大模型实战 DAMODEL云算力平台部署LLama3.1大语言模型
目录
- 一、LLama3.1
- 二、DAMODEL云算力平台
-
- [2.1 提供的服务](#2.1 提供的服务)
-
- [2.1.1 AI训练](#2.1.1 AI训练)
- [2.1.2 AI推理](#2.1.2 AI推理)
- [2.1.3 高性能计算](#2.1.3 高性能计算)
- [2.1.4 图像/视频渲染](#2.1.4 图像/视频渲染)
- [2.1.5 定制化部署](#2.1.5 定制化部署)
- [2.2 支持的GPU](#2.2 支持的GPU)
- 三、在DAMODEL部署LLama3.1
-
- [3.1 在DAMODEL创建实例(装系统部署环境)](#3.1 在DAMODEL创建实例(装系统部署环境))
- [3.2 在DAMODEL部署LLama3.1 8B](#3.2 在DAMODEL部署LLama3.1 8B)
-
- [3.2.1 登录实例](#3.2.1 登录实例)
-
- [3.2.1.1 平台内置JupyterLab](#3.2.1.1 平台内置JupyterLab)
- [3.2.1.2 SSH登录](#3.2.1.2 SSH登录)
- [3.2.2 部署LLama3.1](#3.2.2 部署LLama3.1)
- [3.3.3 在Web端使用LLama模型推理](#3.3.3 在Web端使用LLama模型推理)
- 四、总结
- [五、粉丝福利 - 丹摩低价狂欢节](#五、粉丝福利 - 丹摩低价狂欢节)
大模型(LLM)狭义上指基于深度学习算法进行训练的自然语言处理(NLP)模型,主要应用于自然语言理解和生成等领域,广义上还包括机器视觉(CV)大模型、多模态大模型和科学计算大模型等。
百模大战正值火热,开源 LLM 层出不穷。如今国内外已经涌现了众多优秀开源 LLM,国外如 LLaMA、Alpaca,国内如 ChatGLM、BaiChuan、InternLM(书生·浦语)等。开源 LLM 支持用户本地部署、私域微调,每一个人都可以在开源 LLM 的基础上打造专属于自己的独特大模型。
一、LLama3.1
2024 年 7 月 23 日 Meta宣布推出迄今为止最强大的开源模型------Llama 3.1 405B,同时发布了全新升级的 Llama 3.1 70B 和 8B 模型。
Llama 3.1 405B支持上下文长度为128K Tokens ,在基于15万亿个Tokens 、超1.6万个H100 GPU上进行训练,这也是Meta有史以来第一个以这种规模进行训练的Llama模型。
