全文链接:https://tecdat.cn/?p=37409
分析师:Chunni Wu
随着互联网的不断发展,各领域公司都在拓展互联网获客渠道,为新型互联网产品吸引新鲜活跃用户,刺激用户提高购买力,从而进一步促进企业提升综合实力和品牌影响力。然而,为了更好地了解产品的主要受众群、识别并保留优质用户,企业仍需要对用户群体进行消费行为分析,判别用户的价值,从而优化营销策略**(** 点击文末"阅读原文"获取完整代码数据******** )。
相关视频
为达此目的,便需要对用户的行为数据进行分析,预测不同用户的潜在消费倾向,并针对不同用户实施个性化营销策略,以实现小成本促销、提高用户转化率的目标。本文所研究的公司属于教育领域,其开发并推广的低年龄段儿童课程契合当下社会对该年龄段儿童的教育需求,因而对用户下单情况和消费性行为价值的分析具有较高现实意义。
在本文提供了在线教育用户行为数据及分析代码,其中数据涵盖了 135969 条观测数据**(** 查看文末了解数据免费获取方式 ),包含用户个人信息、登陆情况、访问统计及下单情况等 49 个变量,为深入了解在线教育用户行为提供了参考。
任务/目标
任务1:对获取到的数据进行预处理,提高数据质量;
任务2:对用户的各城市分布情况、登陆情况进行分析,并分别将结果进行多种形式的可视化分析;
任务3:构建预测模型判断用户最终是否会下单购买或下单购买的概率,并将模型结果输出,且预测效果达到85%以上。
任务4:对用户进行消费行为价值分析,并以此为基础给企业提出合理的建议
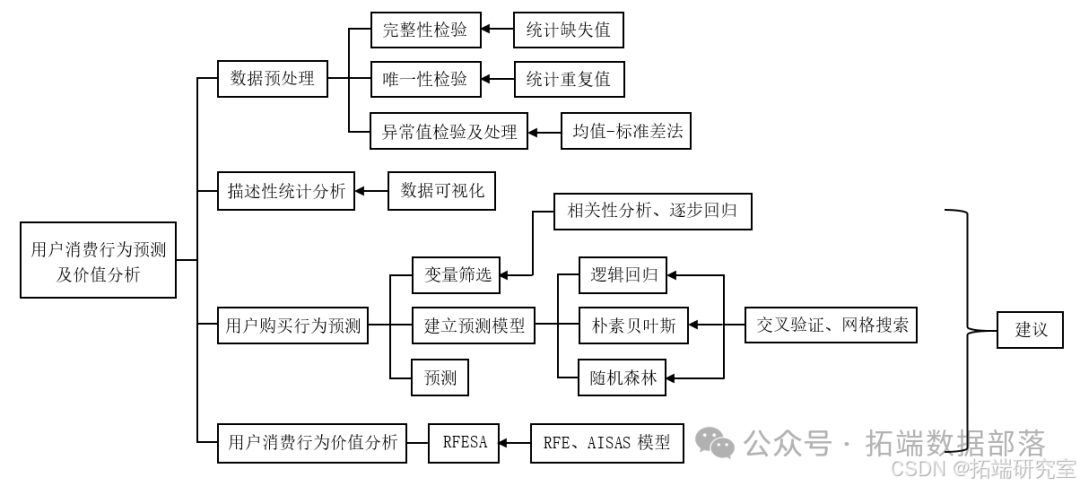
数据源准备
为研究用户消费行为价值,本文得到用户个人信息、登陆情况、访问统计及下单情况的数据,共49个变量,135969条观测数据。
登录数据:
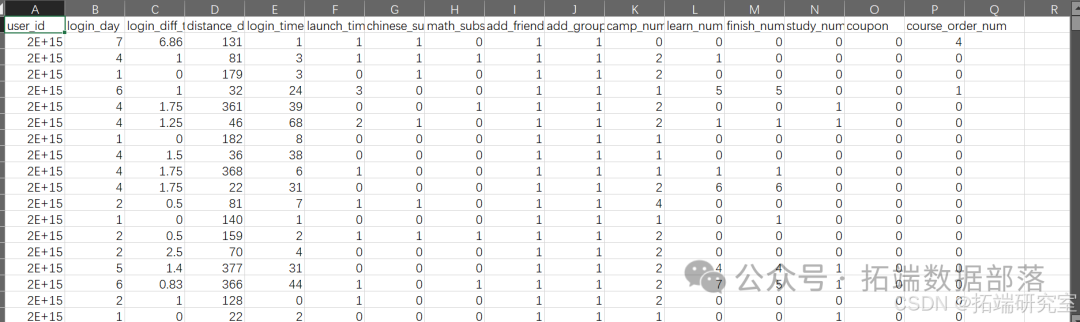 用户数据:
用户数据:

数据预处理
- 完整性检验
合并四张数据表并对各变量完整性进行分析,发现user\_info表中有809个用户在visit\_info和login_day表中均没有匹配的数据,此类信息的不完整性较难用统计方法进行填补,且仅用用户个人信息较难对其购买行为进行预测,也无法对其消费行为进行分析,故删除该809条观测,剩余135159条观测。同时,用户所在城市信息缺失较为严重,而下单情况中的缺失值即为未发生购买行为,可直接用0填补。此外,本文将用户所在城市匹配到所在省市,以支持后续研究。
- 唯一性检验
对数据集中的id变量进行唯一性检验,发现id变量的非重复观测数为135159,与原始数据集中的观测数相同,说明数据集中不存在重复观测。
- 异常值检验
首先,对数值型变量(除id变量user\_id与日期型变量first\_order\_time)进行均值、方差、最大最小值等统计量计算,初步识别可能存在异常值的变量。同时,在得到的统计量结果中可以得出app\_num的值均为1,属于单一型变量,因而不会对用户购买行为及用户的消费行为价值产生影响,故剔除app_num。
随后,由于对数据进行四分位距法识别异常值未能达到预期效果,本文基于大样本数据的近似正态性,采用均值-标准差法识别异常值。
数据可视化
- 用户城市分布
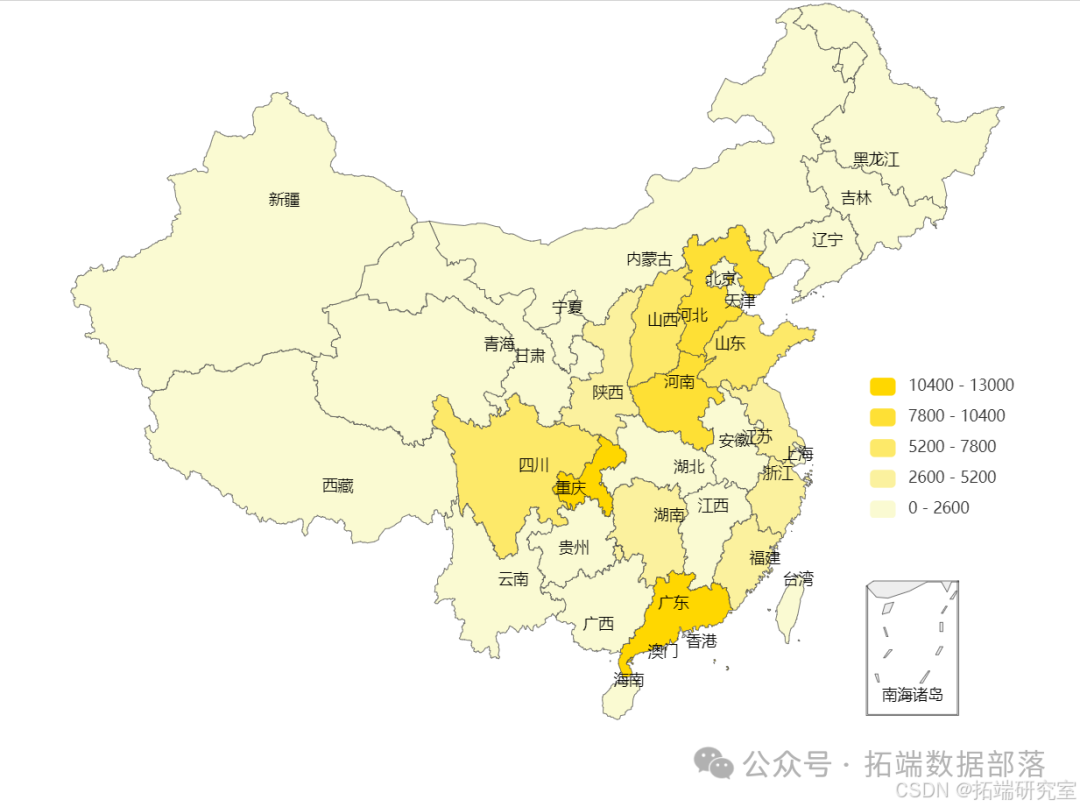

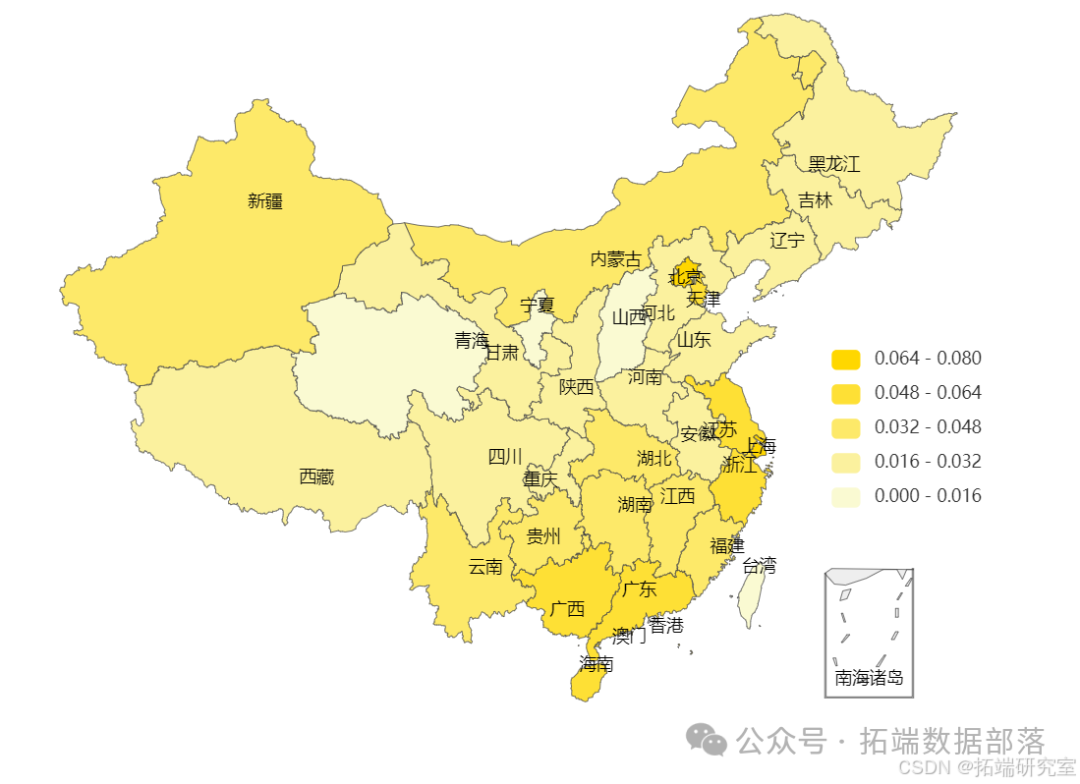
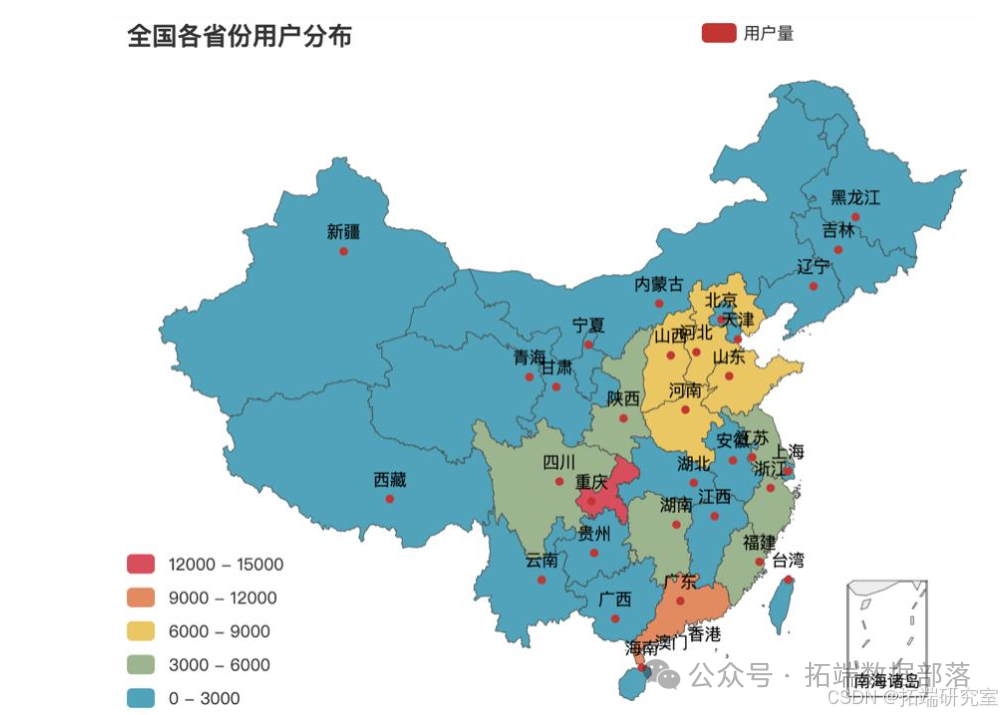
将用户城市信息匹配到所在城市,统计各省份的用户人数。可见用户主要集中在华北、川渝以及东南沿海各省市,其中又以广东、重庆为其主要客群所在市场。而华中、西北、西南以及东北地区客户分布数较少,还有较大的开发空间。
Chunni Wu
拓端分析师

