Xinference实战指南:全面解析LLM大模型部署流程,携手Dify打造高效AI应用实践案例,加速AI项目落地进程
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。通过 Xorbits Inference,可以轻松地一键部署你自己的模型或内置的前沿开源模型
- 官网:https://xorbits.cn/inference
- github:https://github.com/xorbitsai/inference/tree/main
- 官方手册:https://inference.readthedocs.io/zh-cn/latest/index.html


- Xinference功能特点:
模型推理:大语言模型,语音识别模型,多模态模型的部署流程被大大简化。一个命令即可完成模型的部署工作。前沿模型:框架内置众多中英文的前沿大语言模型,包括 baichuan,chatglm2 等,一键即可体验!内置模型列表还在快速更新中!异构硬件:通过 ggml,同时使用你的 GPU 与 CPU 进行推理,降低延迟,提高吞吐!接口调用:提供多种使用模型的接口,包括 OpenAI 兼容的 RESTful API(包括 Function Calling),RPC,命令行,web UI 等等。方便模型的管理与交互。集群计算,分布协同: 支持分布式部署,通过内置的资源调度器,让不同大小的模型按需调度到不同机器,充分使用集群资源。开放生态,无缝对接: 与流行的三方库无缝对接,包括 LangChain,LlamaIndex,Dify、FastGPT、RAGFlow、Chatbox。
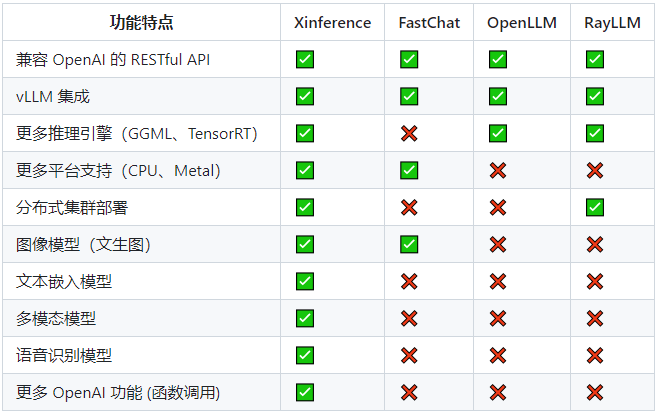
1. 模型支持
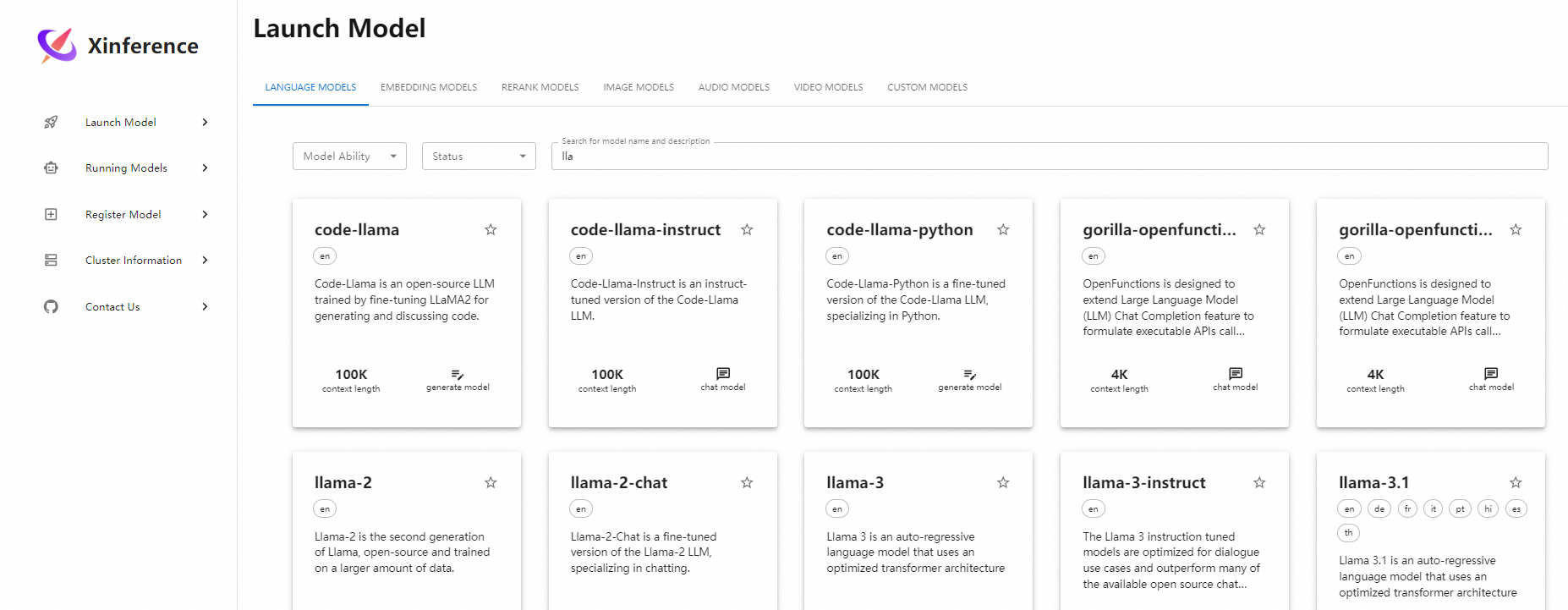
1.1 大模型支持
参考链接:https://inference.readthedocs.io/zh-cn/latest/models/builtin/llm/index.html
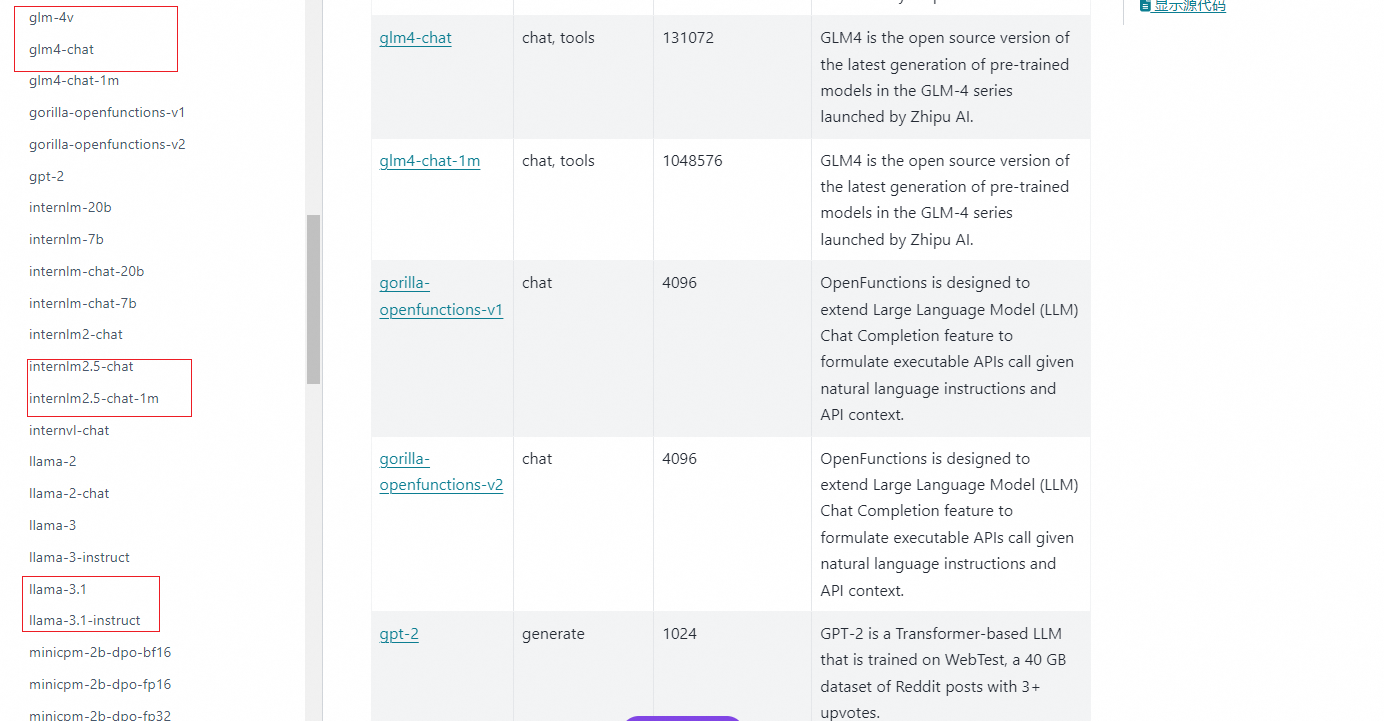
所有主流模型都兼容支持
1.2 嵌入模型
参考链接:https://inference.readthedocs.io/zh-cn/latest/models/builtin/embedding/index.html
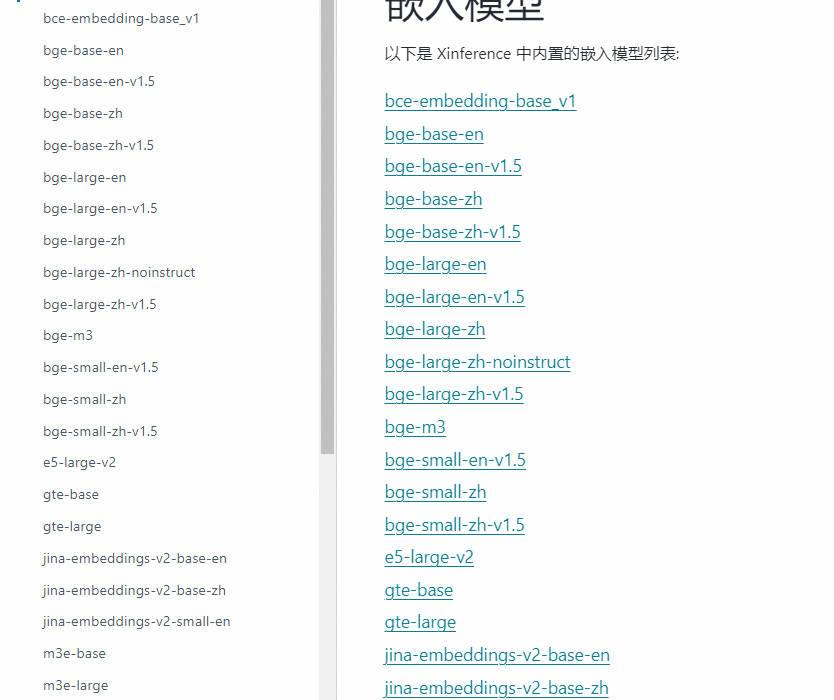
开源的词嵌入模型也都支持
- BAAI-bge-large-zh-v1.5
BAAI Embedding语义向量微调参考链接
1.3 重排序模型(Reranker)
参考链接:https://inference.readthedocs.io/zh-cn/latest/models/builtin/rerank/index.html

- bge-reranker-large
BAAI Cross-Encoder语义向量微调参考链接
1.4 IMAGE 模型
Xinference 还支持图像模型,使用图像模型可以实现文生图、图生图等功能。Xinference 内置了几种图像模型,分别是 Stable Diffusion(SD)的各个版本。部署方式和文本模型类似,都是在 WebGUI 界面上启动模型即可,无需进行参数选择,但因为 SD 模型比较大,在部署图像模型前请确保服务器上有 50GB 以上的空间。
1.5 CUSTOM 模型
语音模型是 Xinference 最近新增的功能,使用语音模型可以实现语音转文字、语音翻译等功能。在部署语音模型之前,需要先安装ffmpeg组件,以 Ubuntu 操作系统为例,安装命令如下:
sudo apt update && sudo apt install ffmpeg1.6 模型来源
Xinference 默认是从 HuggingFace 上下载模型,如果需要使用其他网站下载模型,可以通过设置环境变量XINFERENCE_MODEL_SRC来实现,使用以下代码启动 Xinference 服务后,部署模型时会从 Modelscope5 上下载模型:
XINFERENCE_MODEL_SRC=modelscope xinference-local1.7 模型独占 GPU
在 Xinference 部署模型的过程中,如果你的服务器只有一个 GPU,那么你只能部署一个 LLM 模型或多模态模型或图像模型或语音模型,因为目前 Xinference 在部署这几种模型时只实现了一个模型独占一个 GPU 的方式,如果你想在一个 GPU 上同时部署多个以上模型,就会遇到这个错误:No available slot found for the model。
1.8 管理模型
除了启动模型,Xinference 提供了管理模型整个生命周期的能力。同样的,你可以使用命令行:
