在企业级应用中,Elasticsearch 常常被用来处理复杂的数据查询和操作。
Painless 是 Elasticsearch 的内置脚本语言,虽然强大,但调试起来并不容易。
本文将详细介绍如何在实战中有效调试 Painless 脚本,以提高开发和运维效率。
本文所有实现均在 Elasticsearch 8.11 dev-tool 环境充分验证,建议放大图片查看结果。
1、 抛出问题
在使用 Elasticsearch 的过程中,咱们开发者经常需要编写和调试 Painless 脚本,例如在查询、更新文档或定义复杂的预处理条件时。
由于 Painless 没有 REPL 环境(实时代码测试工具),调试嵌入在 Elasticsearch 中的脚本变得更加困难。
开发者无法直接在交互式环境中输入和测试 Painless 脚本,必须依赖诸如 Kibana 的 Painless Lab 或其他工具来间接调试和验证脚本。
这增加了调试的复杂性和开发周期。
2、脚本调试方式分类
通过大量的调研工作,其实核心就分两类。
2.1 调试方案 1:Elasticsearch Debug.Explain 调试
Painless 提供的调试工具,可以在脚本中插入 Debug.explain 方法,通过抛出异常的方式输出变量信息。
参见官网:https://www.elastic.co/guide/en/elasticsearch/painless/current/painless-debugging.html
2.2 调试方案 2:Kibana Painless Lab 工具调试
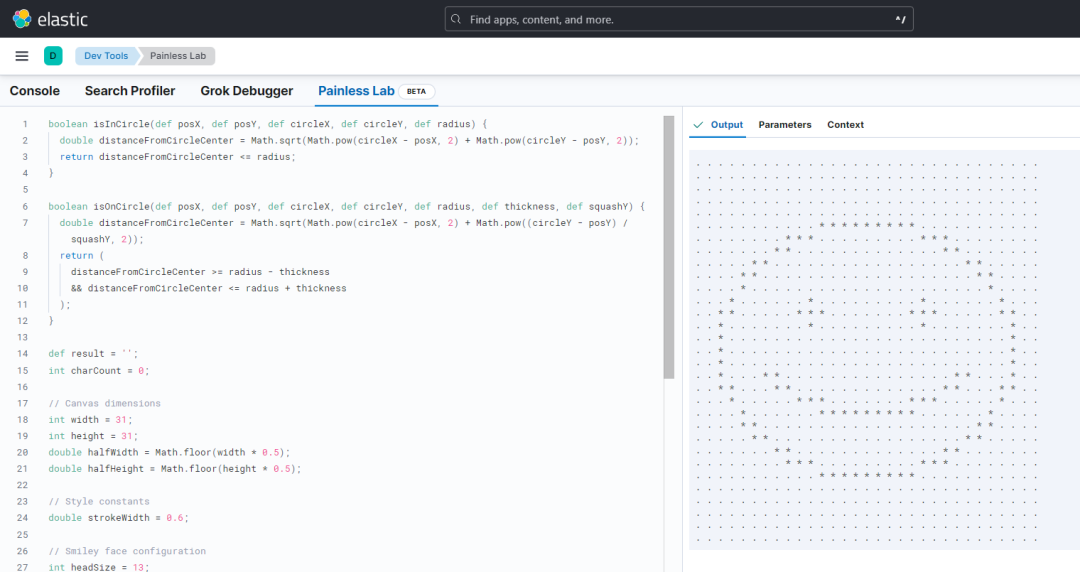
Elasticsearch 7.13 引入的实验性功能 Painless Lab,是一个交互式代码编辑器,可以实时测试和调试 Painless 脚本。
参见如下图,相信你和我一样,看过这幅图,但没有真正用过。下一篇我们多花笔墨解读这一部分的用法。
3、Debug.Explain 调试实战案例
依然以官方示例作为范例解读,参见:
3.1 官方样例解读
假设我们有一个包含球员数据的索引,文档如下:
go
DELETE hockey
PUT /hockey/_doc/1?refresh
{
"first": "johnny",
"last": "gaudreau",
"goals": [9, 27, 1],
"assists": [17, 46, 0],
"gp": [26, 82, 1]
}我们可以使用以下脚本来查看 goals 字段的类型:
go
POST /hockey/_explain/1
{
"query": {
"script": {
"script": "Debug.explain(doc.goals)"
}
}
}执行结果如下:
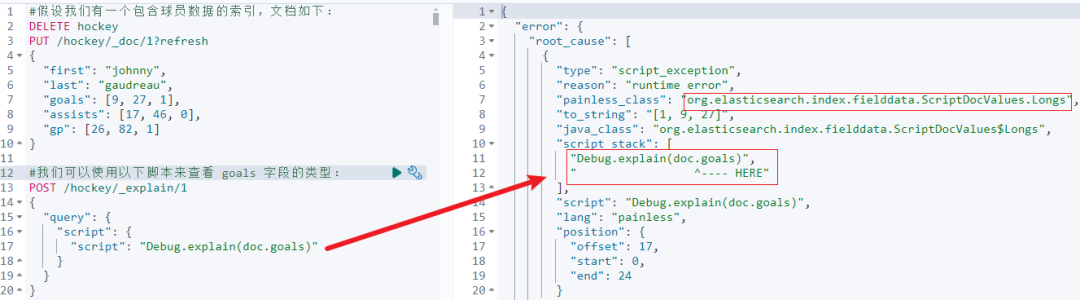
当看到上面一堆输出的时候,相信你和我的表情一致:"这是啥?"、"错了吧?"、"就这"......