Llama 3.1 与其他模型对比:
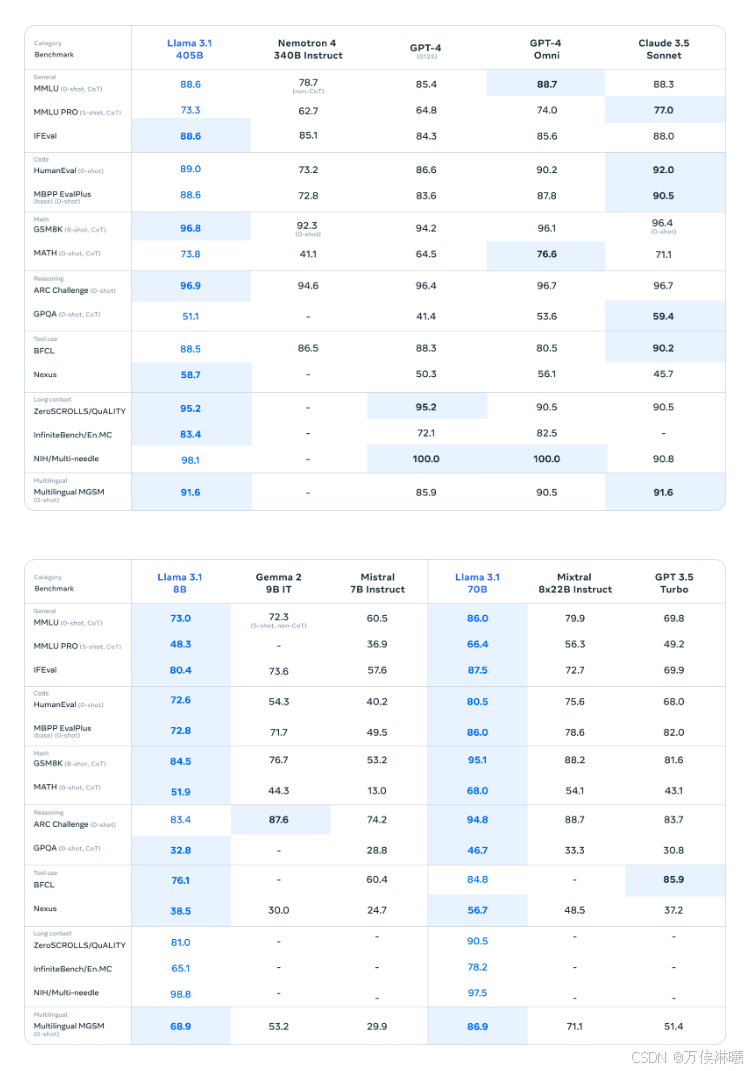
由于资源限制,我们此次选择部署 LLaMA3.1 的 8B 版本,该版本至少需要GPU显存16G。
本次测试环境:
ubuntu 22.04
python 3.12
cuda 12.1
pytorch 2.4.0
二、DAMODEL云算力平台
DAMODEL(丹摩智算) 是专为 AI 打造的智算云,致力于提供丰富的算力资源与基础设施助力 AI 应用的开发、训练、部署。提供CPU/GPU算力集群、CPU/GPU裸金属服务和高性能存储等3大类产品,其中,算力集群可充分满足用户弹性算力的需求;裸金属服务为用户提供了最佳的性能输出,且允许用户根据需求进行定制。平台在计算节点之间以及计算节点与存储节点之间均采用IB网络,同时,平台提供高并发、高性能的存储服务,避免了网络及存储性能瓶颈,使算力节点性能最充分发挥。
2.1 提供的服务
2.1.1 AI训练
提供丰富的用于AI训练的计算资源及训练软件,使得用户可以快速构建、训练和部署自己的人工智能模型。平台支持TensorFlow、PyTorch、Caffe等主流工具和框架,帮助用户构建和训练各种类型的人工智能模型,如图像识别、语音识别、自然语言处理等。
2.1.2 AI推理
基于高性能算力集群为用户AI推理服务提供强大的算力支持,为AI推理服务的部署和发布提供便利的工具支持。具有针对AIGC、图像识别、语音识别、自然语言处理等多种应用场景的解决方案。
2.1.3 高性能计算
基于高性能的CPU/GPU服务器计算集群,提供强大的计算能力、高速的网络连接和大规模的存储资源,帮助用户完成大规模的计算和数据处理任务。高性能计算服务适用于需要大量计算能力的科学研究、工程仿真、药物研发及数字媒体等领域。
2.1.4 图像/视频渲染
通过CPU/GPU集群提供针对特效制作、影视动画、建筑效果图等场景的离线算力服务;通过高性能GPU服务器提供的实时渲染服务可用于直播渲染、游戏娱乐、产品展示等场景。高性能的算力平台显著缩短了图像/视频渲染所需的时长,并基于优化的算法提供大吞吐量的高效实时渲染。
2.1.5 定制化部署
根据用户需求提供从方案设计、部署实施,到日常运维、系统优化等全流程的服务。
2.2 支持的GPU
| 显卡 | 显存-GB | 内存-GB/卡 | CPU-核心/卡 | 存储 | 简介 |
|---|---|---|---|---|---|