同样根据各省份购买发生的人数占比,对应信息,可以发现虽然华北、川渝地区客群基数大,但实际购买的比例相比缺处于较低水平。相反京津沪地区以及沿海各省虽然基数并不处于高位,但是实际购买占比却是客观的。另外就广东省来说,无论其总体人数还是购买比例在总体比较中都处于较
大值。
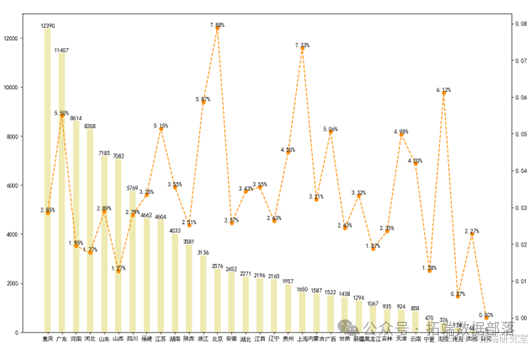
为更直观详细地考虑各省人数与购买比例数据信息,以各省总体基数绘制柱状图,附加各省对应的购买比。可见基数较大的省份除了广东以外前几位在购买比上表现都不佳。总体来看购买发生比都在2%-3%左右,但是北京、上海、江苏、浙江广西、广东和海南的购买比原高于别省,都在5%水平以上。
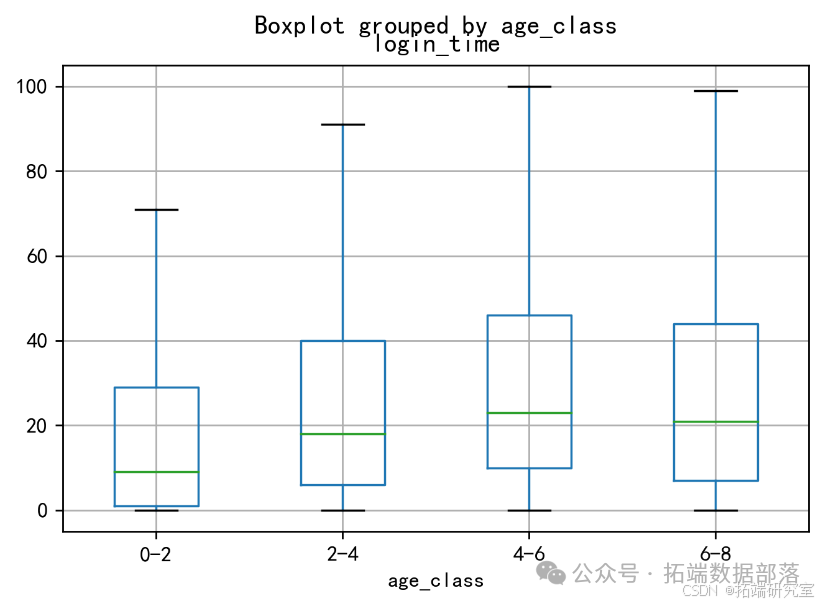
- 用户年龄与登陆天数、登陆时长的关系
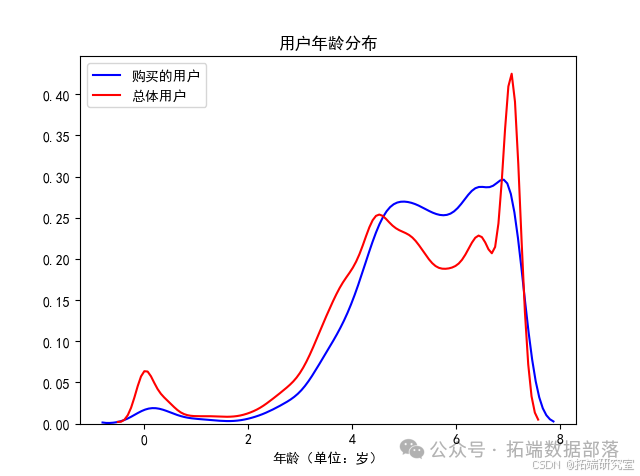
从用户孩子年龄分布中可以看出,总体而言,用户孩子的年龄主要分布在4岁至7岁,且在7岁左右达到峰值,在7岁之后显著下降,说明该网站的服务对象以即将入学和刚入小学的儿童为主,也辅以各种早教课程以满足年龄较小儿童的需求。同时,对于下单购买的用户,其孩子也主要集中在4岁至7岁,但人群密度相对于总体更高,说明孩子在该年龄段中的用户更容易发生购买行为,且该网站提供的课程及辅助功能更适合该年龄段的儿童。
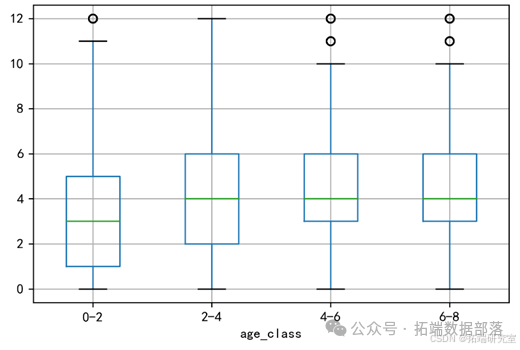
进一步研究各年龄段用户的平均连续登陆天数,总体而言,用户的平均连续登陆天数主要集中在6天以内,说明该公司产品的渗透性还相对较低。同时,孩子在2岁至8岁之间的用户较孩子小于2岁的用户平均连续登陆天数更多,但没有显著差异。该结果说明,公司在用户吸引力方面对不同年龄段孩子的家长有较为平均的效果,但仍需拉动孩子年龄小于2岁的用户,以确保公司的均衡发展。
此外,对各年龄段用户平均登录时长进行分析,发现随孩子年龄的增长,用户的平均登录时长有上升趋势,而当孩子年龄>6岁时有细微下降。该结果表明公司所推出的产品能在更大程度上满足即将入学和刚入小学的儿童的需求,从而表现为该年龄段孩子的家长有更长的登录时长。
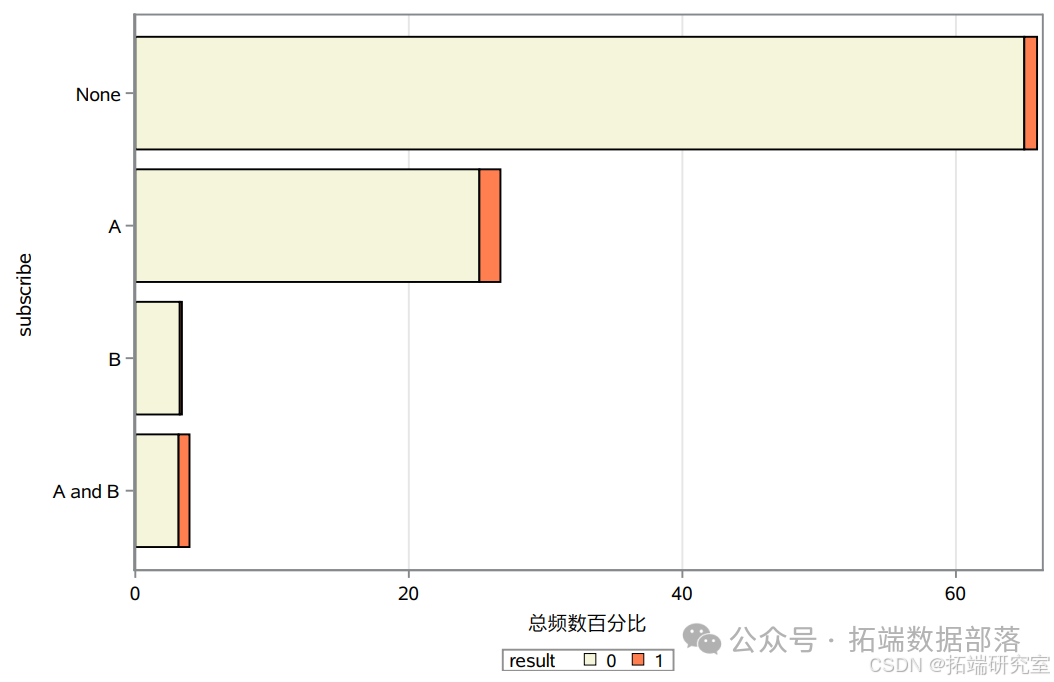
- 公众号关注情况与购买行为
从公众号关注情况可以发现,有超过60%的用户没有关注语文学习公众号chinese\_subscribe(A)和数学学习公众号math\_subscribe(B),而仅有5%左右的用户同时关注了语文学习公众号和数学学习公众号,说明该企业的公众号还有待推广。进一步研究公众号关注情况与用户最终购买情况的关系,发现仅关注语文学习公众号的用户和同时关注语文学习公众号和数学学习公众号的用户有相对较高的购买倾向,说明语文学习公众号的开发和推广有助于提高用户的课程购买欲。
点击标题查阅往期内容

PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像

左右滑动查看更多
01
02
03
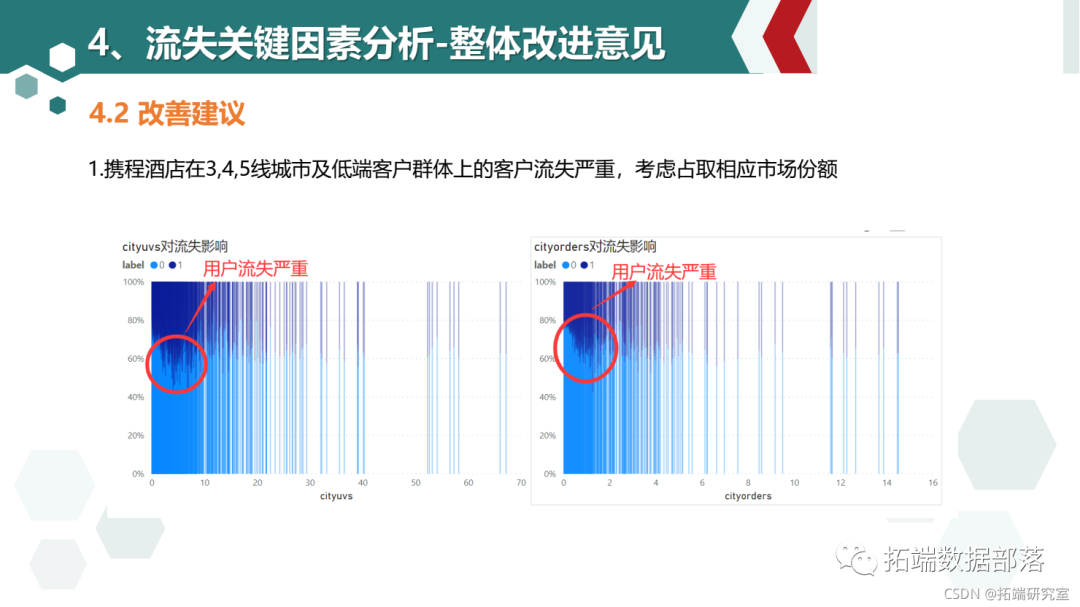
04
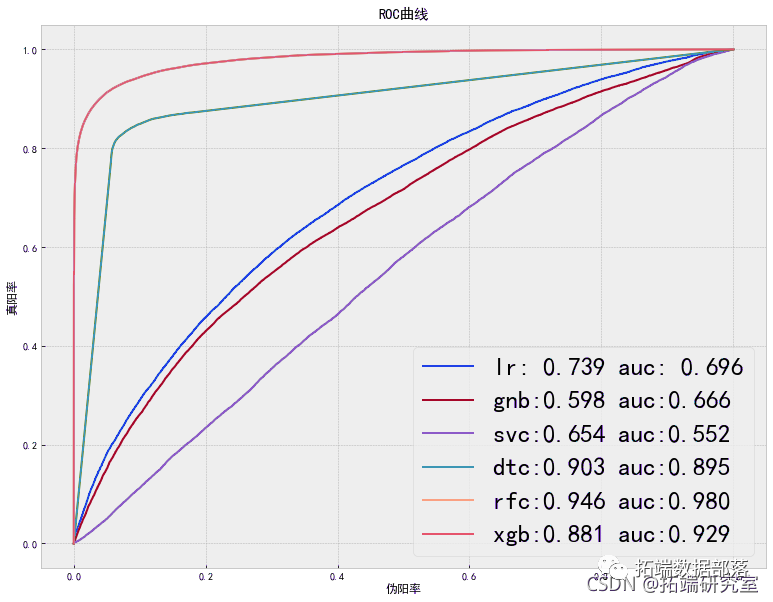
模型与方法
SMOTE 算法
SMOTE,即合成少数类过采样技术,它是一种基于随机过采样算法改进训练集的方案。其基本思想是对少数类样本进行深入分析,然后依据少数类样本人工合成新样本并添加至数据集中。具体算法流程如下:
其一,针对少数类中的每一个样本,以欧氏距离为标准,计算该样本到少数类样本集中所有样本的距离,进而得出其近邻。
其二,根据样本不平衡比例设定一个采样比例,以此确定采样倍率。对于每一个少数类样本,从其近邻中随机挑选若干个样本,假设所选择的近邻为。
其三,对于每一个随机选出的近邻,分别与原样本按照如下公式构建新的样本。