列出所有 Xinference 支持的指定类型的模型:
xinference registrations -t LLM
列出所有在运行的模型:
xinference list
停止某个正在运行的模型:
xinference terminate --model-uid "qwen2"更多内容参考3.1节
2. Xinference 安装
安装 Xinference 用于推理的基础依赖,以及支持用 ggml推理 和 PyTorch推理的依赖。
2.1 Xinference 本地源码安装
首先我们需要准备一个 3.9 以上的 Python 环境运行来 Xinference,建议先根据 conda 官网文档安装 conda。 然后使用以下命令来创建 3.11 的 Python 环境:
conda create --name xinference python=3.11
conda activate xinference 以下两条命令在安装 Xinference 时,将安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端:
pip install "xinference"
pip install "xinference[ggml]"
pip install "xinference[pytorch]"
#安装xinference所有包
pip install "xinference[all]"
pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[transformers,vllm]" # 同时安装
#或者一次安装所有的推理后端引擎
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple如果你想使用 GGML 格式的模型,建议根据当前使用的硬件手动安装所需要的依赖,以充分利用硬件的加速能力。
在 Xinference 安装过程中,有可能会安装 PyTorch 的其他版本(其依赖的 vllm3 组件需要安装),从而导致 GPU 服务器无法正常使用,因此在安装完 Xinference 之后,可以执行以下命令看 PyTorch 是否正常:
python -c "import torch; print(torch.cuda.is_available())"如果输出结果为True,则表示 PyTorch 正常,否则需要重新安装 PyTorch。
2.1.1 llama-cpp-python安装
ERROR: Failed building wheel for llama-cpp-python
Failed to build llama-cpp-python
ERROR: Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based projects错误原因:使用pip install llama-cpp-python安装时,是通过下载源码编译安装的(llama_cpp_python-0.2.55.tar.gz (36.8 MB))。这时候如果系统没有相应的cmake 和 gcc版本,会弹出这个错误。
根据系统选择官方编译后的whl下载进行离线安装。
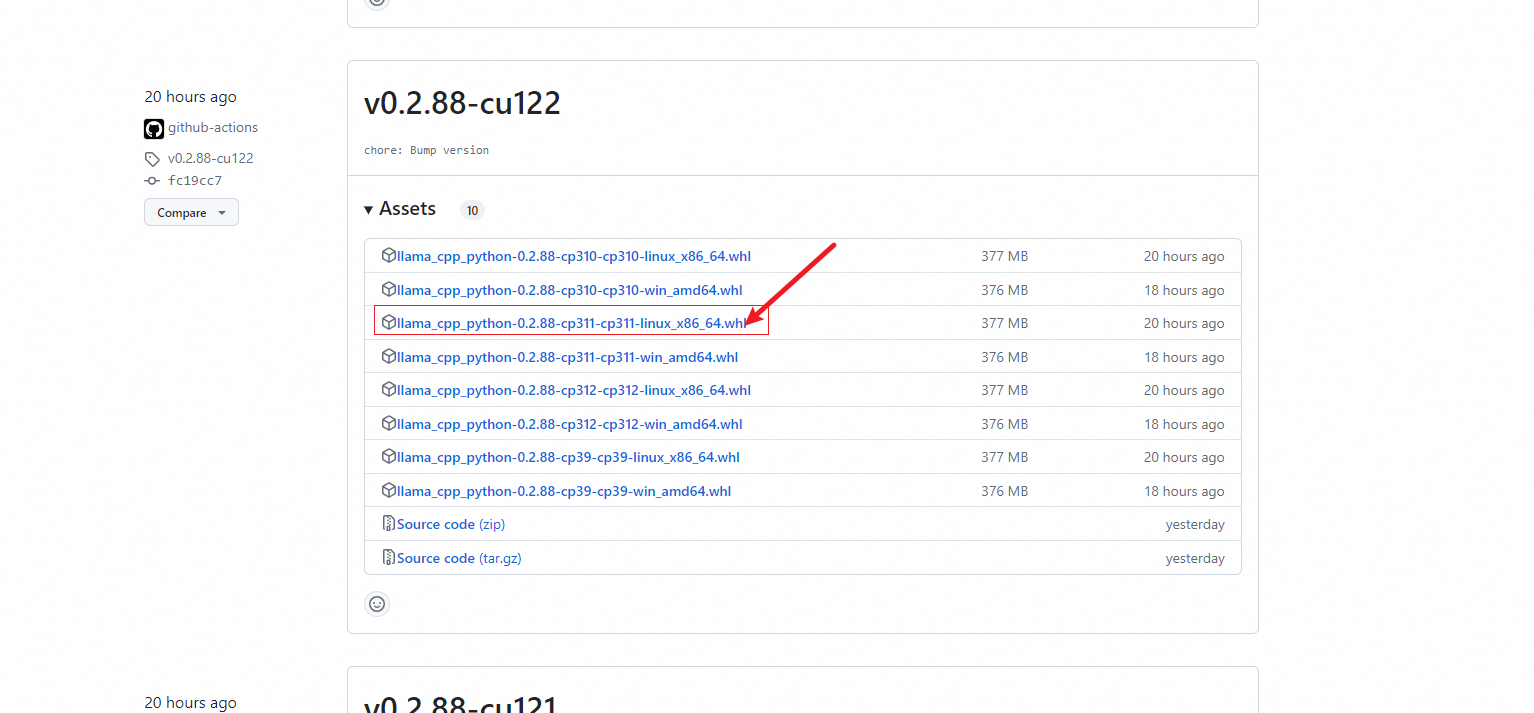
参考链接:告别卡顿,畅享GitHub:国内开发者必看的五大加速访问与下载技巧
找一个加速器就好
wget https://git.886.be/https://github.com/abetlen/llama-cpp-python/releases/download/v0.2.88-cu122/llama_cpp_python-0.2.88-cp311-cp311-linux_x86_64.whl-
安装命令例子
pip install llama_cpp_python-0.2.88-cp311-cp311-linux_x86_64.whl
2.2 Docker安装xinference
参考链接:Docker 镜像安装官方手册
当前,可以通过两个渠道拉取 Xinference 的官方镜像。
- 在 Dockerhub 的 xprobe/xinference 仓库里。
- Dockerhub 中的镜像会同步上传一份到阿里云公共镜像仓库中,供访问 Dockerhub 有困难的用户拉取。拉取命令:docker pull registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:
<tag>。目前可用的标签包括:nightly-main: 这个镜像会每天从 GitHub main 分支更新制作,不保证稳定可靠。v<release version>: 这个镜像会在 Xinference 每次发布的时候制作,通常可以认为是稳定可靠的。latest: 这个镜像会在 Xinference 发布时指向最新的发布版本- 对于 CPU 版本,增加 -cpu 后缀,如 nightly-main-cpu。
