蚂蚁集团最近推出了一项名为EchoMimic的新技术。能通过音频和面部标志生成逼真的肖像动画视频,让你的声音和面部动作被完美复制到视频中,效果自然如照镜子。
EchoMimic不仅可以单独使用音频或面部标志点生成肖像视频,也可以将两者结合,创造出更加逼真的动画。
它还支持多语言和多风格,无论是普通话、英语还是歌唱,EchoMimic都能轻松应对。EchoMimic的应用场景包括面部识别、表情识别、面部动画、增强现实、医学成像等。
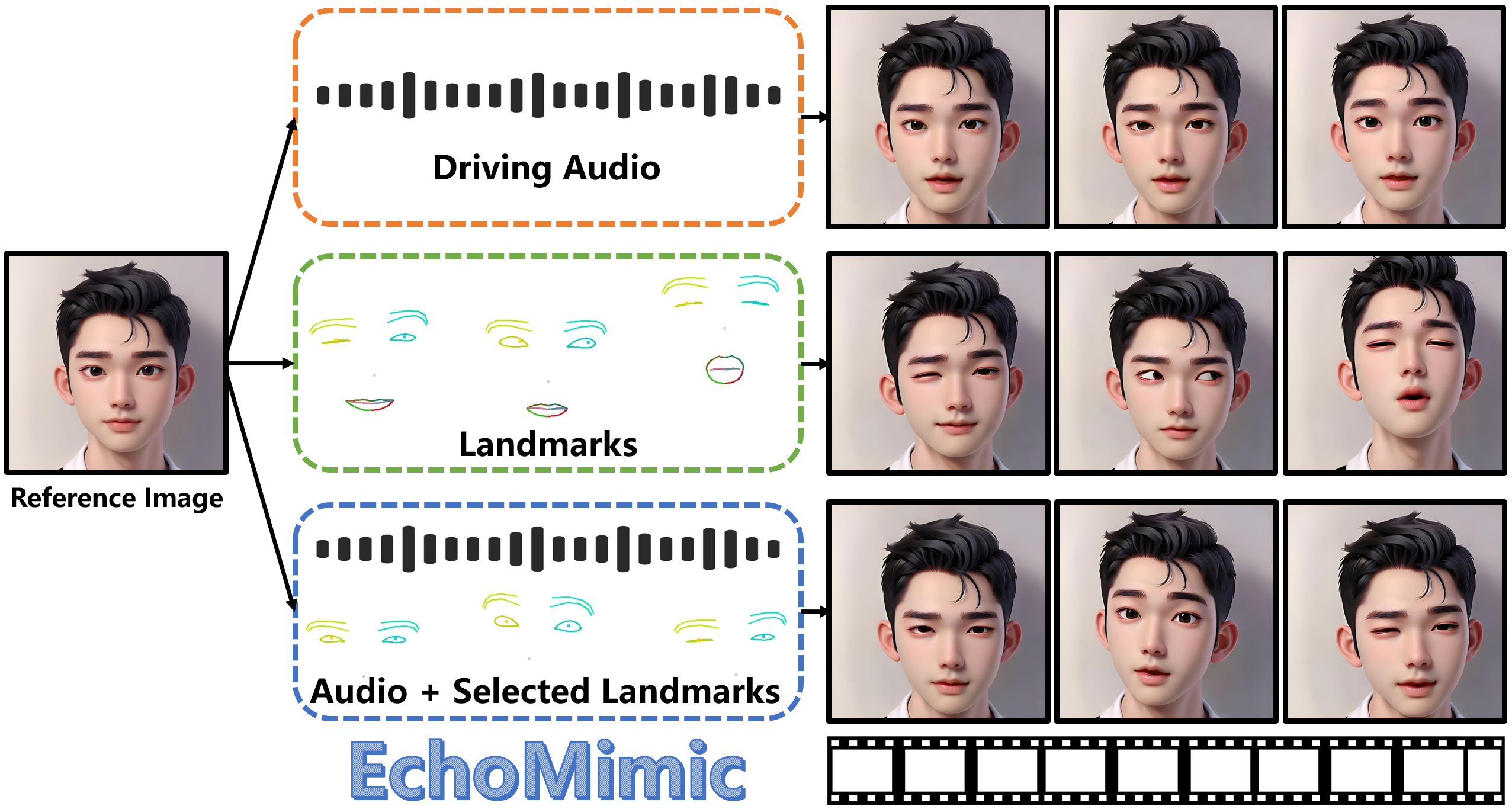
EchoMimic能够生成肖像视频音频,面部标志以及音频和选定的面部标志。

相关链接
论文地址:https://arxiv.org/abs/2407.08136
项目地址:https://github.com/BadToBest/EchoMimic
试用链接:https://huggingface.co/BadToBest/EchoMimic
论文阅读