结合上文定义:"通过抛出异常的方式输出变量信息",本质上是抛出异常了。
3.2 延伸详细解读
我们一点点剖析一下,如下内容官网没有提供。
我们使用脚本的本质,我延展一下:
3.2.1 脚本过滤检索
go
POST /hockey/_search
{
"query": {
"bool": {
"filter": {
"script": {
"script": """
def goals = doc['goals'];
// 计算总和
def sum = 0;
for (def goal : goals) {
sum += goal;
}
return sum > 30;
"""
}
}
}
}
}过滤查询出总和大于 30 的数据。结果符合预期,如下图所示:
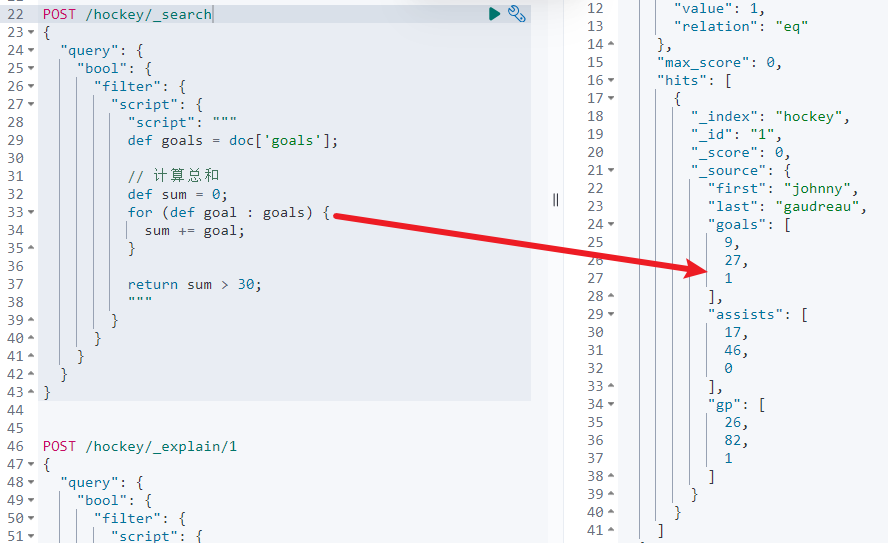
那,如何调试呢?