Nvidia GPU 用户可以使用Xinference Docker 镜像 启动 Xinference 服务器。在执行安装命令之前,确保系统中已经安装了 Docker 和 CUDA。你可以使用如下方式在容器内启动 Xinference,同时将 9997 端口映射到宿主机的 9998 端口,并且指定日志级别为 DEBUG,也可以指定需要的环境变量。
docker run -e XINFERENCE_MODEL_SRC=modelscope -p 9998:9997 --gpus all xprobe/xinference:v<your_version> xinference-local -H 0.0.0.0 --log-level debug需要修改<your_version>为实际使用版本,也可以为latest:
docker run -e XINFERENCE_MODEL_SRC=modelscope -p 9998:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0 --log-level debug- --gpus 必须指定,正如前文描述,镜像必须运行在有 GPU 的机器上,否则会出现错误。
- -H 0.0.0.0 也是必须指定的,否则在容器外无法连接到 Xinference 服务。
- 可以指定多个 -e 选项赋值多个环境变量。
2.2.2 挂载模型目录
默认情况下,镜像中不包含任何模型文件,使用过程中会在容器内下载模型。如果需要使用已经下载好的模型,需要将宿主机的目录挂载到容器内。这种情况下,需要在运行容器时指定本地卷,并且为 Xinference 配置环境变量。
docker run -v </on/your/host>:</on/the/container> -e XINFERENCE_HOME=</on/the/container> -p 9998:9997 --gpus all xprobe/xinference:v<your_version> xinference-local -H 0.0.0.0上述命令的原理是将主机上指定的目录挂载到容器中,并设置 XINFERENCE_HOME 环境变量指向容器内的该目录。这样,所有下载的模型文件将存储在您在主机上指定的目录中。您无需担心在 Docker 容器停止时丢失这些文件,下次运行容器时,您可以直接使用现有的模型,无需重复下载。
如果你在宿主机使用的默认路径下载的模型,由于 xinference cache 目录是用的软链的方式存储模型,需要将原文件所在的目录也挂载到容器内。例如你使用 huggingface 和 modelscope 作为模型仓库,那么需要将这两个对应的目录挂载到容器内,一般对应的 cache 目录分别在 <home_path>/.cache/huggingface 和 <home_path>/.cache/modelscope,使用的命令如下:
docker run \
-v </your/home/path>/.xinference:/root/.xinference \
-v </your/home/path>/.cache/huggingface:/root/.cache/huggingface \
-v </your/home/path>/.cache/modelscope:/root/.cache/modelscope \
-p 9997:9997 \
--gpus all \
xprobe/xinference:v<your_version> \
xinference-local -H 0.0.0.03.启动xinference 服务(UI)
Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。
xinference-local --host 0.0.0.0 --port 7861- 启动输出结果

2024-08-14 15:37:36,771 xinference.core.supervisor 1739661 INFO Xinference supervisor 0.0.0.0:62536 started
2024-08-14 15:37:36,901 xinference.core.worker 1739661 INFO Starting metrics export server at 0.0.0.0:None
2024-08-14 15:37:36,903 xinference.core.worker 1739661 INFO Checking metrics export server...