Logistic 回归
Logistic 回归模型常被用于探究二分类观察结果与诸多影响因素之间的关系。该模型能够运用极大似然估计实现参数的估计,从而剖析因变量与多个自变量之间的定量关系,并据此预测因变量的未知响应值。
朴素贝叶斯
朴素贝叶斯模型假设每一类样本服从。
随机森林
随机森林是基于 bagging 框架下的决策树模型。随机森林由众多树组成,每棵树均给出分类结果。每棵树的生成规则如下:
首先,用表示训练用例(样本)的个数,用表示特征数目。
其次,输入特征数目,用于确定决策树上一个节点的决策结果,且远小于。
接着,从个训练用例(样本)中以有放回抽样的方式,取样次,形成一个训练集(即 bootstrap 取样),并用未抽到的用例(样本)进行预测,评估其误差。
然后,对于每一个节点,随机选择个特征。决策树上每个节点的决定都是基于这些特征确定的。在节点寻找特征进行分裂时,并非对所有特征找到能使指标(如信息增益)最大的,而是在特征中随机抽取一部分特征,在抽到的特征中间找到最优解,应用于节点进行分裂。
最后,每棵树都会完整成长而不会剪枝,这一做法有可能在建成一棵正常树状分类器后被采用。
对特征重要性的评判采用 Gini 系数法。
建模
- 相关性分析
首先,本文对难以进行现实意义解释且取值范围较单一的变量platform\_num和model\_num进行删除;同时,用户的体验课下单时间first\_order\_time与最终的下单行为预测和用户消费行为价值分析无实际关联意义,也进行删除处理。
随后,为更好地了解变量之间的相互影响关系,对各变量与因变量result进行相关性分析。在5%的显著性水平下,认为progress\_bar、baby\_info与result的相关性不显著,因而在变量的初步筛选中剔除progress\_bar、baby\_info。其余变量都与result有显著的线性相关关系。
- 变量筛选
通过与因变量的相关性分析进行初步筛选后,为避免变量内部的相关关系由于包含无用属性或训练数据对模型产生过度拟合,本文利用逐步回归法对除user_id外的剩余变量进行进一步筛选。具体参数设置如下,以5%显著性为界筛选变量进入模型回归,另以1%显著性为界判断已选择的变量是否符合继续停留在模型中。
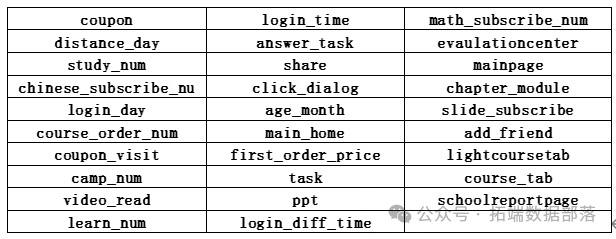
最终选取变量为:
建立模型
(1)数据处理
对于清洗过后的数据集,经统计购买人数为4639人,总人数为135159人。可见购买人数与未购买的人数比约为1:28,可见数据处于十分不平衡的状态。考虑到不平衡数据对于后续模型预测精度的影响,这里先用SMOTE过采样算法处理数据,使得购买与未购买的总体数量基本均衡。另外考虑到数据单位对于拟合的影响,在建模前也对数据进行了标准化处理。
(2)模型选择
基于过采样后的数据为获得最佳预测结果,尝试以下三种模型。在实际操作中,设置5折交叉验证,通过具体交叉验证的结果获得期望泛化误差的估计值。并认为泛化误差较小的模型最终拟合效果较好。
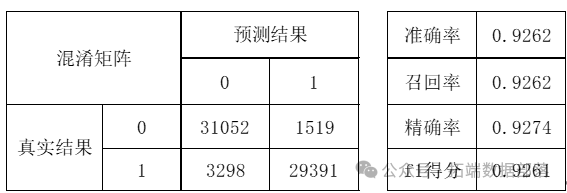
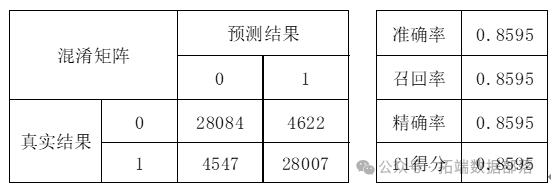
首先考虑逻辑回归模型。逻辑回归模型实施简单,算式简洁高效,很符合处理本案例中的大量0-1型数据集的要求。将数据代入模型拟合得到期望泛化误差结果为0.1045,具体的训练集上的混淆矩阵及各指标值如下所示:
逻辑回归混淆矩阵及其他指标
为防止模型过拟合现象的出现,这里进一步考虑添加随机森林模型。随机森林不仅可以通过随机性的引入降低过拟合现象,同时它采用集成算法能尽可能地提升预测的准确率。代入数据得到其期望泛化误差为0.0180,在训练集上得到以下结果。
随机森林混淆矩阵及其他指标