| RTX 4090 | 24 | 60 | 11 | 100G系统盘 50G数据盘 | 性价比配置,推荐入门用户选择,适合模型推理场景 |
| RTX 4090 | 24 | 124 | 15 | 100G系统盘 50G数据盘 | 性价比配置,推荐入门用户与专业用户选择,适合模型推理场景 |
| H800 SXM | 80 | 252 | 27 | 100G系统盘 50G数据盘 | 顶级配置,推荐专业用户选择,适合模型训练与模型推理场景 |
| H800 PCle | 80 | 124 | 21 | 100G系统盘 50G数据盘 | 顶级配置,推荐专业用户选择,适合模型训练与模型推理场景 |
| L40S | 48 | 124 | 21 | 100G系统盘 50G数据盘 | 专业级配置,推荐专业用户选择,适合模型训练与模型推理场景 |
| P40 | 24 | 12 | 6 | 100G系统盘 50G数据盘 | 性价比配置,推荐入门用户选择,适合模型推理场景 |
三、在DAMODEL部署LLama3.1
3.1 在DAMODEL创建实例(装系统部署环境)
创建实例前需要注册账号,注册地址:DAMODEL(丹摩智算)
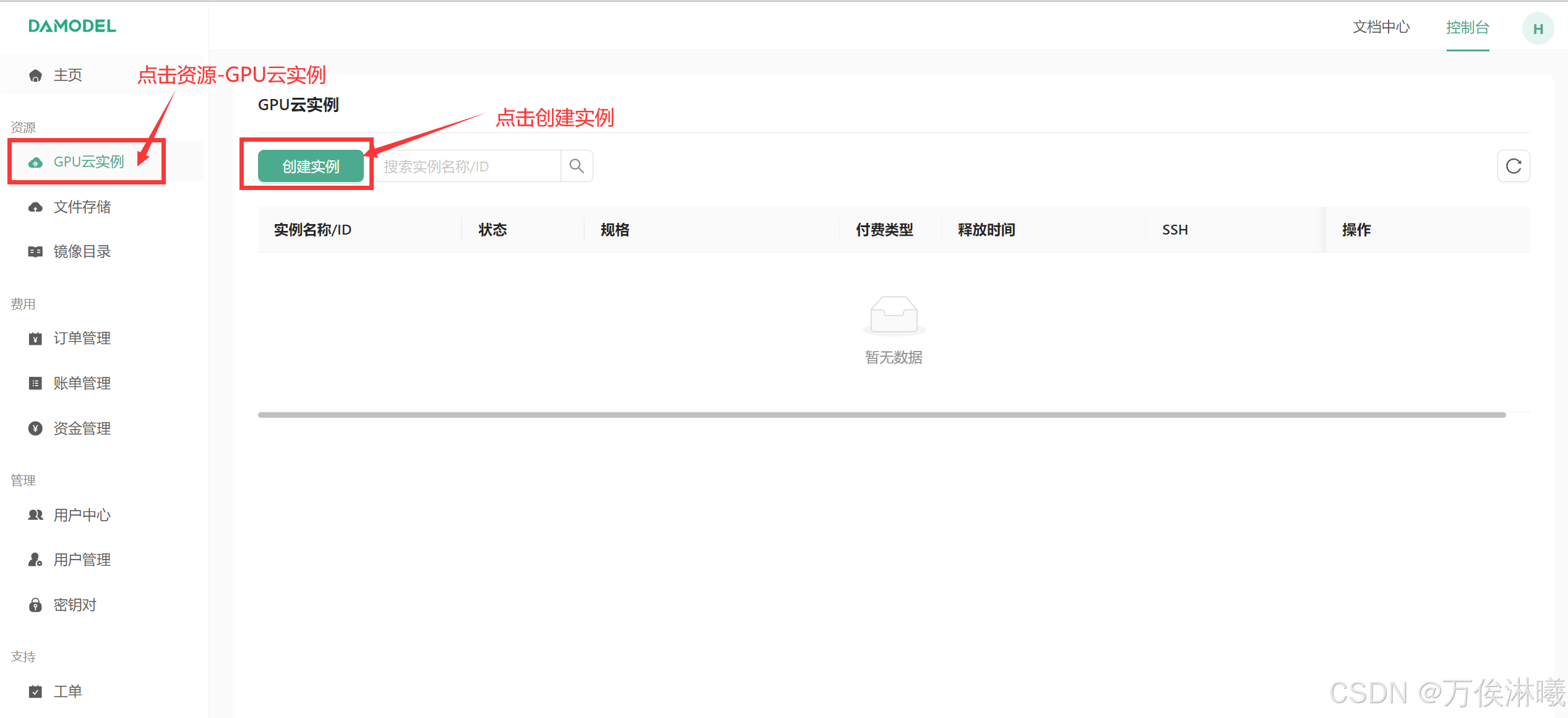
注册成功后进入DAMODEL控制台,点击资源-GPU云实例 --> 点击创建实例:
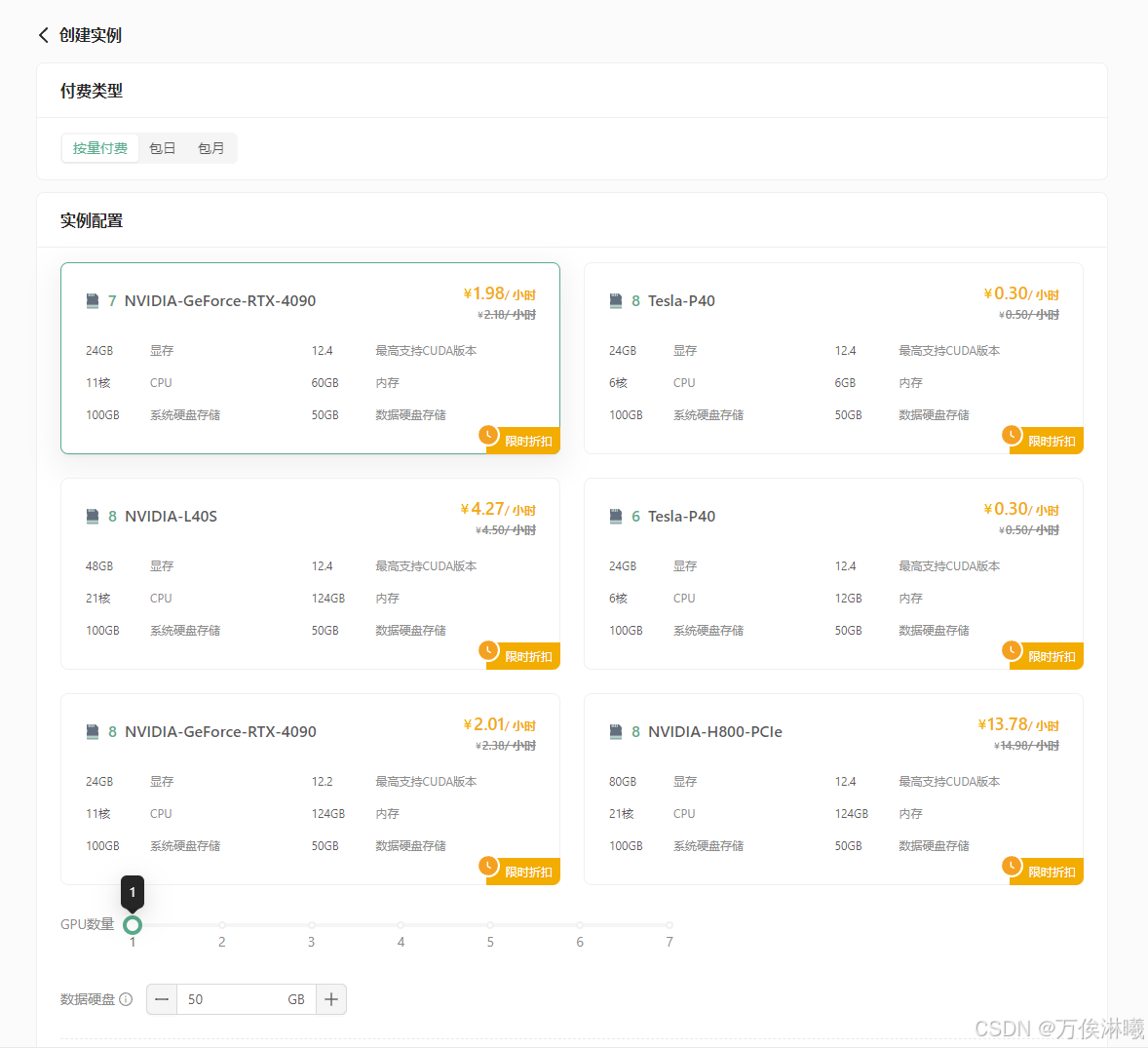
进入创建页面后,首先在实例配置中选择付费类型,一般短期需求可以选择按量付费或者包日,长期需求可以选择包月套餐;
其次选择GPU数量和需求的GPU型号,首次创建实例推荐选择:
按量付费--GPU数量1--NVIDIA-GeForc-RTX-4090,该配置为60GB内存,24GB的显存(本次测试的LLaMA3.1 8B 版本至少需要GPU显存16G)
接下来配置数据硬盘的大小,每个实例默认附带了50GB的数据硬盘,首次创建可以就选择默认大小50GB
继续选择安装的镜像,平台提供了一些基础镜像供快速启动,镜像中安装了对应的基础环境和框架,可通过勾选来筛选框架,这里筛选PyTorch,选择PyTorch 2.4.0。
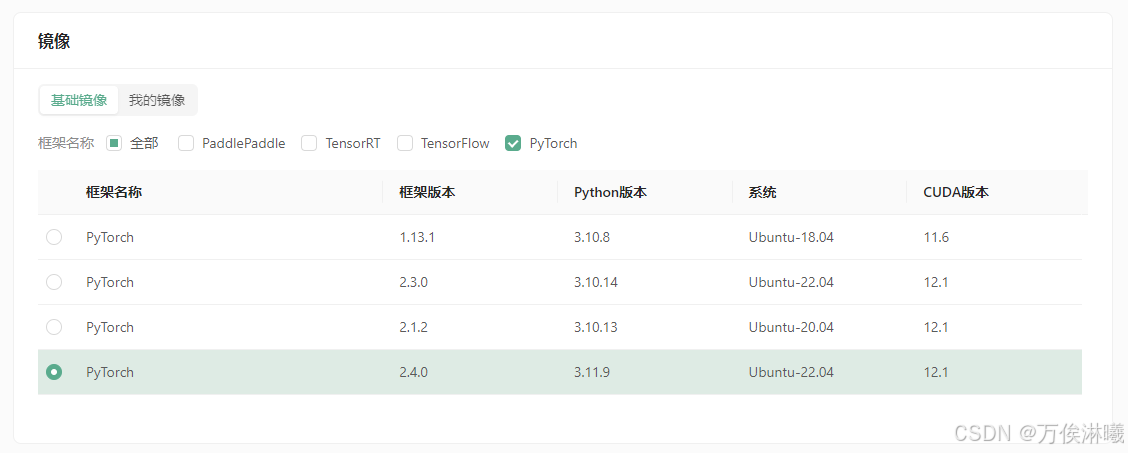
为保证安全登录,创建密钥对,输入自定义的名称,然后选择自动创建并将创建好的私钥保存的自己电脑中并将后缀改为.pem,以便后续本地连接使用。
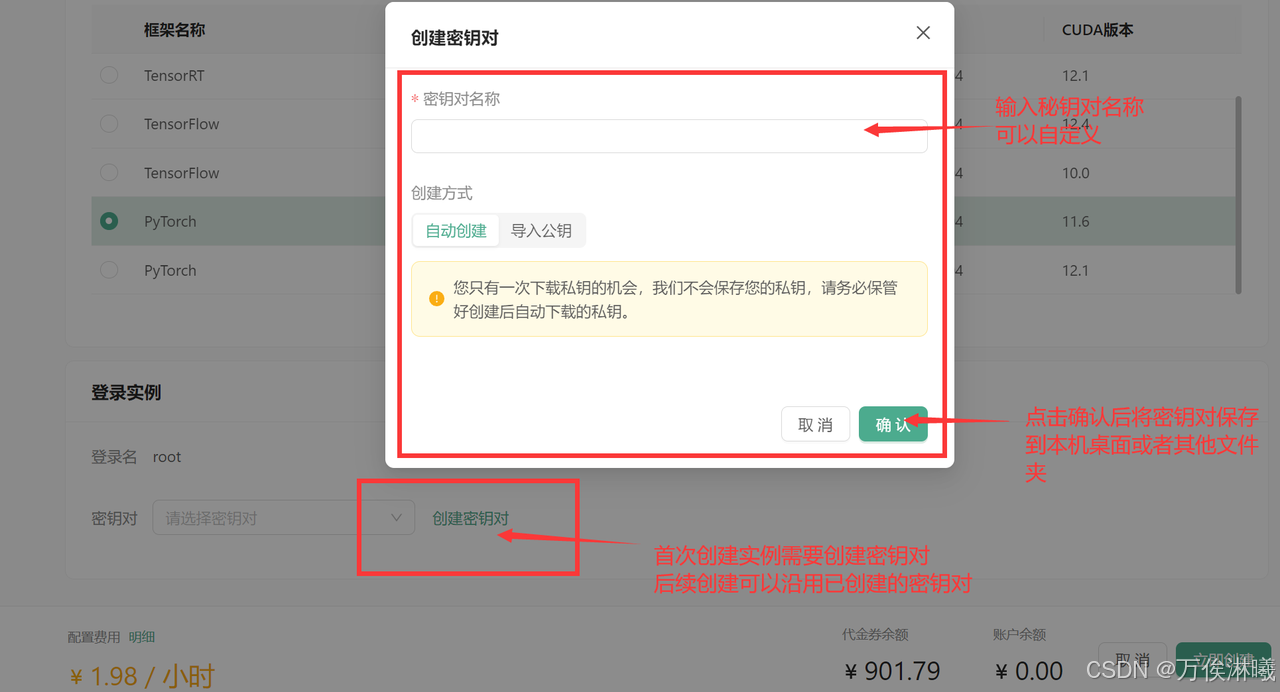
创建好密钥对后,选择刚刚创建好的密钥对,并点击立即创建,等待一段时间后即可启动成功!
