0.简介
DQN算法作为基于值函数的方法代表,基于值函数的方法只学习一个价值函数。REINFORCE算法作为基于策略的方法代表,基于策略的方法只学习一个策略函数。Actor-Critic算法则结合了两种学习方法,其本质是基于策略的方法,因为其目标是优化一个带参的策略,只是会额外学习价值函数帮助策略函数更好地学习。
我们回顾一下在 REINFORCE 算法中,目标函数的梯度中有一项轨迹回报,来指导策略的更新。而值函数的概念正是基于期望回报,我们能不能考虑拟合一个值函数来指导策略进行学习呢?这正是 Actor-Critic 算法所做的。让我们先回顾一下策略梯度的形式,在策略梯度中,我们可以把梯度写成下面这个形式:其中 ψ t 可以有很多种形式:
在 REINFORCE 的最后部分,我们提到了 REINFORCE通过蒙特卡洛采样的方法对梯度的估计是无偏的,但是方差非常大,我们可以用第三种形式引入基线 (baseline) b ( s t ) 来减小方差。此外我们也可以采用 Actor-Critic 算法,估计 一个动作价值函数 Q 来代替蒙特卡洛采样得到的回报,这便是第 4 种形式。这个时候,我们也可以把状态价值函数 V 作为基线,从偍牧但是用神经网络进行估计的方法可以减小方差、提高鲁棒性。除此之外,REINFORCE 算法基于蒙特卡洛采样,只能在序列结束后进行更新,而 Actor-Critic 的方法则可以在每一步之后都进行更新。
我们将 Actor-Critic 分为两个部分: 分别是 Actor (策略网络) 和 Critic (价值网络):
- Critic 要做的是通过 Actor 与环境交互收集的数据学习一个价值函数,这个价值函数会用于帮助 Actor 进行更新策略。
- Actor 要做的则是与环境交互,并利用 Ctitic 价值函数来用策略梯度学习一个更好的策略。
与 DQN 中一样,我们采取类似于目标网络的方法,上式中 r + γ V ω ( s t + 1 )作为时序差分目标,不会产生梯度来更新价值函数。所以价值函数的梯度为
然后使用梯度下降方法即可。接下来让我们总体看看 Actor-Critic 算法的流程吧!
- 初始化策略网络参数 θ ,价值网络参数 ω
- 不断进行如下循环 (每个循环是一条序列) :
。 用当前策略 π θ 平样轨 迹 { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 ... }
。 为每一步数据计算: δ t = r t + γ V ω ( s t + 1 ) − V ω ( s )
。 更新价值参数 w = w + α ω ∑ t δ t ∇ ω V ω ( s )
。 更新策略参数 θ = θ + α θ ∑ t δ t ∇ θ log π θ ( a ∣ s )
好了!这就是 Actor-Critic 算法的流程啦,让我们来用代码实现它看看效果如何吧!
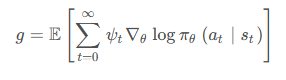

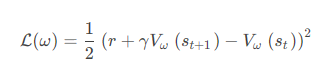
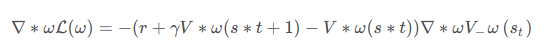
1.导库
python
import gym
import torch
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm2.策略网络PolicyNet定义
python
class PolicyNet(torch.nn.Module):#策略网络
def __init__(self,statedim,hiddendim,actiondim):
super(PolicyNet,self).__init__()
self.fc1=torch.nn.Linear(statedim,hiddendim)
self.fc2=torch.nn.Linear(hiddendim,actiondim)
def forward(self,x):
x=torch.nn.functional.relu(self.fc1(x))
return torch.nn.functional.softmax(self.fc2(x),dim=1)3.价值网络ValueNet定义
python
class ValueNet(torch.nn.Module):#价值网络
def __init__(self,statedim,hiddendim):
super(ValueNet,self).__init__()
self.fc1=torch.nn.Linear(statedim,hiddendim)
self.fc2=torch.nn.Linear(hiddendim,1)
def forward(self,x):
x=torch.nn.functional.relu(self.fc1(x))
return self.fc2(x)4.ActorCritic算法实现
python
class ActorCritic:#演员-评论家算法
def __init__(self,statedim,hiddendim,actiondim,actor_learningrate,critic_learningrate,gamma,device):
self.actor=PolicyNet(statedim,hiddendim,actiondim).to(device)#策略网络
self.critic=ValueNet(statedim,hiddendim).to(device)#价值网络
self.actor_optimizer=torch.optim.Adam(self.actor.parameters(),lr=actor_learningrate)#策略网络优化器
self.critic_optimizer=torch.optim.Adam(self.critic.parameters(),lr=critic_learningrate)#价值网络优化器
self.gamma=gamma
self.device=device
def takeaction(self,state):#根据策略网络采取动作
state=torch.tensor([state],dtype=torch.float).to(self.device)
probs=self.actor(state)
actiondist=torch.distributions.Categorical(probs)
action=actiondist.sample()
return action.item()#返回选择的动作的索引的标量形式
def update(self,transitiondist):#更新策略网络和价值网络
states,actions,rewards,nextstates,dones=transitiondist["states"],transitiondist["actions"],transitiondist["rewards"],transitiondist["nextstates"],transitiondist["dones"]
states=torch.tensor(states,dtype=torch.float).to(self.device)
actions=torch.tensor(actions).view(-1,1).to(self.device)
rewards=torch.tensor(rewards,dtype=torch.float).view(-1,1).to(self.device)