3.2.2 explain API 调试文档是否满足条件
极简单的方式,可以借助:explain 解读。也就是说:使用 _explain API 来探究并调试一个脚本查询。
细节参见:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-explain.html
执行命令如下:
go
POST /hockey/_explain/1
{
"query": {
"bool": {
"filter": {
"script": {
"script": """
def goals = doc['goals'];
//Debug.explain(goals);
// 计算总和
def sum = 0;
for (def goal : goals) {
sum += goal;
}
return sum > 30;
"""
}
}
}
}
}之前咱们讲过 explain 可以详尽展开评分计算细节。
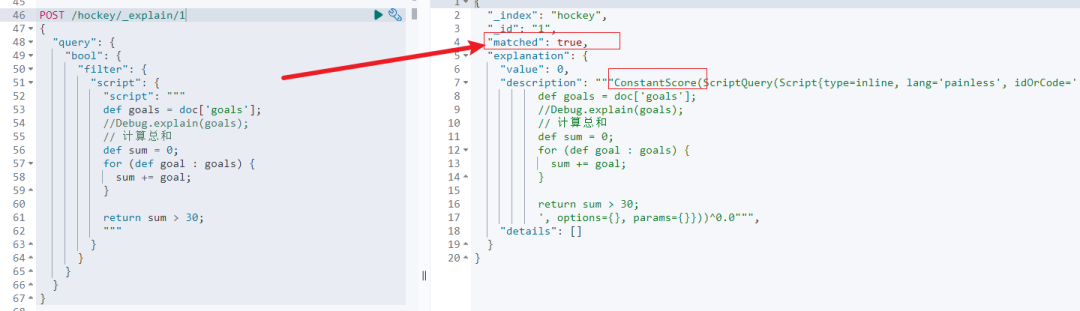
而此处还展示了:matched与否标记,如果条件满足则返回 true;如果不满足则返回 false。
显然,咱们的文档1符合查询条件。
3.2.3 Debug.explain 使用细节调试
还不够,doc'goals' 到底来自哪里呢?
如下 DSL 仅在 3.2.2 基础上加了 Debug.explain 。
go
POST /hockey/_explain/1
{
"query": {
"bool": {
"filter": {
"script": {
"script": """
def goals = doc['goals'];
Debug.explain(doc['goals']);
// 计算总和
