全文链接:https://tecdat.cn/?p=37450
分析师:Shixian Ding
主成分分析(PCA)作为数据科学中用于可视化和降维的重要工具,在处理具有大量特征的数据集时非常有用。就像我们难以找到时间阅读一本 1000 页的书,而更倾向于 2 到 3 页的总结以抓住整体概貌一样,当数据集中特征过多时,PCA 可以帮助我们减少维度,提高模型训练效率,同时尽可能保留更多信息**(** 点击文末"阅读原文"获取完整代码数据******** )。
例如在图像处理和基因组研究等常见应用中,往往需要处理成千上万甚至数万个列的数据,此时维度灾难可能成为问题,而 PCA 则能发挥重要作用。
视频
降维中的主成分分析法(PCA)
在众多的数据集中,部分变量的研究价值相对有限。为了实现连贯性分析,降维便成为一种必要手段。而在降维过程中,关键在于尽可能地保留原始数据中的有用信息。接下来,以二维数据降为一维为例,对主成分分析法进行介绍。
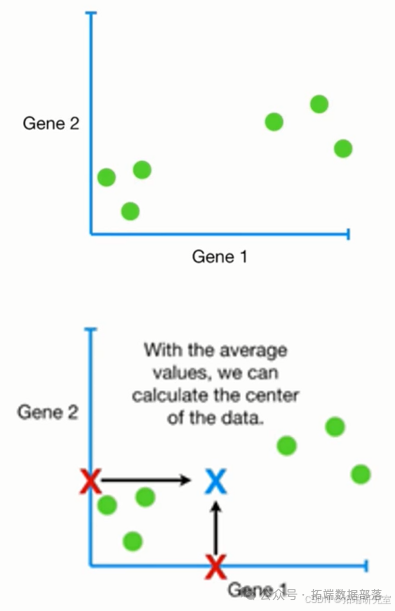
由于我们所研究的主要问题在于参数之间的相关关系,而这种相关关系主要体现在各个数据点的相对位置方面。需注意的是,数据点的具体位置并不会对其相关关系产生影响。

接下来,我们需要找出对数据影响最大的方向。为此,不妨设定一个单位向量来表示这个方向。然后,将表示各个数据点的向量向该方向进行投影,并求出方差的表达式。
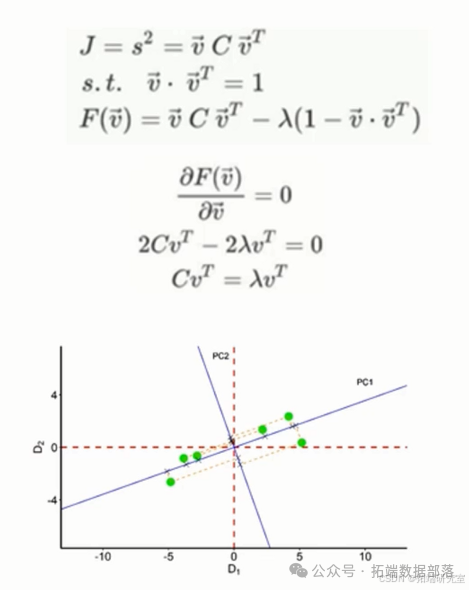
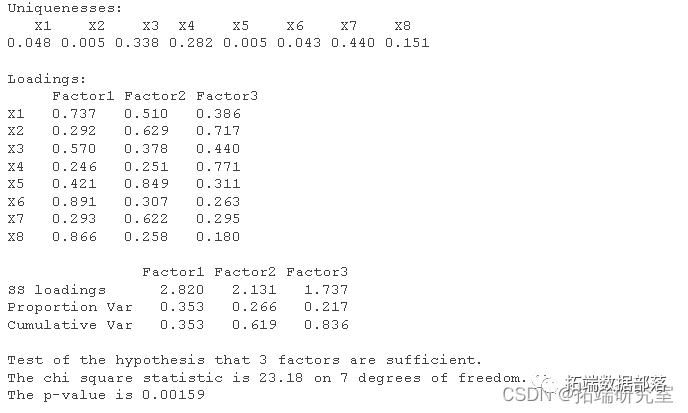
在对数据影响最大的方向上,数据点的分散程度最高,也就是方差最大。在此处,我们运用拉格朗日乘数法来求取最值。从化简后的结果可以看出,我们所寻求的方向正是数据协方差矩阵的特征向量方向。对协方差矩阵进行特征值分解,特征值中较大的那个所对应的特征向量具有重要意义。
一、实现过程
-
数据标准化:首先对数据进行处理,使其每个特征的均值为零,方差为一。
-
这样可以确保数据在后续分析中的稳定性和可比性。
-
协方差矩阵计算:计算标准化后数据的协方差矩阵,该矩阵能够描述特征之间的相关性。
-
协方差矩阵反映了不同特征之间的关联程度。
-
特征值分解:对协方差矩阵进行特征值分解,从而得到特征值和对应的特征向量。
-
特征值和特征向量在主成分分析中起着关键作用。
-
主成分选择:依据特征值的大小,选取前 k 个特征值对应的特征向量,以此构建新的坐标系。
-
选择重要的特征向量可以更好地表示数据的主要信息。
-
数据投影:将原始数据投影到新的坐标系中,进而得到降维后的数据集。
-
通过投影实现数据的降维处理。
二、应用场景
-
图像处理:PCA 可用于图像压缩,在减小图像维度的同时保留主要信息。
-
有助于节省存储空间和提高图像处理效率。
-
金融分析:在金融领域,PCA 可用于降维和风险管理,能够帮助识别资产之间的相关性。
-
为金融决策提供有力支持。
三、优点
-
降维:PCA 能够减小数据的维度,降低存储和计算成本。
-
提高数据处理的效率。
-
去冗余:有助于去除冗余信息,提取出最重要的特征。
-
使数据更加简洁有效。
-
可视化:可将数据可视化,以便更好地理解数据结构和关系。
-
增强对数据的直观认识。
四、缺点
-
信息损失:降维可能会导致信息损失,特别是当较少的主成分用于表示数据时。
-
需要在降维和信息保留之间进行权衡。