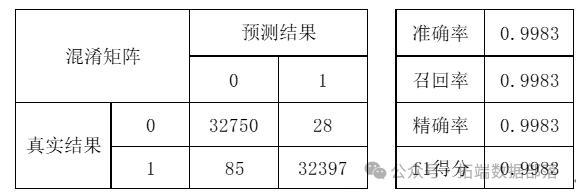
最后再尝试朴素贝叶斯模型,借助交叉验证,得到期望泛化误差为0.1773,在训练集上得到以下结果值。
朴素贝叶斯混淆矩阵及其他指标
因此综合以上结果,对比期望泛化误差可以发现,随机森林的拟合效果最好。而它在测试集上的各项指标表现情况也是最佳的。所以将随机森林作为后续的拟合模型。
4 .随机森林参数选择
将随机森林确定为拟合模型后为提高精度进行参数选择。这里参数选择手段采用网格搜索的方法,主要考虑随机森林中涉及的两个参数:随机森林树的数目(n_estimators)以及寻找最佳分割时要考虑的特征数量(max_features)。在网格搜索时考虑的范围为:n_estimators:10,50,100;max_features:"auto", "sqrt", "log2"。网格调参结果为n_estimators取100 以及max_features取"auto"。
在最优参数下,以4:1划分训练集与测试集,获得在测试集上的表现如下:
最优随机森林训练结果
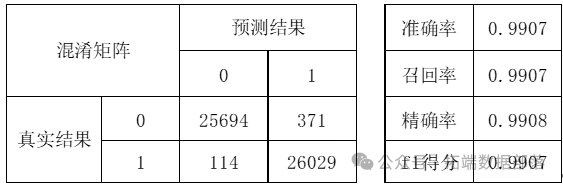
可见模型在训练集上的准确率已经达到99%的较高水平,拟合效果良好。
5. 模型预测
最后,基于以上最优参数下的随机森林模型,对已有的用户信息进行预测,得到的预测准确率为93.63%。
用户消费行为价值分析
- 用户画像
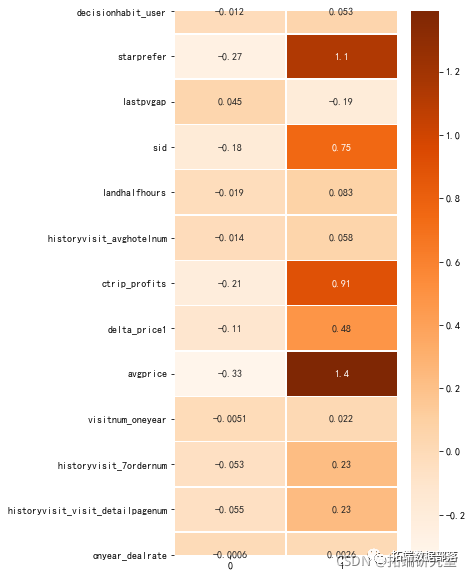
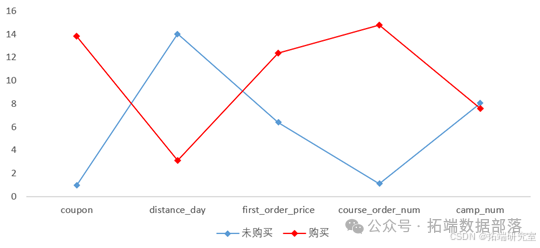
本文选取随机森林结果中重要性程度排名前五的变量,对购买及未购买的用户数据取均值并等比例缩放,得到如下用户画像折线图。
对于领券数量coupon,最终下单的用户领券数量远远高于最终未下单的的用户,该结果表明有最终购买倾向的用户往往会在前期领取优惠券,未后续的课程购买做准备。
对于最终登录距期末的天数distance_day,最终未购买的用户往往比最终购买的客户天数更长,说明最终未购买的用户对公司的课程产品兴趣程度较低,也不会时刻关注公司产品的更新情况和发展情况;而最终购买的用户则相对而言更关注公司产品的更新情况,且也会因完成课程的原因持续登录公司网站和app。
针对体验课价格first\_order\_price,下单用户所参与的体验课价格比未下单用户参与的体验课价格高,可能由于下单用户在正式下单前已参与了较多体验课程以充分了解该公司推出的课程情况,从而促使其进行课程购买。同时,未下单用户所参与的体验课较少,可能由于公司目前推出的课程无法满足此类人的需求、体验课的吸引力较低,公司应当进一步了解市场需求及提高教学质量,以吸引更多人参与到线上课程中。
对于有年课未完成订单course\_order\_num,最终下单用户的订单数较多,说明参与年课的用户往往会继续购买年课以支持孩子今后的学习,也侧面反映出该公司推出的年课产品能在一定程度上激起用户持续购买的欲望。
对于开课数coupon,最终购买用户与最终未购买用户相差不大,但最终未购买用户的开课数较最终购买用户的开课数有细微提升,说明有较多用户在开课后并没有购买此课程,这可能由于课程的实际内容与消费者的心理预期有较大差别,从而导致消费者购买心态的变化。
- 基于RFE和AISAS模型的用户价值分析(RFESA)
RFE模型,即用户活跃度模型,其根据会员最近一次访问时间R(Recency)、访问频率F(Frequency)和页面互动度E(Engagement)得出RFE得分,并基于三个维度对用户的活跃的进行分析。
AISAS模型,即互联网时代消费者行为分析模型,其从传统的AIDMA营销法则发展而来,是电通公司针对互联网导致传统购物行为变化所总结出来的一种新的消费者行为分析模式。该模型通过注意A(Attention)、兴趣I(Interest)、搜索S(Search)、行动A(Action)和分享S(Share)对用户消费行为价值进行分析。