2024-08-14 15:37:39,192 xinference.core.worker 1739661 INFO Metrics server is started at: http://0.0.0.0:33423
2024-08-14 15:37:39,193 xinference.core.worker 1739661 INFO Purge cache directory: /root/.xinference/cache
2024-08-14 15:37:39,194 xinference.core.worker 1739661 INFO Connected to supervisor as a fresh worker
2024-08-14 15:37:39,205 xinference.core.worker 1739661 INFO Xinference worker 0.0.0.0:62536 started
2024-08-14 15:37:43,454 xinference.api.restful_api 1739585 INFO Starting Xinference at endpoint: http://0.0.0.0:8501
2024-08-14 15:37:43,597 uvicorn.error 1739585 INFO Uvicorn running on http://0.0.0.0:8501 (Press CTRL+C to quit)3.1 模型下载
vLLM 引擎
vLLM 是一个支持高并发的高性能大模型推理引擎。当满足以下条件时,Xinference 会自动选择 vllm 作为引擎来达到更高的吞吐量:
- 模型格式为
pytorch,gptq或者awq。 - 当模型格式为
pytorch时,量化选项需为none。 - 当模型格式为
awq时,量化选项需为Int4。 - 当模型格式为
gptq时,量化选项需为Int3、Int4或者Int8。 - 操作系统为 Linux 并且至少有一个支持 CUDA 的设备
- 自定义模型的
model_family字段和内置模型的model_name字段在 vLLM 的支持列表中。
Llama.cpp 引擎
Xinference 通过 llama-cpp-python 支持 gguf 和 ggml 格式的模型。建议根据当前使用的硬件手动安装依赖,从而获得最佳的加速效果。
不同硬件的安装方式:
-
Apple M 系列
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python -
英伟达显卡:
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python -
AMD 显卡:
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
SGLang 引擎
SGLang 具有基于 RadixAttention 的高性能推理运行时。它通过在多个调用之间自动重用 KV 缓存,显著加速了复杂 LLM 程序的执行。它还支持其他常见推理技术,如连续批处理和张量并行处理。
初始步骤:
pip install 'xinference[sglang]'3.2 模型部署
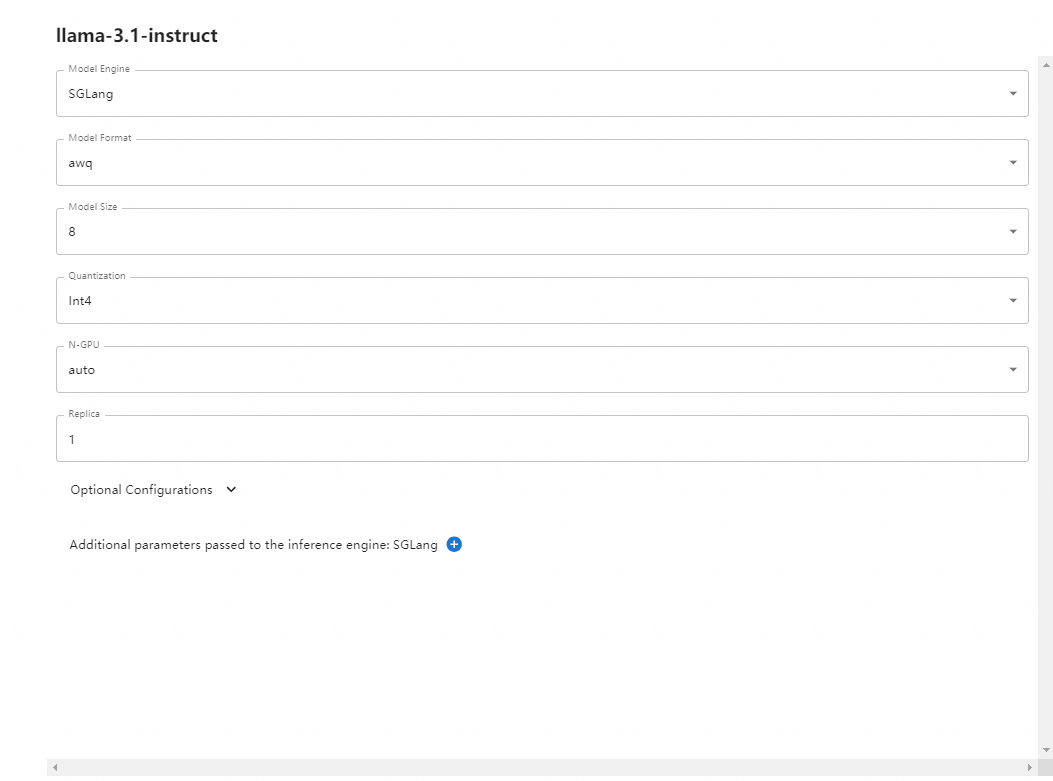

在部署 LLM 模型时有以下参数可以进行选择:
-
Model Format: 模型格式,可以选择量化和非量化的格式,非量化的格式是 pytorch,量化格式有 ggml、gptq、awq 等
-
Model Size:模型的参数量大小,如果是Llama3 的话,则有 8B、70B 等选项
-
Quantization:量化精度,有 4bit、8bit 等量化精度选择
-
N-GPU:选择使用第几个 GPU
-
Model UID(可选): 模型自定义名称,不填的话就默认用原始模型名称
参数填写完成后,点击左边的火箭图标按钮即开始部署模型,后台会根据参数选择下载量化或非量化的 LLM 模型。部署完成后,界面会自动跳转到 Running Models 菜单,在 LANGUAGE MODELS 标签中,我们可以看到部署好的模型。
3.2.1 flashinfer安装
参考链接:https://docs.flashinfer.ai/installation.html
-
提供了适用于Linux的预编译轮子,可以通过以下命令尝试FlashInfer:
#针对CUDA 12.4及torch 2.4
pip install flashinfer -i https://flashinfer.ai/whl/cu124/torch2.4
#对于其他CUDA和torch版本,请访问 https://docs.flashinfer.ai/installation.html 查看详情 -
或者你可以从源代码编译安装:
git clone https://github.com/flashinfer-ai/flashinfer.git --recursive
cd flashinfer/python
pip install -e . -
若需减小构建和测试时的二进制大小,可以这样做:
git clone https://github.com/flashinfer-ai/flashinfer.git --recursive
cd flashinfer/python
#参考 https://pytorch.org/docs/stable/generated/torch.cuda.get_device_capability.html#torch.cuda.get_device_capability
export TORCH_CUDA_ARCH_LIST=8.0
pip install -e .
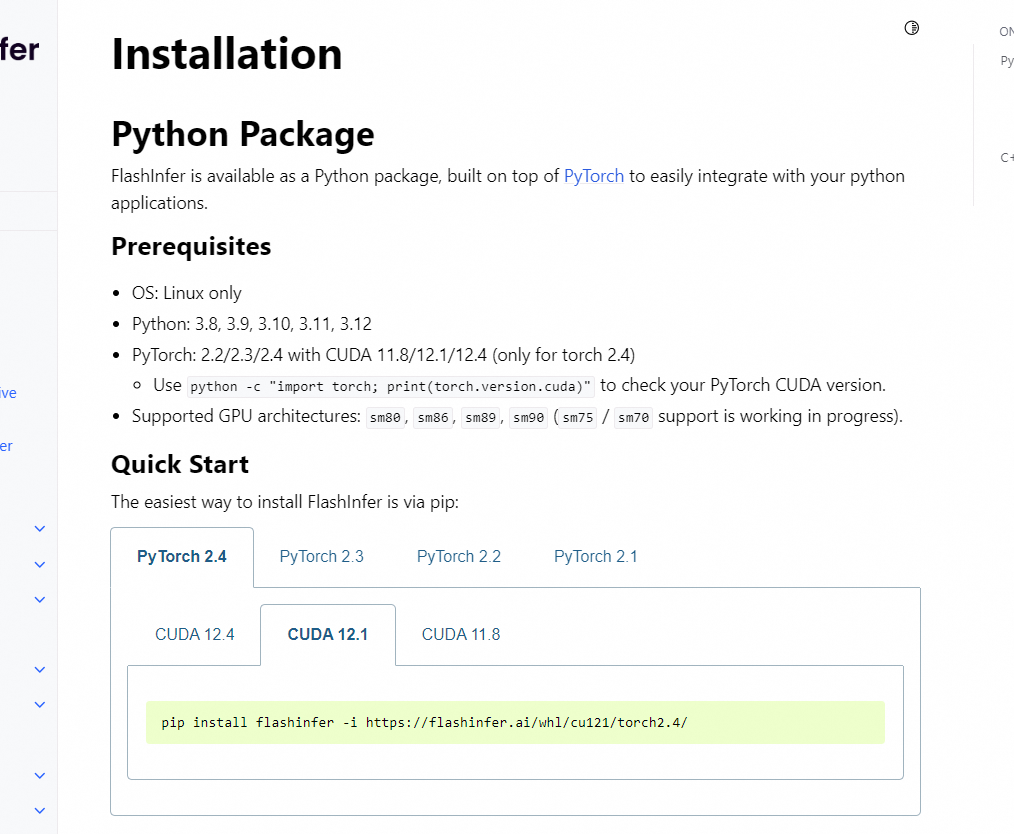
查看torch版本:
import torch
print(torch.__version__)
#2.4.0+cu121-
OS: Linux only
-
Python: 3.8, 3.9, 3.10, 3.11, 3.12
-
PyTorch: 2.2/2.3/2.4 with CUDA 11.8/12.1/12.4 (only for torch 2.4)
- Use python -c "import torch; print(torch.version.cuda)" to check your PyTorch CUDA version.
