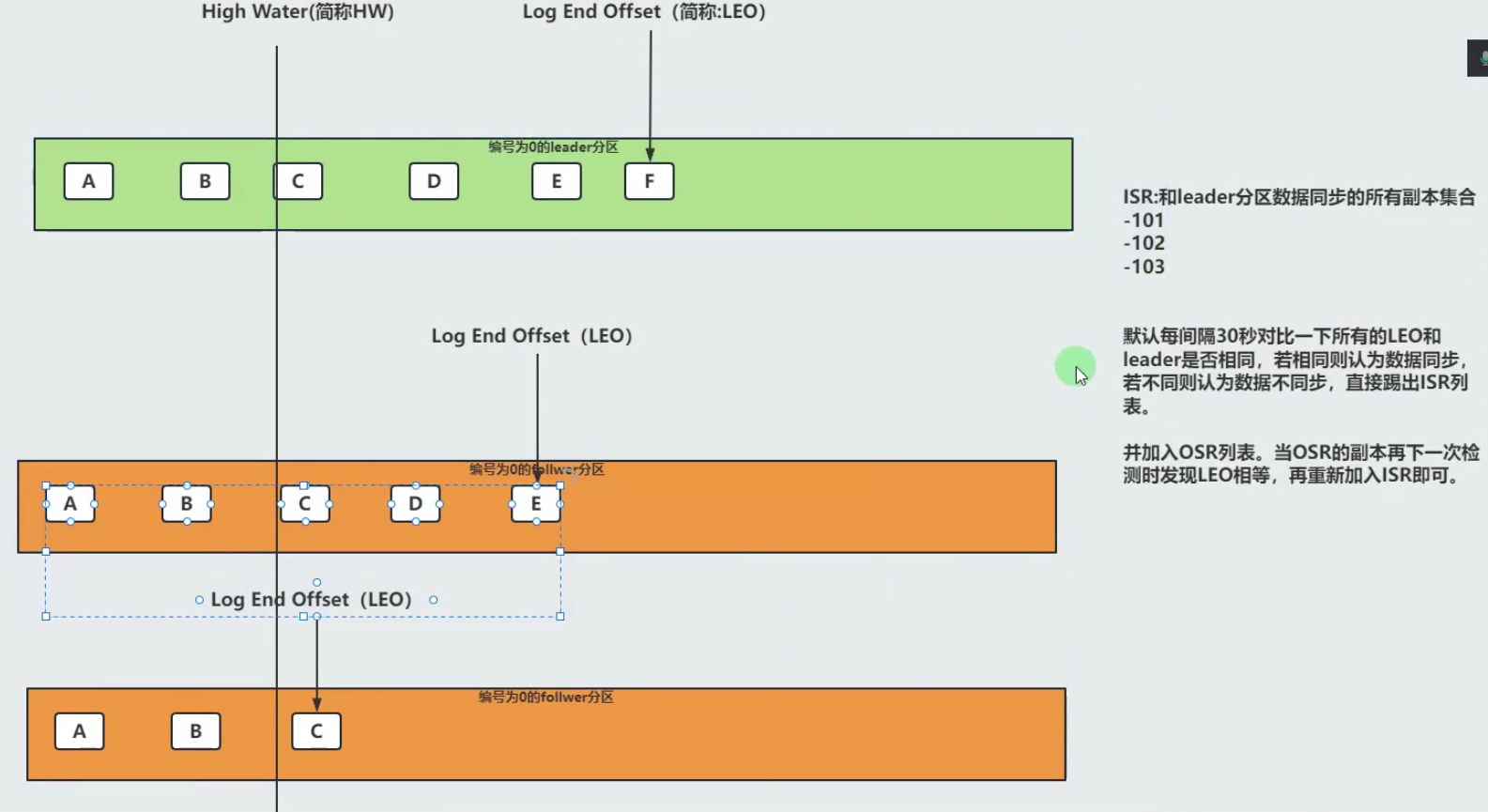
ISR:
表示和leader同步的所有副本集合。
OSR:
表示和leader不同步的所有副本即可。
zookeeper集群:
kafka 0.9之前的版本维护消费者组的offset,之后kafka内部的topic进行维护。
协调kafka的leader选举,控制器协调者选举等....client:
consumer API:
即消费者,指的是从boker拉取数据的角色。
每个消费者均隶属于一个消费者组(consumer Group),一个消费者组内可以有多个消费者。
producer API:
即生产者,指的是往broker写入数据的角色。
admin API:
集群管理的相关API,包括topic,parititon,replica等管理。
stream API:
数据流处理等API,提供给Spark,Flink,Storm分布式计算框架提供数据流管道。
connect API:
连接数据库相关的API,例如将MySQL导入到kafka。 常见问题:
Q1: 分区和副本有啥区别?
分区可以暂时理解为分区编号,它包含该分区编号的所有副本,和磁盘的分区没关系。
副本是实际存储数据的地方,
Q2: offset存储在kafka集群,客户端在kafka集群任意一个节点如何获取偏移量。
通过内部的消费者组的偏移量读取即可。("__consumer_offsets")
4、topic管理
- 查看topic
bash
# 查看topic列表,
[root@elk101.oldboyedu.com ~]# kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --list
# 查看指定topic的详细信息。
[root@elk101.oldboyedu.com ~]# kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --describe --topic oldboyedu-linux85
# 查看所有的topic详细信息。
[root@elk101.oldboyedu.com ~]# kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --describe - 创建topic
一个topic是生产者(producer)和消费者(consumer)进行逻辑的通信单元。
底层存储数据的是对应一个或多个分区(partition)副本(replica)。
bash
# 创建一个名为"oldboyedu-linux85",分区数为3,副本数量为2的topic。
[root@elk101.oldboyedu.com ~]# kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --create --partitions 3 --replication-factor 2 --topic oldboyedu-linux85
# 创建一个名为"oldboyedu-jiaoshi07",分区数为3,副本数量为2的topic。
[root@elk101.oldboyedu.com ~]# kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --create --partitions 3 --replication-factor 2 --topic oldboyedu-jiaoshi07- 修改topic(分区数量可以调大,但不可以调小!)