本文基于RFE模型和AISAS模型,针对本文所涉及到的变量构建用户价值分析模型(RFESA)。本文选取随机森林结果中重要性程度排名前十五的变量,并将其分为:
-
访问时间R(Recency):distance_day
-
访问频率F(Frequency):login\_day、login\_diff\_time、login\_time
-
用户参与度E(Engagement):camp\_num、learn\_num、video\_read、main\_home、ppt、task
-
分享S(Share):share
-
购买倾向A(Action):coupon、first\_order\_price、age\_month、course\_order_num
随后,本文基于RFESA中各变量的权重计算出数据集中每位用户的R、F、E、S、A值,并对最终购买用户和最终未购买用户分别计算R、F、E、S、A均值,得到如下雷达图:
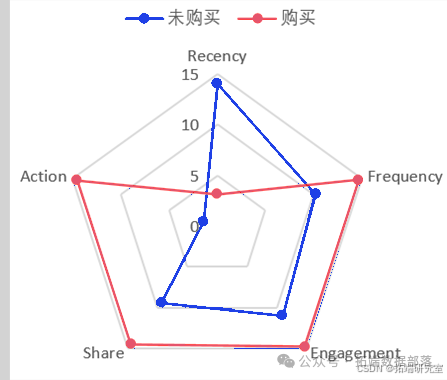
从图中可以看出,在访问时间R(Recency)方面,未购买用户的最终登录距期末的天数较购买用户而言明显增多,说明未购买用户的总体访问时间较为分散,与该公司网站或app的联系程度较不密切。
在访问频率F(Frequency)方面,购买用户的访问频率较高,说明用户的消费行为一定程度上受到其访问频率的影响,对该公司网站和app的访问越频繁,用户便能及时了解该公司在各类课程上的推进和更新。此外,熵权法结果显示Frequency中login_time所占权重最大,说明用户的登录时长在很大程度上反映了用户的访问频率,登录时长越长,说明用户对该公司推出的课程产品及辅助产品有较高的关注度与兴趣度,进而会促进其购买。
在用户参与度E(Engagement)方面,购买用户的用户参与度高于未购买用户的参与度,表明购买用户往往会对公司网站和app上的页面进行访问,学习的课程数较多,且更多参与ppt学习、视频学习、任务达成等环节,与该公司培养了较为紧密的互动关系。
在分享S(Share)方面,最终购买的用户往往更会将该公司网站或app上的内容分享给他人,同时也体现了分享次数较多用户对该公司所推出产品的满意度较高,因而更有意愿对各类课程进行购买。
在购买倾向A(Action)方面,领券数量和有年课未完成订单往往对用户的购买倾向产生显著的影响。最终购买的用户,其购买倾向得分远远高于最终未购买的用户,同时也表现为其领券数量较多、有年课未完成订单数较多、所参与的体验课总价较多,且孩子的年龄符合该公司推出的多数课程产品,能较好地满足其教育需求。
通过上述分析,基于最终购买用户和最终未购买用户在R、F、E、S、A上的均值水平,进一步将用户分为4类:
-
潜在流失用户:Recency>140时,可认为该用户为潜在流失用户。用户的最后登录距期末天数较长时,说明其对公司产品兴趣程度较低,该公司提供的产品及辅助项目无法满足用户实际需求,这会导致用户不再关注该公司推出的各项产品与服务,从而成为流失用户。针对此类用户,公司应当及时跟进市场需求,抓住用户痛点,并将课程更新信息及时推送给用户,从而提升潜在流失用户对公司及产品的好感度。
-
重要发展用户:Frequency>21 且 Engagement>32时,可认为该用户为重要发展用户。访问频率高且参与度高的用户更容易购买该公司推出的产品,针对此类人群,公司应当给予一系列优惠政策和购买福利,刺激用户进行消费并针对其课程反馈进一步提升公司产品,将其发展为公司长期的优质客户。
-
有价值用户:Share>6且Action>3时,可认为该用户为有价值用户。此类用户不仅拥有较强的产品购买倾向,还能通过分享为公司起到宣传作用,从而拓宽公司产品的受众人群,吸引更多年龄段的用户。同时,公司也应当不断拓展产品种类,针对不同年龄段的人群推出不同课程,以增加产品的宣传性及吸引力。
