图论理论基础
**分类:**有向图,无向图,有无权重
度:【无向图】:有几条边连接该节点,该节点就有几度。
【有向图】:每个节点有出度和入度。出度:从该节点出发的边的个数。入度:指向该节点边的个数。
连通情况:
【无向图】:任意两个点之间都有路径可达------连通图
如果有节点不能到达其他节点,则为非连通图
在无向图中的极大连通子图称之为该图的一个连通分量。
【有向图】:任何两个节点是可以相互到达的,我们称之为 强连通图。
有可能出现1能到2,2不能到1的情况。
在有向图中极大强连通子图称之为该图的强连通分量。
图的存储:
邻接矩阵
使用 二维数组来表示图结构。
邻接矩阵是++从节点的角度++ 来表示图,++有多少节点就申请多大的二维数组++。
例如: grid25 = 6,表示 节点 2 连接 节点5 为有向图,节点2 指向 节点5,边的权值为6。
如果想表示无向图,即:grid25 = 6,grid52 = 6,表示节点2 与 节点5 相互连通,权值为6。
如图:
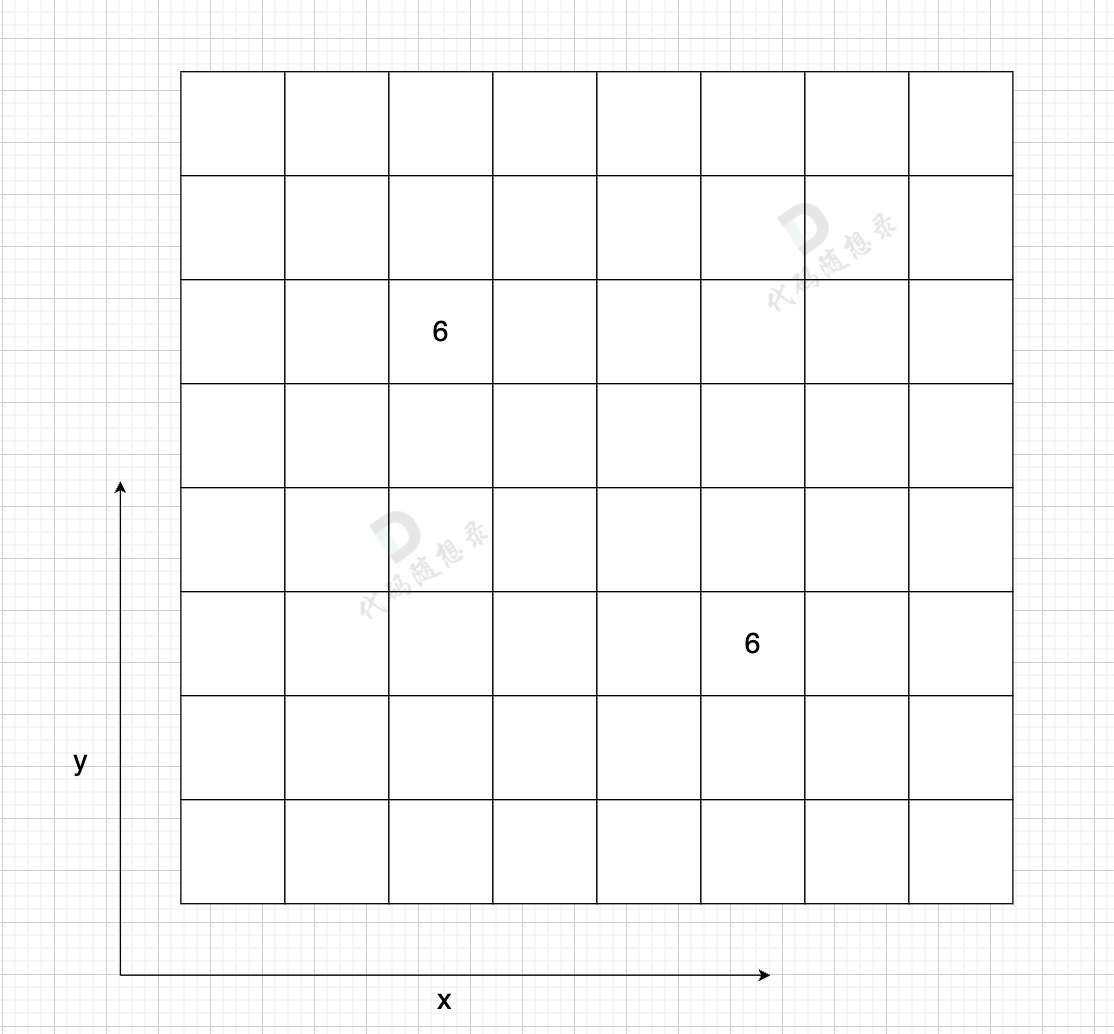
在一个 n (节点数)为8 的图中,就需要申请 8 * 8 这么大的空间。
图中有一条双向边,即:grid25 = 6,grid52 = 6
这种表达方式(邻接矩阵) 在 边少,节点多的情况下,会导致申请过大的二维数组,造成空间浪费。
而且在寻找节点连接情况的时候,需要遍历整个矩阵,即 n * n 的时间复杂度,同样造成时间浪费。
邻接矩阵的优点:
- 表达方式简单,易于理解
- ++检查任意两个顶点间是否存在边的操作非常快++
- ++适合稠密图++,在边数接近顶点数平方的图中,邻接矩阵是一种空间效率较高的表示方法。
缺点:
- 遇到稀疏图,会导致申请过大的二维数组造成空间浪费
- ++不适合遍历++,遍历 边 的时候需要遍历整个n * n矩阵,造成时间浪费
代码:

邻接表
邻接表 使用 数组 + 链表的方式来表示。 邻接表是++从边的数量来表示图,有多少边 才会申请对应大小的链表。++
邻接表的构造如图:
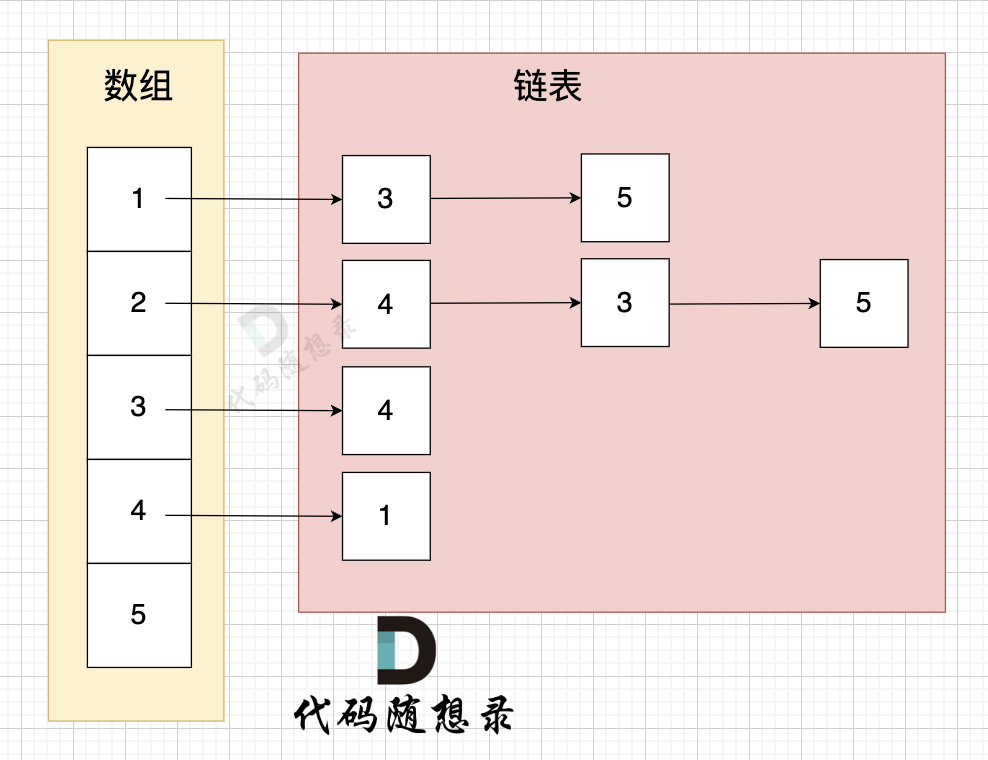
这里表达的图是:
- 节点1 指向 节点3 和 节点5
- 节点2 指向 节点4、节点3、节点5
- 节点3 指向 节点4
- 节点4指向节点1
有多少边 邻接表才会申请多少个对应的链表节点。
从图中可以直观看出 使用 数组 + 链表 来表达 边的连接情况 。
邻接表的优点:
- 对于++稀疏图++的存储,只需要存储边,空间利用率高
- ++遍历节点连接情况相对容易++
缺点:
- ++检查任意两个节点间是否存在边,效率相对低++,需要 O(V)时间,V表示某节点连接其他节点的数量。
- 实现相对复杂,不易理解
代码实现:



图的遍历方式
图的遍历方式基本是两大类:
- 深度优先搜索(dfs)
- 广度优先搜索(bfs)
在讲解二叉树章节的时候,其实就已经讲过这两种遍历方式。
二叉树的递归遍历,是dfs 在二叉树上的遍历方式。
二叉树的层序遍历,是bfs 在二叉树上的遍历方式。