bash
[root@elk101.oldboyedu.com ~]# kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --alter --topic oldboyedu-linux85 --partitions 5- 刪除topic
bash
[root@elk101.oldboyedu.com ~]# kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --delete --topic oldboyedu-linux85 kafka关于修改副本数和分区的数的案例实战:
https://www.cnblogs.com/yinzhengjie/p/9808125.html
- 创建生产者
bash
[root@elk102.oldboyedu.com ~]# kafka-console-producer.sh --bootstrap-server 10.0.0.103:9092 --topic oldboyedu-jiaoshi07- 创建消费者
bash
[root@elk103.oldboyedu.com ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.102:9092 --topic oldboyedu-jiaoshi07 --from-beginning- 消费者组案例
bash
[root@elk103 ~]# vim /oldboyedu/softwares/kafka/config/consumer.properties
...
group.id=linux85
(1)创建topic
[root@elk103.oldboyedu.com ~]# kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --create --partitions 3 --replication-factor 2 --topic oldboyedu-jiaoshi03
(2)启动生产者
[root@elk102.oldboyedu.com ~]# kafka-console-producer.sh --bootstrap-server 10.0.0.103:9092 --topic oldboyedu-jiaoshi03
(3)启动消费者加入同一个消费者组
[root@elk101.oldboyedu.com ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.102:9092 --topic oldboyedu-jiaoshi03 --consumer-property group.id=linux85 --from-beginning
kafka-console-consumer.sh --bootstrap-server 10.0.0.102:9092 --topic oldboyedu-jiaoshi01 --consumer-property group.id=linux85 --from-beginning
[root@elk103.oldboyedu.com ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.102:9092 --topic oldboyedu-jiaoshi03 --consumer.config /oldboyedu/softwares/kafka/config/consumer.properties --from-beginning(4)测试
在生产者端写入数据,观察消费者的输出即可。
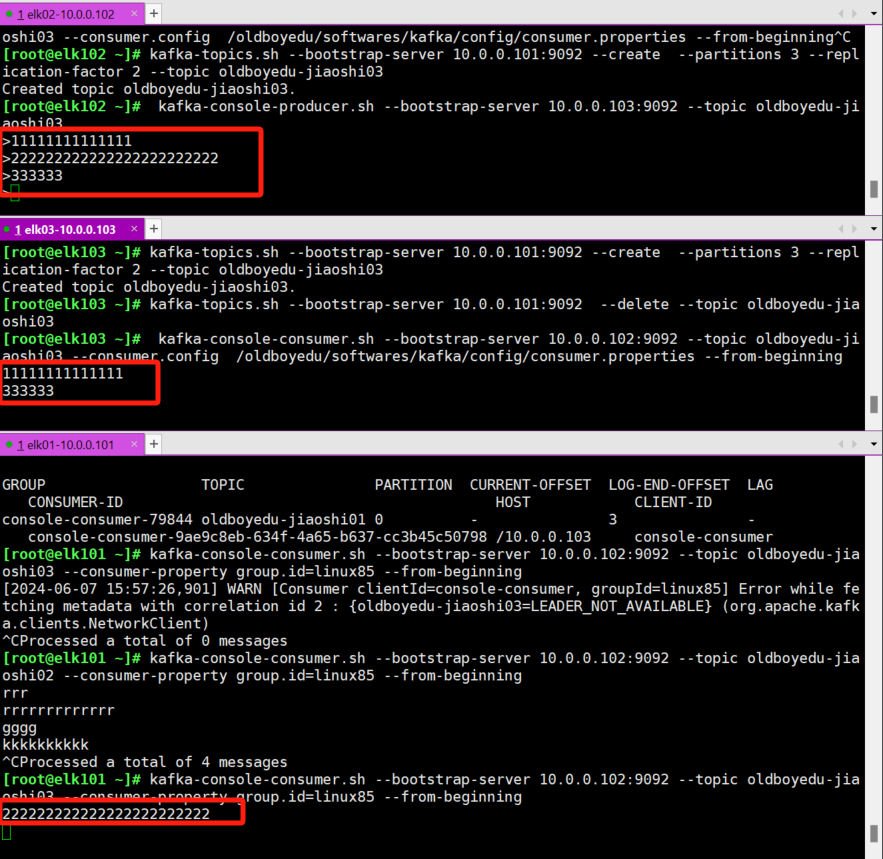
(5)观察消费者组的详细信息
bash
[root@elk101.oldboyedu.com ~]# kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --describe --group linux85
[root@elk101 ~]# kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --list
console-consumer-43305
console-consumer-7295
console-consumer-79844
[root@elk101 ~]# kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --describe --all-groups
Consumer group 'console-consumer-43305' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-7295 oldboyedu-jiaoshi01 0 - 3 - console-consumer-388fafbd-8e5e-4783-a771-60d490889de3 /10.0.0.103 console-consumer
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-79844 oldboyedu-jiaoshi01 0 - 3 - console-consumer-9ae9c8eb-634f-4a65-b637-cc3b45c50798 /10.0.0.103 console-consumer
彩蛋:
bash
查看内置的"__consumer_offsets "的数据:
[root@elk103.oldboyedu.com ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.101:9092 --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning | grep linux85
# kafka-server-start.sh
# kafka-server-stop.sh
# kafka-topics.sh
# kafka-console-producer.sh
# kafka-console-consumer.sh
# kafka-consumer-groups.sh5、kafka堆内存调优
(1)修改启动脚本
bash
[root@elk101.oldboyedu.com ~]# vim `which kafka-server-start.sh ` +28
...
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
...
