概述
单目深度估计(Monocular Depth Estimation, MDE)是一项在计算机视觉领域中非常重要的技术,它旨在从单张图像中恢复出场景的三维结构。这项技术对于机器人导航、自动驾驶汽车、增强现实(AR)和虚拟现实(VR)等应用至关重要。
"DepthAnything"是TikTok、香港大学和浙江大学共同研发的一种先进单目深度估计技术。这项技术能够从2D图像中提取深度信息,并将其转换为3D影像。与传统的MDE技术相比,"DepthAnything"在提高深度图质量方面取得了显著进步,这使得它能够更准确地估计场景的深度信息。
这种技术的应用前景非常广泛:
- 增强现实(AR)和虚拟现实(VR):通过将2D图像转换为3D,可以为用户创造更加沉浸式的体验。
- 机器人和自动驾驶汽车:更准确的深度估计可以帮助机器人和自动驾驶汽车更好地理解周围环境,从而提高它们的导航和决策能力。
- 内容创作:摄影师和视频制作者可以使用这项技术将普通2D内容转换为3D,增加作品的吸引力和互动性。
"DepthAnything"模型的成功研发,不仅展示了单目深度估计技术的进步,也为相关领域的研究和应用提供了新的可能性。随着技术的进一步发展和优化,我们可以期待它在未来的实际应用中取得更好的效果,并为多个行业带来便利。
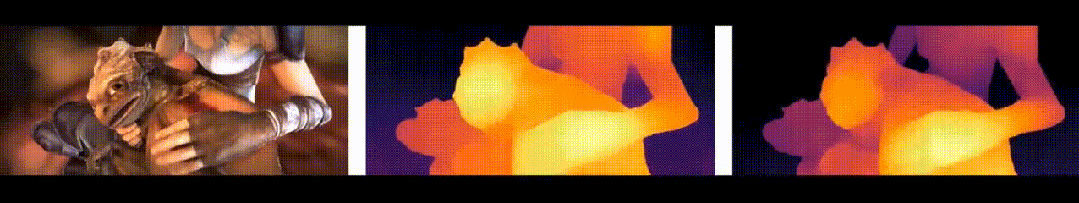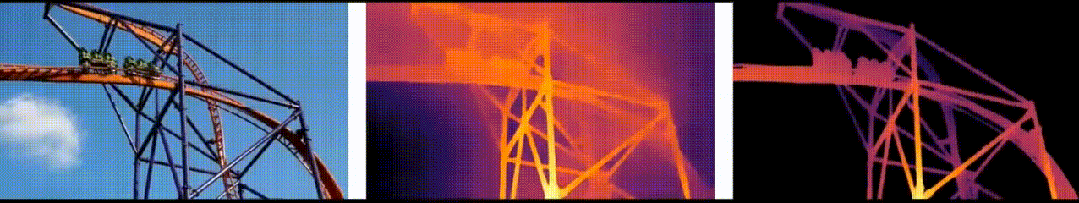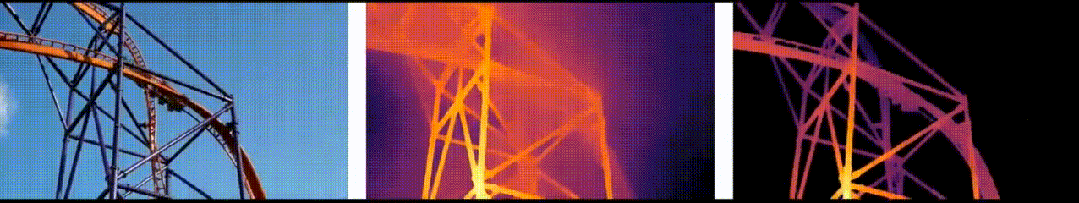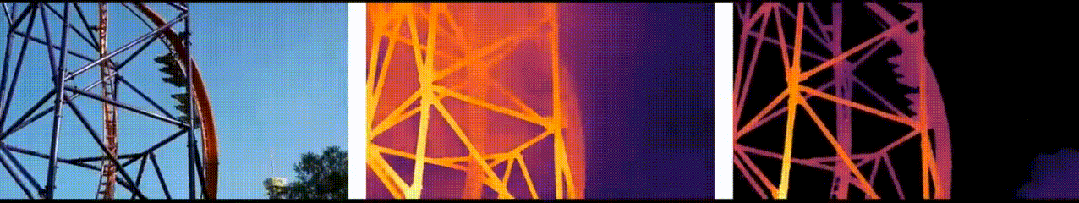


代码:https://github.com/LiheYoung/Depth-Anything
论文:https://arxiv.org/abs/2401.1089
Depth Anything