-
线性假设:PCA 基于线性假设,可能不适用于非线性数据。
-
对于非线性数据的处理效果有限。
-
选择主成分数量:需要选择保留的主成分数量,这可能是一个主观过程。
-
增加了分析的不确定性。
Python主成分分析PCA、线性判别分析LDA、卷积神经网络分类分析水果成熟状态数据|附代码数据
本文对给定数据集进行多类别分类任务时所采用的各种统计和机器学习技术进行了总结。给定数据集包含 20 个类别,对应 10 种不同的水果及其成熟或未成熟状态。为实现分类任务,首先进行数据可视化,接着进行数据预处理,包括异常值检测技术(如局部异常因子和隔离森林)以及数据缩放技术(如标准缩放器和分位数转换器)。
随后运用降维算法如主成分分析(PCA)和线性判别分析(LDA)以及聚类技术,将聚类 ID 作为额外特征添加到数据集中。最后尝试通过深度学习技术(如卷积神经网络)来提高模型准确性。通过交叉验证评估模型性能,并比较其准确性和计算效率。总体而言,本项目展示了统计机器学习技术在多类别分类任务中的有效性,并强调了异常值检测和降维在提高机器学习模型准确性方面的重要性。
数据加载与重构
- 导入数据:
go
df = pd.read_csv('../../codin.csv')df.head()
``````
df = pd.read\_csv('../../co/train.csv')df.head()将字符串标签转换为代码:categories\_list = df\[ 'category' \].astype( 'category' ).cat.categoriesdf\[ 'category' \] = df\[ 'category' \].astype('category').cat.codes- 拆分数据为特征矩阵和目标向量:
go
X = data\[:,:-1\]y = data\[:,-1\]print(X.shape)print(y)
去除异常值
使用隔离森林去除异常值:
go
from sklearn.ensemble import IsolationForestclf = IsolationForest(max\_samples = 100, random\_state = 1多层感知机神经网络
- 数据标准化:
go
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()- 进行主成分分析:
go
from sklearn.decomposition import PCApca = PCA(n\_components=363)pca.fit(nn\_X_train)- 进行线性判别分析:
go
from sklearn.discriminant\_analysis import LinearDiscriminantAnalysislda = LinearDiscriminantAnalysis(n\_components=19)lda.fit(nn\_X\_train, nn\_y\_train)nn\_X\_train\_lda = lda.transform(nn\_X\_train)nn\_X\_test\_lda = lda.transform(nn\_X\_test)- 构建并训练多层感知机模型:
go