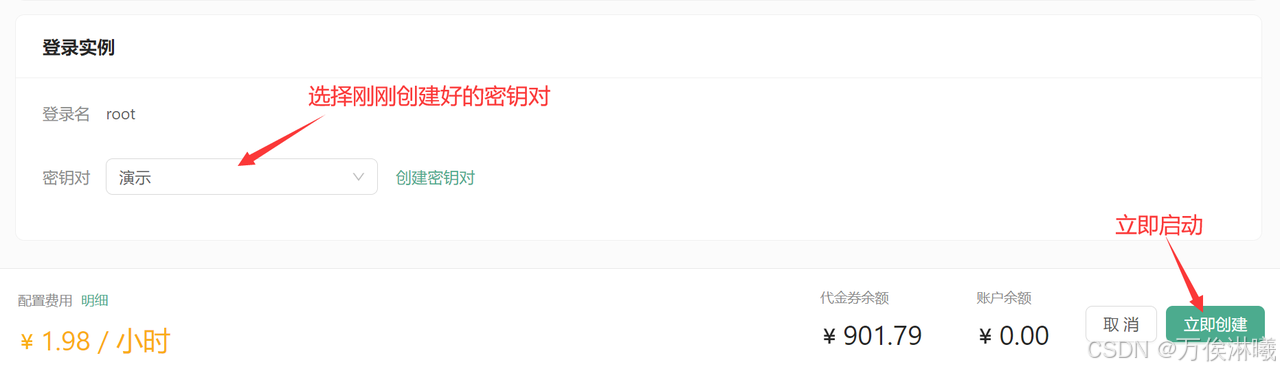
3.2 在DAMODEL部署LLama3.1 8B
等待实例创建成功,在 GPU云实例 中查看实例信息:
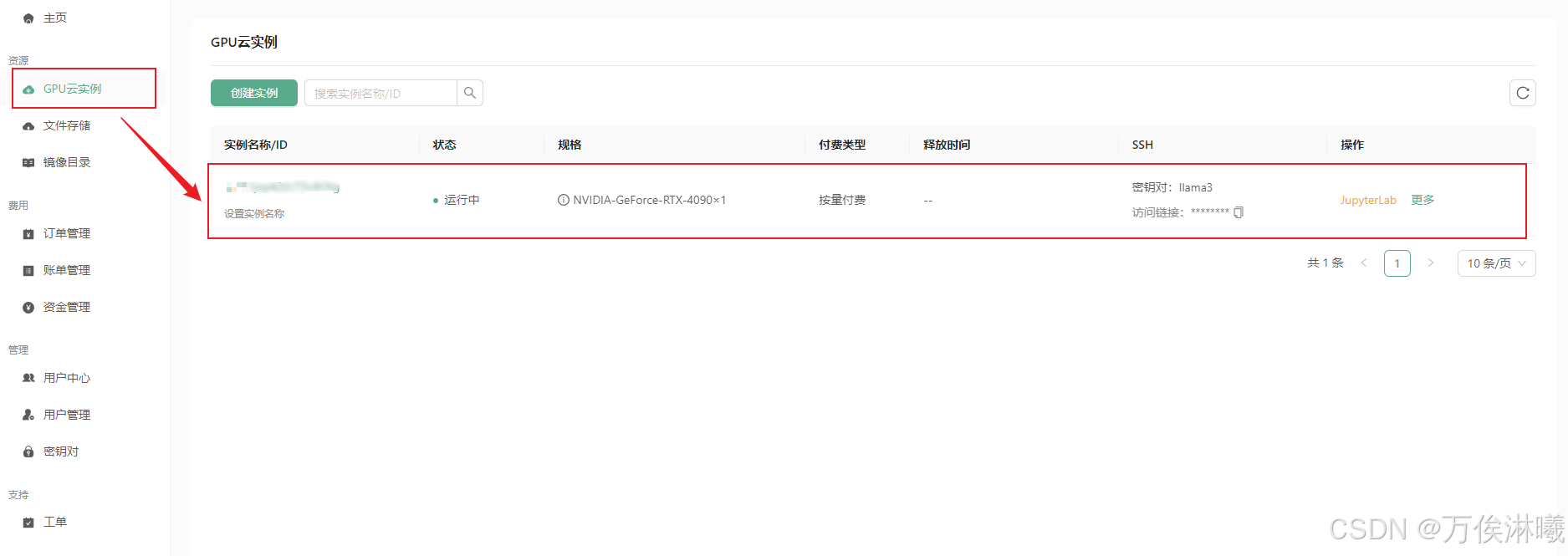
3.2.1 登录实例
有多种方法登录:
3.2.1.1 平台内置JupyterLab
平台提供了在线访问实例的 JupyterLab 入口,可以直接登录实例:
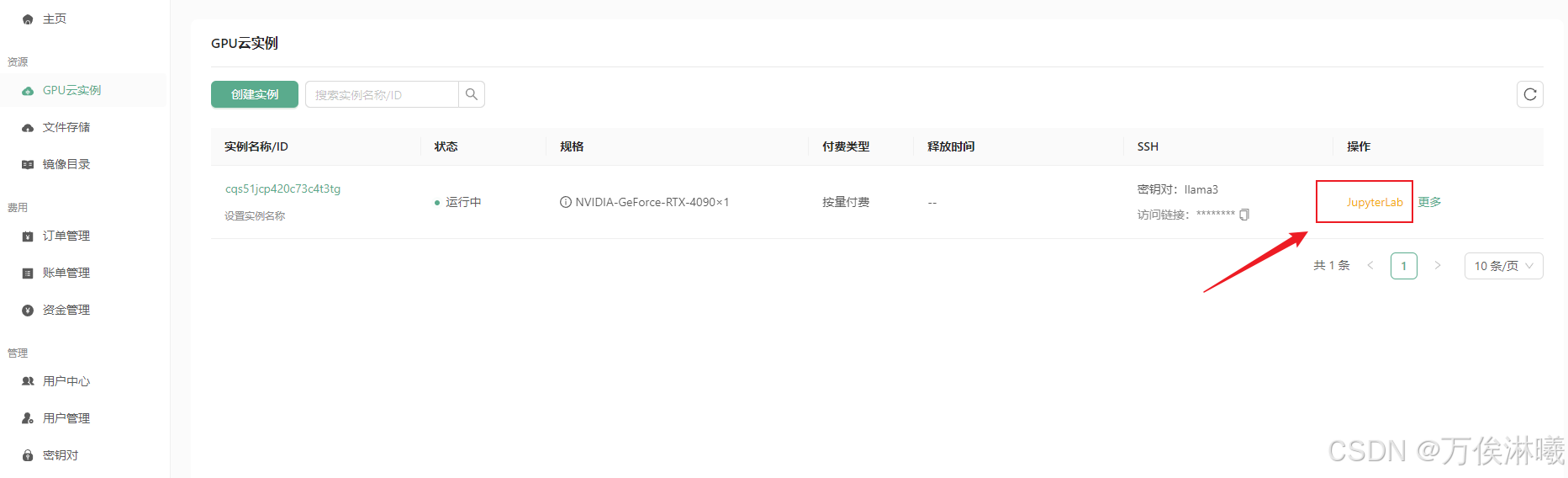
JupyterLab 界面:
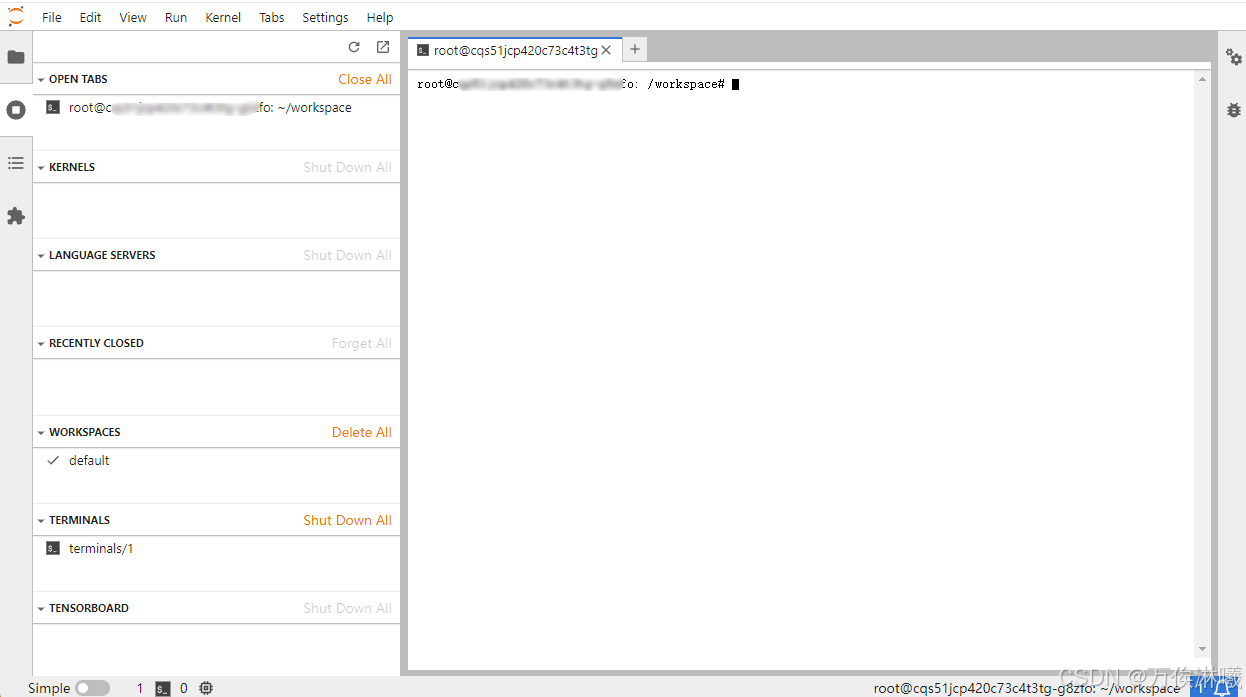
登录后一般会在 /root/workspace 目录下,服务器各个路径具体意义如下:
/:系统盘,替换镜像,重置系统时系统盘数据都会重置。/root/workspace:数据盘,支持扩容,保存镜像时此处数据不会重置。/root/shared-storage:共享文件存储,可跨实例存储。
3.2.1.2 SSH登录
SSH只是登录方式,工具可以是系统自带终端、Xshell、MobaXterm等。
SSH登录一般需要以下 4 个信息:
- 用户名:root
- 远程主机域名或IP(这里使用host域名):实例页面获取
- 端口号:实例页面获取
- 登录密码或密钥(这里使用密钥):前面创建实例时保存到本地的密钥
在实例页面获取主机host和端口号:

复制结果类似如下:
bash
ssh -p 31729 root@gpu-s277r6fyqd.ssh.damodel.com其中,gpu-s277r6fyqd.ssh.damodel.com 即主机host,31729 为端口号。
如果在终端登录,使用如下指令:
指令格式:ssh -i <私钥文件名> -p <端口号> <用户名>@<host地址>
