第二部分 预训练
第四章 数据准备
4.1 数据来源
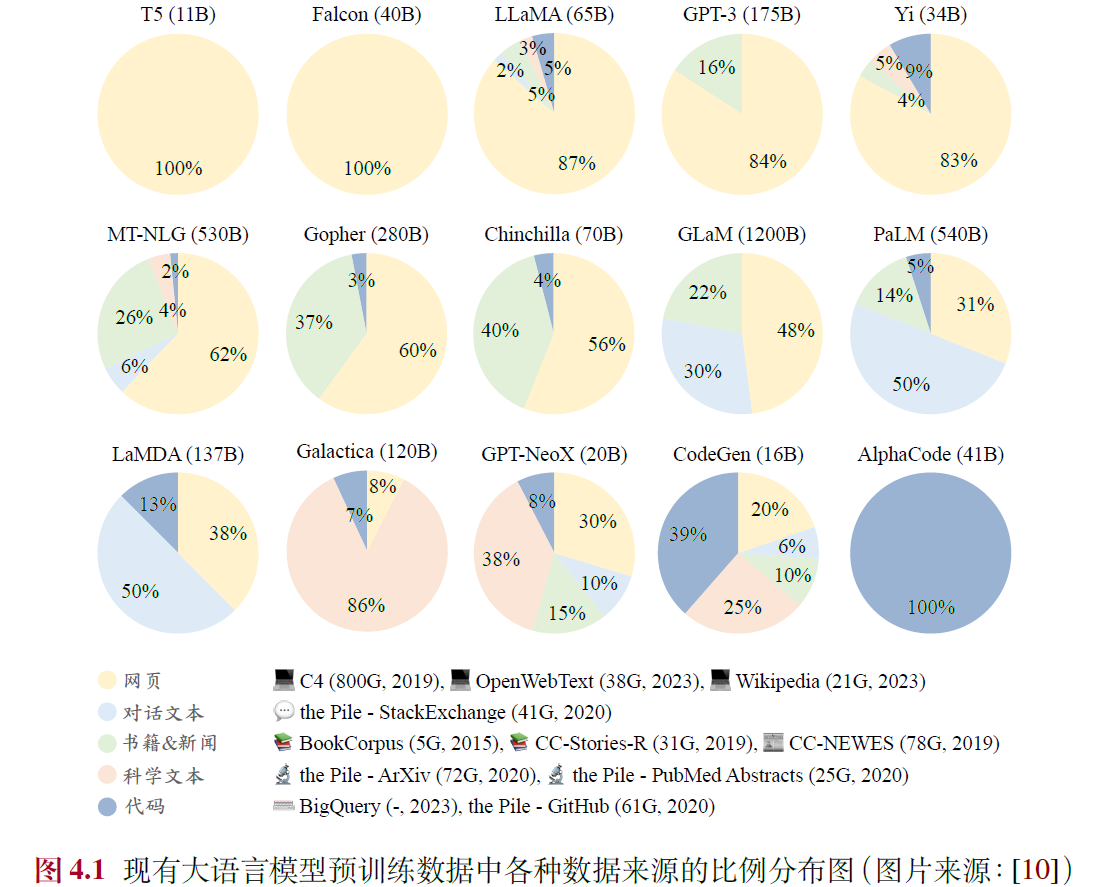
4.1.1 通用文本数据
4.1.2 专用文本数据
4.2 数据预处理