EchoMimic:通过可编辑地标调节实现栩栩如生的音频驱动肖像动画
摘要
EchoMimic不仅能够通过音频和面部特征点单独生成肖像视频,还能通过音频和选定的面部特征点的组合生成肖像视频。
由音频驱动的肖像动画领域在生成逼真的动态肖像方面取得了显著进展。传统方法仅限于利用音频或面部关键点将图像驱动到视频中,虽然它们可以产生令人满意的结果,但也存在某些问题。例如,仅由音频驱动的方法有时会因为相对较弱的音频信号而不稳定,而仅由面部关键点驱动的方法虽然驱动更稳定,但由于对关键点信息的过度控制,可能会导致不自然的结果。为了解决前面提到的挑战,在本文中,我们介绍了一种名为 EchoMimic 的新方法。
EchoMimic 同时使用音频和面部关键点进行训练。通过实施一种新颖的训练策略,EchoMimic 不仅能够通过音频和面部关键点单独生成肖像视频,而且还能够通过音频和选定的面部关键点的组合生成肖像视频。EchoMimic 已在各种公共数据集和我们收集的数据集中与其他算法进行了全面比较,在定量和定性评估中均表现出色。。
方法
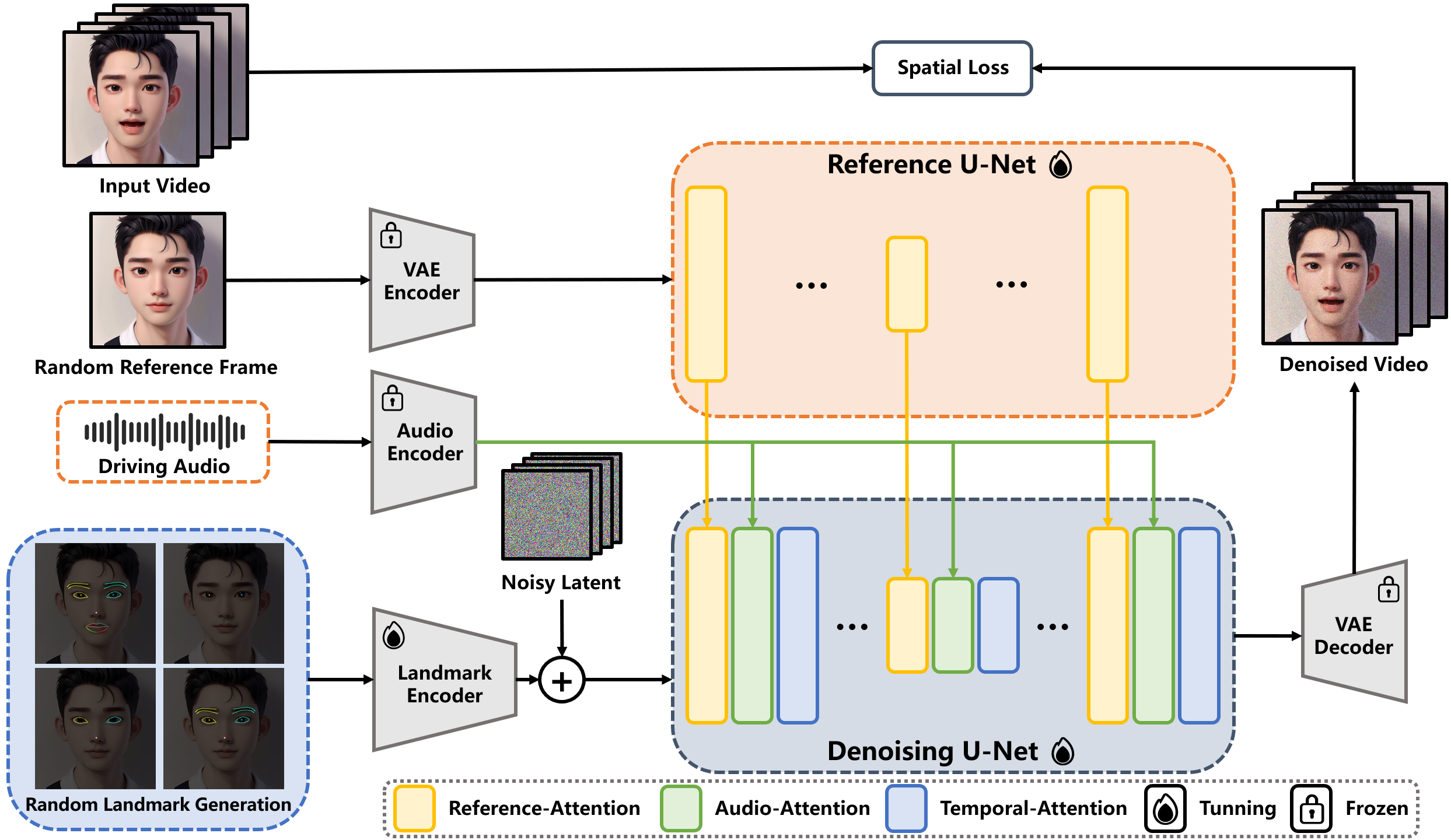
EchoMimic (EM)框架的整体流程。EchoMimic 框架的基础组件是 Denoising U-Net 架构,如上图所示。为了增强网络吸收各种输入的能力,EchoMimic 集成了三个专门的模块:用于编码参考图像的参考 U-Net、用于使用面部标志引导网络的标志编码器和用于编码音频输入的音频编码器。这些模块共同确保了全面且上下文丰富的编码过程,这对于生成高保真视频内容至关重要。
效果

所提出的EchoMimic的视频生成结果给出了不同的肖像风格和音频。

所提出的EchoMimic的视频生成结果给出了不同的肖像风格和地标。

EchoMimic的视频生成结果给出了不同的肖像风格、音频和选定的地标。

运动同步法的地标映射结果。


结论
在本文中,我们介绍了一种新颖的肖像动画方法 EchoMimic,该方法利用音频信号和面部特征来生成高质量且富有表现力的说话头视频。通过一种新颖的训练策略,EchoMimic 在生成真实且具有视觉吸引力的肖像动画方面取得了重大进展。对各种公共数据集进行的全面评估以及与其他算法的细致比较凸显了 EchoMimic 的卓越性能和稳健性。通过解决肖像动画中的关键挑战,我们的方法展示了增强多媒体体验和推进视频合成最新技术的巨大希望。详细的方法、定性和定量评估以及消融研究共同加强了 EchoMimic 在肖像动画领域的功效和潜在影响。