论文提出的"Depth Anything"技术,是单目深度估计(MDE)领域的一个重要进展。它通过以下几个关键点来实现鲁棒和高效的深度估计:
-
数据引擎设计:通过创建一个数据引擎来自动收集和标注大规模无标签数据(约62M),显著扩大了数据集的覆盖范围,这有助于减少模型的泛化误差。
-
数据增强策略:利用数据增强工具来创建更具挑战性的优化目标,迫使模型寻找额外的视觉知识,从而获得更鲁棒的特征表示。
-
辅助监督:开发了一种辅助监督机制,强制模型从预训练的编码器中继承丰富的语义先验,而不是依赖于辅助性的语义分割任务,这有助于实现更好的场景理解。
-
零样本能力评估:在六个公共数据集和随机捕获的照片上广泛评估了模型的零样本能力,展示了其出色的泛化能力。
-
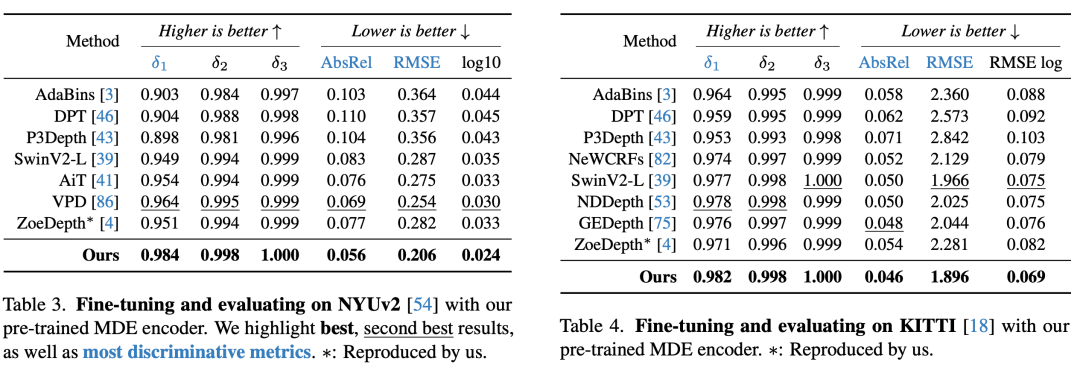
微调提升性能:通过使用NYUv2和KITTI的度量深度信息对模型进行微调,进一步提升了模型的性能,达到了新的最先进水平(SOTA)。
-
深度条件控制网:更好的深度模型导致了更好的深度条件控制网,这对于许多应用场景来说是一个重要的优势。
论文的主要贡献可以总结为:
- 强调了大规模、低成本和多样化的无标注图像数据扩展对于MDE的重要性。
- 提出了一种有效的联合训练方法,通过提供更困难的优化目标,让模型学会使用额外的知识。
- 展示了从预训练编码器继承语义先验的有效性,而不是依赖辅助任务。
算法框架
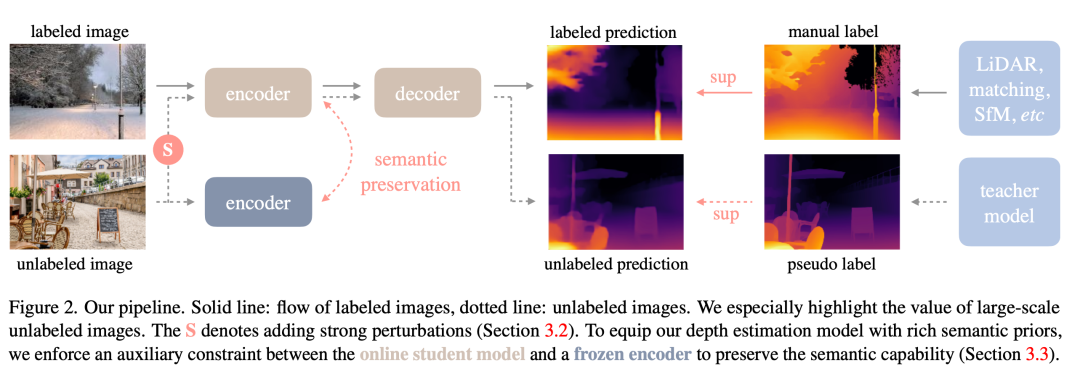 本文提出了一种利用带标签和未标记图像进行单目深度估计(MDE)的方法,称之为"Depth Anything"。方法包括以下步骤:
本文提出了一种利用带标签和未标记图像进行单目深度估计(MDE)的方法,称之为"Depth Anything"。方法包括以下步骤:
-
