目录
- 1分类任务
-
- [1.1 二分类](#1.1 二分类)
-
- [1.1.1 含义介绍](#1.1.1 含义介绍)
- [1.1.2 指标](#1.1.2 指标)
- 1.2多分类
- 2图像分割
-
- [2.1 常用指标](#2.1 常用指标)
- [2.2 具体含义](#2.2 具体含义)
-
- [2.3 代码实现](#2.3 代码实现)
1分类任务
1.1 二分类
混淆矩阵
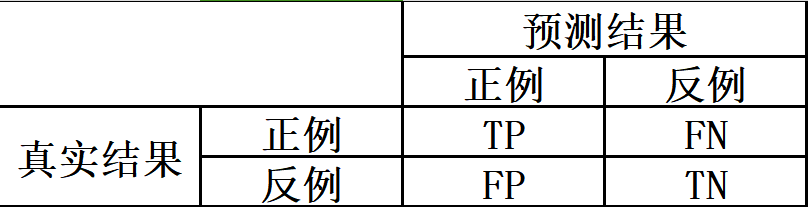
1.1.1 含义介绍
- TP:预测为真所以是Positive,预测结果和真实结果一致所以为True
- TN:预测为假所以是Negative,预测结果和真实结果一致所以为True
- FP:预测为真所以是Positive,预测结果和真实结果不一致所以为False
- FN:预测为假所以是Negative,预测结果和真实结果不一致所以为False
1.1.2 指标
- Accuracy(准确率)
准确率(Accuracy)表示分类正确的样本占总样本个数的比例。
优点:当样本中不同类别比例均衡时,Accuracy是衡量分类模型的最直白的指标,是一个较好的衡量标准
缺点:当样本中不同类别比例不均衡时,其中占比大的类别会是影响准确率的最主要的因素。
A c c u r a c y = T P + T N T P + F P + T N + F N Accuracy=\frac{TP+TN}{TP+FP+TN+FN} Accuracy=TP+FP+TN+FNTP+TN
- Precision(精确率)
别名查准率,表示预测结果为正例的样本中实际为正样本的比例。
特点:使用场景:当反例被错误预测成正例(FP)的代价很高时,适合用精确率。
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP
- 召回率
别名查全率,表示预测结果为正样本中实际正样本数量占全样本中正样本的比例。
特点:当正例被错误的预测为反例(FN)产生的代价很高时,适合用召回率。
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP
- F1 score
F1 score是精确率和召回率的一个加权平均。
特点:Precision体现了模型对负样本的区分能力,Precision越高,模型对负样本的区分能力越强;Recall体现了模型对正样本的识别能力,Recall越高,模型对正样本的识别能力越强。F1 score是两者的综合,F1 score越高,说明模型越稳健。
F 1 = 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l F_1=2*\frac{Precision*Recall}{Precision+Recall} F1=2∗Precision+RecallPrecision∗Recall
1.2多分类
2图像分割
2.1 常用指标
这里的主要是评价两个集合之间的相似性
像素准确率(Pixel Accuracy,PA)
类别像素准确率(Class Pixel Accuray,CPA)
类别平均像素准确率(Mean Pixel Accuracy,MPA)
交并比(Intersection over Union,IoU)
平均交并比(Mean Intersection over Union,MIoU)
Dice coefficient
2.2 具体含义
- PA 预测类别正确的像素数占总像素数的比例
混淆矩阵计算:
对角线元素之和 / 矩阵所有元素之和
P A = T P + T N T P + F P + T N + F N PA=\frac{TP+TN}{TP+FP+TN+FN} PA=TP+FP+TN+FNTP+TN
- CPA
在类别 i 的预测值中,真实属于 i 类的像素准确率,换言之:模型对类别 i 的预测值有很多,其中有对有错,预测对的值占预测总值的比例
混淆矩阵计算:
类 1 : P 1 = T P ( T P + F P ) 类1:P1 = \frac{TP} {(TP + FP)} 类1:P1=(TP+FP)TP
类 2 : P 2 = T P ( T P + F P ) 类2:P2 = \frac{TP} {(TP + FP)} 类2:P2=(TP+FP)TP
类 3 : ... 类3:... 类3:...
- MPA:类别平均像素准确率 分别计算每个类被正确分类像素数的比例,即:CPA,然后累加求平均
混淆矩阵计算:
每个类别像素准确率为:Pi(计算:对角线值 / 对应列的像素总数)
M P A = s u m ( P i ) 类别数 MPA = \frac{sum(P_i) } {类别数} MPA=类别数sum(Pi)
- IoU:交并比
模型对某一类别预测结果和真实值的交集与并集的比值
混淆矩阵计算:
以求二分类:正例(类别1)的IoU为例
交集:TP,并集:TP、FP、FN求和
IoU = TP / (TP + FP + FN)
- MIoU:平均交并比
模型对每一类预测的结果和真实值的交集与并集的比值,求和再平均的结果
混淆矩阵计算:
以求二分类的MIoU为例
MIoU = (IoU正例p + IoU反例n) / 2 = TP / (TP + FP + FN) + TN / (TN + FN + FP) / 2
2.3 代码实现
=持续更新=========