-
Supported GPU architectures: sm80, sm86, sm89, sm90 (sm75 / sm70 support is working in progress).
pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.4/
如果觉得太慢了,就用whl
-
github网址:https://github.com/flashinfer-ai/flashinfer/releases
Downloading https://github.com/flashinfer-ai/flashinfer/releases/download/v0.1.4/flashinfer-0.1.4%2Bcu121torch2.4-cp311-cp311-linux_x86_64.whl (1098.5 MB)
pip install flashinfer-0.1.4+cu121torch2.4-cp311-cp311-linux_x86_64.whl
-
又遇到问题,可能是量化模型不支持问题
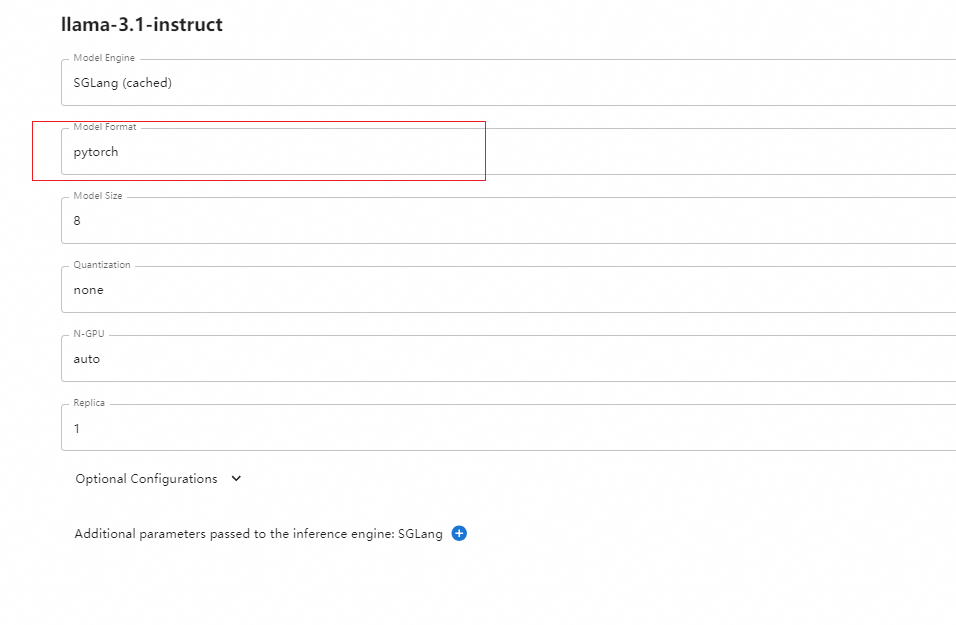
尝试使用qwen2:1.5b遇到一下问题:
Bfloat16 is only supported on GPUs with compute capability of at least 8.0. Your Tesla V100-SXM2-16GB GPU has compute capability 7.0. You can use float16 instead by explicitly setting the`dtype` flag in CLI, for example: --dtype=half- GPU的Compute Capability列表:
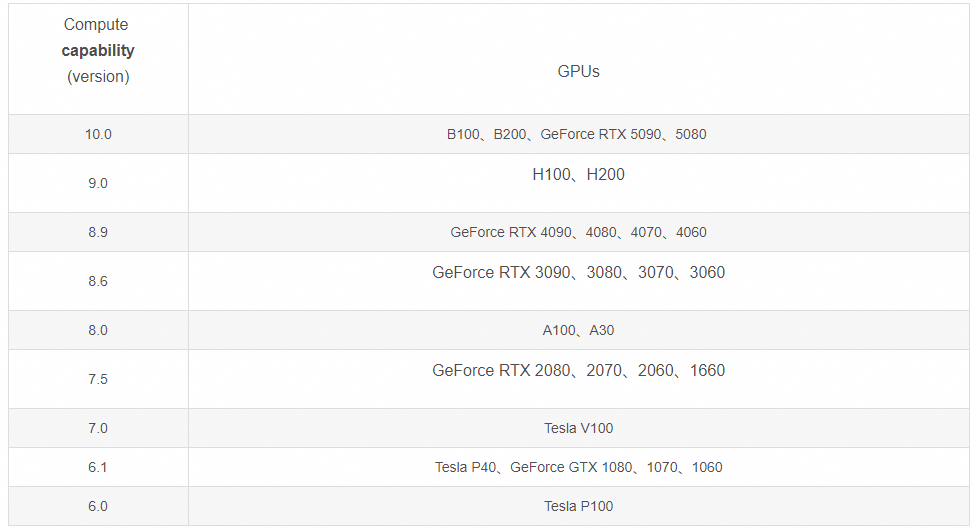
由此可见Tesla V100的Compute Capability是7.0,也就是不能用Bfloat16进行计算,要对Bfloat16减半转换为float16,所以运行时的dtype是half或者float16,否则vLLM会报错。
在国内需要设置环境变量VLLM_USE_MODELSCOPE=True,然后就可以启动一个vLLM大模型API服务了:
CUDA_VISIBLE_DEVICES=0,1 nohup python -m vllm.entrypoints.openai.api_server --model pooka74/LLaMA3-8B-Chat-Chinese --dtype=half --port 8000 &> ~/logs/vllm.log &- 界面修改参考:
- 命令行就是 --dtype half,界面上 extra +号点击,key是 dtype,值是 half。
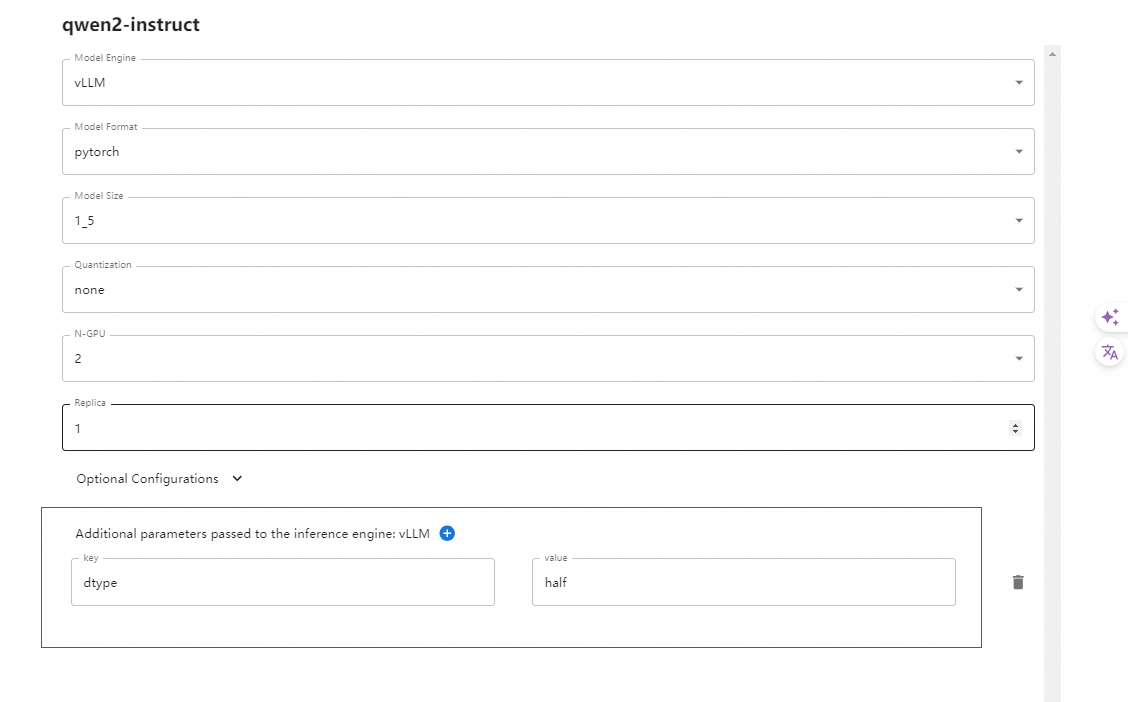

- 查看GPU资源占用

3.2.2 分布式部署
分布式场景下,需要在一台服务器上部署一个 Xinference supervisor,并在其余服务器上分别部署一个 Xinference worker。 具体步骤如下:
(1)启动 supervisor执行命令
xinference-supervisor -H "{supervisor_host}",替换 {supervisor_host} 为 supervisor 所在服务器的实际主机名或 IP 地址。
(2)启动 workers其余服务器执行命令
xinference-worker -e "http://${supervisor_host}:9997"
Xinference 启动后,将会打印服务的 endpoint。这个 endpoint 用于通过命令行工具或编程接口进行模型的管理:
本地部署下,endpoint 默认为 http://localhost:9997
集群部署下,endpoint 默认为 http://${supervisor_host}:9997。其中 ${supervisor_host} 为 supervisor 所在服务器的主机名或 IP 地址。
3.3 模型使用
模型下载并启动后,会自动打开一个本地网页,你可以在这里与模型进行简单的对话,测试其是否成功运行。
复制标题下方的Model ID,可以在其他LLMops上使用
3.3.1 快速Gradio对话

3.3.2 集成Dify智能问答
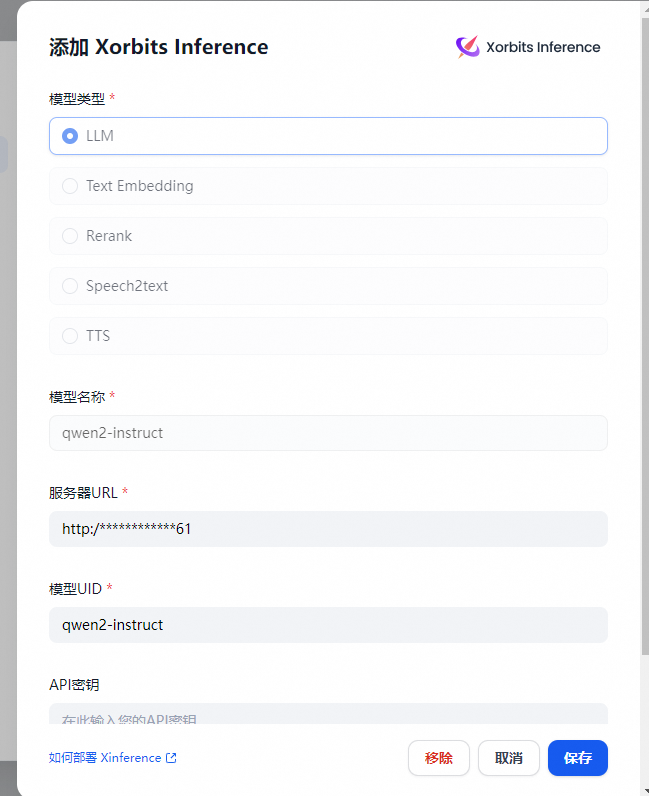
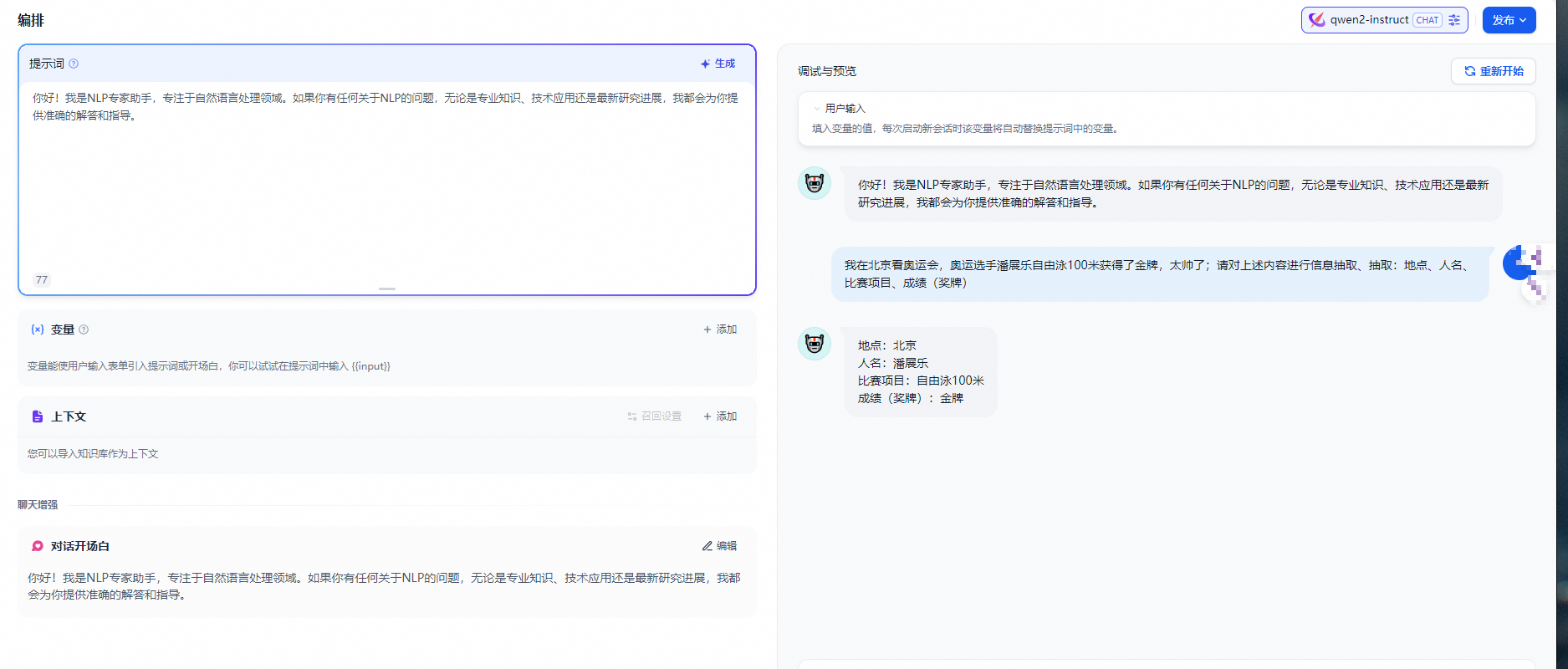
模型部署完毕,在 Dify 中使用接入模型,在 设置 > 模型供应商 > Xinference 中填入:
-
模型名称:qwen2-instruct
-
服务器 URL:http://<Machine_IP>:7861 替换成您的机器 IP 地址
-
模型 UID:qwen2-instruct
-
"保存" 后即可在应用中使用该模型。
Dify 同时支持将 Xinference embed 模型 作为 Embedding 模型使用,只需在配置框中选择 Embeddings 类型即可。
3.4 自定义模型
参考链接:参考下文
-
内置模型
xinference registrations --model-type LLM --endpoint "http://127.0.0.1:7861"
Type Name Language Ability Is-built-in
LLM aquila2 ['zh'] ['generate'] True
LLM aquila2-chat ['zh'] ['chat'] True
LLM aquila2-chat-16k ['zh'] ['chat'] True