最优用户:当Frequency、Engagement、Share、Action都大于上述阈值时,可认为该用户为最优用户。最优用户是公司应当重点关注的人群,公司应当及时获取此类用户对产品的反馈及建议,通过产品革新和新产品引进维持与最优用户之间的紧密关系,以帮助企业长期稳定发展。
结果
综合分析全篇,本文聚焦网课产品,以网课消费者的相关用户数据入手展开分析。首先通过数据清洗,排除异常值等其他不完善信息,为后续分析奠定基础。接下来通过描述性统计获得了用户的地理分布、不同年龄段平均登录时长与公众号与购买情况的图像。从中可以直观地发现目前客户仍是集中在华北、川渝即沿海各地。消费主要人群是4-6岁的学龄前儿童以及6-8岁的初上小学的儿童。而语文类公众号对于是否购买也影响显著。在模型筛选中,通过逻辑回归、随机森林与朴素贝叶斯分类器的比较,最终选定随机森林预测用户的购买行为。在测试集上达到99%准确率的良好结果,而在整体预测中也实现了93%的较高准确率。最终基于以上信息,将用户分为四类,分别是潜在流失用户、重要发展用户、有价值用户以及最优用户。对于潜在流失用户要及时监测、把握需求,通过推荐信息等方式挽回顾客。对于重要发展用户则是加大优惠力度,提升其消费倾向与可能。而对有价值用户则可以考虑以其为市场发展突破口,做好积极营销与产品体验,从而实现以一带多。最后对于最优客户则是公司重点关注人群,应该与其紧密联系,最大可能保有此类稳定消费输出人群。最后由用户角度分析,形成以下建议。
1、实施地区差异化营销,提升地区占有率与购买率
通过地区描述分析可以发现公司的客户主要集中在华北、川渝以及沿海地区,公司在保有这部分客户的前提下可以积极扩展,以区带片推动其他地区的增长。另外川渝等总体基数大但购买比例低,有潜力提升购买量。因而针对这些地区可以有针对性地展开调研,获取用户真实消费需求,设定合理的消费产品以及定价以此提升购买量。
2、丰富课程种类,关注年课产品开发
就现有情况分析,可见公司产品目前的主要消费人群是4-7岁的学龄前与初上小学的儿童。公司可考虑进一步开发其他业务,发展消费人群。除了针对学龄前教育外还可逐步推出小学阶段的巩固、辅导性学习等课程,满足其他年龄段消费者的需求。另外由通过年课用户发生购买比例高的现象可以提示公司应该重视年课产品的开发。丰富年课产品、提升相关课程以及后续服务质量,以此在稳定已有客户的基础上,吸引更多的消费者。
3、提升体验课等课程质量,契合消费者需求
未下单的用户参与的体验课较少,说明体验课的覆盖力度还有待加强。另外在其他课程方面,即使是开课了的用户仍然有较大比例并未发生购买行为。因此课程的实际体验效果可能与其存在出入。建议公司把握市场动向,跟进消费需求。同时可以在每节体验课与其他课程之后添加反馈调查,搜集用户的使用体验,以此作为改进和提升的方向。
4、实施推荐策略,提升用户粘性
研究发现对网站访问越频繁的用户越可能成为潜在购买人群。因此可以通过一些推荐手段,提升用户对于网站的访问时间与频次。比如设置每天登陆奖励或登陆任务使用户形成周期登陆习惯;另外可考虑微信、其他关联网站的推送信息,从他端吸纳顾客,增加访问量;也可以构建用户生态,让用户彼此可以交流学习,以此稳定已有用户。另外优惠券也是一种十分有效的促进手段。通过优惠券可以间接向用户推荐相关课程。而事实也证明,领取优惠券越多的客户越可能购买产品。公司在监测到相关需求后可进一步提升优惠力度,将其转化为实际消费流量。
在线教育用户行为可视化分析与建模|附数据、代码
获取数据并进行预处理,提高数据质量;
go