val\_acc = \[\]pca\_acc = \[\]lda\_acc = \[\]pca\_lda\_acc = \[\]for i in range(40, 44):# clf = MLPClassifier(solver='adam' , alpha=1e-5, random\_state=i, max\_iter=10000, hidden\_layer\_sizes=(300, 60))# clf = MLPClassifier(solver='lbfgs' , alpha=1e-5, random\_state=i, max\_iter=10000, hidden\_layer\_sizes=(300, 59))# best one till nowclf = MLPClassifier(solver='adam' , alpha=1e-5, random\_state=i, max\_iter=10000, hidden\_layer\_sizes=(448, 119, 170, 116))# clf = MLPClassifier(solver='adam' , alpha=1e-5, random\_state=i, max\_iter=10000, hidden\_layer\_sizes=(300, 60))clf.fit(nn\_X\_train, nn\_y_train)
- 输出不同处理方式下的平均准确率:
go
print(sum(val\_acc)/len(val\_acc))print(sum(pca\_acc)/len(pca\_acc))print(sum(lda\_acc)/len(lda\_acc))print(sum(pca\_lda\_acc)/len(pca\_lda\_acc))
``````
卷积神经网络
- 特征值归一化:
go
print(X_train.max())
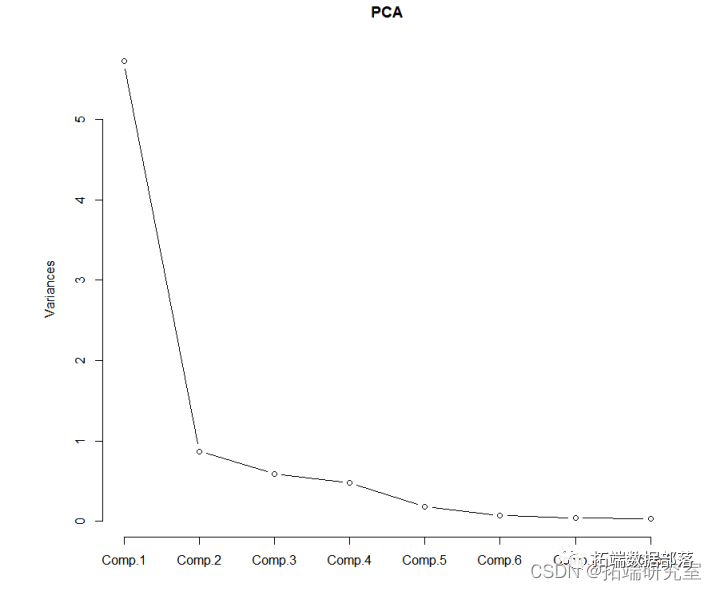
主成分分析PCA
go
from sklearn.decomposition import PCApca = PCA(n\_components=900)X\_train = pca.fit\_transform(X\_train)X\_test = pca.transform(X\_test)X\_train = X\_train.reshape(X\_train.shape\[0\], 30, 30, 1)X\_test = X\_test.reshape(X\_test.shape\[0\], 30, 30, 1)LDA
- 进行线性判别分析:
go
# lda = LDA(n\_components=18)# X\_train = lda.fit\_transform(X\_train, y\_train)# X\_test = lda.transform(X_test)可视化样本
go
plt.figure(figsize=(10,10))for i in range(25):plt.subplot(5,5,i+1)
点击标题查阅往期内容

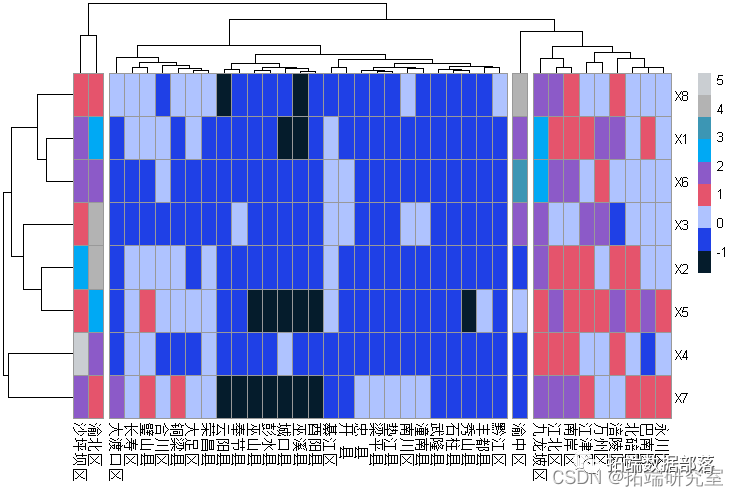
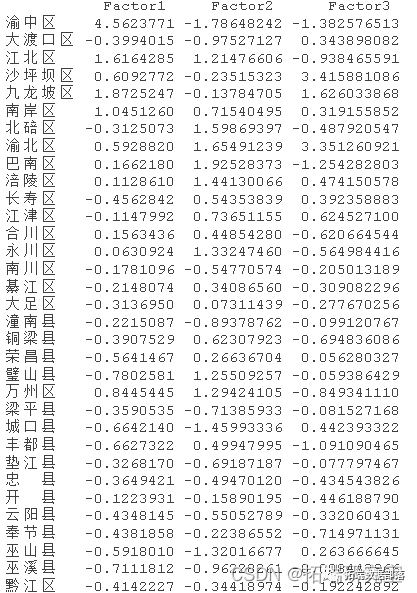
R语言主成分PCA、因子分析、聚类对地区经济研究分析重庆市经济指标

左右滑动查看更多
01
02
03
04
定义卷积神经网络架构
go
from tensorflow.keras import regularizersmodel = models.Sequential()model.add(layers.Conv2D(128, (3, 3), activation

编译卷积神经网络
go
model.compile(optimizer='adam',
绘制准确率与 epoch 的关系图
go
test\_loss, test\_acc = model.evaluate(X\_test.reshape(X\_test.shape\[0\], 64, 64, 1), y_test, verbose=2)
``````
10/10 - 0s - loss: 0.9434 - accuracy: 0.7888 - 211ms/epoch - 21ms/step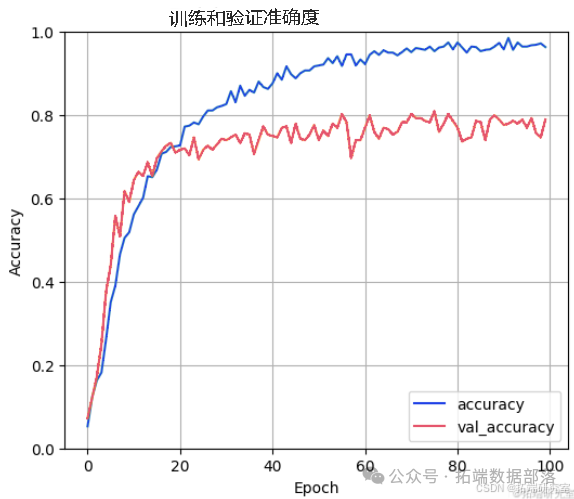
评估模型并输出结果
go
df\_test = pd.read\_csv('../../codes/sml/project/test.csv')df_test.head()
结论
通过对多种机器学习和深度学习技术的应用与比较,本文展示了不同方法在多类别分类任务中的性能表现。同时,数据预处理中的异常值检测和降维技术对提高模型准确性起到了重要作用。未来,可以进一步探索更先进的模型架构和优化方法,以提高多类别分类任务的性能。
关于分析师

在此对Shixian Ding对本文所作的贡献表示诚挚感谢,他在中国科学技术大学完成了计算机科学与技术(主修)和金融学(辅修)的学位,专注机器学习、数理金融、数据采集、数据挖掘领域。擅长 R 语言、Python、MySQL、Matlab。

本文中分析的数据、代码**** 分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取全文完整代码数据资料。
本文选自《PCA主成分分析原理与水果成熟数据实例:Python中PCA-LDA 与卷积神经网络CNN》。
点击标题查阅往期内容
数据分享|R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言逻辑回归logistic模型分析泰坦尼克titanic数据集预测生还情况
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
R语言用局部加权回归(Lowess)对logistic逻辑回归诊断和残差分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言用线性模型进行臭氧预测:加权泊松回归,普通最小二乘,加权负二项式模型,多重插补缺失值
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言多元时间序列滚动预测:ARIMA、回归、ARIMAX模型分析
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据
R语言高维数据的主成分pca、 t-SNE算法降维与可视化分析案例报告
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言使用Metropolis- Hasting抽样算法进行逻辑回归
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分