def sum = 0;
for (def goal : goals) {
sum += goal;
}
return sum > 30;
"""
}
}
}
}
}执行结果截图如下:
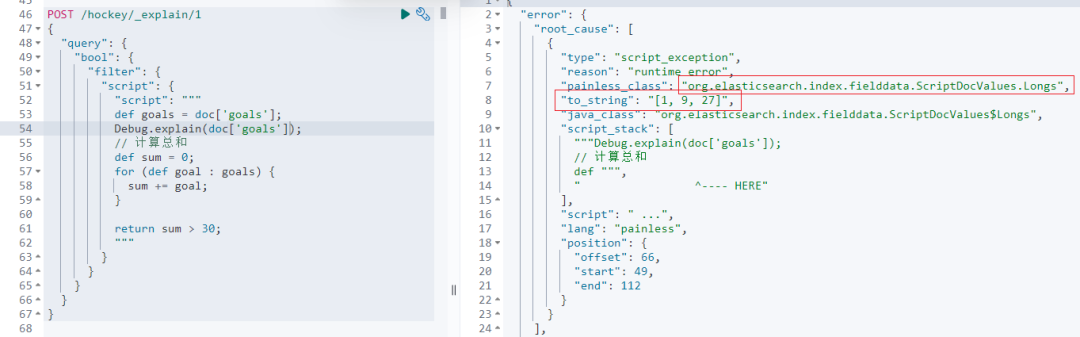
该错误指出在调用 Debug.explain(doc'goals'); 时发生了运行时错误。
Debug.explain 是一个调试方法,用于在脚本中输出变量的信息。然而,这种方法在某些上下文中可能不被允许,或者 doc'goals' 字段的类型 ScriptDocValues.Longs 导致了这个问题。
其实,我们还能得到如下有价值信息:
-
(1):"to_string": "1, 9, 27" 显示了 doc'goals' 字段的值,即一个包含 1, 9, 27 的数组。
-
(2):"painless_class": "org.elasticsearch.index.fielddata.ScriptDocValues.Longs" 指出导致错误的类是 ScriptDocValues.Longs。这是一个表示长整型字段值的类。
关于这个类的官方文档,可以参见:
根据:org.elasticsearch.index.fielddata.ScriptDocValues.Longs
找到 fielddata 子模块,进而找到文档,参见下图。
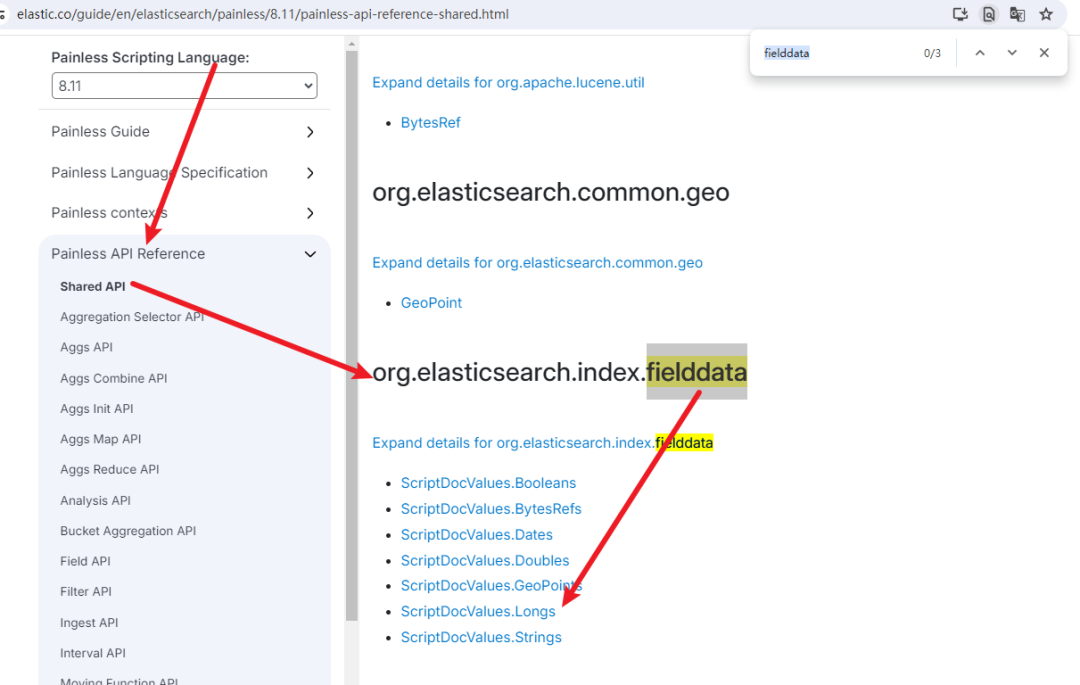
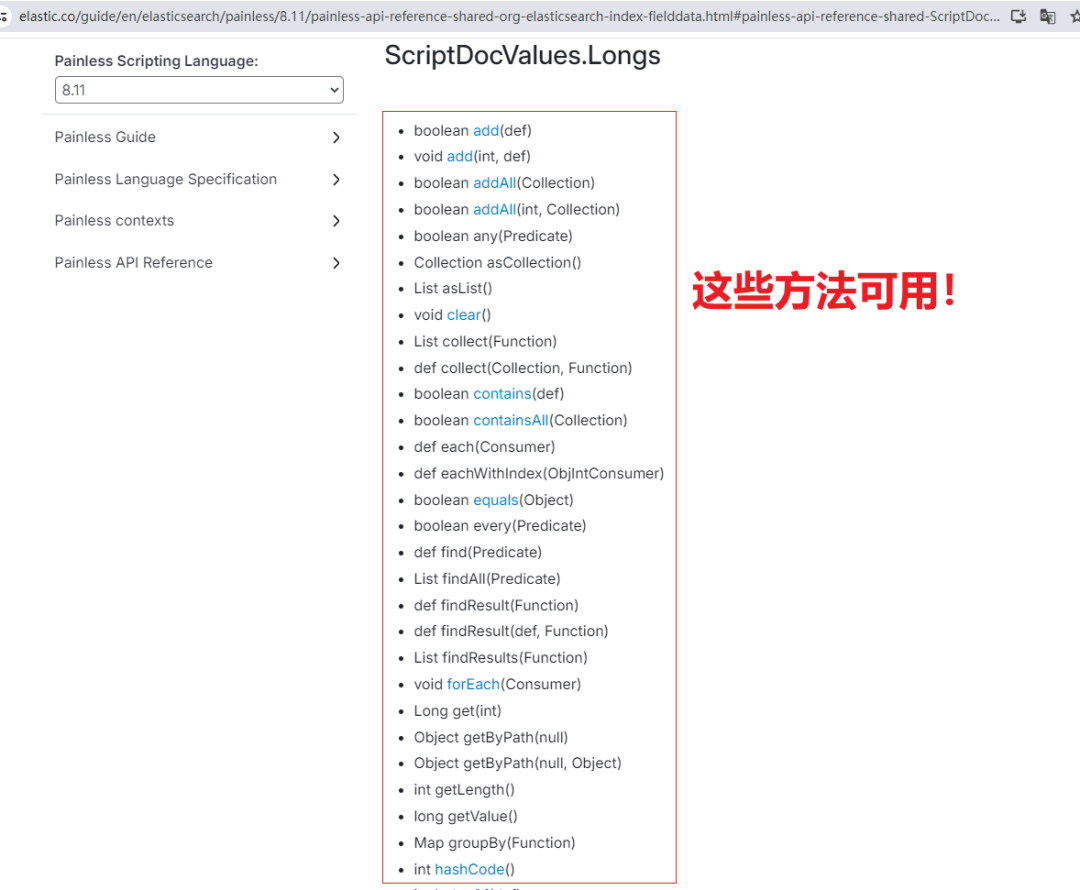
其实,这些 API 就是我们使用脚本的依据和参考。
这里,往往也是被问最多的地方:Elasticsearch 脚本细节运算的 API 在哪里查?支持哪些方法?
有了它,我们进一步可以执行脚本了,举例:sort 使用如下:
go
POST /hockey/_search
{
"script_fields": {
"sorted_goals": {
"script": {
"lang": "painless",
"source": """
// 获取 goals 数组,并复制到一个新的列表中
def goals = new ArrayList(doc['goals']);
// 定义排序比较器,从大到小排序
goals.sort((a, b) -> b.compareTo(a));
// 返回排序后的数组
return goals;
"""
}
}
}
}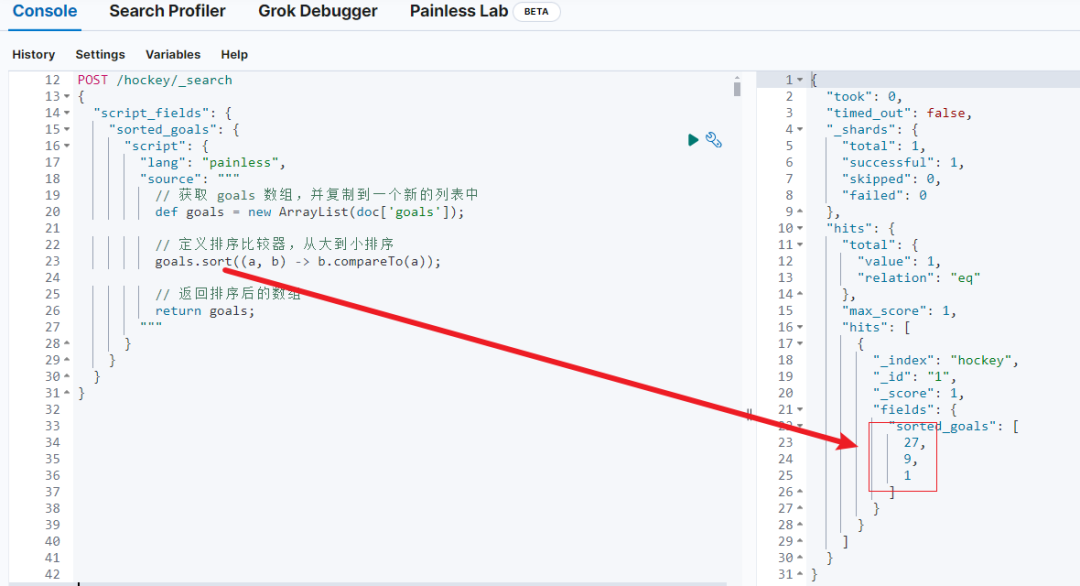
goals.sort((a, b) -> b.compareTo(a)); ------语法的核心是使用 Java 8 的 lambda 表达式和 Comparator 接口来定义排序规则。
b.compareTo(a) 是对 b 和 a 进行比较的方法调用。compareTo 方法返回一个整数,用于指示元素的顺序:
-
如果返回负数,则表示 b 小于 a。
-
如果返回零,则表示 b 等于 a。
-
如果返回正数,则表示 b 大于 a。仔细看来,这是意外的收获!
4、小结
篇幅原因,本文只给出了Painless 脚本的第一种调试方式:Debug.explain 的详尽解读。
相信对你的脚本调试也会有帮助,如果你有脚本调试疑问,欢迎留言交流哈。
关于 Kibana Painless Lab 工具调试 ,且听下回分解。
探究 | Elasticsearch Painless 脚本 ctx、doc、_source 的区别是什么?
干货 | Elasticsearch7.X Scripting脚本使用详解
新时代写作与互动:《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
http://elastic6.cn------ElasticStack进阶助手

抢先一步学习进阶干货!