dfs 和 bfs 一种搜索算法,可以在不同的数据结构上进行搜索,在二叉树章节里是在二叉树这样的数据结构上搜索。
而在图论章节,则是在图(邻接表或邻接矩阵)上进行搜索。
深度优先搜索理论基础
二者区别:
- dfs是可一个方向去搜,不到黄河不回头,直到遇到绝境了,搜不下去了,再换方向(换方向的过程就涉及到了回溯)。
- bfs是先把本节点所连接的所有节点遍历一遍,走到下一个节点的时候,再把连接节点的所有节点遍历一遍,搜索方向更像是广度,四面八方的搜索过程。
dfs:
- 搜索方向,是认准一个方向搜,直到碰壁之后再换方向
- 换方向是撤销原路径,改为节点链接的下一个路径,回溯的过程。
代码:

主要分为三个板块:
1、递归函数、递归参数
二维数组数组结构保存所有路径,需要一维数组保存单一路径,这种保存结果的数组,我们可以定义一个全局变量,避免让我们的函数参数过多。
2、确认终止条件
结束递归,并且收获结果
3、 处理目前搜索节点出发的路径
98. 所有可达路径
对于print来说
cpp
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
//如何开辟
typedef struct anode{//边结点,一个anode代表一条从头结点-thisnode的边
int thisnode;//这条边 的另外一个终点 的编号
struct anode *nextnode;//指向下一条边
//int weight;//记录这条边的权重
}Arcnode;
typedef struct vnode{//头结点
int thisnode;//顶点编号
Arcnode* firstarc;//指向第一条边
}Vnode;
typedef struct{
Vnode adjlist[100];//邻接表
int n,m;//顶点,边数
}gragh;
//dfs的写法
void dfs(gragh *g,int x,int n,int* path,int index){
if(x==n){
for(int i=0;i<index-1;i++){
printf("%d ",path[i]);
}
printf("%d\n",path[index-1]);
return;
}
Arcnode *p = g->adjlist[x].firstarc;
while(p!=NULL){
int w=p->thisnode;
path[index]=w;
dfs(g,w,n,path,index+1);
p=p->nextnode;
}
}
int main(){
int n,m;//n是结点,m是边
gragh *g=(gragh*)malloc(sizeof(gragh));
scanf("%d%d",&n,&m);
g->n=n;
g->m=m;
for(int i=1;i<=n;i++) g->adjlist[i].firstarc=NULL;
//如何创建邻接表
for(int i=0;i<m;i++){
int s,t;
scanf("%d%d",&s,&t);
Arcnode *newnode=(Arcnode*)malloc(sizeof(Arcnode));