# 将原有的注释掉
# export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_HEAP_OPTS="-server -Xmx256m -Xms256m -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="8888"
fi(2)同步集群启动脚本
bash
[root@elk101.oldboyedu.com ~]# data_rsync.sh `which kafka-server-start.sh `(3)重启kafka集群
bash
[root@elk101.oldboyedu.com ~]# kafka-server-stop.sh
[root@elk101.oldboyedu.com ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk102.oldboyedu.com ~]# kafka-server-stop.sh
[root@elk102.oldboyedu.com ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk103.oldboyedu.com ~]# kafka-server-stop.sh
[root@elk103.oldboyedu.com ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties (4)验证kafka集群的内存大小
bash
[root@elk101.oldboyedu.com ~]# jmap -heap `jps | awk '/Kafka/{print $1}'`
[root@elk102.oldboyedu.com ~]# jmap -heap `jps | awk '/Kafka/{print $1}'`
[root@elk103.oldboyedu.com ~]# jmap -heap `jps | awk '/Kafka/{print $1}'`6、kafka开源监控组件-kafka-eagle
- 启动kafka的JXM端口
(1)所有节点停止kafka
bash
kafka-server-stop.sh(2)所有节点修改kafka的配置文件
bash
vim `which kafka-server-start.sh`
...
# export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" # 注视掉该行,并将下面2行复制即可
export KAFKA_HEAP_OPTS="-server -Xmx256M -Xms256M -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="8888"(3)所有节点启动kafka服务
bash
kafka-server-start.sh -daemon /oldboyedu/softwares/kafka/config/server.properties - 启动zookeeper的JMX端口
(1)修改配置文件
bash
[root@elk101.oldboyedu.com ~]# vim /oldboyedu/softwares/zk/conf/zoo.cfg
# 添加下面的一行,启动zk的4字监控命令
4lw.commands.whitelist=*(2)修改zk的启动脚本
bash
[root@elk101.oldboyedu.com ~]# vim /oldboyedu/softwares/zk/bin/zkServer.sh +77
...
# 如果修改上面的方式不生效,则需修改zkServer.sh脚本中77行之后ZOOMAIN的值即可。
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"(3)修改环境变量开启JMX
bash
[root@elk101.oldboyedu.com ~]# vim /oldboyedu/softwares/zk/bin/zkEnv.sh
...
JMXLOCALONLY=false
JMXPORT=21812
JMXSSL=false
JMXLOG4J=false(4)同步脚本
bash
[root@elk101.oldboyedu.com ~]# data_rsync.sh /oldboyedu/softwares/zk/bin/zkServer.sh
[root@elk101.oldboyedu.com ~]# data_rsync.sh /oldboyedu/softwares/zk/bin/zkEnv.sh (5)使用jconsole验证是否能连接JMX端口
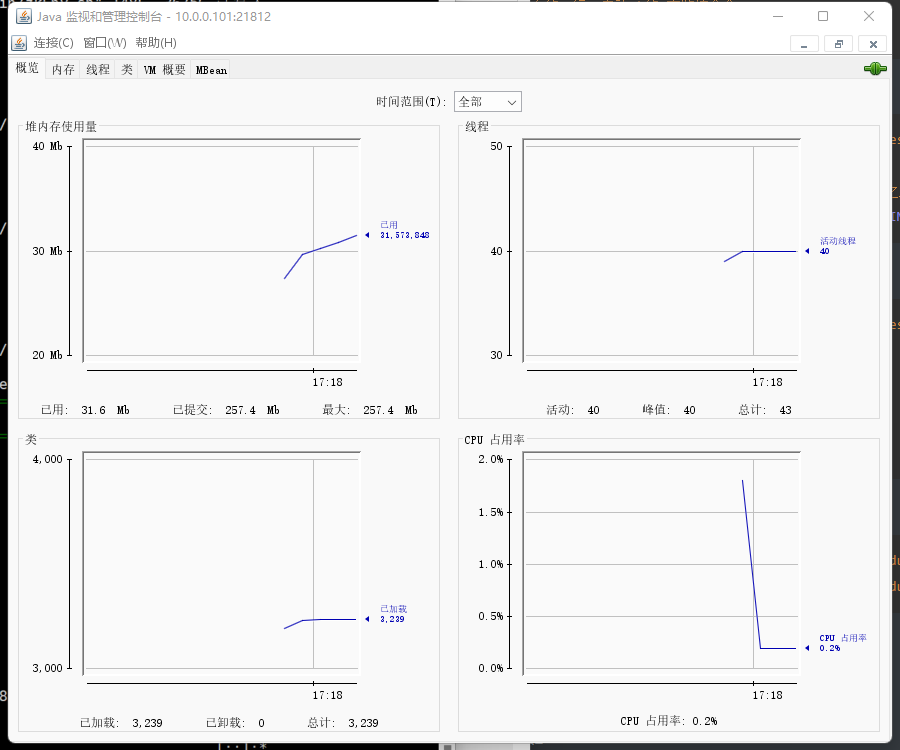
- 安装MySQL
(1)安装mariadb
bash
[root@elk101.oldboyedu.com ~]# yum -y install mariadb-server(2)配置mariadb的配置文件
bash
[root@elk101 ~]# vim /etc/my.cnf
[mysqld]
...
# 关闭MySQL的反向解析功能
skip-name-resolve=1(2)启动服务并设置开机自启动
bash
[root@elk101.oldboyedu.com ~]# systemctl enable mariadb --now(3)创建数据库
bash
[root@elk101.oldboyedu.com ~]# mysql
...
CREATE DATABASE oldboyedu_kafka DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;4)创建授权用户
bash
CREATE USER admin IDENTIFIED BY 'oldboyedu';
GRANT ALL ON oldboyedu_kafka.* TO admin;
SHOW GRANTS FOR admin;(5)测试用户
bash
mysql -u admin -poldboyedu -h 10.0.0.101- 部署kafka-eagle监控
(1)下载kafka-eagle软件
bash
[root@elk101.oldboyedu.com ~]# wget http://192.168.15.253/ElasticStack/day08-/softwares/kafka-eagle-bin-2.0.8.zip(2)解压软件包
bash
[root@elk101.oldboyedu.com ~]# unzip kafka-eagle-bin-2.0.8.zip
[root@elk101.oldboyedu.com ~]# tar xf efak-web-2.0.8-bin.tar.gz -C /oldboyedu/softwares/(3)修改配置文件
bash
[root@elk101.oldboyedu.com ~]# yy /oldboyedu/softwares/efak-web-2.0.8/conf/system-config.properties
...
