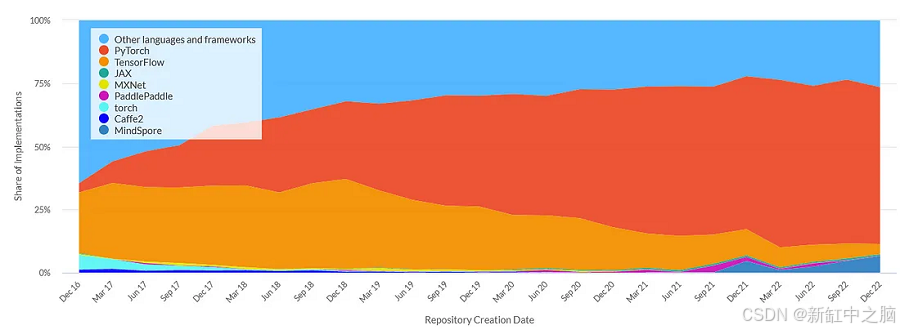
深度学习领域是计算机科学中变化最快的领域之一。大约 5 年前,当我开始研究这个主题时,TensorFlow 被认为是主导框架。如今,大多数研究人员已经转向 PyTorch。
NSDT工具推荐 : Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
虽然这种快节奏令人兴奋,但也带来了很多挑战。最近,我面临着继续完成 2018 年开展的一个项目的任务。一位同事在大量临床数据集上训练了一个分割模型,并报告了出色的性能。
今天,我们的目标是在称为迁移学习的过程中,将该训练好的模型用于类似的目标。这里的直觉是,与其从头开始,不如至少部分使用预训练权重来实例化新模型的权重,这将提供一个更好的起点。
1、收集 Tensorflow 1.x 权重
这听起来比实际容易。在 tensorflow 1.x 中,模型保存在四个单独的文件中 - 其中没有一个可以直接转换为 pytorch 的 state_dict。为了解决这个问题,我们必须手动创建一个字典并从 tensorflow 后端检索权重。
为了实现这一点,你需要了解 tensorflow 实现的命名方案。每个操作都可以在创建时分配一个名称。这个名称在稍后转换为 pytorch 时很重要。
import tensorflow as tf # tensorflow 1.x
import pickle
'''
<base_folder>
├───checkpoint
├───<model_name>.meta
├───<model_name>.data-00000-of-00001
└───<model_name>.index
'''
# First let's load meta graph and restore weights
sess = tf.Session()
saver = tf.train.import_meta_graph(r'<base_folder>\<model_name>.meta')
saver.restore(sess, tf.train.latest_checkpoint(r'<base_folder>'))
# get all trainable weights and save them in a dictionary
vars = sess.graph.get_collection('trainable_variables')
weights = {}
for v in vars:
weights[v.name] = sess.run(v) # retrieve the value from the tf backend
with open('weights.pickle', 'wb') as handle:
pickle.dump(weights, handle, protocol=pickle.HIGHEST_PROTOCOL)2、重建模型
遗憾的是,没有直接的方法将 TensorFlow 模型转换为 PyTorch。但是,尽管语法略有不同,但大多数层都存在于这两个框架中。例如,在 tf1 中,卷积层可以包含激活函数,而在 PyTorch 中,该函数需要按顺序添加。
此示例展示了 tf1 和 PyTorch 实现中流行的 UNet 架构的 upconv 块。
# >>> tf1 implementation (without encapsulating class)
import tensorflow as tf
def upconvcat(self, x1, x2, n_filter, name):
x1 = tf.keras.layers.UpSampling2D((2, 2))(x1)
x1 = tf.layers.conv2d(x1, filters=n_filter, kernel_size=(3, 3), padding='same', name="upsample_{}".format(name))
return tf.concat([x1, x2], axis=-1, name="concat_{}".format(name)) # NHWC format
# >>> pytorch implementation
import torch
class UpConvCat(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = torch.nn.Upsample(scale_factor=2)
self.conv = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
def forward(self, x1, x2):
x1 = self.up(x1)
return torch.cat([x1, x2], dim=1) # NCHW format3、NHWC 与 NCHW
tensorflow 和 pytorch 之间的最后一个重要区别是关于轴的约定。
在旧版 tensorflow 中, data_format 属性可以指定为 channels_last 或 channels_first ,而前者是默认选项。然而,在 pytorch 中,只能使用 channels first。通常,这些格式表示为 NHWC 和 NCHW,分别表示批处理大小 (N)、高度 (H)、宽度 (W) 和通道 (C)。
np.transpose(kernel, (3, 2, 0, 1))如果使用默认的 channels_lastoption 训练 tensorflow 中的预训练模型,则需要对内核轴进行置换才能与 torch 一起使用。为了弥补这一点,需要像这样调整 2d-conv 层权重。
4、初始化 pytorch 模型
将权重转换为正确的格式后,我们可以将它们加载到 pytorch 模型中。为此,我们随机实例化一个模型并遍历命名参数列表。然后我们使用来自 tensorflow 的权重就地修改参数。
# set new weights from loaded tf values
with torch.no_grad():
for (name, param), (tf_name, tf_param) in zip(m.named_parameters(), tf_weights.items()):
# convert NHWC to NCHW format and copy to change memory layout
tf_param = np.transpose(tf_param, (3, 2, 0, 1)).copy() if len(tf_param.shape) == 4 else tf_param
assert tf_param.shape == param.detach().numpy().shape, name
# https://discuss.pytorch.org/t/how-to-assign-an-arbitrary-tensor-to-models-parameter/44082/3
param.copy_(torch.tensor(tf_param, requires_grad=True, dtype=param.dtype))5、结束语
按照这些步骤,可以提取在 tensorflow 1.x 中训练的模型并将其转换为 pytorch 模型。我希望这对与我处境相似的人有所帮助。