newnode->thisnode = t;
newnode -> nextnode = g->adjlist[s].firstarc;
g->adjlist[s].firstarc = newnode;
}
for (int i=1;i<=n;i++){
printf("start %d->",i);
Arcnode *p=g->adjlist[i].firstarc;
while(p!=NULL){
printf("%d",p->thisnode);
p=p->nextnode;
}
printf("\n");
}
int path[101];
path[0]=1;
dfs(g,1,n,path,1);
return 0;
}但提交报错,怀疑是没有处理输出-1的情况,加上果然好了^-^很巧妙的逃避了创建个大矩阵
cpp
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
//建立邻接表数据结构:分三步
//存放每条边 终点------arcnode
//存放每个顶点(作为起点)------vnode
//邻接表本体 ------gragh
typedef struct anode{//边结点,一个anode代表一条从头结点-thisnode的边
int thisnode;//这条边 的另外一个终点 的编号
struct anode *nextnode;//指向下一条边
//int weight;//记录这条边的权重
}Arcnode;
typedef struct vnode{//头结点
int thisnode;//顶点编号
Arcnode* firstarc;//指向第一条边
}Vnode;
typedef struct{
Vnode adjlist[100];//邻接表
int n,m;//顶点,边数
}gragh;
int flag=0;
void dfs(gragh *g,int x,int n,int* path,int index){
if(x==n){
flag=1;
for(int i=0;i<index-1;i++){
printf("%d ",path[i]);
}
printf("%d\n",path[index-1]);
return;
}
Arcnode *p = g->adjlist[x].firstarc;
while(p!=NULL){
int w=p->thisnode;
path[index]=w;
dfs(g,w,n,path,index+1);
p=p->nextnode;
}
}
int main(){
int n,m;//n是结点,m是边
gragh *g=(gragh*)malloc(sizeof(gragh));
scanf("%d%d",&n,&m);
//初始化 邻接矩阵:
//三步走:
//赋值边数、顶点数
//firstarc指针全部指向空
//遍历每条边:创建Arcnode,找到起点对应的g->adjlist[start].firstarc,记录终点arcnode->thisnode=end;尾插法建表
g->n=n;
g->m=m;