4.2.1 质量过滤
- 基于启发式规则的方法
- 基于语种的过滤:语言识别器筛选中英文,对于多语的维基百科由于数据规模小可直接训
- 基于简单统计指标的过滤


- 基于分类器的方法
- 轻量级模型:效率高,受限于模型能力,FastText
- 可微调的预训练语言模型:可针对性微调,通用性和泛化性不足,BERT、BART、LLaMA
- 闭源大语言模型API:能力较强,成本高,不够灵活,GPT-4、Claude 3
- 可用方案:先用规则再用分类器,分类器可用多种集成
4.2.2 敏感内容过滤
- 过滤有毒内容:毒性文本分类器
- 过滤隐私内容:使用启发式方法,如关键字识别,用特定词元替换
4.2.3 数据去重
- 计算粒度:首先针对数据集和文档级别进行去重,进一步在句子级别实现更为精细的去重
- 用于去重的匹配方法
- 精确匹配算法:后缀数组来匹配最小长度的完全相同子串
- 近似匹配算法:局部敏感哈希(Locality-Sensitive Hashing, LSH),如最小哈希(MinHash)
4.2.4 数据对预训练效果的影响
- 数据数量的影响:训练数据数量越大,模型性能越好,未达到极限
- 数据质量的影响
- 整体质量:质量不好导致不稳定不收敛,同数量下质量越高越好,能减少"幻想"
- 重复数据:可能导致"双下降现象"(训练损失先经历下降然后出现升高再下降的现象),降低利用上下文信息的能力,如果要使用高质量数据重复训练,可以进行改写或针对性生成
- 有偏、有毒、隐私内容:严重不良影响,容易被攻击和诱使生成
- 数据集污染:也称为基准泄漏,尽量不要包含评估测试集
4.2.5 数据预处理实践
- 质量过滤
- 加载预训练好的FastText 语言分类器,为每个输入文本生成一个语言标签,不符合配置文件中语言类别的文本将被过滤。
from utils.evaluator import LangIdentifier
class FilterPassageByLangs():
def __init__(self) -> None:
# 使用LangIdentifier 模块加载已经训练好的fasttext 模型
self.language_identifier = LangIdentifier(model_path="utils/models/fasttext/lid.176.bin")
self.reject_threshold = 0.5
def filter_single_text(self, text: str, accept_lang_list: list) -> bool:
# 使用fasttext 模型给text 打分,每种语言生成一个置信分数
labels, scores = self.language_identifier.evaluate_single_text(text)
# 如果text 所有语言的分数均比reject_threshold 要低,则直接定义为未知语言
if any(score < self.reject_threshold for score in scores):
labels = ["uk"]
accept_lang_list = [each.lower() for each in accept_lang_list]
# 如果分数最高的语言标签不在配置文件期望的语言列表中,则丢弃该文本
if labels[0] not in accept_lang_list:
return True
return False
- 去重
- 句子级去重:对文本包含的所有句子(每行对应一个句子)计算𝑛 元组,对于相邻的句子之间𝑛 元组的Jaccard 相似度超过设定阈值的都将会被过滤
import string
import re
from nltk.util import ngrams
class CleanerDedupLineByNgram():
def __init__(self):
# 定义行分隔符和元组分隔符
self.line_delimiter = list("\n")
chinese_punctuation = ",。!?:;""''()《》【】、|---"
self.gram_delimiter = list(string.punctuation) + list(chinese_punctuation) + [' ']
def clean_single_text(self, text: str, n: int = 5, thre_sim: float = 0.95) -> str:
# 依靠行分隔符分割所有行
lines = [each for each in re.split('|'.join(map(re.escape, self.line_delimiter)), text) if each != '']
lineinfo, last = list(), {}
for idx, line in enumerate(lines): # 计算每行的n 元组
# 依靠元组分隔符分割所有N 元组,并将其暂时存储到lineinfo 里
grams = [each for each in re.split('|'.join(map(re.escape, self.gram_delimiter)), line) if each != '']
computed_ngrams = list(ngrams(grams, min(len(grams), n)))
lineinfo.append({ "lineno": idx, "text": line, "n": min(len(grams), n), "ngrams": computed_ngrams, "keep": 0 })
for idx, each in enumerate(lineinfo): # 过滤掉和相邻行之间n 元组的 Jaccard 相似度超过 thre_sim 的行
if last == {}:
each["keep"], last = 1, each
else:
# 计算相邻行间的Jaccard 相似度
ngrams_last, ngrams_cur = set(last["ngrams"]), set(each["ngrams"])
ngrams_intersection, ngrams_union =
len(ngrams_last.intersection(ngrams_cur)),
len(ngrams_last.union(ngrams_cur))
jaccard_sim = ngrams_intersection / ngrams_union if ngrams_union != 0 else 0
if jaccard_sim < thre_sim:
each["keep"], last = 1, each
# 将所有未被过滤掉的N 元组重新拼接起来
text = self.line_delimiter[0].join([each["text"] for each in lineinfo if each["keep"] == 1])
return text
- 隐私过滤
- 去除身份证号:对每个输入的文本,下面使用正则替换的方式将匹配到的身份证号替换为特定字符串
from utils.rules.regex import REGEX_IDCARD
from utils.cleaner.cleaner_base import CleanerBase
class CleanerSubstitutePassageIDCard(CleanerBase):
def __init__(self):
super().__init__()
def clean_single_text(self, text: str, repl_text: str = "**MASKED**IDCARD**") -> str:
# 使用正则表达式REGEX_IDCARD 匹配身份证号,用repl_text 代替
return self._sub_re(text=text, re_text=REGEX_IDCARD, repl_text=repl_text)
4.3 词元化(分词)
4.3.1 BPE 分词
- 流程:从一组基本符号(例如字母和边界字符)开始,迭代地寻找语料库中的两个相邻词元 ,并将它们替换为新的词元,这一过程被称为合并。
- 合并的选择标准是计算两个连续词元的共现频率,也就是每次迭代中,最频繁出现的一对词元会被选择与合并。合并过程将一直持续达到预定义的词表大小。
import re
from collections import defaultdict
from collections import Counter
def extract_frequencies(sequence):
"""
给定一个字符串,计算字符串中的单词出现的频率,并返回词表(一个词到频率的映射字典)。
"""
token_counter = Counter()
for item in sequence:
tokens = ' '.join(list(item)) + ' </w>'
token_counter[tokens] += 1
return token_counter
def frequency_of_pairs(frequencies):
"""
给定一个词频字典,返回一个从字符对到频率的映射字典。
"""
pairs_count = Counter()
for token, count in frequencies.items():
chars = token.split()
for i in range(len(chars) - 1):
pair = (chars[i], chars[i+1])
pairs_count[pair] += count
return pairs_count
def merge_vocab(merge_pair, vocab):
"""
给定一对相邻词元和一个词频字典,将相邻词元合并为新的词元,并返回新的词表。
"""
re_pattern = re.escape(' '.join(merge_pair))
pattern = re.compile(r'(?<!\S)' + re_pattern + r'(?!\S)')
updated_tokens = {pattern.sub(''.join(merge_pair), token): freq for token, freq in vocab.items()}
return updated_tokens
def encode_with_bpe(texts, iterations):
"""
给定待分词的数据以及最大合并次数,返回合并后的词表。
"""
vocab_map = extract_frequencies(texts)
for _ in range(iterations):
pair_freqs = frequency_of_pairs(vocab_map)
if not pair_freqs:
break
most_common_pair = pair_freqs.most_common(1)[0][0]
vocab_map = merge_vocab(most_common_pair, vocab_map)
return vocab_map
num_merges = 1000
bpe_pairs = encode_with_bpe(data, num_merges)