nextstates=torch.tensor(nextstates,dtype=torch.float).to(self.device)
dones=torch.tensor(dones,dtype=torch.float).view(-1,1).to(self.device)
td_target=rewards+self.gamma*self.critic(nextstates)*(1-dones)#时序差分目标
td_delta=td_target-self.critic(states)#时序差分误差
log_probs=torch.log(self.actor(states).gather(1,actions))
#.detach() 来创建一个与原始张量值相同但不可训练的副本。这个副本可以在不影响原始张量的情况下进行各种操作,并且不会在反向传播中被更新。
actor_loss=torch.mean(-log_probs*td_delta.detach())#策略网络的损失函数;#.detach()的作用是将这个张量从计算图中分离出来,这样在计算损失时不会对其进行反向传播,通常是为了防止某些不希望被更新的部分被意外更新。
critic_loss=torch.mean(torch.nn.functional.mse_loss(self.critic(states),td_target.detach()))#均方差损失函数
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()#计算策略网络的梯度
critic_loss.backward()#计算价值网络的梯度
self.actor_optimizer.step()#策略网络参数更新
self.critic_optimizer.step()#价值网络参数更新5.训练本算法的函数实现
python
def train_on_policy_agent(env,agent,episodesnum,pbarnum,printreturnnum,seedid):#训练演员-评论家算法
returnlist=[]
for k in range(pbarnum):
with tqdm(total=int(episodesnum/pbarnum),desc='Iteration %d' % k) as pbar:
for episode in range(int(episodesnum/pbarnum)):
episodereturn=0
transitiondist={"states":[],"actions":[],"nextstates":[],"rewards":[],"dones":[]}
state=env.reset(seed=seedid)[0]
done=False
while not done:
action=agent.takeaction(state)
nextstate,reward,done,truncated,_=env.step(action)
done=done or truncated
transitiondist["states"].append(state)
transitiondist["actions"].append(action)
transitiondist["nextstates"].append(nextstate)
transitiondist["rewards"].append(reward)
transitiondist["dones"].append(done)
state=nextstate
episodereturn+=reward
returnlist.append(episodereturn)
agent.update(transitiondist)
if (episode+1)%(printreturnnum)==0:
pbar.set_postfix({"episode":"%d"%(episodesnum/pbarnum*k+episode+1),"return":"%.3f"%np.mean(returnlist[-printreturnnum:])})
pbar.update(1)
return returnlist6.移动平滑处理时间序列函数实现
python
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))7.参数配置
python
actor_learningrate=1e-3
critic_learningrate=1e-2
episodesnum=1000
hiddendim=128
gamma=0.98
pbarnum=10
printreturnnum=10
seedid=0
device=torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")8.车杆环境实验
python
env=gym.make("CartPole-v1")#env=gym.make("CartPole-v1",render_mode="human")
env.reset(seed=seedid)
torch.manual_seed(seedid)
statedim=env.observation_space.shape[0]
actiondim=env.action_space.n
agent=ActorCritic(statedim,hiddendim,actiondim,actor_learningrate,critic_learningrate,gamma,device)
returnlist=train_on_policy_agent(env,agent,episodesnum,pbarnum,printreturnnum,seedid)
episodelist=list(range(len(returnlist)))
plt.plot(episodelist,returnlist)
plt.xlabel("Episodes")
plt.ylabel("Returns")
plt.title("Actor-Critic on {}-{}".format(env.spec.name,env.spec.id))
plt.show()
mvreturn=moving_average(returnlist,9)
plt.plot(episodelist,mvreturn)
plt.xlabel("Episodes")
plt.ylabel("Returns")
plt.title("Actor-Critic on {}-{}".format(env.spec.name,env.spec.id))
plt.show()9.实验结果
Actor-Critic算法很快收敛到最优策略,训练过程非常稳定,抖动情况与REINFORCE算法相比有了明显改进,这说明价值函数的引入减少了方差。



10.小结
Actor-Critic算法是基于值函数和基于策略的方法的叠加,价值模块Critic在策略模块Actor采样的数据中学习分辨什么是好的动作,什么是不好的动作,进而指导Actor进行策略更新,随着Actor训练不断进行,与环境交互产生的数据分布也发生改变,这需要Critic尽快适应新数据分布并给出好的判别。TRPO、PPO、DDPG、SAC等深度强化学习算法都是在Actor-Critic算法基础上进行发展改进的,其作为基础,深入理解大有裨益。