import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch.nn as nn
import torch
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
# Importing the training set
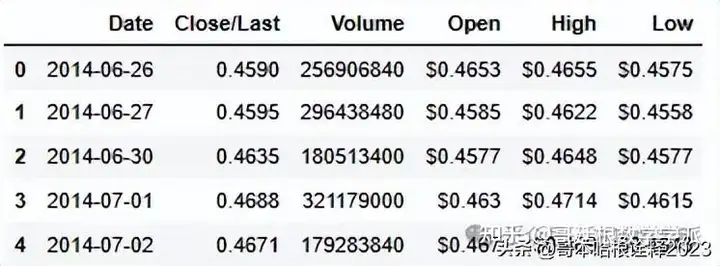
dataset = pd.read_csv('HistoricalData_1719412320530.csv')
dataset.head(10)
复制代码
dataset.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2516 entries, 0 to 2515
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 2516 non-null object
1 Close/Last 2516 non-null object
2 Volume 2516 non-null int64
3 Open 2516 non-null object
4 High 2516 non-null object
5 Low 2516 non-null object
dtypes: int64(1), object(5)
memory usage: 118.1+ KB
# change time order
dataset['Date'] = pd.to_datetime(dataset['Date'], format='%m/%d/%Y')
# Sort the DataFrame in ascending order
dataset = dataset.sort_values(by='Date', ascending=True)
# Reset index if necessary
dataset = dataset.reset_index(drop=True)
dataset.head(5)
Step 2: Cutting time series into sequences (Sliding Window)
复制代码
input_size = 7
# Create a function to process the data into 7 day look back slices
# lb is window size
def processData(data, lb):
X, y = [], [] # X is input vector, Y is output vector
for i in range(len(data) - lb - 1):
X.append(data[i: (i + lb), 0])
y.append(data[(i + lb), 0])
return np.array(X), np.array(y)
X, y = processData(dataset_cl, input_size)
# plot original data
plt.plot(sc.inverse_transform(y.reshape(-1,1)), color='k')
# train_inputs = torch.tensor(X_train).float().cuda()
train_pred, hidden_state = rnn(inputs_cuda, None)
train_pred_cpu = train_pred.cpu().detach().numpy()
# use hidden state from previous training data
test_predict, _ = rnn(X_test_cuda, hidden_state)
test_predict_cpu = test_predict.cpu().detach().numpy()
# plt.plot(scl.inverse_transform(y_test.reshape(-1,1)))
split_pt = int(X.shape[0] * 0.80) + 7 # window_size
plt.plot(np.arange(7, split_pt, 1), sc.inverse_transform(train_pred_cpu.reshape(-1,1)), color='b')
plt.plot(np.arange(split_pt, split_pt + len(test_predict_cpu), 1), sc.inverse_transform(test_predict_cpu.reshape(-1,1)), color='r')
# pretty up graph
plt.xlabel('day')
plt.ylabel('price of Nvidia stock')
plt.legend(['original series','training fit','testing fit'], loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()
复制代码
MMSE = np.sum((test_predict_cpu.reshape(1,X_test.shape[0])-y[2006:])**2)/X_test.shape[0]
print(MMSE)
0.0018420128176938062
担任《Mechanical System and Signal Processing》审稿专家,担任《中国电机工程学报》,《控制与决策》等EI期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。
知乎学术咨询:https://www.zhihu.com/consult/people/792359672131756032?isMe=1