示例:ssh -i private_key.pem -p 31729 root@gpu-s277r6fyqd.ssh.damodel.com如果通过其他工具连接,输入对应信息即可,以 MobaXterm 为例:
首先打开MobaXterm软件,点击左上方Session按钮创建一个新的Session,并选择通过SSH连接登录。
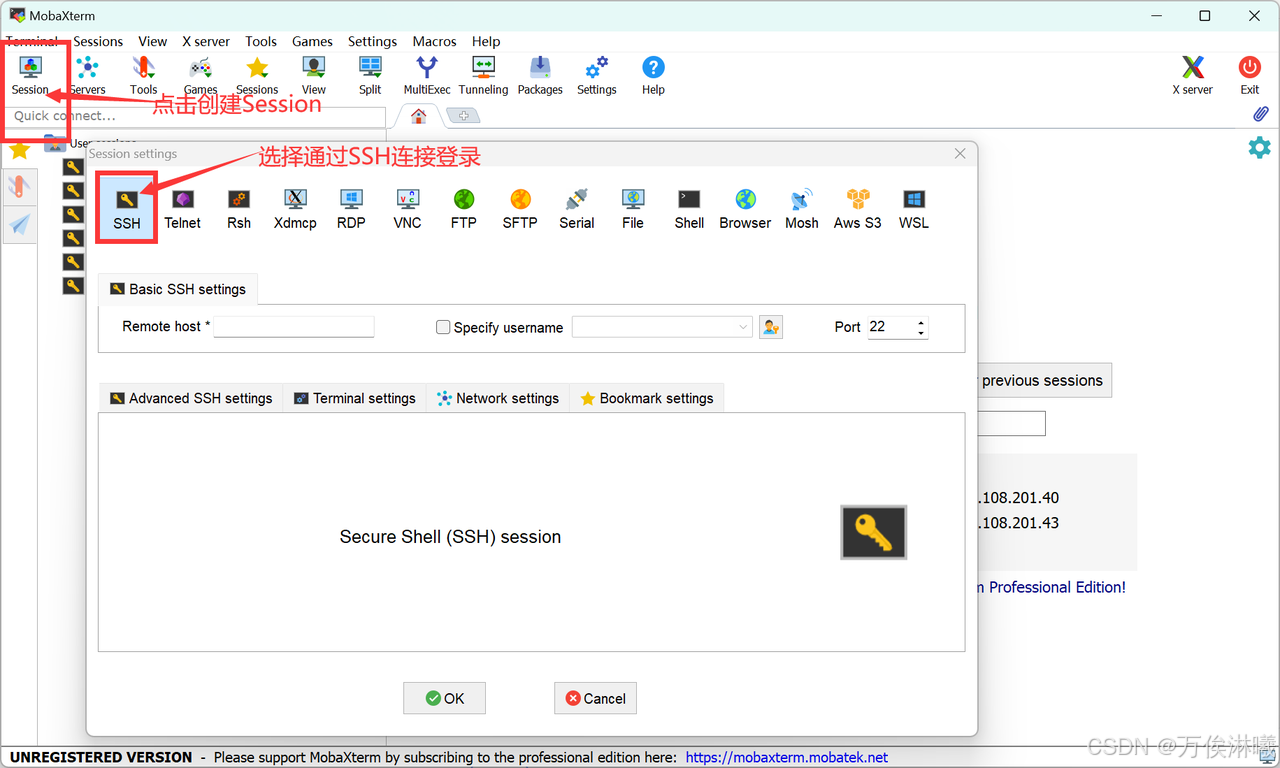
然后将刚刚记录的主机host填入 Remote host 当中,端口号填入 Port 中,
在下方的 Adavanced SSH settings 中勾选 Use private key,并将前面创建实例时保存到本地的密钥导入其中。
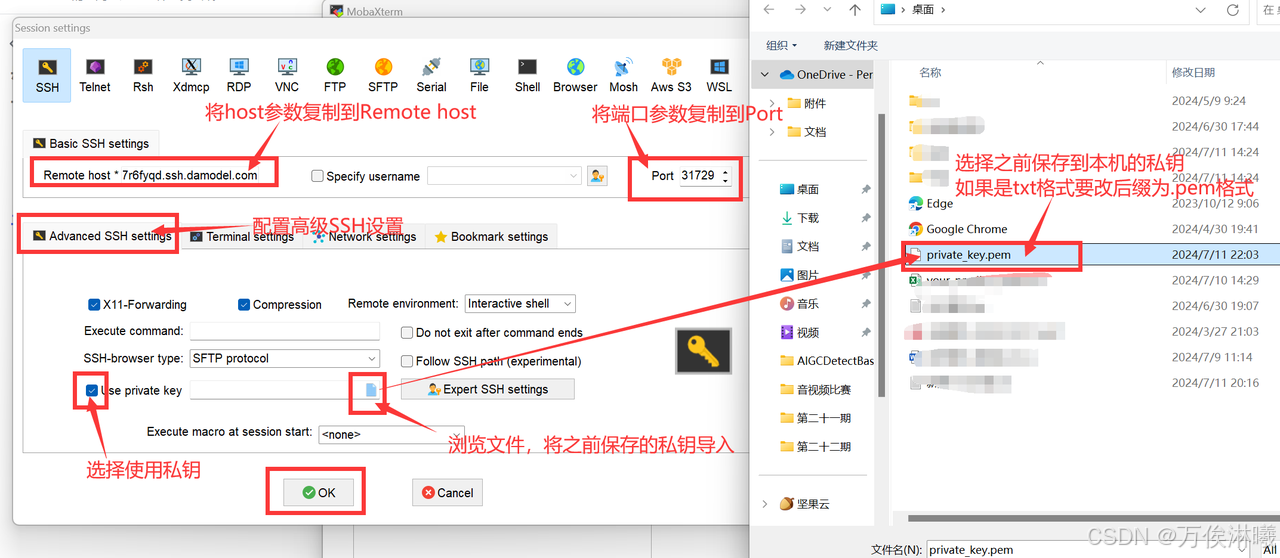
点击ok后,即可看到成功创建了session,输入刚刚记录的用户名root,回车即可连接成功。
显示如下界面后,即连接成功,后续就可以正常通过MobaXterm连接使用服务器了。
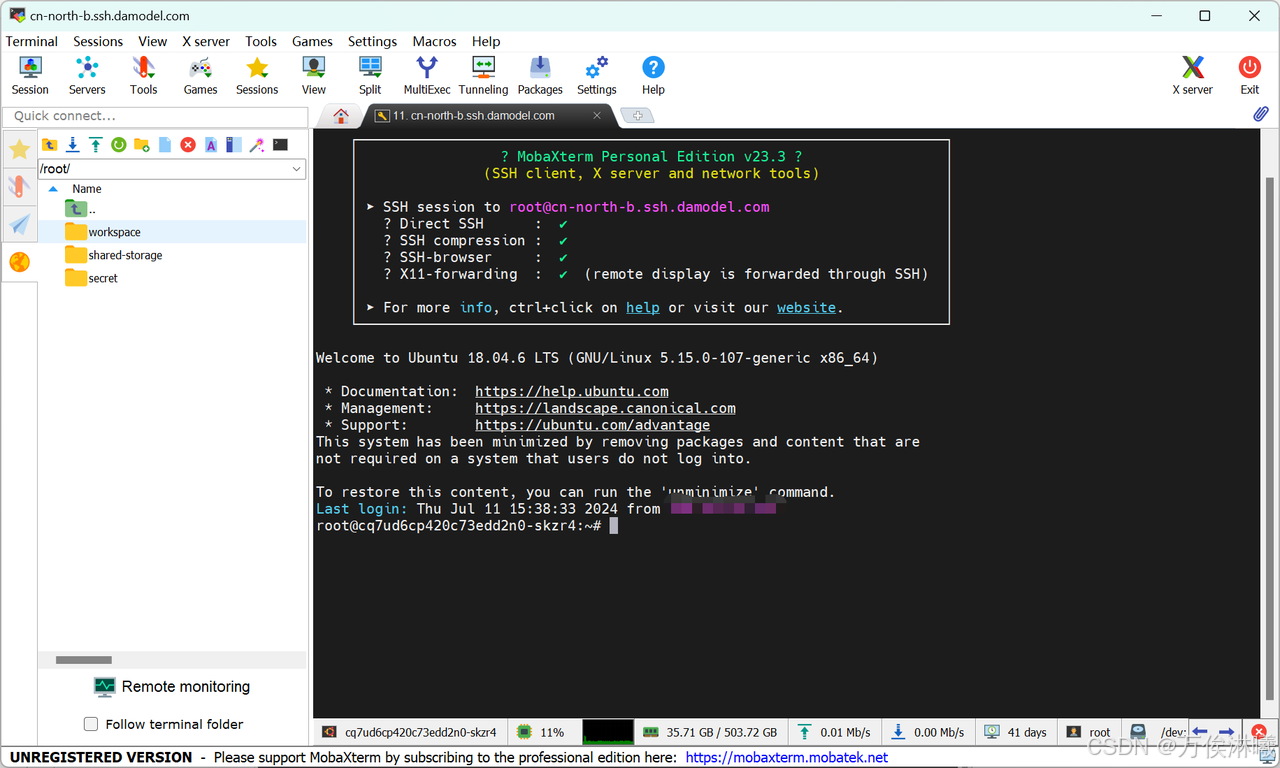
3.2.2 部署LLama3.1
我们使用 conda 管理环境,DAMODEL示例已经默认安装了 conda 24.5.0 ,直接创建环境即可:
bash
conda create -n llama3 python=3.12环境创建好后,使用如下命令切换到新创建的环境:
bash
conda activate llama3继续安装部署LLama3.1需要的依赖:
bash
pip install modelscope==1.11.0
pip install langchain==0.1.15
pip install streamlit==1.36.0
pip install transformers==4.44.0
pip install accelerate==0.32.1安装好后,下载 Llama-3.1-8B 模型,新建 model_download.py 文件并在其中输入以下内容,并运行 python model_download.py 执行下载。
python
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3.1-8B-Instruct', cache_dir='/root/workspace/model', revision='master')模型一共大约 30G,网速慢的话需要等很长时间,不过DAMODEL平台的网速还是不错的。

模型下载好后,准备加载模型及启动Web服务等工作,新建 llamaBot.py 文件并在其中输入以下内容:
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 创建一个标题和一个副标题
st.title("💬 LLaMA3.1 Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")
# 定义模型路径
mode_name_or_path = '/root/workspace/model/LLM-Research/Meta-Llama-3.1-8B-Instruct'
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
# 从预训练的模型中获取tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 从预训练的模型中获取模型,并设置模型参数
model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16).cuda()
return tokenizer, model
# 加载LLaMA3的model和tokenizer
tokenizer, model = get_model()
# 如果session_state中没有"messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 将用户输入添加到session_state中的messages列表中
st.session_state.messages.append({"role": "user", "content": prompt})
# 将对话输入模型,获得返回
input_ids = tokenizer.apply_chat_template(st.session_state["messages"],tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 将模型的输出添加到session_state中的messages列表中
st.session_state.messages.append({"role": "assistant", "content": response})
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(response)
print(st.session_state)在终端中运行以下命令,启动 streamlit 服务,server.port 可以更换端口:
streamlit run llamaBot.py --server.address 127.0.0.1 --server.port 1024可以直接运行该指令,也可以将该指令保存在shell脚本里,运行后提示输入邮箱,可不输入直接回车:

回车后,结果如下,即启动成功:
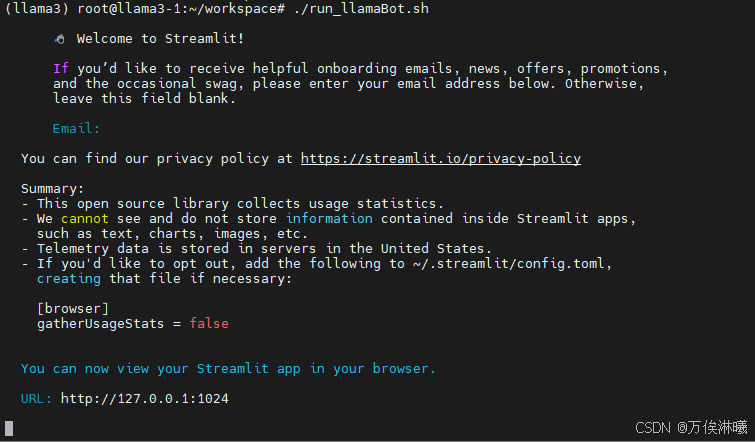
由于云平台服务器没有浏览器,需要在本地访问。
3.3.3 在Web端使用LLama模型推理
由于服务器启动的是localhost IP,不是公网IP,所以本地无法直接访问,需要做一下转发。