import pandas as pdimport numpy as npfrom pyecharts.charts import *from pyecharts import options as optsimport matplotlib as mplfrom matplotlib import pyplot as pltimport seaborn as snsimport openpyxl
``````
# 导入数据user\_info=pd.read\_csv('user\_info.csv')login\_day=pd.read\_csv('login\_day.csv')visit\_info=pd.read\_csv('visit\_info.csv')result=pd.read\_csv('result.csv')数据初步观察
go
print(user\_info.info())print(login\_day.info())print(visit_info.info())print(result.info())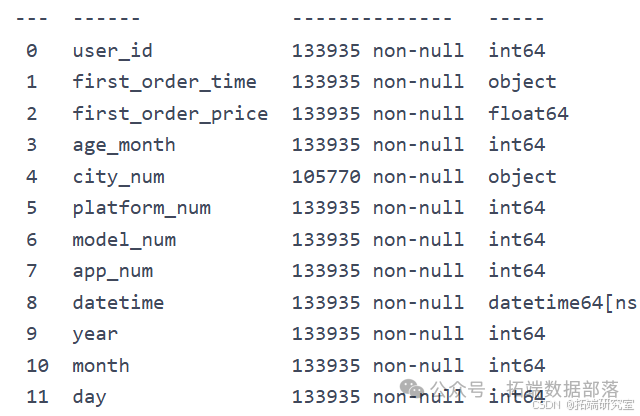
缺失值处理
go
# 判断是否存在缺失值:仅发现user\_info中city\_num存在27948个,此处暂不处理,根据后续实际问题选择处理方式。print(user_info.isnull().sum())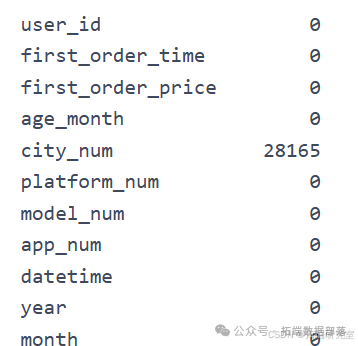
重复值处理
go
# 判断是否存在重复值,若存在剔除重复值print(user_info.duplicated().sum())异常值处理(依据数据的统计分布情况和实际意义)
go
# 一、根据各数据集描述统计情况初步判断异常情况print(user\_info.describe())print(login\_day.describe())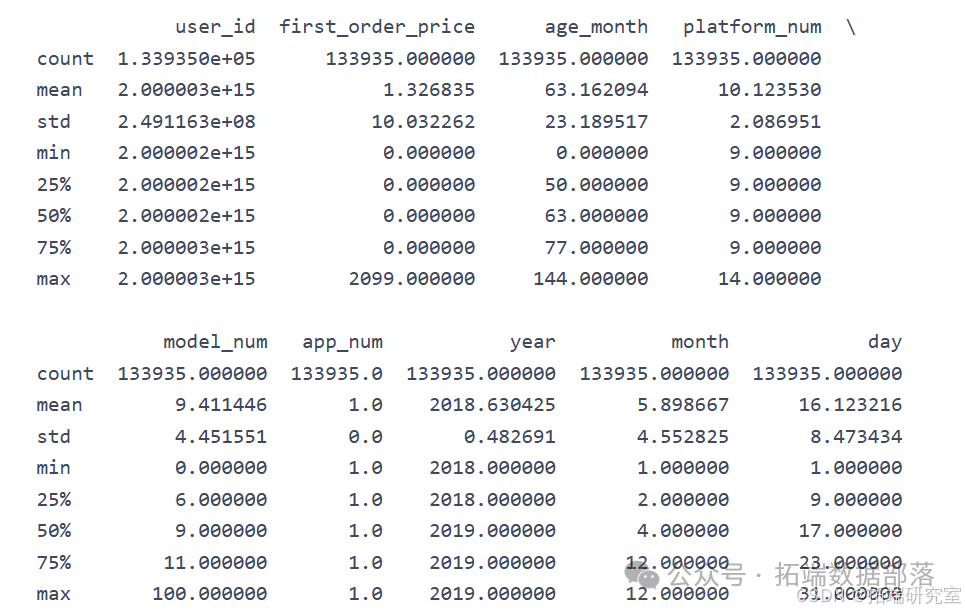
对用户的各城市分布情况、登录情况进行分析,并分别将结果进行多种形式的可视化展现;
用户各城市分布情况的可视化
go
# 剔除city\_num为na值的行,得到user\_info1user\_info1 = user\_info.dropna(subset=\['city\_num'\])user\_info1 = user\_info1.reset\_index(drop=True)print(user_info1)
不同时间PV、UV流量统计
go
"""字段说明:PV(Page View):页面的浏览量或点击率,其中点击或刷新一次总量增加一次UV(Unique Visitor):独立访客数,1天内访问某站点的用户数"""# 现将obj格式转换为时间格式user\_info\['datetime'\] = pd.to\_datetime(user\_info\['first\_order_time'\])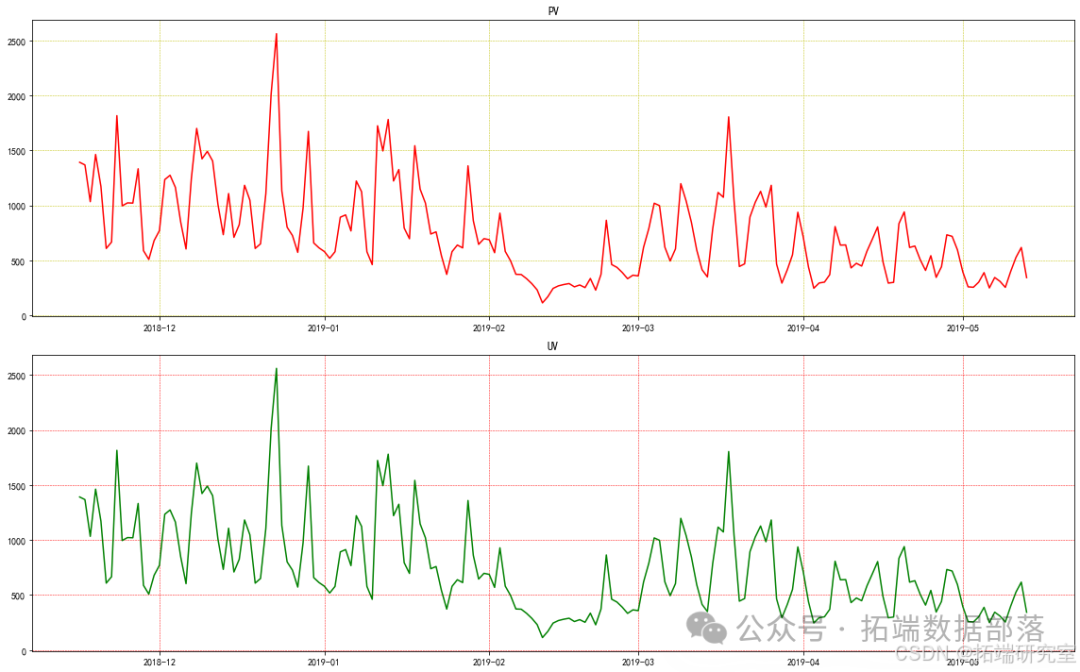
决策树的购买预测模型构建
以 result(是否购买:1 代表购买, 0 代表不购买)作为因变量,其余变量作为自变量进
行建模,其中将体验课下单时间转化为年份,通过模型预测用户是否购买。通过对数据进行
预处理,我们得到 133935 条有效样本,但是其中购买的样本数远小于不购买的样本数,故对
购买的样本进行随机过采样,最终得到 253935 条有效样本。将处理好的数据随机分成训练集
和测试集,其中训练集占总数据的 70%,测试集占总数据的 30%
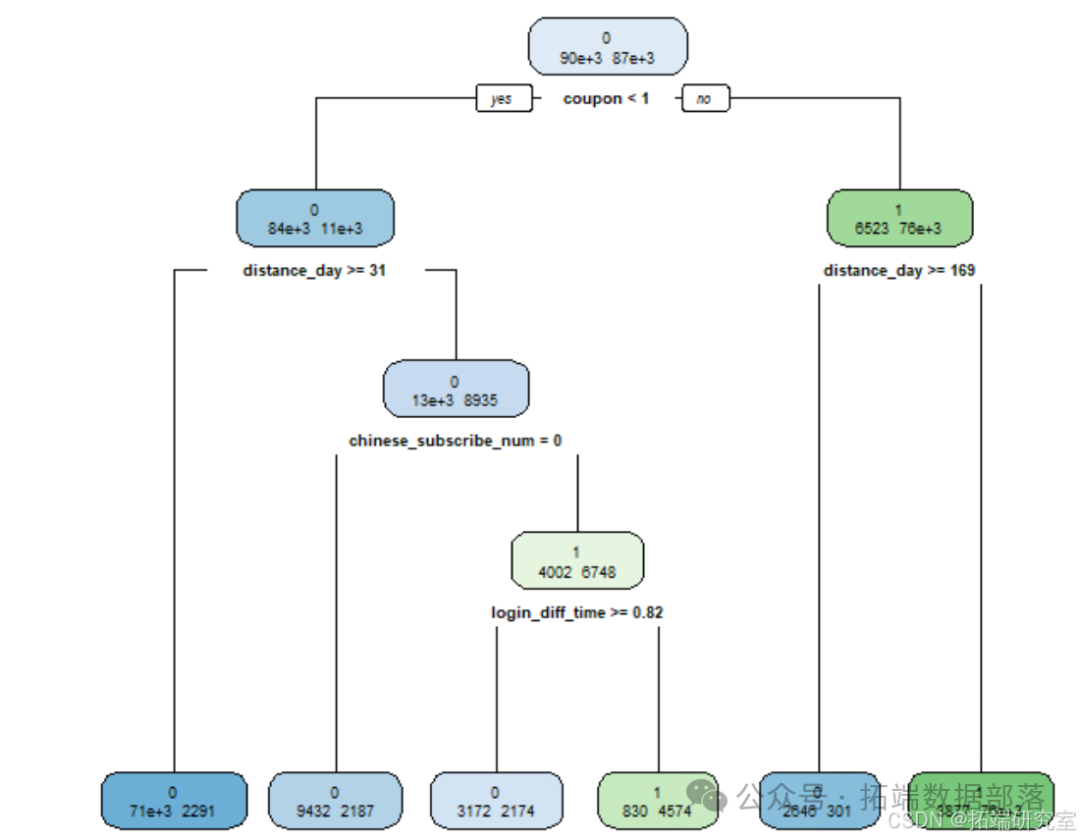
使用单独的决策树做预测,并不是越大越好,因为有可能出现过拟合现象,因此必须限
制决策树的规模1。程序包 rpart 可以计算一个复杂度参数(cp,默认值为 0.01),用于控制
决策树的大小并选择最佳树大小。从表 4.1 中可以看出,第 5 行的 cp(等于 0.01),交叉验