efak.zk.cluster.alias=oldboyedu-linux85
oldboyedu-linux85.zk.list=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181/oldboyedu-linux85-kafka321
oldboyedu-linux85.efak.broker.size=20
kafka.zk.limit.size=32
efak.webui.port=8048
oldboyedu-linux85.efak.offset.storage=kafka
oldboyedu-linux85.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
efak.metrics.charts=true
efak.metrics.retain=15
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
efak.topic.token=oldboyedu
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://10.0.0.101:3306/oldboyedu_kafka?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=admin
efak.password=oldboyedu
[root@elk101.oldboyedu.com ~]# (4)配置环境变量
bash
cat >> /etc/profile.d/kafka.sh <<'EOF'
export KE_HOME=/oldboyedu/softwares/efak-web-2.0.8
export PATH=$PATH:$KE_HOME/bin
EOF
source /etc/profile.d/kafka.sh(5)修改堆内存大小
bash
[root@elk101.oldboyedu.com ~]# vim `which ke.sh `
...
export KE_JAVA_OPTS="-server -Xmx256m -Xms256m -XX:MaxGCPauseMillis=20 -XX:+UseG1GC -XX:MetaspaceSize=128m -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"(6)启动服务
bash
[root@elk101.oldboyedu.com ~]# ke.sh start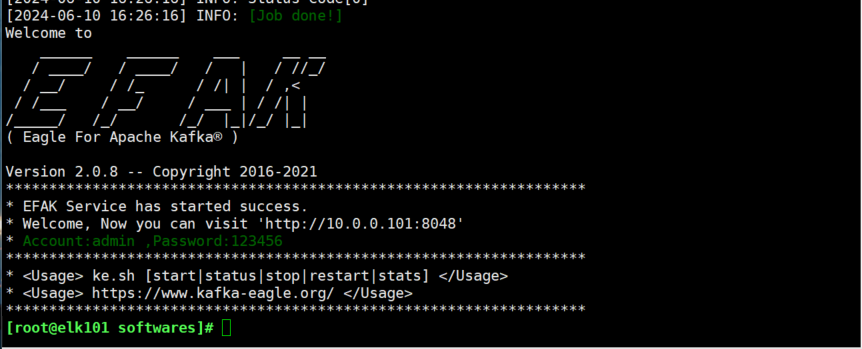
账号:admin 密码:123456
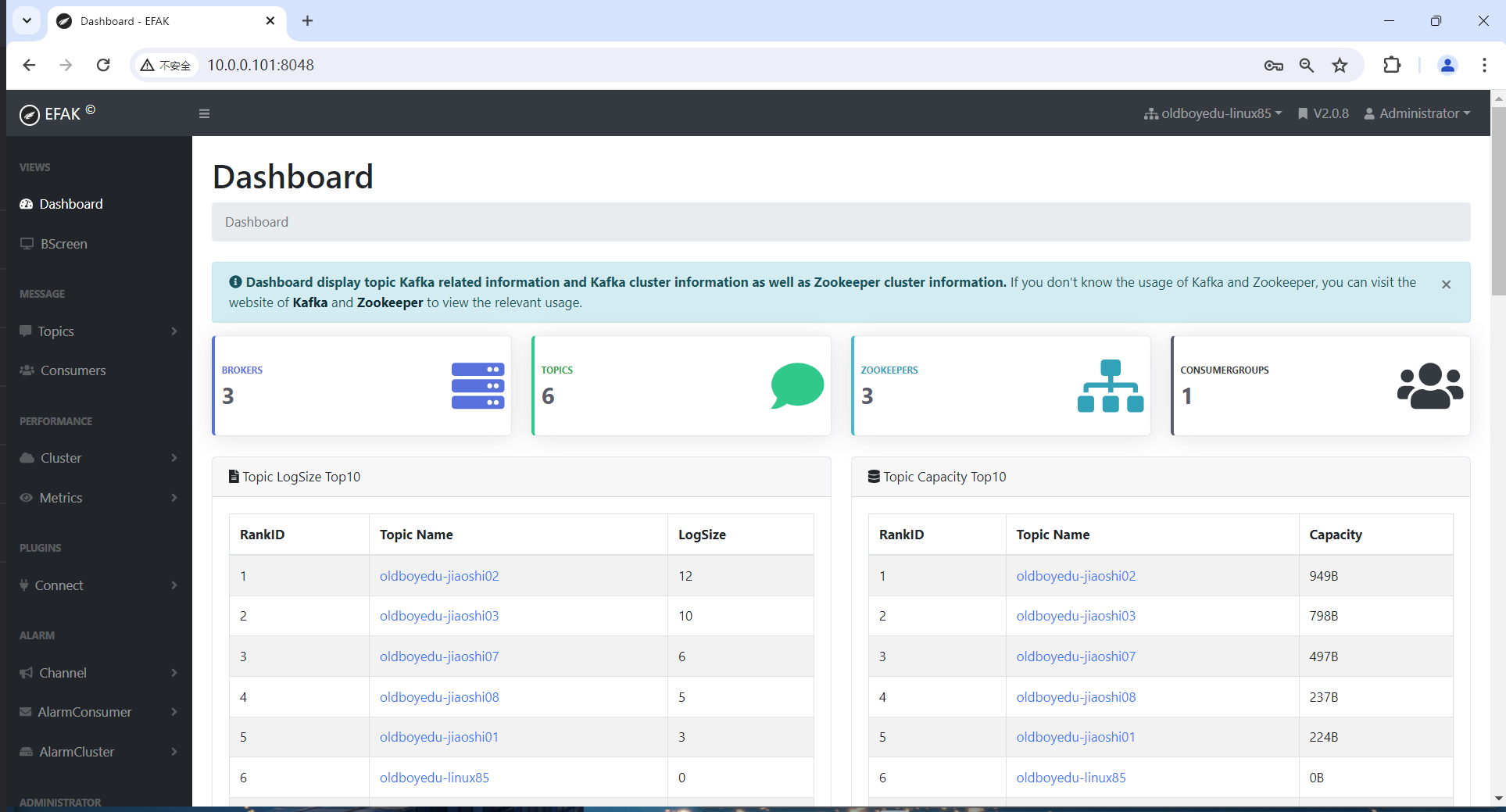
7、kafka集群压力测试
7.1 什么叫压力测试
在软件工程中,压力测试是对系统不断施加压力的测试,是通过确定一个系统的瓶颈或者不能接收的性能点,来获得系统能提供的最大服务级别的测试。
简单来说,所谓压力测试就是对一个集群的处理能力的上限做一个评估。为将来集群扩容提供有效的依据。
7.2 为什么要进行压力测试
(1)压力测试可以了解当前集群的处理能力上限;
(2)当修改集群的配置参数后,压力测试可以协助运维人员去参考本次调优的效果;
(3)压力测试的结果以后可以作为参考扩容集群的有效依据;
7.3 实战案例
bash
install -d /tmp/kafka-test/
cat >oldboyedu-kafka-test.sh <<'EOF'
# 创建topic
kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102.9092,10.0.0.103:9092 --topic oldboyedu-kafka-2022 --replication-factor 1 --partitions 10 --create
# 启动消费者消费数据
nohup kafka-consumer-perf-test.sh --broker-list 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic
oldboyedu-kafka-2022 --messages 100000000 &>/tmp/kafka-test/oldboyedu-kafka-consumer.log &