4.3.2 WordPiece 分词
- 和BPE分词的想法非常相似,都是通过迭代合并连续的词元,但是合并的选择标准略有不同。
- 提前训练语言模型进行评分,或使用以下计算方式计算得分

4.3.3 Unigram 分词
- 从语料库的一组足够大的字符串或词元初始集合开始,迭代地删除其中的词元,直到达到预期的词表大小
4.3.4 分词器的选用
- 无损重构:其分词结果能够准确无误地还原为原始输入文本
- 高压缩率:在给定文本数据的情况下,经分词处理后的词元数量尽可能少,实现高效的文本编码和存储
- 压缩率计算 :

4.4 数据调度
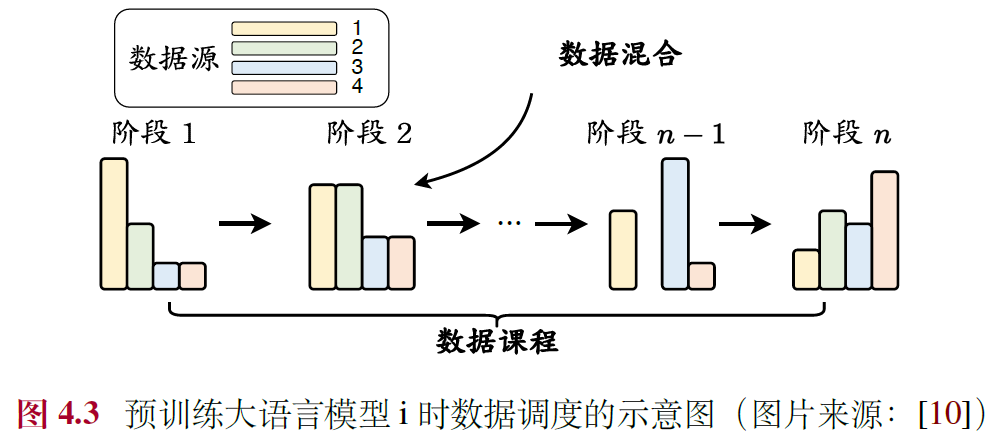
4.4.1 数据混合
- 典型数据分布:参考图4.1,典型的LLaMA 包括超过80%的网页数据、6.5%代码、4.5%的书籍以及2.5% 科学数据,可作为重要参考
- 数据混合策略:增加数据源的多样性、优化数据混合、优化特定能力
- 建议:从小模型上探索最优配比再迁移到大模型上

4.4.2 数据课程
- 定义:按照特定顺序训练 / 不同阶段使用不同配比,工作集中在继续预训练(Continual Pre-training)
- 实用方法:基于专门构建的评测基准监控大语言模型的关键能力的学习过程,然后在预训练期间动态调整数据的混合配比,基本技能→目标技能
- 代码能力:2T 通用词元 → 500B 代码相关的词元 →100B Python 代码相关的词元
- 数学能力:2T 通用词元 → 500B 代码相关的词元 →50∼200B 数学相关的词元
- 长文本能力:2.5T 词元,4K 上下文窗口 → 20B 词元,16K 上下文窗口