for(int i=1;i<=n;i++) g->adjlist[i].firstarc=NULL;
for(int i=0;i<m;i++){
int s,t;
scanf("%d%d",&s,&t);
Arcnode *newnode=(Arcnode*)malloc(sizeof(Arcnode));
newnode->thisnode = t;
newnode -> nextnode = g->adjlist[s].firstarc;
g->adjlist[s].firstarc = newnode;
}
int path[101];
path[0]=1;
dfs(g,1,n,path,1);
if(flag==0) printf("-1");
return 0;
}邻接矩阵版:主要是注意矩阵的编号 和 真实顶点的编号
cpp
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
#define max 100
//邻接矩阵 两步走
//vnode 包括所有每个顶点的信息
//gragh 三部分:顶点、边长信息;
typedef struct node{
int no;
//int otherdata;
}vnode;
typedef struct www{
int excel[max][max];
vnode list[max];
int n,e;
}gragh;
int flag=0;
void dfs(gragh *g,int x,int n,int index,int*path){
if(x==n){
flag=1;
for(int i=0;i<index-1;i++){
printf("%d ",path[i]);
}
printf("%d\n",path[index-1]);
return;
}
for(int j=1;j<=n;j++){
if(g->excel[x-1][j-1]==1){
path[index]=j;
dfs(g,j,n,index+1,path);
}
}
}
int main(){
int n,m;
scanf("%d%d",&n,&m);
gragh*g=(gragh*)malloc(sizeof(gragh));
for(int i=0;i<n;i++){
for(int j=0;j<n;j++) g->excel[i][j]=0;
g->list[i].no=i+1;
}
for(int i=0;i<m;i++){
int s,t;
scanf("%d%d",&s,&t);
g->excel[s-1][t-1]=1;
}
int path[100];
path[0]=1;
dfs(g,1,n,1,path);
if(flag==0) printf("-1");
return 0;
}广度优先搜索理论基础
适合于解决两个点之间的最短路径问题
广搜是从起点出发,以起始点为中心一圈一圈进行搜索,一旦遇到终点,记录之前走过的节点就是一条最短路
当然,也有一些问题是广搜 和 深搜都可以解决的,例如岛屿问题,这类问题的特征就是不涉及具体的遍历方式,只要能把相邻且相同属性的节点标记上就行。

