CLIP-DIY 是一种基于 CLIP 模型的开放词汇语义分割方法,特点是无需额外的训练或者像素级标注,即可实现高效、准确的分割效果。该方法主要利用 CLIP 模型在图像分类方面的强大能力,并结合无监督目标定位技术,实现开放词汇语义分割。
在论文中,首先肯定了CLIP出现的重要意义,开启了开放世界图像感知的大门。缺点是难以用在图像分割这样的密集任务。虽然已经有完全监督学习的方法,可以用来解决图像分割问题。但是冗长的像素级标注,要付出高昂的成本。

为此论文作者提出了一种新的零采样开放词汇语义分割方法,它直接利用了CLIP的高性能图像分类特性,不需要改变结构或额外的训练。
论文的核心核心思想
-
多尺度推理: 将图像分割成不同大小的Patch,利用 CLIP 模型对每个Patch进行分类,得到每个 patch 对应每个类别的置信度分数。
-
聚合预测: 将不同尺度的预测结果进行聚合,得到每个像素对应每个类别的置信度分数图。
-
前景/背景引导: 利用无监督目标定位方法获取前景/背景分数,对预测结果进行引导,提升分割精度。
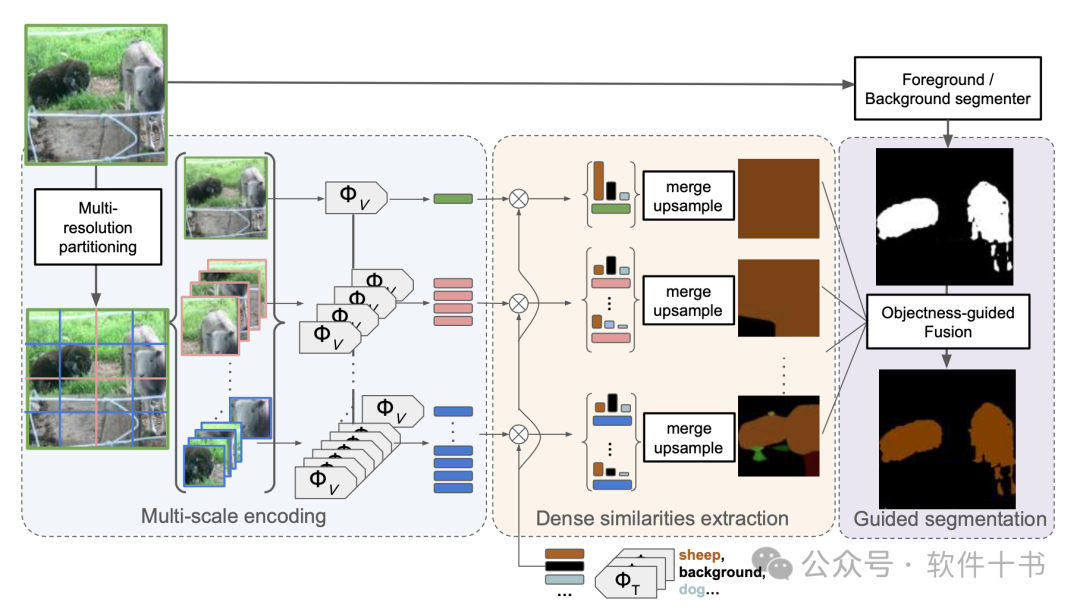
图像分割过程
首先是特征向量的提取,CLIP-DIY并没有训练新的模型,而是利用已经预训练好的CLIP模型,先使用 CLIP 文本编码器将文本提示(如"一张狗的照片")编码成向量。将图像分割成不同大小的Patch之后,使用 CLIP 图像编码器提取每个Patch 的特征向量。
然后就可以计算每个Patch与文本向量之间的相似度,并进行上采样,得到每个像素对应每个类别的置信度分数图。再使用无监督的前景/背景分割方法(如 FOUND)获取前景/背景分数,根据前景/背景分数对预测结果进行引导,就可以提升分割的精度。
最终生成分割图的时候,是通过 SoftMax 操作,将相似度得分转换为概率分布,其中每个像素都被分配了一个类别标签。
论文中使用的FOUND是一个轻量级的卷积神经网络,通过自训练学习前景/背景分割。能够有效地识别图像中的前景区域,并生成前景/背景得分图。除了FOUND之外,还可以采用其他基于无监督或者自监督学习的目标分割方法,例如CutLER和Freesolo。

结论和思考
使用CLIP-DIY不需要任何特定的额外训练就可以使用。作为开放世界分割的现成方法,可以用来辅助作为数据标注的工具,减少数据标注的成本和人力投入。
减少标注成本在大模型训练中是非常有价值的,尤其针对特定领域的模型训练,往往需要处理大量的视频和图片,如果全部由人来进行剪辑和标注,不但成本高、效率低、还容易出错;用自动化工具辅助,可以极大改善。
对我自己来说,最有启发性地方在于,在解决问题的时候,可以设计出一种算法,完全不需要任何特定的训练,将算法的核心,放在输入层和输出层,如何处理和分割数据,然后组合不同的模型和函数,就可以带来质的变化。
CLIP-DIY 论文解读:基于 CLIP 和无监督目标定位的语义分割![]() https://mp.weixin.qq.com/s/E6naltzclXNT2jJyzuLZaA
https://mp.weixin.qq.com/s/E6naltzclXNT2jJyzuLZaA