使用 MobaXterm 建立ssh隧道,实现远程端到本机端的转发,打开 Tunneling,点击 New SSH tunnel ,
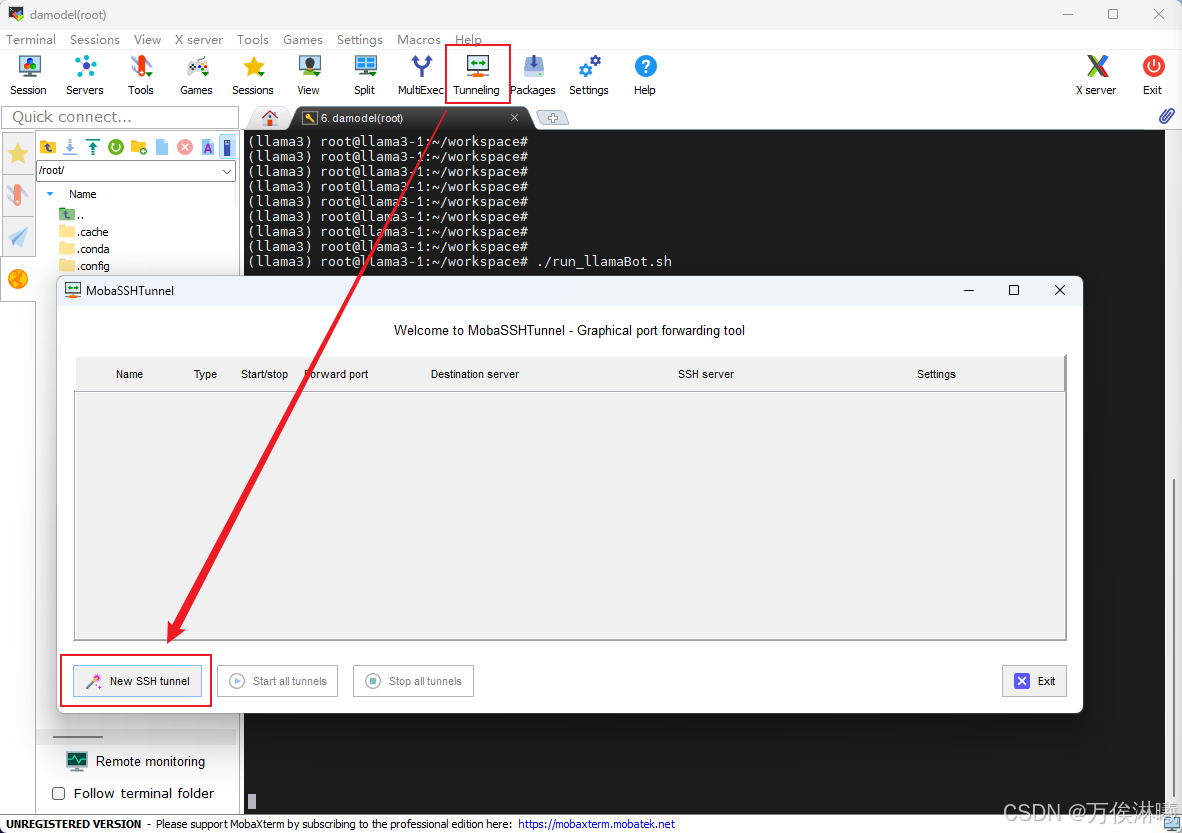
编辑转发信息,点击 Local port dorwarding 弹出配置页面,其中各部分信息说明如下:
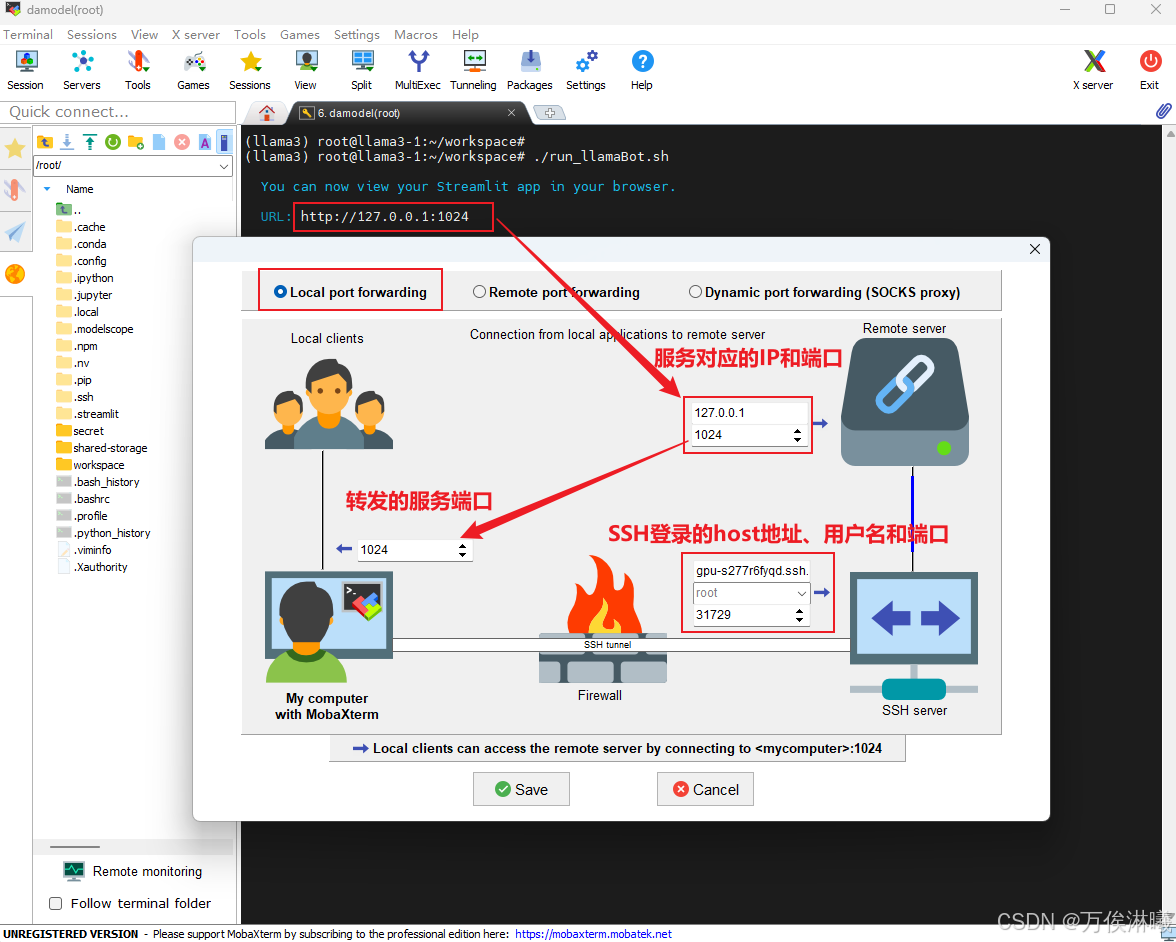
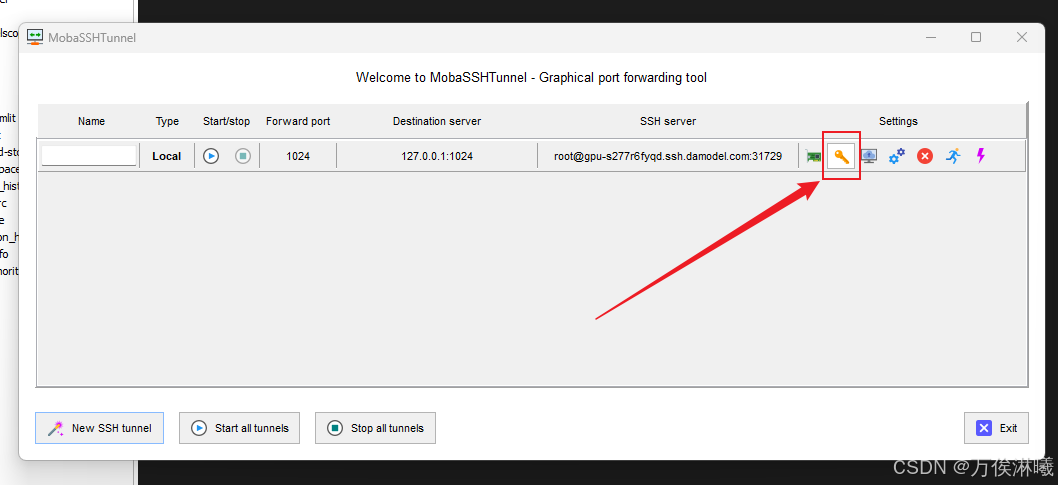
点击 Save 保存配置如下,检查配置无误后点击这个小钥匙,加载上面保存的密钥文件。
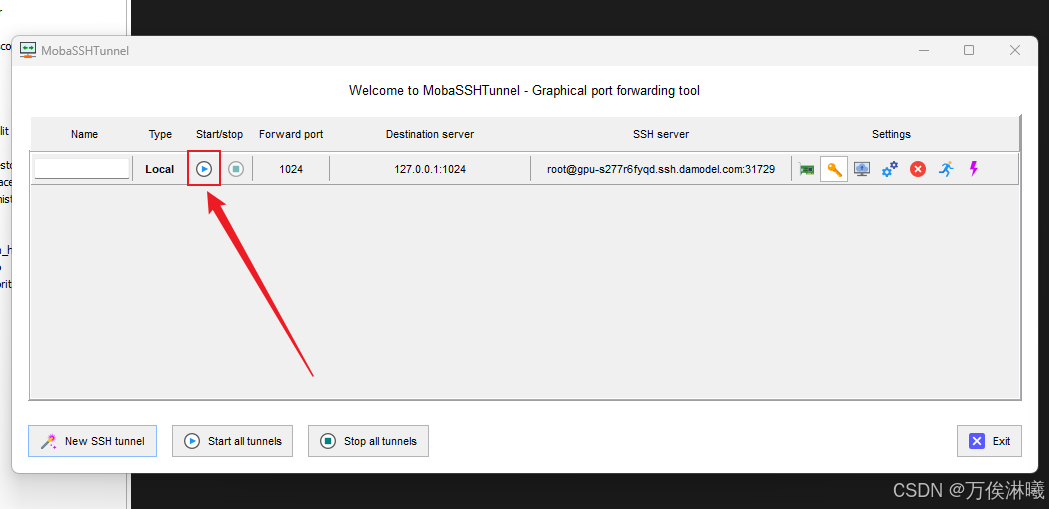
然后点击启动按钮,点击后,启动按钮变灰,旁边的停止按钮变亮,表示启动成功。
此时在浏览器中访问 http://127.0.0.1:1024 ,即可打开LLaMA3.1 Chatbot交互界面,并与其对话:

四、总结
体验 DAMODEL(丹摩智算) 后,整体感觉它是一个非常强大且易用的AI开发云算力平台。对初学者非常友好,新建的实例基本不用再手动部署环境,一些常用的依赖已经帮你安装好,直接上手开发。
不仅如此,它还提供了多种不同的开发环境,可以轻松地选择最熟悉或最适合用户需求的环境来构建、训练和部署应用程序,而无需考虑配置的问题。
总的来说,和现有平台相比, DAMODEL(丹摩智算) 核心在于快速启动,便捷开发,非常适合和各个应用领域结合,快速提供相关的解决方案。
五、粉丝福利 - 丹摩低价狂欢节
点击 ~~~~~~~~~~~~~~~~~~~~~~~~~~ 注册链接 ~~~~~~~~~~~~~~~~~~~~~~~~~~
可享受免费试用,实名认证后还可获得30元代金券。
🔥全场折扣价
全场6折起,部分GPU型号最低0.3元/卡/时。
🔥H800资源扩容
H800算力全新升级,资源扩容!保障用户使用需求,无需排队等待。