LLM baichuan ['en', 'zh'] ['generate'] True
LLM baichuan-2 ['en', 'zh'] ['generate'] True
LLM baichuan-2-chat ['en', 'zh'] ['chat'] True
LLM baichuan-chat ['en', 'zh'] ['chat'] True
LLM c4ai-command-r-v01 ['en', 'fr', 'de', 'es', 'it', 'pt', 'ja', 'ko', 'zh', 'ar'] ['chat'] True
LLM chatglm ['en', 'zh'] ['chat'] True
LLM chatglm2 ['en', 'zh'] ['chat'] True
LLM chatglm2-32k ['en', 'zh'] ['chat'] True
LLM chatglm3 ['en', 'zh'] ['chat', 'tools'] True
LLM chatglm3-128k ['en', 'zh'] ['chat'] True
LLM chatglm3-32k ['en', 'zh'] ['chat'] True
LLM code-llama ['en'] ['generate'] True
LLM code-llama-instruct ['en'] ['chat'] True
LLM code-llama-python ['en'] ['generate'] True
LLM codegeex4 ['en', 'zh'] ['chat'] True
LLM codeqwen1.5 ['en', 'zh'] ['generate'] True
LLM codeqwen1.5-chat ['en', 'zh'] ['chat'] True
LLM codeshell ['en', 'zh'] ['generate'] True
LLM codeshell-chat ['en', 'zh'] ['chat'] True
LLM codestral-v0.1 ['en'] ['generate'] True
LLM cogvlm2 ['en', 'zh'] ['chat', 'vision'] True
LLM csg-wukong-chat-v0.1 ['en'] ['chat'] True
LLM deepseek ['en', 'zh'] ['generate'] True
LLM deepseek-chat ['en', 'zh'] ['chat'] True
LLM deepseek-coder ['en', 'zh'] ['generate'] True
LLM deepseek-coder-instruct ['en', 'zh'] ['chat'] True
LLM deepseek-vl-chat ['en', 'zh'] ['chat', 'vision'] True
LLM falcon ['en'] ['generate'] True
LLM falcon-instruct ['en'] ['chat'] True
LLM gemma-2-it ['en'] ['chat'] True
LLM gemma-it ['en'] ['chat'] True
LLM glaive-coder ['en'] ['chat'] True
LLM glm-4v ['en', 'zh'] ['chat', 'vision'] True
LLM glm4-chat ['en', 'zh'] ['chat', 'tools'] True
LLM glm4-chat-1m ['en', 'zh'] ['chat', 'tools'] True
LLM gorilla-openfunctions-v1 ['en'] ['chat'] True
LLM gorilla-openfunctions-v2 ['en'] ['chat'] True
LLM gpt-2 ['en'] ['generate'] True
LLM internlm-20b ['en', 'zh'] ['generate'] True
LLM internlm-7b ['en', 'zh'] ['generate'] True
LLM internlm-chat-20b ['en', 'zh'] ['chat'] True
LLM internlm-chat-7b ['en', 'zh'] ['chat'] True
LLM internlm2-chat ['en', 'zh'] ['chat'] True
LLM internlm2.5-chat ['en', 'zh'] ['chat'] True
LLM internlm2.5-chat-1m ['en', 'zh'] ['chat'] True
LLM internvl-chat ['en', 'zh'] ['chat', 'vision'] True
LLM llama-2 ['en'] ['generate'] True
LLM llama-2-chat ['en'] ['chat'] True
LLM llama-3 ['en'] ['generate'] True
LLM llama-3-instruct ['en'] ['chat'] True
LLM llama-3.1 ['en', 'de', 'fr', 'it', 'pt', 'hi', 'es', 'th'] ['generate'] True
LLM llama-3.1-instruct ['en', 'de', 'fr', 'it', 'pt', 'hi', 'es', 'th'] ['chat'] True
LLM minicpm-2b-dpo-bf16 ['zh'] ['chat'] True