#启动生产者写入数据
nohup kafka-producer-perf-test.sh --num-records 100000000 --record-size 1000 --topic oldboyedu-kafka-2022 --throughput 1000000 --producer-props bootstrap.servers=10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 &>/tmp/kafka-test/oldboyedu-kafka-producer.log &
EOF
bash oldboyedu-kafka-test.sh
参数说明:
kafka-consumer-perf-test.sh
---messages:
指定消费消息的数量。
--broker-list:
指定broker列表。
--topic:
指定topic主体。
kafka-producer-perf-test.sh
-num-records
生产消息的数量,
--record-size:
每条消息的大小,单位是字节。
--topic:
指定topic主体。
--throughput
设置每秒发送的消息数量,即指定最大消息的吞吐量,若设置为-1代表不限制!
--producer-props
bootstrap.servers指定broker列表。
温馨提示:
本案例测试大约会生成93GB( echo "100000000*1000/1024/1024/1024"|bc)的数据,如果硬盘资源不足的小伙伴可以暂时不用测试了,或者改小上面提到的参数。7.4 kafka生产环节测试截图
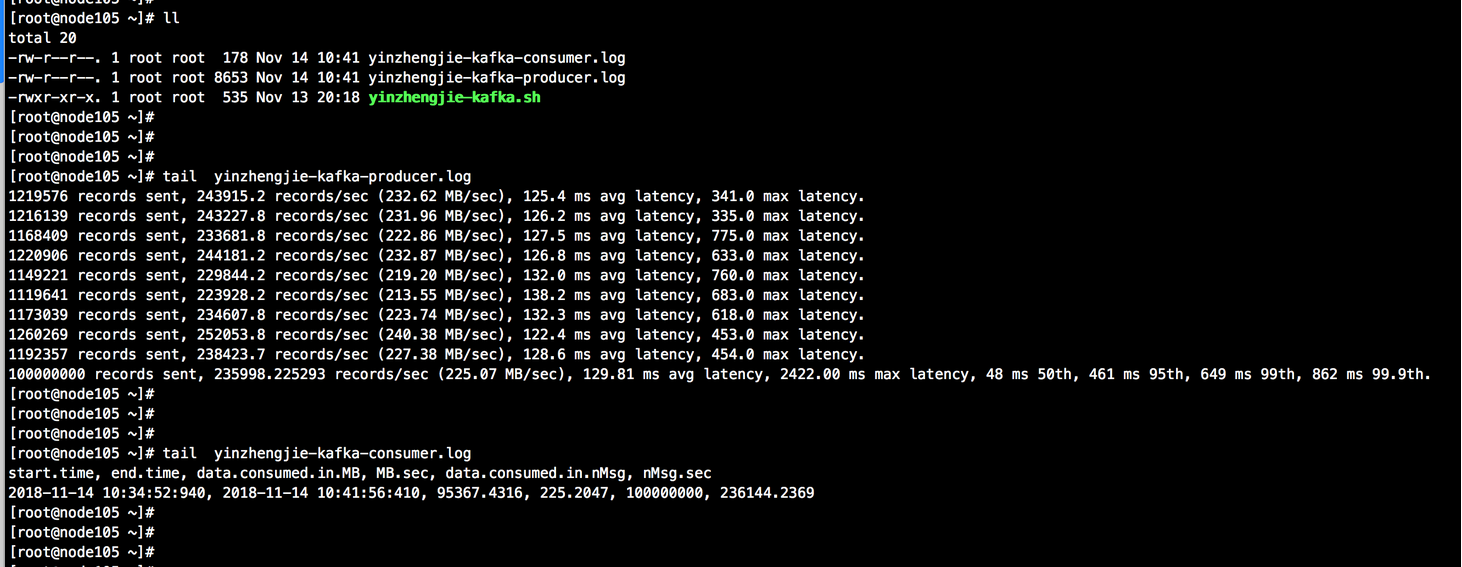
bash
生产端:
总共需要发送的消息数:1亿条,每个记录的字节数是:1000字节,每秒钟发送的记录数是:1000000
消费端:
模拟了10个消费者:进行消费
指定每次fetch的数据的大小:1M
总共要消费的消息个数:1亿条
生产端结论:
1>.每秒平均向kafka写入了225.07 MB的数据;
2>.每次写入的平均延迟为 129.81毫秒;
3>.最大延迟为2422.00毫秒;
消费端结论:
1>. 共消费了95367.4316M的数据;
2>.消费速度为225.2047M/s;
3>.总共消费了1亿条消息;
4>.每秒消费236144.2369条消息;
参考链接:
https://www.cnblogs.com/yinzhengjie/p/9953212.html7.5 压力测试注意点
如下图所示,压测试需要注意以下几点:
(1)根据公司的架构来调整咱们的生产者和消费者所在的环境;
(2)专线带宽需要实时监控,不能因为测试把正常业务的数据因打满带宽而导致数据丢失;
(3)测试时尽量选择在业务低峰期去操作,不建议在业务高峰期做:
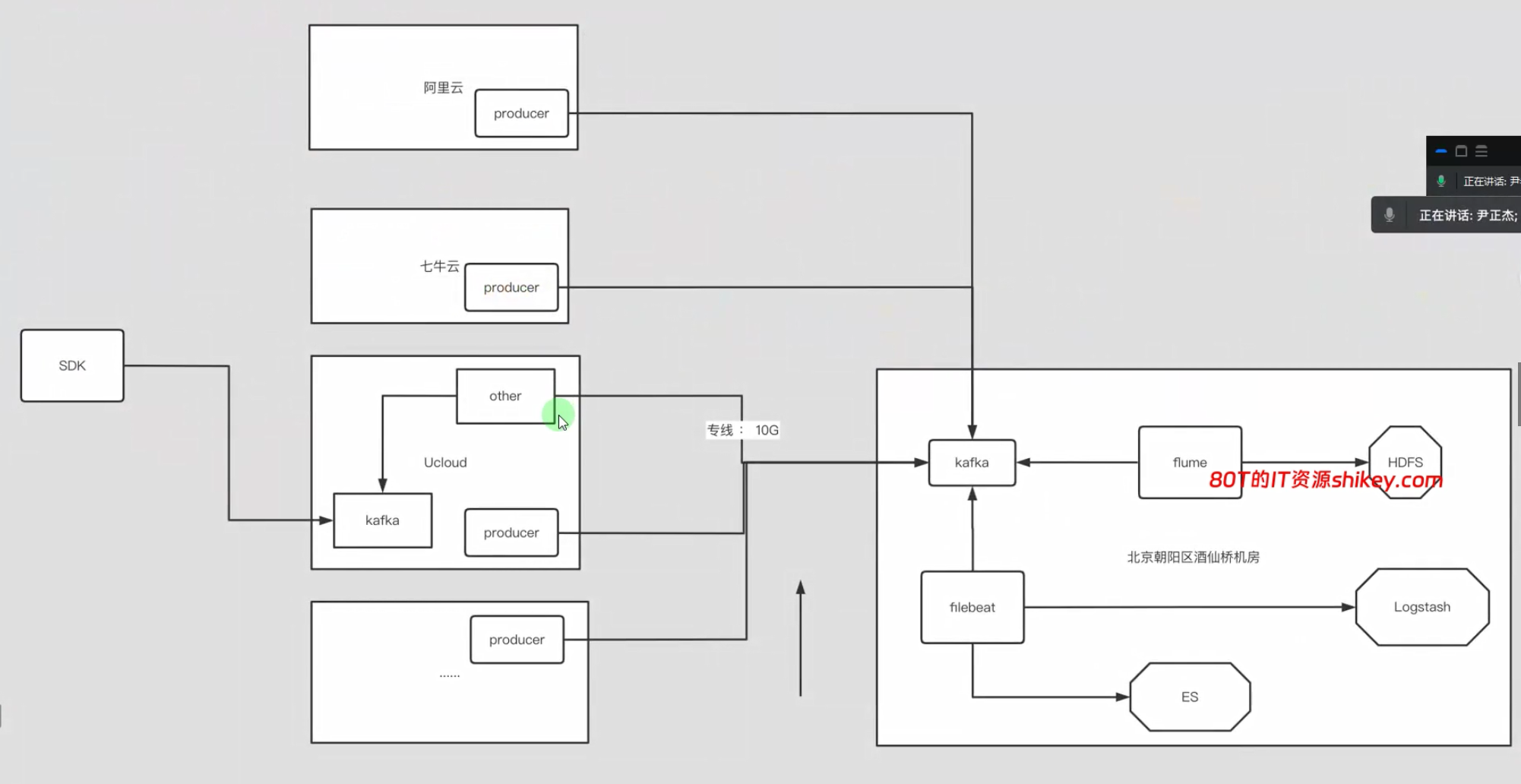
8、kafka优化
broker优化
bash
#################################### Server Basics ###############################################
#每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
broker.id=116
#这就是说,这条命令其实并不执行删除动作,仅仅是在zookeeper上标记该topic要被删除而已,同时也提醒用户一定要提前打开delete.topic.enable开关,否则删除动作是不会执行的。
delete.topic.enable=true
#是否允许自动创建topic,若是false,就需要通过命令创建topic
auto.create.topics.enable=false
########################## Socket Server Settings #########################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners =listener_name://host_name:port