学习带标签图像(Learning Labeled Images):通过使用来自六个公共数据集的1.5M带标签图像,采用与MiDaS相似的深度值变换和归一化方法,采用仿射不变损失进行多数据集联合训练,构建了一个师傅模型T。
-
释放未标记图像的力量(Unleashing the Power of Unlabeled Images):与传统方法不同,该方法强调利用大规模未标记图像提高数据覆盖。通过利用互联网或各种任务的公共数据集,构建了一个多样化和大规模的未标记集。通过师傅模型T为未标记集生成伪标签,然后利用带标签图像和伪标签图像的组合,训练了一个学生模型S。在训练中,采用强烈的颜色和空间扭曲来激励学生模型主动寻求额外的视觉知识。
-
语义辅助感知(Semantic-Assisted Perception):引入了辅助语义分割任务,通过为未标记图像分配语义分割标签,提供了高级语义相关信息。然而,为了更好地处理深度估计任务,采用了DINOv2模型在语义相关任务中的优秀性能,通过辅助特征对齐损失将其强大的语义能力转移到深度模型中。
本文方法通过联合利用带标签和未标记图像,充分利用大规模未标记数据的优势,通过深度模型的自我挑战和语义辅助感知,实现了更强大的单目深度估计性能。方法在多个数据集上进行了评估,并取得了令人满意的结果。
实验与测试
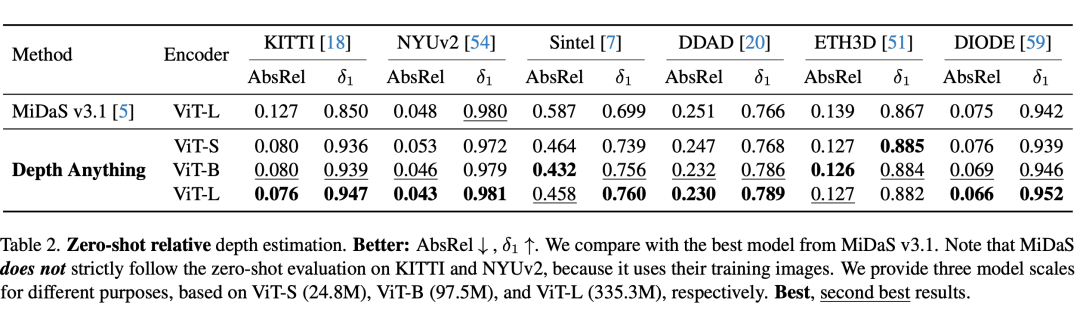
在六个公开数据集与随机拍摄图片上评估了Depth Anything模型的zero-shot能力;通过度量深度信息微调达成新的SOTA;更优的深度模型进而引申出更优的深度引导ControlNet。



总结
本研究引入了Depth Anything模型,该模型在稳健的单目深度估计方面展现了高度实用性。通过强调廉价且多样化的未标记图像的价值,并采用两种有效策略,即在学习未标记图像时设定更具挑战性的优化目标以及保留预训练模型的丰富语义先验,使得该模型在零样本深度估计方面表现出色。此外,该模型还可作为有望初始化下游度量深度估计和语义分割任务的有效工具。
