秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】------点击即可跳转
💡💡💡 本专栏所有程序均经过测试,可成功执行**💡💡💡**
专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有70+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
EffectiveSEModule是一种改进的图像模型块,它通过使用单个全连接层而不是传统的两个层来优化Squeeze-and-Excitation(SE)模块,避免了通道信息的丢失,并维持了通道数量。这种方法提高了模型处理图像时的性能,尤其是在计算机视觉任务中。本文介绍他的主要原理以及如何将EffectiveSEModule融合到C2f中并添加到YOLOv8中。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
目录
[1. 原理](#1. 原理)
[2. 将C3_EMBC添加到yolov8网络中](#2. 将C3_EMBC添加到yolov8网络中)
[2.1 C3_EMBC代码实现](#2.1 C3_EMBC代码实现)
[2.2 新增yaml文件](#2.2 新增yaml文件)
[2.3 注册模块](#2.3 注册模块)
[2.4 执行程序](#2.4 执行程序)
[3. 完整代码分享](#3. 完整代码分享)
[4. GFLOPs](#4. GFLOPs)
[5. 进阶](#5. 进阶)
[6. 总结](#6. 总结)
1. 原理

有效挤压激励模块 (eSE) 是在提高深度神经网络性能的背景下引入的关键组件,特别是在您提供的文档中讨论的 VoVNetV2 主干架构中。下面简要概述其主要原理:
-
通道注意机制:eSE 模块是挤压激励 (SE) 模块的一种变体,旨在通过对通道关系进行建模来增强网络的表示能力。本质上,SE 模块通过考虑通道之间的相互依赖性来自适应地重新校准特征图。这是通过使用全局平均池化来捕获通道统计数据,然后使用几个学习重新加权通道的全连接层来实现的。
-
有效简化:在原始 SE 模块中,有两个全连接 (FC) 层,它们会减少然后恢复通道维度,这会无意中导致一些通道信息丢失。 eSE 模块通过将两个 FC 层替换为单个 FC 层来简化此过程。此设计保持了原始通道维度,防止了信息丢失,从而提高了注意力机制的有效性。
-
残差连接:为了进一步改进优化并防止更深层网络的性能下降,在 OSA 模块中添加了残差连接。此添加有助于在反向传播期间保持梯度流,从而使网络更易于训练且更稳健。
综上所述,eSE 模块通过降低复杂性和避免信息丢失来改进通道注意机制,从而实现深度神经网络中更高效、更有效的特征重新校准。这有助于提高对象检测和实例分割等任务的性能。
2. 将C3_EMBC添加到yolov8网络中
2.1 C3_EMBC代码实现
关键步骤一: 将下面的代码粘贴到\yolov5\models\common.py中
python
class EffectiveSEModule(nn.Module):
def __init__(self, channels, add_maxpool=False):
super(EffectiveSEModule, self).__init__()
self.add_maxpool = add_maxpool
self.fc = nn.Conv2d(channels, channels, kernel_size=1, padding=0)
self.gate = nn.Hardsigmoid()
def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
if self.add_maxpool:
# experimental codepath, may remove or change
x_se = 0.5 * x_se + 0.5 * x.amax((2, 3), keepdim=True)
x_se = self.fc(x_se)
return x * self.gate(x_se)
class MBConv(nn.Module):
def __init__(self, inc, ouc, shortcut=True, e=4, dropout=0.1) -> None:
super().__init__()
midc = inc * e
self.conv_pw_1 = Conv(inc, midc, 1)
self.conv_dw_1 = Conv(midc, midc, 3, g=midc)
self.effective_se = EffectiveSEModule(midc)
self.conv1 = Conv(midc, ouc, 1, act=False)
self.dropout = nn.Dropout2d(p=dropout)
self.add = shortcut and inc == ouc
def forward(self, x):
return x + self.dropout(self.conv1(self.effective_se(self.conv_dw_1(self.conv_pw_1(x))))) if self.add else self.dropout(self.conv1(self.effective_se(self.conv_dw_1(self.conv_pw_1(x)))))
class C3_EMBC(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(MBConv(c_, c_, shortcut) for _ in range(n)))Effective Squeeze-Excitation Module (eSE) 处理图像的主要流程如下:
-
输入特征图 :首先,eSE 模块接收来自前一层的特征图,特征图的尺寸为
,其中 (C) 表示通道数,(W) 和 (H) 分别表示特征图的宽度和高度。
-
全局平均池化 :接下来,eSE 模块对输入特征图进行全局平均池化操作。这个操作将每个通道的二维空间信息(即
-
全连接层:然后,eSE 模块使用一个全连接层对该全局特征向量进行处理。这一步通过学习到的权重对每个通道的全局特征进行重新加权,以调整每个通道的重要性。与传统 SE 模块不同,eSE 只使用一个全连接层,从而避免了通道信息的丢失。
-
注意力映射生成:全连接层的输出经过一个激活函数(通常是 sigmoid 函数),生成一个范围在 (0) 到 (1) 之间的注意力权重。这些权重将用于重新调整每个通道的响应强度。
-
特征重校准:最后,eSE 模块将生成的注意力权重与输入的特征图进行逐通道相乘。这个操作会突出显示那些被认为更重要的通道特征,同时抑制那些不重要的通道特征。
通过以上步骤,eSE 模块可以有效地增强特征图中有用的信息,并减少无关或噪声信息,从而提高后续图像处理任务的效果。