# EXAMPLE:
# listeners =PLAINTEXT://your.host.name:9092
#Socket服务器侦听的地址。如果没有配置,它将获得从Java.NET.InAddio.GETCANONICALITHAMEMENE()返回的值
#listeners=PLAINTEXT://10.1.3.116:9092
#broker server服务端口
port=9092
#broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接口上,并将其中之一发送到ZK,一般不设置
host.name=10.1.3.116
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. otherwise, it will use the value
# returned from java.net.InetAddress.getcanonicalHostName()
#kafka 0.9.x以后的版本新增了advertised.listeners配置,kafka 0.9.x以后的版本不要使用 advertised.host.name 和advertised.host.port 已经deprecated.如果配置的话,它使用"listeners"的值。否则,它将使用从java.net.InetAddress.getcanonicalHostName()返回的值。
#advertised.listeners=PLAINTEXT://your.host.name:9092
#将侦听器(listener)名称映射到安全协议,默认情况下它们是相同的。有关详细信息,请参阅配置文档。#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
#处理网络请求的最大线程数
num.network.threads=30
#处理磁盘I/0的线程数
num.io.threads=30
#套接字服务器使用的发送缓冲区(SOYSNDBUF)
socket.send.buffer.bytes=5242880
#套接字服务器使用的接收缓冲区(SOYRCVBUF)
socket.receive.buffer.bytes=5242880
#套接字服务器将接受的请求的最大大小(对OOM的保护)
socket.request.max.bytes=104857600
#I/0线程等待队列中的最大的请求数,超过这个数量,network线程就不会再接收一个新的请求。应该是一种自我保护机制。
queued.max.requests=1000
############################### Log Basics ################################
#日志存放目录,多个目录使用逗号分割,如果你有多块磁盘,建议配置成多个目录,从而达到I/0的效率的提升。
log.dirs=/home/oldhoyedu/kafka/logs,/home/oldboyedu/kafka/1ogs2,/home/oldboyedu/kafka/logs3
#每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖
# num.partitions=20
# 默认副本数
# default.replication.factor=2
#在启动时恢复日志和关闭时刷盘日志时每个数据目录的线程的数量,默认1
num.recovery.threads.per.data.dir=32
#服务器接受单个消息的最大大小,即消息体的最大大小,单位是字节,下面是100MB
message.max.bytes=104857600
# 自动负载均衡,如果设为true,复制控制器会周期性的自动尝试,为所有的broker的每个partition平衡leadership,为更优先(preferred)#的replica分配leadership。
auto.leader.rebalance.enable=true
############################# Log Flush Policy ###############################
#在强制fsync一个partition的log文件之前暂存的消息数量。调低这个值会更领繁的sync数据到磁盘,影响性能。通常建议人家使用replication来确保持久性,而不是依靠单机上的fsync,但是这可以带来更多的可靠性,默认10000.
#log.flush.interval.messages=10000
#2次fsync调用之间最大的时间间隔,单位为ms。即使log.flush.interval.messages没有达到,只要这个时间到了也需要调用fsync。默认3000ms.
#log.flush.interval.ms=10000
################################## Log Retention Policy ####################################
#日志保存时间(hours|minutes),默认为7天(168小时)。超过这个时间会根据policy处理数据。hours和minutes无论哪个先达到都会触发。
log.retention.hours=168
#日志数据存储的最大字节数。超过这个时间会根据po1icy处理数据。
#log.retention.bytes=1073741824
#控制日志segment文件的大小,超出该大小则追加到一个新的日志segment文件中(-1表示没有限制)
log.segment.bytes=536870912
#当达到下面时间,会强制新建一个segment
#log.roll.hours = 24*7
#日志片段文件的检查周期,查看它们是否达到了删除策略的设置(log.retention.hours或log.retention.bytes)
log.retention.check.interval.ms=600000
#是否开启压缩
#log.cleaner.enable=false
#日志清理策略选择有:delete和compact主要针对过期数据的处理,或是日志文件达到限制的额度,会被topic创建时的指定参数覆盖
#log.cleanup.policy=delete
#日志压缩运行的线程数
#log.cleaner.threads=2
# 压缩的日志保留的最长时间
#log.cleaner.delete.retention.ms=3600000
############################### Zookeeper ########################################
#zookeeper集群的地址,可以是多个,多个之间用逗号分割,生产环境中,建议配置chroot目录
zookeeper.connect=10.1.3.117:2181,10.1.3.118:2181,10.1.3.119:2181/oldboyedu-kafka300
#zooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大
zookeeper.session.timeout.ms=180000
#指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息,连接zk的超时时间
zookeeper.connection.timeout.ms=6000
#请求的最大大小为字节,请求的最大字节数。这也是对最大记录尺寸的有效覆盖。注意:server具有自己对消息记录尺寸的覆盖,这些尺寸和这个设置不同。此项设置将会限制producer每次批量发送请求的数目,以防发出巨量的请求。
max.request.size=104857600
#每次fetch请求中,针对每次fetch消息的最大字节数。这些字节将会督导用于每个partition的内存中,因此,此设置将会控制consumer所使用的memory大小。这个fetch请求尺寸必须至少和server允许的最大消息尺寸相等,否则,producer可能发送的消息尺寸大于consumer所能消耗的尺寸。
fetch.message.max.bytes=104857600
#zooKeeper集群中leader和follower之间的同步时间,换句话说:一个zK fo11ower能落后leader多久。
#zookeeper.sync.time.ms=2000
################################## Replica Basics #########################################
# leader接收follower的"fetch请求"的超时时间,默认是10秒。
# replica.lag.time.max.ms=30000
# 如果relicas落后太多,将会认为此partition relicas已经失效。而一般情况下,因为网络延迟等原因,总会导致replicas中消息同步滞后。如果消息严重滞后,leader将认为此relicas网络延迟较大或者消息吞吐能力有限。在broker数量较少,或者网络不足的环境中,建议提高此值.follower落后于leader的最大message数,这个参数是broker全局的。设置太大了,影响真正"落后"follower的移除;设置的太小了,导致follower的频繁进出。无法给定一个合适的replica.lag.max.messages的值,因此不推荐使用,据说新版本的Kafka移除了这个参数。#replica.lag.max.messages=4000
#follower与leader之间的socket超时时间
#replica.socket.timeout.ms=30000
# follower每次fetch数据的最大尺寸
replica.fetch.max.bytes=104857600
# follower的fetch请求超时重发时间
replica.fetch.wait.max.ms=2000
# fetch的最小数据尺寸
#replica.fetch.min.bytes=1
#是否允许控制器关闭broker,默认值为true,它会关团所有在这个broker上的leader,并转移到其他broker,建议启用,增加集群稳定性。
# controlled.shutdown.enable = false
#0.11.0.0版本开始unclean.leader.election.enable参数的默认值由原来的true改为fa1se,可以关闭unclean leader election,也就是不在ISR(IN-Sync Replica)列表中的replica,不会被提升为新的leader partition。kafka集群的持久化力大于可用性,如果ISR中没有其它的replica,会导致这个partition不能读写。
unclean.leader.election=false
# follower中开启的fetcher线程数,同步速度与系统负载均衡
num.replica.fetchers=5
# partition leader与replicas之间通讯时,socket的超时时间
#controller.socket.timeout.ms=30000
# partition leader与replicas数据同步时,消息的队列尺寸
#controller.message.queue.size=10
#指定将使用哪个版本的 inter-broker 协议。 在所有经纪人升级到新版本之后,这通常会受到冲击。升级时要设置
#inter.broker.protocol.version=0.10.1
#指定broker将用于将消息添加到日志文件的消息格式版本。该值应该是有效的Apiversion。一些例子是:0.8.2,0.9.0.0,0.10.0。通过设置特定的消息格式版本,用户保证磁盘上的所有现有消息都小于或等于指定的版本。 不正确地设置这个值将导致使用旧版本的用户出错,因为他们将接收到他们不理解的格式的消息。
#log.message.format.version=0.10.1
温馨提示:
生产环境中请一定要弄清楚参数的含义,然后在配置,配置后重启集群时请不要批量重启,要滚动重启!
推荐阅读:
https://kafka.apache.org/documentation/#configuration9、filebeat将数据写入到Kafka实战
bash
[root@elk103.oldboyedu.com filebeat-7.17.5-linux-x86_64]# cat config/25-stdin-to-kafka.yaml
filebeat.inputs:
- type: stdin
# 将数据输出到kafka
output.kafka:
# 指定kafka主机列表
hosts:
- 10.0.0.101:9092
- 10.0.0.102:9092
- 10.0.0.103:9092
# 指定kafka的topic
topic: "oldboyedu-linux85-kafka"
[root@elk103.oldboyedu.com filebeat-7.17.5-linux-x86_64]#
[root@elk103.oldboyedu.com filebeat-7.17.5-linux-x86_64]# ./filebeat -e -c config/25-stdin-to-kafka.yaml
# 查看
[root@elk101 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.102:9092 --topic oldboyedu-linux85-kafka --from-beginning
{"@timestamp":"2024-06-10T09:40:37.364Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.17.5"},"host":{"name":"elk103.oldboyedu.com"},"agent":{"version":"7.17.5","hostname":"elk103.oldboyedu.com","ephemeral_id":"24af5d8c-aaa8-4552-ad29-cb085e3367da","id":"eb4646e6-59e9-4aa8-a54d-3bbd11132ce8","name":"elk103.oldboyedu.com","type":"filebeat"},"log":{"offset":0,"file":{"path":""}},"message":"111111111111111","input":{"type":"stdin"},"ecs":{"version":"1.12.0"}}
{"@timestamp":"2024-06-10T09:40:39.688Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.17.5"},"message":"2222222222222222222","log":{"offset":0,"file":{"path":""}},"input":{"type":"stdin"},"host":{"name":"elk103.oldboyedu.com"},"agent":{"id":"eb4646e6-59e9-4aa8-a54d-3bbd11132ce8","name":"elk103.oldboyedu.com","type":"filebeat","version":"7.17.5","hostname":"elk103.oldboyedu.com","ephemeral_id":"24af5d8c-aaa8-4552-ad29-cb085e3367da"},"ecs":{"version":"1.12.0"}}
{"@timestamp":"2024-06-10T09:40:42.619Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.17.5"},"ecs":{"version":"1.12.0"},"host":{"name":"elk103.oldboyedu.com"},"agent":{"id":"eb4646e6-59e9-4aa8-a54d-3bbd11132ce8","name":"elk103.oldboyedu.com","type":"filebeat","version":"7.17.5","hostname":"elk103.oldboyedu.com","ephemeral_id":"24af5d8c-aaa8-4552-ad29-cb085e3367da"},"log":{"offset":0,"file":{"path":""}},"message":"33333333333333333333333333","input":{"type":"stdin"}}10、logstash从kafka拉取数据并解析json格式案例
bash
[root@elk101.oldboyedu.com ~]# cat config/17-kafka-to-stdout.conf
input {
kafka {
# 指定kafka集群地址
bootstrap_servers => "10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092"
# 指定消费的topic
topics => ["oldboyedu-linux85-kafka"]
# 指定消费者组
group_id => "oldboyedu-linux85-demo04"
# 指定消费的偏移量,"earliest"表示从头读取数据,"latest"表示从最新的位置读取数据.
auto_offset_reset => "earliest"
}
}
filter {
json {
# 对指定字段进行json格式解析。
source => "message"
}
mutate {
remove_field => [ "agent","log","input","host","ecs","tags" ]
}
}
output {
stdout {}
}
[root@elk101.oldboyedu.com ~]# 今日作业:
(1)完成课堂的所有练习并整理思维导图;
(2)使用zabbix监控zookeeper和kafka集群;
明日环境准备:
(1)主机集群地址:
bash
10.0.0.231 k8s231.oldboyedu.com
10.0.0.232 k8s232.oldboyedu.com
10.0.0.233 k8s233.oldboyedu.com(2)配置说明如下
内存:4G
CPU:2C
DISK:20G+
(3)准备一台harbor服务器(1c2G足以)
要求是使用https认证。服务器地址为: "https://habor.oldboyedu.com"
扩展作业:
(1)使用ansible一键构建zookeeper和kafka集群;
(2)使用docker一键构建elasticstack架构体系,要求镜像命名规则如下:
bash
- oldboyedu-es:v0.1
- oldboyedu-logstash:v0.1
- oldboyedu-filebeat:v0.1
- oldboyedu-kibana:v0.1
- oldboyedu-zookeeper:v0.1
- oldboyedu-kafka:v0.1使用docker-compose一键构建即可。
bash
# 查看自定义网络
[root@elk103.oldboyedu.com ~]# docker network ls
# 创建自定义网络
[root@elk103.oldboyedu.com ~]# docker network create oldboyedu-linux85
# 查看自定义网络的详细信息。
[root@elk103.oldboyedu.com ~]# docker network inspect oldboyedu-linux85
# 创建网络时,可以自定义网段,分配容器的网段地址及网关地址。
[root@elk103.oldboyedu.com ~]# docker network create --subnet 172.31.0.0/16 --ip-range 172.31.200.0/24 --gateway 172.31.0.254 test02
# 启动容器时指定自定义网络。
[root@elk103.oldboyedu.com ~]# docker run --network test02 --rm --name myweb -d nginx:1.22.1-alpine
参考链接:
https://gitee.com/jasonyin2020/docker-compose/tree/master