证误差较小且相对于其他 cp 值最小,因此,我们得到的决策树不需要进行修剪。
模型评估
对于一个二分类问题,特异性(specificity) 代表在所有真是情况为反例的样本中,被预
测为反例的比例;查准率(precision) 代表在所有预测为正例的样本中,真实情况为正例的比
例;查全率( recall) 代表在所有真实情况为正例的样本中,被预测为正例的比例;敏感性
(sensitivity) =查全率。通过计算公式可以看出,特异性、查准率、查全率越高,模型的预测
效果越好。但是,通常情况下,查准率和查全率是一对矛盾的指标,当查准率高时,查全率
低;查全率高时,查准率低。在本案例的二分类问题中,下单购买代表正例,未下单购买代
表反例。在本案例中,我们应该着重关注查全率,以防止潜在客户流失,因为我们最不希望
的是将下单购买的用户预测为不会下单购买的用户。
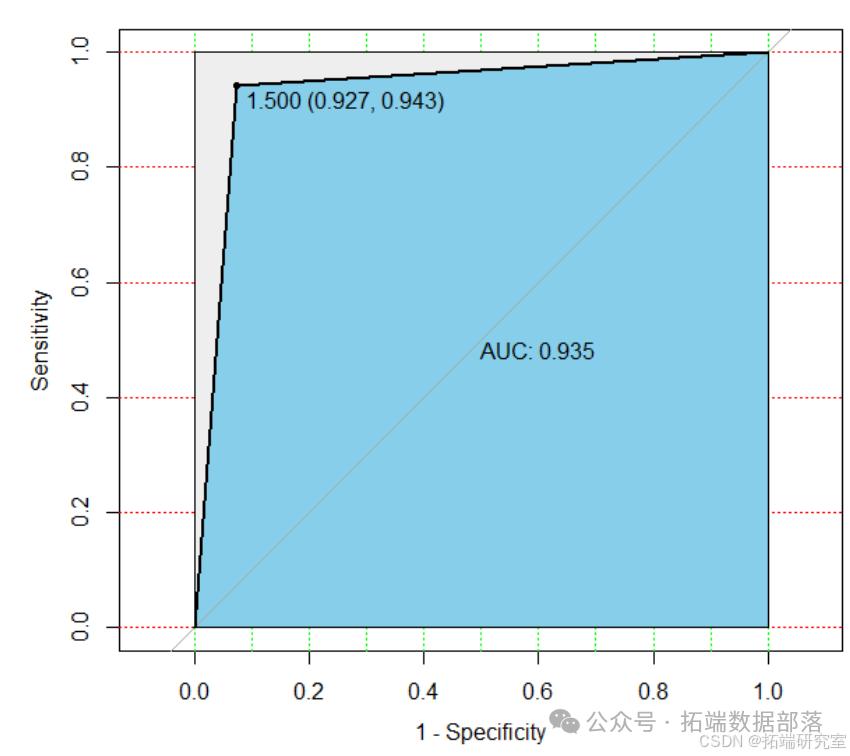
结果预测
利用我们经过过采样得到样本训练的分类器对原有的 133935 条有效样本进行预测,预测
结果见(predict\_result\_output.csv),其误判率为 0.0535。在对用户
是否下单进行预测时,我们最不希望的是将下单购买的用户预测为不会下单购买的用户。而
本分类器进行对原有的 133935 条有效样本预测时,查全率为 0.9207,此分类器可以有效的识
别潜在客户
用户消费行为价值分析
用户流失率分析
go
# 注册用户数login\_users\_counts = user\_info\[user\_info\['app_num'\]!=0\].shape\[0\]# 加入课程用户数
用户价值分析
go
#画出体验课下单时间的人数分布图plt.plot(user_info.groupby('datetime')\['use
用户购买行为与领券行为的相关性分析
go
"""新建consumer\_behavior数据集包含变量user\_id、first_order
RFM用户价值分析
go
#画出体验课下单时间的人数分布图plt.plot(user_info.groupby('dateti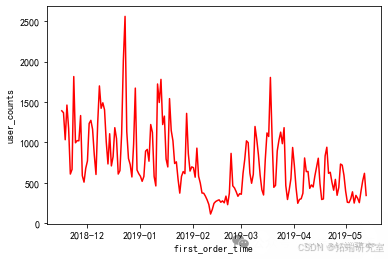
go
R:最近一次消费时间间隔F:消费频率 #由于我们前面的计算发现没有重复的user\_id,因此用户在此时间段内全部都是下单一次,即所有F都为1,所以不考虑FM:消费金额'''#通过上面的折线图,我们发现在在2018年12月-2019年1月这个时间段下单的人数较多,因此,我们假设现在是2018年12月31日,分析最近30天的用户#计算R、M值user=user\_infouser\['datetime'\] = pd.to\_datetime(user\['first\_order_time'\])user\['year'\]=user\['datetime'\].dt.year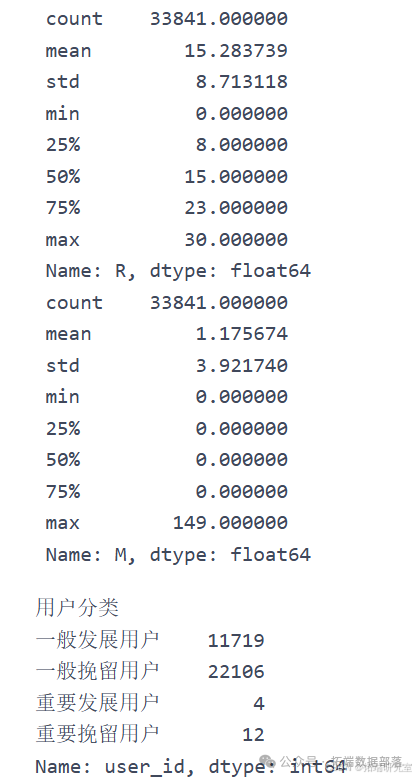
关于分析师

在此对 Chunni Wu 对本文所作的贡献表示诚挚感谢,她在上海财经大学完成了经济统计学专业的硕士学位,专注数据预处理、数据可视化、机器学习领域以及用户消费行为预测及价值分析。擅长 SAS、R 语言、Python。
数据获取
在公众号后台回复"网课数 据",可免费获取完整数据。

本文中分析的数据、代码**** 分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取全文完整代码数据资料。
本文选自《Python、R用RFM模型、机器学习对在线教育用户行为可视化分析》。
点击标题查阅往期内容
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线