2.2 新增yaml文件
关键步骤二:在下/yolov5/models下新建文件 yolov5_C3_EMBC .yaml并将下面代码复制进去
- 目标检测yaml文件
python
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_EMBC, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_EMBC, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_EMBC, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_EMBC, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]- 语义分割yaml文件
python
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_EMBC, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_EMBC, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_EMBC, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_EMBC, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
]温馨提示:本文只是对yolov5基础上添加模块,如果要对yolov5n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
python
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py的parse_model函数替换添加C3_EMBC

2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_C3_EMBC.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀
python
from n params module arguments
0 -1 1 7040 models.common.Conv [3, 64, 6, 2, 2]
1 -1 1 73984 models.common.Conv [64, 128, 3, 2]
2 -1 3 339328 models.common.C3_EMBC [128, 128, 3]
3 -1 1 295424 models.common.Conv [128, 256, 3, 2]
4 -1 6 2535936 models.common.C3_EMBC [256, 256, 6]
5 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
6 -1 9 14815744 models.common.C3_EMBC [512, 512, 9]
7 -1 1 4720640 models.common.Conv [512, 1024, 3, 2]
8 -1 3 21064704 models.common.C3_EMBC [1024, 1024, 3]
9 -1 1 2624512 models.common.SPPF [1024, 1024, 5]
10 -1 1 525312 models.common.Conv [1024, 512, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 3 2757632 models.common.C3 [1024, 512, 3, False]
14 -1 1 131584 models.common.Conv [512, 256, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 3 690688 models.common.C3 [512, 256, 3, False]
18 -1 1 590336 models.common.Conv [256, 256, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 3 2495488 models.common.C3 [512, 512, 3, False]
21 -1 1 2360320 models.common.Conv [512, 512, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 3 9971712 models.common.C3 [1024, 1024, 3, False]
24 [17, 20, 23] 1 457725 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [256, 512, 1024]]
YOLOv5_C3_EMBC summary: 536 layers, 67638781 parameters, 67638781 gradients, 121.6 GFLOPs3. 完整代码分享
python
https://pan.baidu.com/s/1Smqah2PkjcWGdMPJTrdieg?pwd=xmb8提取码: xmb8
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识------Convolution
未改进的GFLOPs
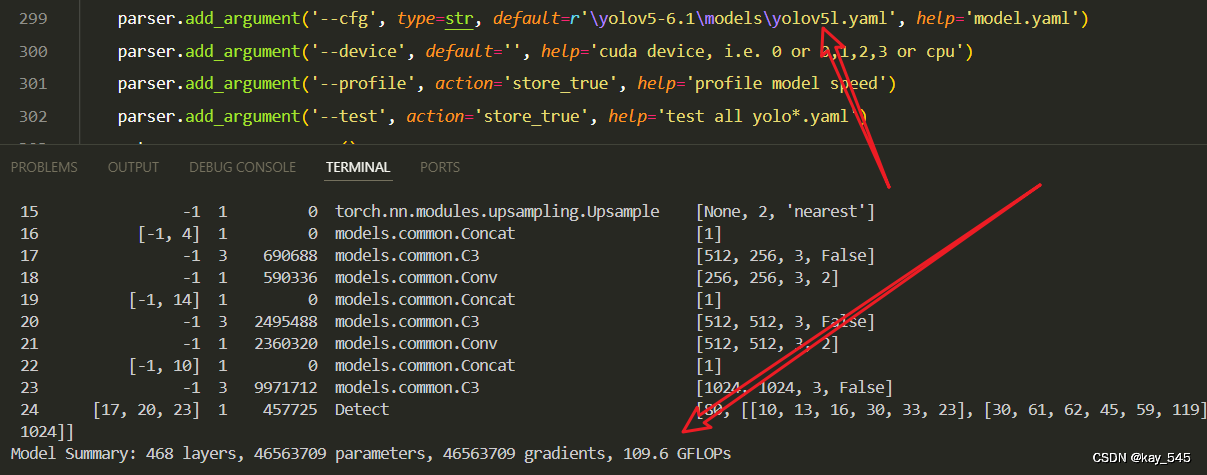
改进后的GFLOPs

5. 进阶
可以结合损失函数或者卷积模块进行多重改进
YOLOv5改进 | 损失函数 | EIoU、SIoU、WIoU、DIoU、FocuSIoU等多种损失函数------点击即可跳转
6. 总结
Effective Squeeze-Excitation Module (eSE) 的主要原理在于优化通道注意力机制,通过简化原始 Squeeze-Excitation (SE) 模块中的全连接层设计,从而在保持通道维度的同时避免信息丢失。传统 SE 模块通过全局平均池化提取通道间的统计信息,并通过两个全连接层对通道进行重新加权,然而这会导致部分通道信息的损失。eSE 模块通过将两个全连接层简化为一个全连接层,直接保持通道维度,进而提高了注意力机制的有效性。eSE 模块利用一体式聚合 (OSA) 模块,将多个层次的特征高效聚合,并通过引入残差连接来改善深层网络的优化,确保梯度在反向传播中的流动性,从而提升网络的训练效果和稳定性。这种改进不仅提升了网络在通道间信息重校准方面的表现,也增强了在目标检测和实例分割等任务中的精度和速度。