LLM minicpm-2b-dpo-fp16 ['zh'] ['chat'] True
LLM minicpm-2b-dpo-fp32 ['zh'] ['chat'] True
LLM minicpm-2b-sft-bf16 ['zh'] ['chat'] True
LLM minicpm-2b-sft-fp32 ['zh'] ['chat'] True
LLM MiniCPM-Llama3-V-2_5 ['en', 'zh'] ['chat', 'vision'] True
LLM MiniCPM-V-2.6 ['en', 'zh'] ['chat', 'vision'] True
LLM mistral-instruct-v0.1 ['en'] ['chat'] True
LLM mistral-instruct-v0.2 ['en'] ['chat'] True
LLM mistral-instruct-v0.3 ['en'] ['chat'] True
LLM mistral-large-instruct ['en', 'fr', 'de', 'es', 'it', 'pt', 'zh', 'ru', 'ja', 'ko'] ['chat'] True
LLM mistral-nemo-instruct ['en', 'fr', 'de', 'es', 'it', 'pt', 'zh', 'ru', 'ja'] ['chat'] True
LLM mistral-v0.1 ['en'] ['generate'] True
LLM mixtral-8x22B-instruct-v0.1 ['en', 'fr', 'it', 'de', 'es'] ['chat'] True
LLM mixtral-instruct-v0.1 ['en', 'fr', 'it', 'de', 'es'] ['chat'] True
LLM mixtral-v0.1 ['en', 'fr', 'it', 'de', 'es'] ['generate'] True
LLM OmniLMM ['en', 'zh'] ['chat', 'vision'] True
LLM OpenBuddy ['en'] ['chat'] True
LLM openhermes-2.5 ['en'] ['chat'] True
LLM opt ['en'] ['generate'] True
LLM orca ['en'] ['chat'] True
LLM orion-chat ['en', 'zh'] ['chat'] True
LLM orion-chat-rag ['en', 'zh'] ['chat'] True
LLM phi-2 ['en'] ['generate'] True
LLM phi-3-mini-128k-instruct ['en'] ['chat'] True
LLM phi-3-mini-4k-instruct ['en'] ['chat'] True
LLM platypus2-70b-instruct ['en'] ['generate'] True
LLM qwen-chat ['en', 'zh'] ['chat', 'tools'] True
LLM qwen-vl-chat ['en', 'zh'] ['chat', 'vision'] True
LLM qwen1.5-chat ['en', 'zh'] ['chat', 'tools'] True
LLM qwen1.5-moe-chat ['en', 'zh'] ['chat', 'tools'] True
LLM qwen2-instruct ['en', 'zh'] ['chat', 'tools'] True
LLM qwen2-moe-instruct ['en', 'zh'] ['chat', 'tools'] True
LLM seallm_v2 ['en', 'zh', 'vi', 'id', 'th', 'ms', 'km', 'lo', 'my', 'tl'] ['generate'] True
LLM seallm_v2.5 ['en', 'zh', 'vi', 'id', 'th', 'ms', 'km', 'lo', 'my', 'tl'] ['generate'] True
LLM Skywork ['en', 'zh'] ['generate'] True
LLM Skywork-Math ['en', 'zh'] ['generate'] True
LLM starchat-beta ['en'] ['chat'] True
LLM starcoder ['en'] ['generate'] True
LLM starcoderplus ['en'] ['generate'] True
LLM Starling-LM ['en', 'zh'] ['chat'] True
LLM telechat ['en', 'zh'] ['chat'] True
LLM tiny-llama ['en'] ['generate'] True
LLM vicuna-v1.3 ['en'] ['chat'] True
LLM vicuna-v1.5 ['en'] ['chat'] True
LLM vicuna-v1.5-16k ['en'] ['chat'] True
LLM wizardcoder-python-v1.0 ['en'] ['chat'] True
LLM wizardlm-v1.0 ['en'] ['chat'] True
LLM wizardmath-v1.0 ['en'] ['chat'] True
LLM xverse ['en', 'zh'] ['generate'] True
