1. 技术选型
爬虫这个功能,我个人理解是什么语言都能写的,只要能正常发送 HTTP 请求,将响应回来的静态页面模版 HTML 上把我们所需要的数据提取出来就可以了,原理很简单,这个东西当然可以手动去统计收集,但是网络平台毕竟还是很多的,还是画点时间,写个爬虫把数据爬取下来,存到数据库里,然后写一个统计报表的 SQL 语句比较方便,后续如果有时间的话,我会写一个简单的前后端分离的报表样例分享出来。
网上现在 Python 爬虫的课程非常的火爆,其实我心里也有点小九九,想玩点骚操作,不想用老本行去写这个爬虫,当然最后的事实是证明确实用 Python 写爬虫要比用 Java 来写爬虫要简单的多。
2. 环境准备
首先笔者的电脑是 Win10 的,Python 选用的是 3.7.4 ,貌似现在网上 Python3 的爬虫教程并不多,其中还是遇到不少的问题,下面也会分享给大家。
开发工具笔者选用的是 VSCode ,在这里推荐一下微软这个开源的产品,非常的轻量化,需要什么插件自己安装就好,不用的插件一律不要,自主性非常高,如果感觉搞不定的朋友可以选择 JetBrains 提供的 Pycharm ,分为社区版和付费版,一般而言,我们使用社区版足矣。
笔者这里直接新建了一个文件夹,创建了一个名为 spider-demo.py 的文件,这个就是我们一会要写的爬虫的文件了,可以给大家看下笔者的开发环境,如下:

这其实是一个调试成功的截图,从下面打印的日志中可以看到,笔者这里抓取了三个平台的数据。
3. 数据库
笔者使用的数据是 Mysql 5.7.19 版本,数据库的字符集是使用的 utf8mb4 ,至于为什么使用 utf8mb4 而不是 utf8 ,各位百度一下吧,很多人讲的都比我讲的好,我简单说一句就是 Mysql 的 utf8 其实是一个假的 utf8 ,而后面增加的字符集 utf8mb4 才是真正的 utf8 。
而 Python 连接 Mysql 也是需要驱动的,和在 Java 中连接数据库需要驱动一样,这里使用的是 pymysql ,安装命令:
pip install pymysql有没有感觉很简单, pip 是 Python 的一个包管理工具,我的个人理解是类似于一个 Maven 的东西,所有的我们需要的第三方的包都能在这个上面下载到。
当然,这里可能会出现 timeout 的情况,视大家的网络情况而定,我在晚上执行这个命令的时候真的是各种 timeout ,当然 Maven 会有国内的镜像战, pip 显然肯定也会有么,这里都列给大家:
- 阿里云 Simple Index
- 中国科技大学 Simple Index
- 豆瓣(douban) https://pypi.douban.com/simple/
- 清华大学 Simple Index
- 中国科学技术大学 Simple Index
具体使用方式命令如下:
pip install -i https://mirrors.aliyun.com/pypi/simple/ 库名笔者这里仅仅尝试过阿里云和清华大学的镜像站,其余未做尝试,以上内容来自于网络。
表结构,设计如下图,这里设计很粗糙的,简简单单的只做了一张表,多余话我也不说,大家看图吧,字段后面都有注释了:
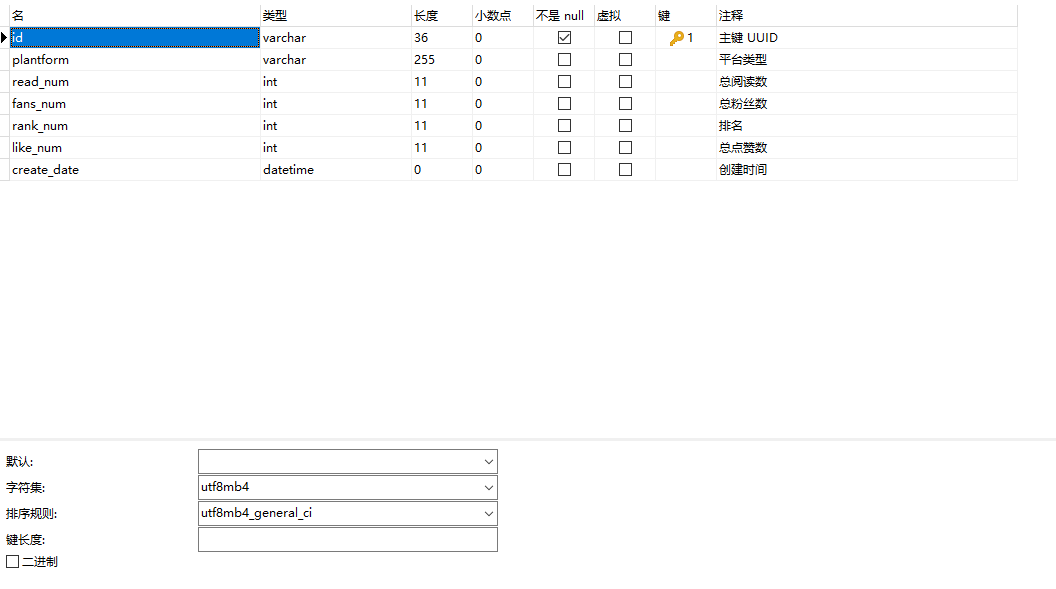
建表语句提交至 Github 仓库,有需要的同学可以去查看。
4. 实战
整体思路分以下这么几步:
- 通过 GET 请求将整个页面的 HTML 静态资源请求回来
- 通过一些匹配规则匹配到我们需要的数据
- 存入数据库
5.1 请求 HTML 静态资源
Python3 为我们提供了 urllib 这个标准库,无需我们额外的安装,使用的时候需要先引入:
from urllib import request接下来我们使用 urllib 发送 GET 请求,如下:
req_csdn = request.Request('https://blog.csdn.net/meteor_93')
req_csdn.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36')
html_csdn = request.urlopen(req_csdn).read().decode('utf-8')User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
这里在请求头中添加这个是为了模拟浏览器正常请求,很多服务器都会做检测,发现不是正常浏览器的请求会直接拒绝,虽然后面实测笔者爬取的这几个平台都没有这项检测,但是能加就加一下么,当然真实的浏览器发送的请求头里面不仅仅只有一个 UA ,还会有一些其他的信息,如下图:

笔者这里的 UA 信息是直接从这里 Copy 出来的。代码写到这里,我们已经拿到了页面静态资源
html_csdn ,接下来我们就是要解析这个资源,从中匹配出来我们需要的信息。
5.2 xpath 数据匹配
xpath 是什么?
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。 XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
从上面这句话我们可以看出来, xpath 是用来查找 XML ,而我们的 HTML 可以认为是语法不标准的 XML 文档,恰巧我们可以通过这种方式来解析 HTML 文档。
我们在使用 xpath 之前,需要先安装 xpath 的依赖库,这个库并不是 Python 提供的标准库,安装语句如下:
pip install lxml如果网络不给力的同学可以使用上面的镜像站进行安装。
而 xpath 的表达式非常简单,具体的语法大家可以参考 W3school 提供的教程(XPath 语法 ),笔者这里不多介绍,具体使用方式如下:
read_num_csdn = etree.HTML(html_csdn).xpath('//*[@id="asideProfile"]/div[3]/dl[2]/dd/@title')[0]
fans_num_csdn = etree.HTML(html_csdn).xpath('//*[@id="fan"]/text()')[0]
rank_num_csdn = etree.HTML(html_csdn).xpath('//*[@id="asideProfile"]/div[3]/dl[4]/@title')[0]
like_num_csdn = etree.HTML(html_csdn).xpath('//*[@id="asideProfile"]/div[2]/dl[3]/dd/span/text()')[0]这里笔者主要获取了总阅读数、总粉丝数、排名和总点赞数。
这里列举几个最基础的使用,这几个使用在本示例中已经完全够用:
| 表达式 | 描述 |
|---|---|
nodename |
选取此节点的所有子节点。 |
/ |
从根节点选取。 |
// |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
. |
选取当前节点。 |
.. |
选取当前节点的父节点。 |
@ |
选取属性。 |
text |
选取当前节点内容。 |
还有一种简单的方式,我们可以通过 Chrome 浏览器获取 xpath 表达式,具体操作见截图:

打开 F12 ,鼠标右键需要生成 xpath 表达式的内容,点击 Copy -> Copy XPath 即可。
这里有一点需要注意,我们直接通过 xpath 取出来的数据数据类型并不是基础数据类型,如果要做运算或者字符串拼接,需要做类型强转,否则会报错,如下:
req_cnblog = request.Request('https://www.cnblogs.com/babycomeon/default.html?page=2')
req_cnblog.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36')
html_cnblog = request.urlopen(req_cnblog).read().decode('utf-8')
max_page_num = etree.HTML(html_cnblog).xpath('//*[@id="homepage_top_pager"]/div/text()')
# 最大页数
max_page_num = re.findall(r"\d+\.?\d*", str(max_page_num))[0]这里需要获取 cnblog 的博客最大页数,首先取到了 max_page_num ,这里直接做 print 的话是可以正常打印一个字符串出来的,但是如果直接去做正则匹配,就会类型错误。
5.3 写入数据库
数据库的操作我就不多做介绍了,有写过 Java 的同学应该都很清楚 jdbc 是怎么写的,先使用 ip 、 port 、 用户名、密码、数据库名称、字符集等信息获取连接,然后开启连接,写一句 sql ,把 sql 拼好,执行 sql ,然后提交数据,然后关闭连接,代码如下:
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='123456',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into spider_data(id, plantform, read_num, fans_num, rank_num, like_num, create_date) values (UUID(), %(plantform)s, %(read_num)s, %(fans_num)s, %(rank_num)s, %(like_num)s, now())"在本示例中,爬虫只负责一个数据爬取工作,所以只需要一句 insert 语句就够了,然后在每个平台爬取完成后,将这句 sql 中的占位符替换掉,执行 sql 后 commit 操作即可,示例代码如下:
csdn_data = {
"plantform": 'csdn',
"read_num": read_num_csdn,
"fans_num": fans_num_csdn,
"rank_num": rank_num_csdn,
"like_num": like_num_csdn
}
cursor.execute(sql_insert, csdn_data)
conn.commit()最后这里给大家免费分享一份Python学习资料,包含了视频、源码、课件,希望能够帮助到那些不满现状,想提示自己却又没用方向的朋友,也可以和我一起来交流呀!
编辑资料、学习路线图、源代码、软件安装包等!

一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。