LLM xverse-chat ['en', 'zh'] ['chat'] True
LLM Yi ['en', 'zh'] ['generate'] True
LLM Yi-1.5 ['en', 'zh'] ['generate'] True
LLM Yi-1.5-chat ['en', 'zh'] ['chat'] True
LLM Yi-1.5-chat-16k ['en', 'zh'] ['chat'] True
LLM Yi-200k ['en', 'zh'] ['generate'] True
LLM Yi-chat ['en', 'zh'] ['chat'] True
LLM yi-vl-chat ['en', 'zh'] ['chat', 'vision'] True
LLM zephyr-7b-alpha ['en'] ['chat'] True
LLM zephyr-7b-beta ['en'] ['chat'] True -
通过Web注册模型
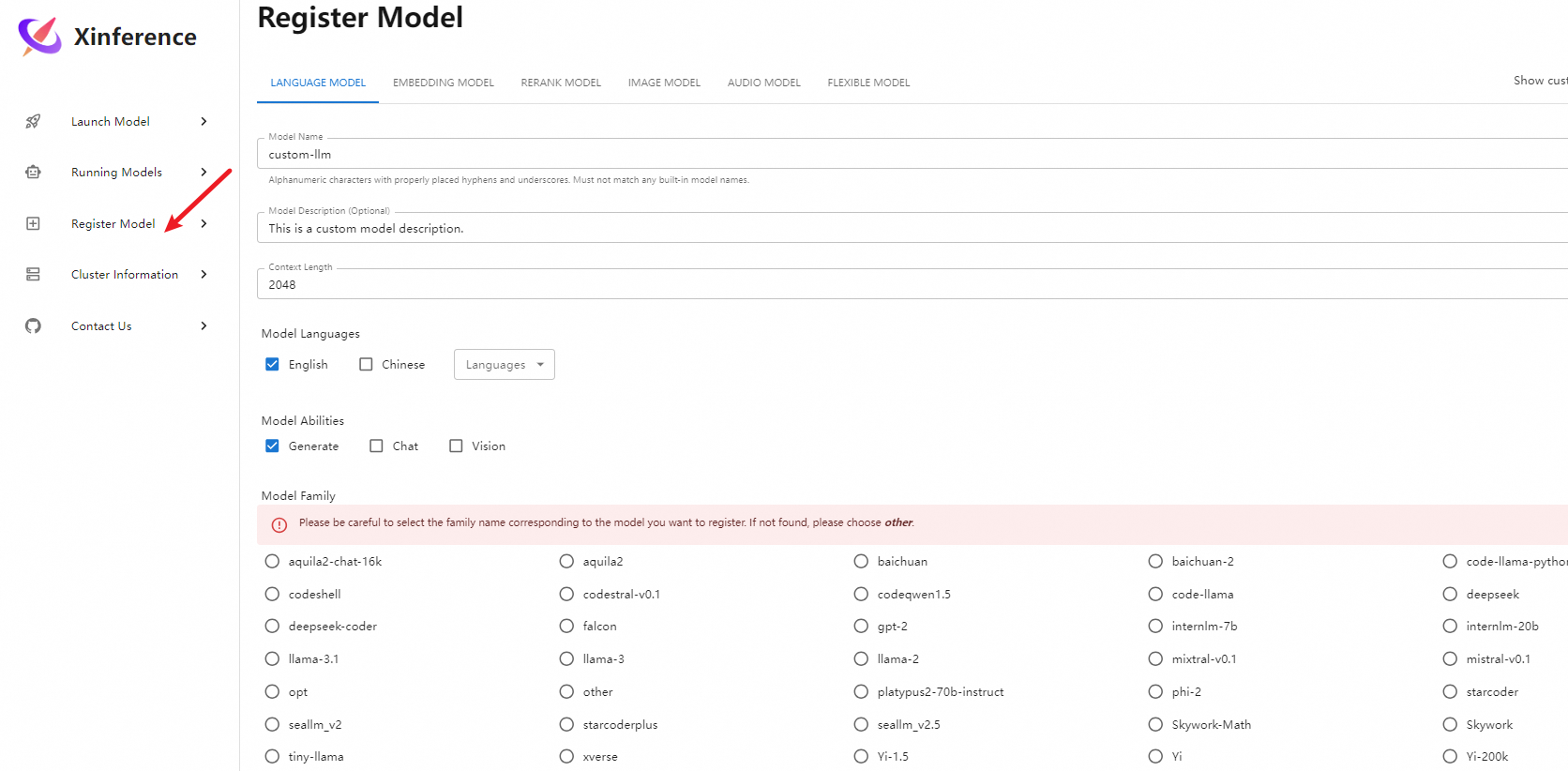
4. 终端命令
上面如果修改了端口,可以根据下面对应的修改端口
#https://hf-mirror.com/
export HF_ENDPOINT=https://hf-mirror.com
export XINFERENCE_MODEL_SRC=modelscope
#log缓存地址
export XINFERENCE_HOME=/root/autodl-tmp
#端口修改了重新设置环境变量
export XINFERENCE_ENDPOINT=http://0.0.0.0:7863修改完了就可以对应的启动相对应的服务,下面是分别启动chat / embedding / rerank 三种模型的cmd命令, 其他模型命令可以参考xinference主页。 启动完了,会返回对应模型的UID(后期在Dify部署会用到)
#部署chatglm3
xinference launch --model-name chatglm3 --size-in-billions 6 --model-format pytorch --quantization 8-bit
#部署 bge-large-zh embedding
xinference launch --model-name bge-large-zh --model-type embedding
#部署 bge-reranker-large rerank
xinference launch --model-name bge-reranker-large --model-type rerankAPI调用
如果你不满足于使用 LLM 模型的 Web 界面,你也可以调用 API 接口来使用 LLM 模型,其实在 Xinference 服务部署好的时候,WebGUI 界面和 API 接口已经同时准备好了,在浏览器中访问 http://localhost:9997/docs / 就可以看到 API 接口列表。
接口列表中包含了大量的接口,不仅有 LLM 模型的接口,还有其他模型(比如 Embedding 或 Rerank )的接口,而且这些都是兼容 OpenAI API 的接口。以 LLM 的聊天功能为例,我们使用 Curl 工具来调用其接口,示例如下:
curl -X 'POST' \
'http://localhost:9997/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "chatglm3",
"messages": [
{
"role": "user",
"content": "hello"
}
]
}'
#返回结果
{
"model": "chatglm3",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I help you today?",
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 8,
"total_tokens": 29,
"completion_tokens": 37
}
}如果想测试模型是否已经部署到本地,以rerank模型为例可以执行下面这个脚本, 或者执行
from xinference.client import Client
#url 可以是local的端口 也可以是外接的端口
url = "http://172.19.0.1:6006"
print(url)
client = Client(url)
model_uid = client.launch_model(model_name="bge-reranker-base", model_type="rerank")
model = client.get_model(model_uid)
query = "A man is eating pasta."
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin."
]
print(model.rerank(corpus, query))-
或者执行查看已经部署好的模型
xinferencelist
-
如果需要释放资源
xinferenceterminate--model-uid"my-llama-2"
-
需要外网访问,需要查找本地IP地址 即 http://<Machine_IP>:<端口port> , 查找IP地址的方式如下。
#Windows
ipconfig/all#Linux
hostname -I
5. Xinference官方AI实践案例
官方链接:https://inference.readthedocs.io/zh-cn/latest/examples/index.html
参考链接: