大语言模型(Large Language Models, LLMs)通常指的是拥有大量参数和训练数据的深度学习模型,它们在处理语言相关的任务时表现出色,然而,大模型也带来了计算资源消耗大、部署成本高等问题,BERT及其变体能够处理更加复杂和多样化的语言任务
BERT之所以在这些场景中表现突出,是因为它采用了双向编码器(Bidirectional Encoder),能够同时考虑单词前后的上下文信息,从而生成更加丰富和准确的词向量表示,此外,BERT的预训练过程使用了大量文本数据,使其能够捕捉到语言的复杂性和多样性
本篇是大语言模型实战篇的上篇,后续将进一步介绍模型的微调,特别是LoRA微调细节,以及部署实战
1 代码实战目标
本文通过huggingface的Transform类进行BERT的文本分类代码训练与验证,数据集采用网上整理包括正向和负向评论的携程网数据
通过实战完整地去掌握完整代码步骤,包括
数据的加载、创建数据集、划分训练集和验证集、创建模型和优化器、包括训练与验证、模型的训练、模型的预测
实现当输入一个对酒店的评价的一段文字,模型输出对于这个酒店的分析,判断是正向评价还是负面评价
1.1 BERT适用场景
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练语言模型,它在自然语言处理(NLP)领域中具有广泛的应用,以下是一些BERT特别适用的场景:
1、文本分类:BERT可以用于情感分析、主题分类、垃圾邮件检测等文本分类任务。它能够捕捉到文本中细微的语义差异,从而实现更准确的分类。
2、问答系统:BERT可以用于构建问答系统,它能够理解问题的上下文,并在大量文本中找到正确的答案。
3、命名实体识别(NER):在NER任务中,BERT能够识别文本中的特定实体,如人名、地点、组织等。
4、机器翻译:虽然BERT最初是为英语设计的,但它也可以通过多语言预训练模型来支持机器翻译任务。
5、文本摘要:BERT可以用于生成文本的摘要,无论是提取式摘要还是生成式摘要。
6、语言模型评估:BERT可以用于评估其他语言模型的性能,通过比较预训练模型和目标模型的表示。
7、文本相似度:BERT可以用于计算文本之间的相似度,这在推荐系统、搜索引擎优化等领域非常有用。
8、对话系统:BERT可以用于构建对话系统,理解用户的意图,并生成合适的回复。
9、文档分类:在法律、医疗等领域,BERT可以用于对文档进行分类,帮助专业人士快速定位信息。
10、文本生成:虽然BERT主要用于理解语言,但它也可以用于文本生成任务,如续写故事、生成诗歌等。
11、语义匹配:BERT可以用于比较两个句子的语义相似度,这在语义搜索、信息检索等领域非常有用。
12、文本纠错:BERT可以用于检测和纠正文本中的错误,提高文本质量。
13、多任务学习:BERT可以同时处理多个NLP任务,通过共享表示来提高各个任务的性能。
1.2 本次数据集介绍
数据集来源于谭松波整理的携程网数据, 包括7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论
数据集已全部上传到个人gitee仓库,注意该数据集并没有划分训练集和验证集,在后续需要进行按比例进行划分
地址**:https://gitee.com/ethancheng/bert_classification/blob/master/data/ChnSentiCorp_htl_all.txt\*\*
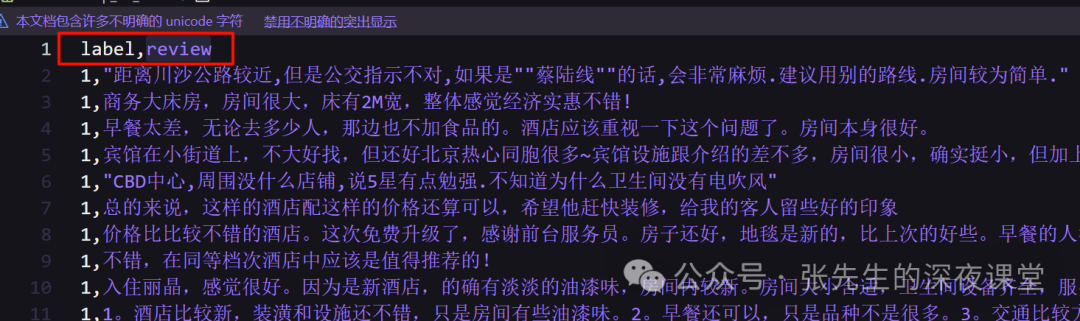
字段说明
| 字段 | 说明 |
|---|---|
| label | 1 表示正向评论,0 表示负向评论 |
| review | 评论内容 |

1.3 实验环境
本次实验使用Linux平台,采用GPU卡进行训练,使用Ubuntu 24.04LTS版本,Python使用Python 3.12.3版本
基本的硬件配置如下:
1、Intel® Core™ Ultra 7 155H 1.40 GHz
2、32GB内存
3、GPU:Nvidia 4070Ti
1.4 代码的整体架构
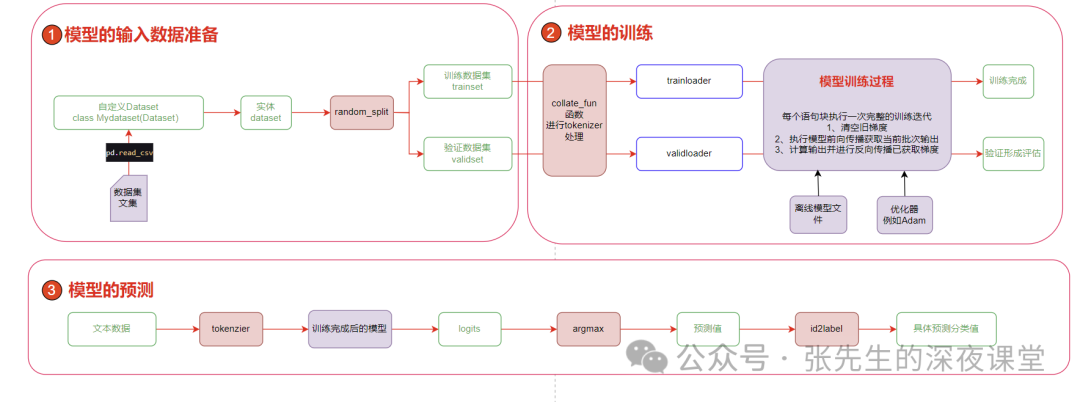
2 安装基础环境
2.1 安装Nvidia驱动
这里强烈推荐采用官方下载run文件进行安装
在Nvidia官网下载对应的驱动
根据自己显卡的情况下载对应版本的显卡驱动。本次环境下我的显卡是4070Ti
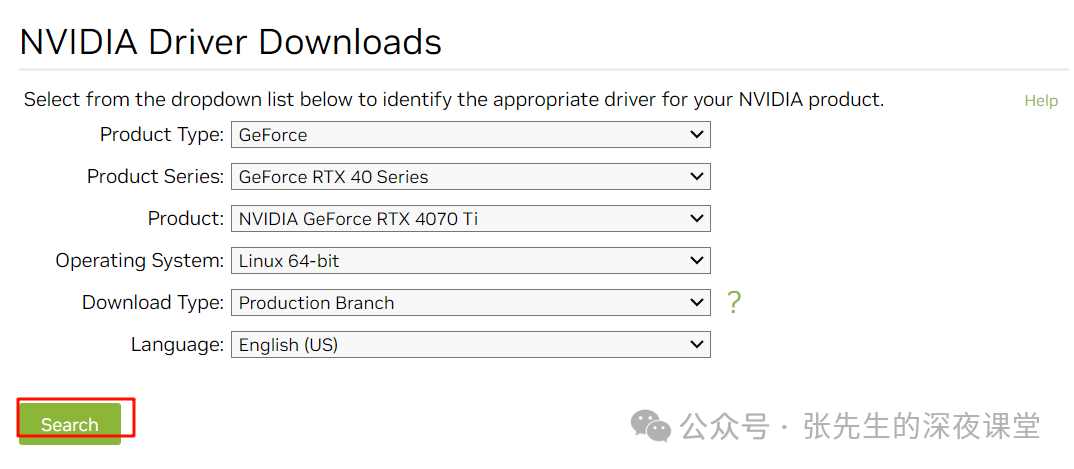
下载完成后,通过scp或者其他工具上传到Linux主机上
正式安装驱动之前,必须安装gcc和make
apt install gcc make安装
chmod +x NVIDIA-Linux-x86_64-550.90.07.run
./NVIDIA-Linux-x86_64-550.90.07.run开始安装

中途会提示以下信息
WARNING: nvidia-installer was forced to guess the X library path '/usr/lib64' and X module path '/usr/lib64/xorg/modules'; these paths were not queryable from the system. If X fails to find the NVIDIA X driver
module, please install the `pkg-config` utility and the X.Org SDK/development package for your distribution and reinstall the driver.意思为
1、nvidia-installer(NVIDIA的安装程序)在安装过程中无法查询到X库和X模块的正确路径,因此它猜测了这些路径可能位于/usr/lib64和/usr/lib64/xorg/modules
2、如果遇到X无法找到NVIDIA X驱动模块的问题,建议安装pkg-config工具和X.Org SDK/开发包
如果遇到以下提示
WARNING: This NVIDIA driver package includes Vulkan components, but no Vulkan ICD loader was detected on this system. The NVIDIA Vulkan ICD will not function without the loader. Most distributions package the
Vulkan loader; try installing the "vulkan-loader", "vulkan-icd-loader", or "libvulkan1" package.意思为:尽管NVIDIA驱动程序包含了Vulkan组件,但是系统缺少必要的Vulkan ICD loader,导致这些组件无法正常工作。用户需要安装相应的Vulkan loader软件包来解决这个问题。
如果遇到以下提示

1、提示中提到 Nouveau 驱动已经存在于 initramfs 中。由于 Nouveau 是开源的 NVIDIA 显卡驱动,而安装 NVIDIA 官方驱动前通常需要禁用 Nouveau,因此这可能是一个不兼容的问题。
2、是否重建 initramfs:提示询问用户是否要重建 initramfs,以确保 Nouveau 驱动不会在系统启动过程中被加载。
Would you like to run the nvidia-xconfig utility to automatically update your X configuration file so that the NVIDIA X driver will be used when you restart X? Any pre-existing X configuration file will be
backed up. 意思是:
1、这个询问是为了确保 NVIDIA 显卡驱动能够被正确配置和使用,同时提供了对现有配置文件的保护措施,以防万一需要回滚到之前的设置
2、如果你希望确保 NVIDIA 驱动能够接管图形界面的控制,并且不介意现有的 X 配置被修改,你可以选择运行这个工具
使用nvidia-smi命令验证
注意:
CUDA Version: 12.4这里的版本是后续安装CUDA Toolkit的依据
注实际上
nvitop比nvidia-smi更加可视化,特别是对于资源的占用可以类似top动态监控

2.2 安装CUDA Toolkit
注意nvidia-smi中显示的 CUDA Version: 12.4
前往官网
https://developer.nvidia.com/cuda-toolkit-archive/选择nvidia-smi命令显示所匹配的CUDA版本
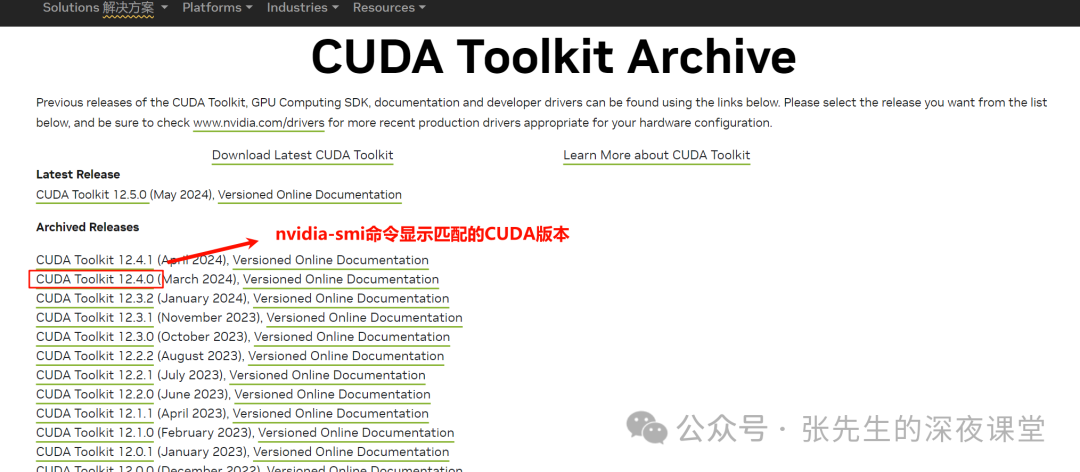
针对自己Linux版本选择正确CUDA Toolkit版本
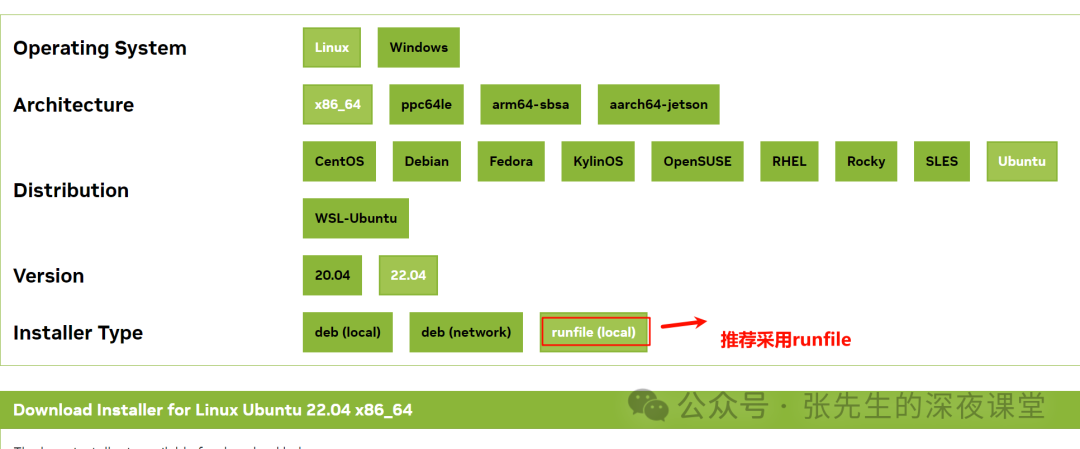
具体安装步骤
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
sudo sh cuda_12.4.0_550.54.14_linux.run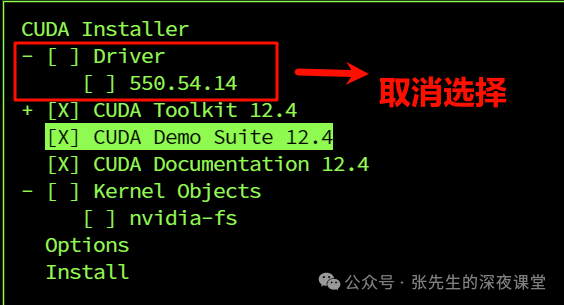
【可选项添加到环境变量】
Please make sure that
- PATH includes /usr/local/cuda-12.4/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-12.4/lib64, or, add /usr/local/cuda-12.4/lib64 to /etc/ld.so.conf and run ldconfig as root我们手动添加到环境变量文件~/.bashrc中
直接点我们可以运行命令验证

至此CUDA Toolkit安装完毕
2.3 设置pip国内镜像站点
由于某墙的原因,直接使用原始国外的pip源,安装速度会很慢
永久将pip的镜像地址设置为清华大学
install python3-pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple如果需要恢复
pip config set global.index-url https://pypi.org/simple2.4 安装虚拟环境
第一步我们先建立代码部署的基础环境,包括pytorch、huggginface transforms类,以及jupterlab等工具
虚拟环境使得每个项目可以拥有自己的依赖库,互不影响
2.4.1 Anaconda
当然我们可以使用使用范围最广的Anaconda工具,但这款体积较大
Anaconda 是一个流行的开源数据科学平台,旨在简化数据科学和机器学习任务的环境配置和包管理
Anaconda 提供了以下主要功能:
1、一站式安装:Anaconda 包含了许多常用的数据科学和机器学习库
2、环境管理:Anaconda 允许用户创建和管理多个独立的环境
3、包管理:Anaconda 使用名为 Conda 的包管理器来安装、更新和管理库
4、Jupyter Notebook:Anaconda 集成了 Jupyter Notebook
本人更加推荐使用
miniconda,本篇采用Python自带venv虚拟环境
2.4.2 使用venv创建虚拟环境
venv是Python自带的一种虚拟环境管理工具,它允许开发者在隔离的环境中安装和管理不同版本的Python包,从而避免不同项目间的依赖冲突
在Python 3.3之前的版本中,需要使用virtualenv这个第三方库来实现类似的功能
如果你使用的是Python 3.3或更高版本,就可以直接使用venv来创建和管理虚拟环境
我们开始创建一个用于本次实验环境的虚拟环境,从而避免不同项目间的依赖冲突
apt install python3-venv
python3 -m venv huggingface其中python3指的是Python 3的解释器,-m venv告诉Python解释器使用venv模块来创建虚拟环境。huggingface是你想要创建的虚拟环境的名字
2.4.3 使用miniconda创建虚拟环境
访问官网https://docs.anaconda.com/free/miniconda/
https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
安装
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh安装完成后,需要初始化
~/miniconda3/bin/conda init bash
#or
~/miniconda3/bin/conda init zsh创建虚拟环境
conda create -n huggingface2.5 激活虚拟环境
采用venv方式激活
source huggingface/bin/activate
(huggingface) ethan@Ethan-Carbon-X1:~$采用miniconda方式激活
conda activate huggingface虚拟环境激活后,在命令行提示符前会有虚拟环境名称的标注,表明已经进入虚拟环境
进入虚拟环境后,确保后续的依赖包就可以在虚拟环境下安装
2.6 安装pytorch
建议直接使用官网建议的安装脚本
地址:https://pytorch.org/get-started/locally/
注意区别CUDA版本和CPU版本

命令行输入进行安装(Linux环境下推荐采用Conda方式,会比PIP方式更快)
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
# or
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121安装过程中如果出现错误,可以使用
pip cache purge或者conda clean --tarballs清除缓存
conda的安装支持断点续传
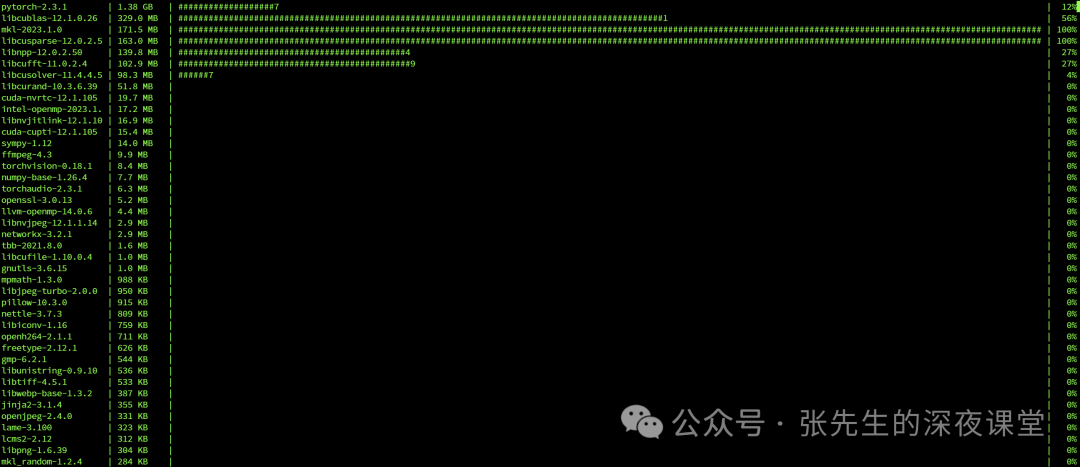
多次实践证明采用conda方式安装pytorch速度快不少
安装完成后验证

如果能够正常返回向量,说明pytorch安装成功
2.7 安装transformers库
在虚拟环境下,我们使用conda直接安装hugginface的transformers库
conda install -c conda-forge transformers完成transformers库后,提示
Installing collected packages: urllib3, typing-extensions, tqdm, safetensors, regex, pyyaml, packaging, numpy, idna, fsspec, filelock, charset-normalizer, certifi, requests, huggingface-hub, tokenizers, transformers
Successfully installed certifi-2024.6.2 charset-normalizer-3.3.2 filelock-3.14.0 fsspec-2024.5.0 huggingface-hub-0.23.2 idna-3.7 numpy-1.26.4 packaging-24.0 pyyaml-6.0.1 regex-2024.5.15 requests-2.32.3 safetensors-0.4.3 tokenizers-0.19.1 tqdm-4.66.4 transformers-4.41.2 typing-extensions-4.12.1 urllib3-2.2.12.8 安装jupyterlab
对于机器学习而言,jubpyerlab极大提升了生产力
它允许用户在一个浏览器页面中同时打开和编辑多个 Notebook、IPython 控制台和终端终端,并且支持预览和编辑多种文件类型,如代码文件、Markdown 文档、JSON、YAML、CSV 以及各种格式的图片
直接在虚拟环境下安装jupyterlab
conda install jupyterlab启动jupyerlab
如果后续需要利用vscode远程调试的,本地不需要启动
jupyter lab --allow-root执行完毕后系统返回具体信息

我们可以选择打开提示的urlhttp://localhost:8888/lab?token=ebcd54a2d2b7031dcc195a9831f4fe7aabca3dfb23b51c46
2.9 功能验证测试
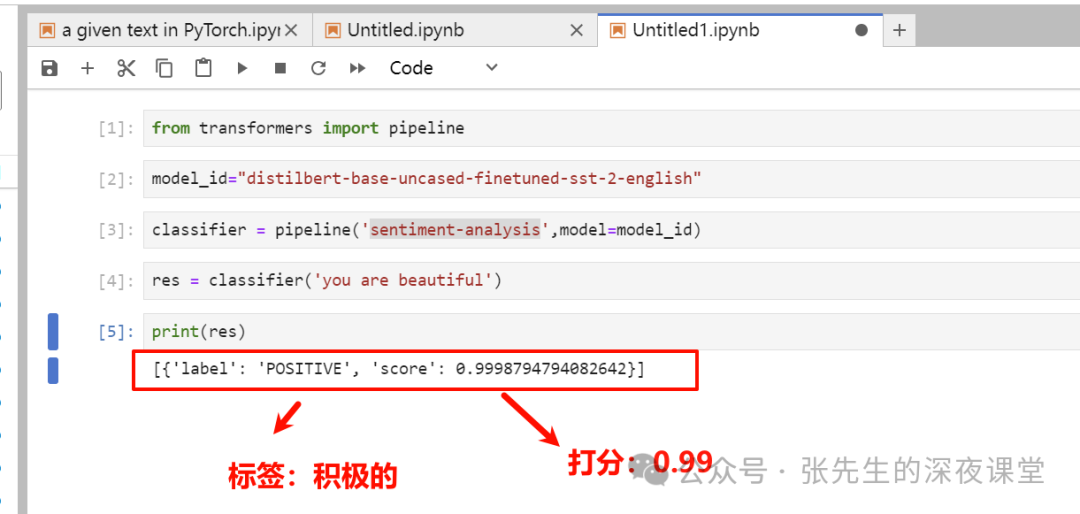
基础环境部署后,我们可以使用hungginface的pipeline直接做词语情感分析,具体代码如下

import os os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'由于huggingface已经对国内禁用,上述两行代码是使用国内镜像地址代替
返回以下表示,基础环境部署正确
[{'label': 'POSITIVE', 'score': 0.9998794794082642}]如果我们使用jupterlab的话,我们可以更加方便输入测试验证代码
2.10 利用vscode远程调试jupyterlab
使用vscode远程调试jupyterlab的优势在于除了具有jupyterlab本身的功能外,还有代码提示功能,且更容易方便查看源码
使用vscode,需要提前安装Remote Development插件
需要安装Jupyyer插件且在远程主机上启用扩展
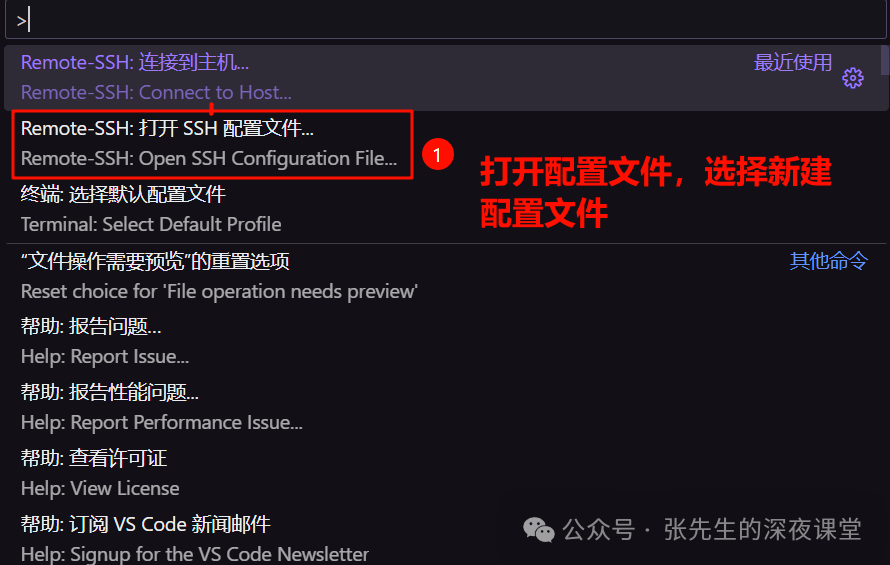
1、在 VSCode 中,使用命令面板(Ctrl+Shift+P 或 Cmd+Shift+P)输入 "Remote-SSH: Open Configuration File" 来打开或创建 SSH 配置文件
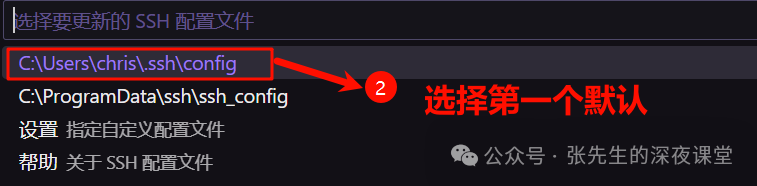
选择第一个默认配置文件进行编辑
进行配置
Host 4070Ti
HostName 58.33.40.xx
User root
Port 22这里密码不输入
2、在 VSCode 中,使用命令面板输入 "Remote-SSH: Connect to Host..." 并选择你的远程主机
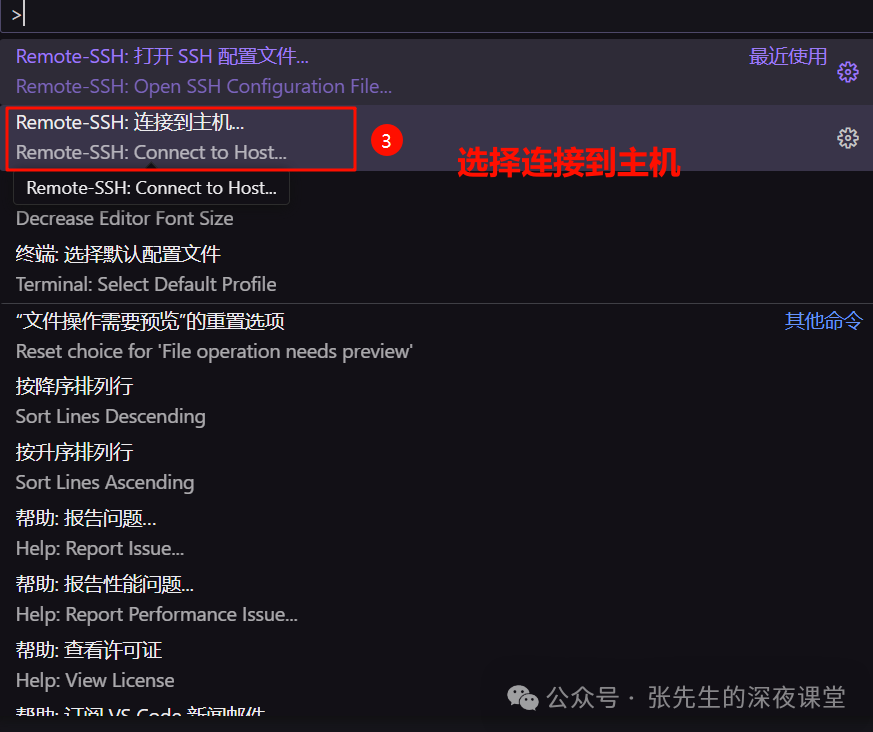
 image-20240608123323664
image-20240608123323664
提示接受指纹
提示输入密码
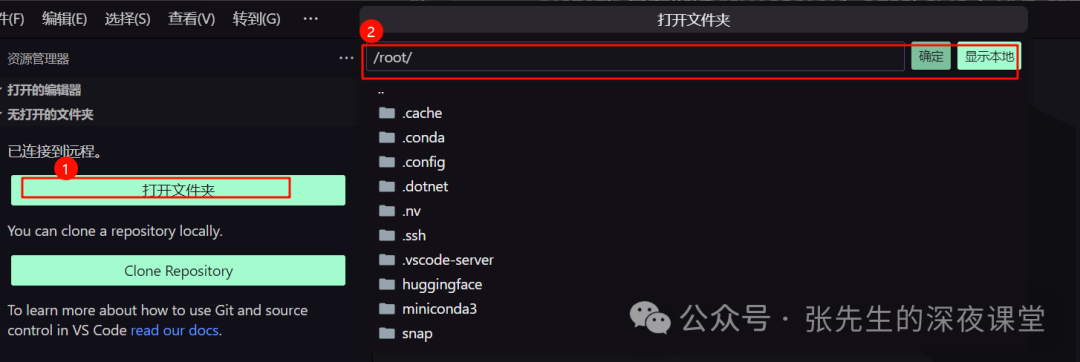
此时已经连接到远程,打开文件夹
信任

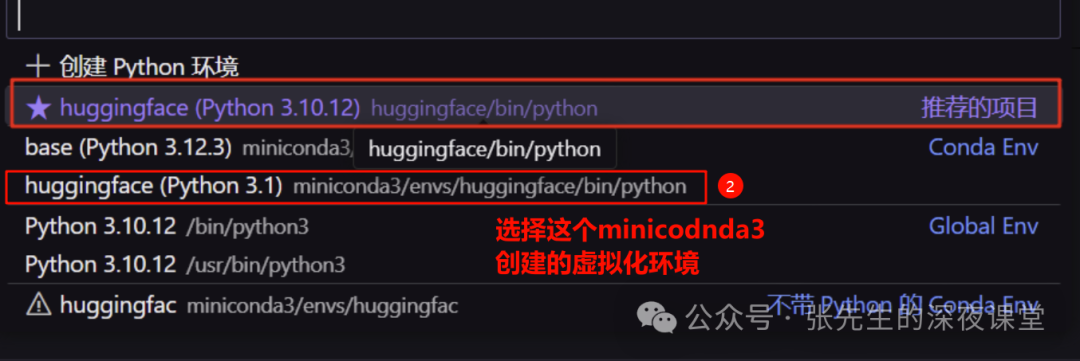
右上角的选择内核

选择具体的虚拟环境
注意
1、第一个系统推荐的项目是使用venv创建虚拟环境下
2、而本文后续都是通过miniconda创建的虚拟环境,且后续各种库均是在这个虚拟环境下安装的,因此选择第三个即miniconda3/envs/huggingface/bin/python
注意一个小技巧
初次使用jupyter远程调试时,会提示
/root/miniconda3/envs/huggingface/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html具体原因是因为tqdm 试图集成到 Jupyter notebook 或 IPython 中的进度条显示,但是没有找到 IProgress 组件,因此需要手动安装,务必要在虚拟环境下安装
conda activate huggingface
conda install ipywidgets2.11 退出虚拟环境
后续想提出虚拟环境
1、如果采用venv环境我们可以使用deactivate进行退出
2、如果采用miniconda创建虚拟环境的,使用conda deactivate进行退出
3 代码实战部分
3.1 术语解释
1、Batch size 是指在训练过程中,每次迭代(iteration)用于计算损失函数和更新模型参数的数据样本数量
2、Data size 是指整个训练数据集的大小,即训练集中所有样本的总数
3、Epoch 是指整个训练数据集被完整地用于训练模型的次数
注意:
1、一个 epoch 意味着每个样本至少被使用一次来更新模型,可以设置多个epoch,过多的 epoch 可能导致过拟合,而太少的 epoch 可能导致模型未能充分学习
2、如果Data size是10,Batch size是3,则一次Epoch需要4次Iteration
这三个参数共同决定了模型训练的过程和效果
4、Dataset是数据集的抽象表示,它定义了如何访问数据集中的每个样本,一次返回一条记录
5、Dataloader用于从Dataset中批量加载数据,并提供多线程加载和数据打乱等功能
6、DataLoader作为数据流的来源,它会按照指定的批次大小和迭代次数来提供数据。这样模型就可以在每个epoch中迭代整个数据集,而不需要手动管理数据的加载和批处理
7、vscode直接新建后缀名为ipynb的代码文件,vscode则会自动打开jupter插件
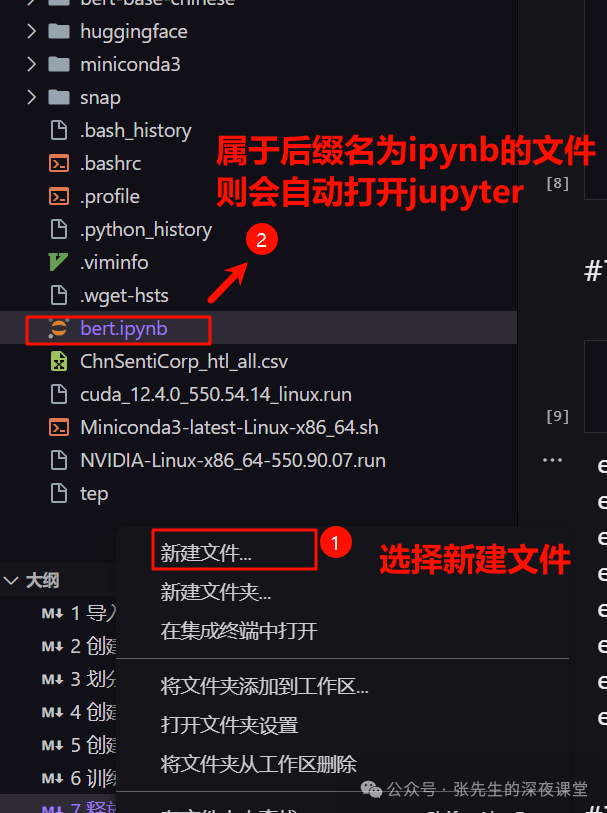
3.2 导入相关包
第一步是导入相关包
注意Dataset、AutoTokenizer、AutoModelForSequenceClassification的包需要依赖相关包,因此需要安装pytorch和transformers库,安装步骤详见2.5和2.6章节

注意
使用vscode远程调试时,注意notepbook的工作路径,可能需要手动设置当前notebook所在的工作路径,防止后续找不到索要加载的数据集和模型
import os
os.chdir("/root")3.3 创建自定义Dataset
第二步是创建自定义的Dataset类

具体解释如下
1、Pytorch约定,自定的Dataset类必须实现__init__(self),__getitem__(self, index)以及__len__(self)三个类的方法
2、__init__(self)方法中首先加载父类的方法,然后通过pd.read_csv去加载数据集,self.data.dropna()去删除其中空白行
3、__getitem__(self, index)去返回指定索引的数据
注意这里的
review和label是要根据数据集具体的标头去设置
4、__len__(self)直接返回数据集的长度
3.4 划分训练集和验证集
由于训练集和验证集是合在一起的,因此有必要将其进行划分,这里使用了random_split类
from torch.utils.data import random_split
trainset,validset = random_split(dataset,lengths=[0.9,0.1])这里的
lengths=[0.9,0.1],通过设置lengths参数将训练集和验证集进行了9:1的拆分,注意如果这里使用了比例进行拆分,比例的总和必须等于1
合理分配训练集和验证集的大小是至关重要的,因为这会影响到模型的训练效果和泛化能力
一个常见的小规模数据集训练集、验证集、测试的比例为6:2:2,大规模的比例可以是98:1:1
3.5 创建自定义Dataloader
Dataloader需要去从Dataset去读取数据,它提供了一种简便的方式来迭代数据集
这里需要设置批处理读取的数量即batch_size(具体参见3.1术语解释 ),shuffle参数代表是否乱序
这里一个很重要的操作就是,要先定义一个collate_fn函数,在这个函数中我们将Dataset原始文本通过tokenizer去进行词向量的转换
collate_fn是DataLoader的一个可选参数,它允许用户自定义如何将多个数据样本(通常是在一个batch中)合并成一个batch
用过 Word2Vec 的小伙伴应该比较清楚,在 Word2Vec 中,对于同一个词语,它的向量表示是固定的,因此对于不同语境下同一个单词所表达的不同语义是没有办法照顾到的
BERT 中则不一样,根据上下文的不同,对于同一个 token 给出的词向量是动态变化的
BERT 通过基于字符、字符片段、单词等不同粒度的 token 覆盖并作 WordPiece(WordPiece是一种用于自然语言处理中的词汇分割算法),能够覆盖上百种语言,甚至可以说,只要你能够发明出一种逻辑上自洽的语言,BERT 就能够处理
我们先将Dataloader完整的代码先贴出来,重点逐个解释
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
def collate_fun(batch):
texts ,labels = [],[]
for item in batch:
texts.append(item[0])
labels.append(item[1])
inputs = tokenizer(texts,max_length=128,padding="max_length",truncation=True,return_tensors="pt")
inputs["labels"] = torch.tensor(labels)
return inputs
from torch.utils.data import DataLoader
trainloader = DataLoader(trainset,batch_size=64,shuffle=True,collate_fn=collate_fun)
validloader = DataLoader(validset,batch_size=64,shuffle=False,collate_fn=collate_fun)代码部分解释
1、函数中batch形参表示Dataset批处理读取的数据
例如当我们batch_size设置为2时,DataLoader读取的一次batch为一个列表,里面是元组
可以看出其中review点评内容是原始文本,需要进行Token embeddings词向量转换
[('第一次住这个酒店,感觉还不错,特别是酒店里面和周边的环境非常好!我们一家三口入住的是行政楼(四合院)标准间,(我原来订的是标准间,运气好,给我免费升级了)房间很宽敞,从房间就可以直接走到户外的庭院,早上起来走出去感觉很舒服。酒店的康乐设施也很齐全,带儿子玩了儿童乐园,沙狐球,(酒店有池塘可以钓鱼,我们没来得及去)值得一提的是酒店游泳池,很大,很舒服,据说是直接从双溪景区的水引进来净化的。晚上我们3个人到中餐厅吃饭,消费算是实惠,吃了不到200块,有一道毛笋干烧肉味道很好。总体来说,性价比很高,600多点的价格住这样一个五星(在总台看到了五星的牌子)还是很值的,推荐大家周末去度假。', 1), ('酒店比较干净,设施也不错。反正就200出头的酒店也是相当的不错了,就是一般房间不带早餐让人不解,钱也不多啊。。。。大不了转嫁到房费里面好了', 1)]2、需要对原始文本做词向量变换,重点就是tokenizer函数
for item in batch:我们遍历一次batch,将内容拆分为两个列表 ,其中review点评内容进行Token embeddings词向量转换
因此使用了inputs = tokenizer(texts,max_length=128,padding="max_length",truncation=True)
max_length=128代表最长不要超过128个字
padding="max_length",当长度不足的时候进行填充,需要将它们填充到相同的长度
truncation=True,超过最大长度时候进行截断
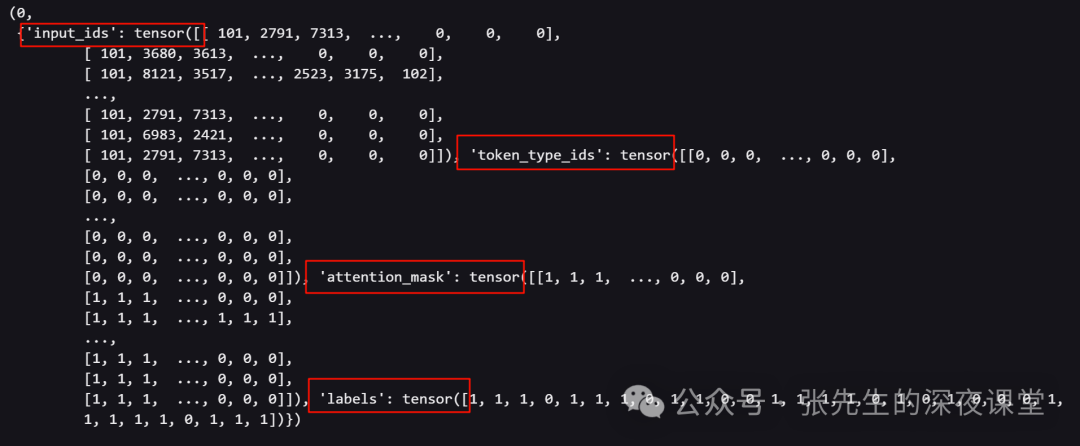
3、我们注意务必将参数设置return_tensors="pt"表示输出数据将作为 PyTorch 张量返回,而不是 NumPy 数组或其他格式
我们对比原始文本格式和词向量的格式
另外这里tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese"),调用模型的AutoTokenizer组件,需要离线加载,理线架在部分详见《3.9 如何离线使用Huggingface模型》相关信息
至此所有调用模型前的数据处理工作均已完成
3.6 创建自定义模型和优化器
Adam(Adaptive Moment Estimation)优化器是一种流行的梯度下降优化算法,它结合了动量(Momentum)和RMSprop(Root Mean Square Propagation)的思想,Adam优化器在很多深度学习任务中表现良好,尤其是在处理大规模的数据集和模型时

代码解释:
1、使用PyTorch框架中的Adam优化器来优化一个模型的参数
2、学习率Learning Rate:BERT模型的分类任务学习率并没有一个固定的标准,它会受到多种因素的影响,包括任务的复杂性、数据集的大小、模型的规模以及训练策略等
对于BERT这样的大型模型,通常建议使用较小的学习率,如2e-5(0.00002)、3e-5(0.00003)或5e-5(0.00005)。这些学习率能够确保模型在训练过程中稳定地收敛
使用Adam优化器时,一个常见的学习率是2e-5,而使用SGD(随机梯度下降)时,可能需要根据具体情况调整学习率
创建后,回返回提示:
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-chinese and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.大致意思就是
1、正在使用的BERT模型在序列分类任务中有一些权重是新初始化的,因此需要通过训练来调整这些权重,以便模型能够用于实际的预测和推理任务
2、这表明模型中的classifier.bias和classifier.weight这两个权重是新初始化的,而不是从预训练模型的检查点加载的。classifier通常指的是模型的最后一层,用于将BERT的输出转换为特定任务的输出,比如分类任务的类别概率
3、建议用户应该对这个模型进行训练,以适应特定的下游任务(down-stream task)
3.7 训练和验证
先放上代码

代码解释
1、evaluate()为验证函数,返回验证集下计算出的准确率,acc_num / len(validset),其中acc_num用于累计正确预测的数量
.float(): 将比较操作的结果(布尔值张量)转换为浮点数。True 转换为 1.0,False 转换为 0.0。这样,每个预测正确的位置现在是一个 1.0,错误的是一个 0.0
sum()这是一个聚合操作,用于计算上一步得到的浮点数张量的元素总和,总和的值等于正确预测的数量
2、output.logits: 这是模型输出中的一个属性,包含了模型对于每个类别的原始分数(未经过 softmax 函数处理的值)。在分类任务中,logits 是一个二维张量(2D tensor),dim这是 torch.argmax() 函数的一个参数,指定了要在哪个维度上寻找最大值。在这个例子中,dim=-1 表示函数将在最后一个维度上寻找最大值,这通常是类别的维度
pred = torch.argmax(output.logits,dim=-1)其实就是从模型输出的原始分数(logits)中,找到每个样本最有可能属于的类别索引
3、变量 global_step 除以 log_step 的余数是否为0,如果为0意味着 global_step 是 log_step 的整数倍,这通常用作日志记录或打印进度的触发条件
4、batch = {k: v.cuda() for k,v in batch.items()},这段代码是在使用PyTorch框架进行深度学习模型训练时,将数据批次(batch)中的所有张量(tensors)移动到GPU上以加速计算,如果程序在支持CUDA的GPU上运行,这将加速张量的操作,因为GPU特别适合进行并行计算
5、for ep in range(epoch):是设置训练的次数
6、for batch in trainloader:是训练完训练集所有数据所执行的语句块,每个语句块执行一次完整的训练迭代包括:
-
清空旧梯度:
optimizer.zero_grad()在PyTorch中,梯度默认是累加的,因此每次参数更新前都需要清空之前的梯度,以避免它们对新的梯度计算产生影响
-
执行模型的前向传播来获取当前批次的输出:
output = model(**batch)**batch: 这是Python的解包操作符,它将batch字典中的键值对作为命名参数传递给模型的forward方法 -
计算输出损失并进行反向传播以获取梯度:
output.loss.backward()loss属性就是损失值,backward()用于计算损失相对于模型参数的梯度,这个过程就是反向传播 -
使用优化器根据梯度更新模型参数:
optimizer.step()
需要在每个训练批次上重复执行,直到模型在验证集上的性能达到满意的水平
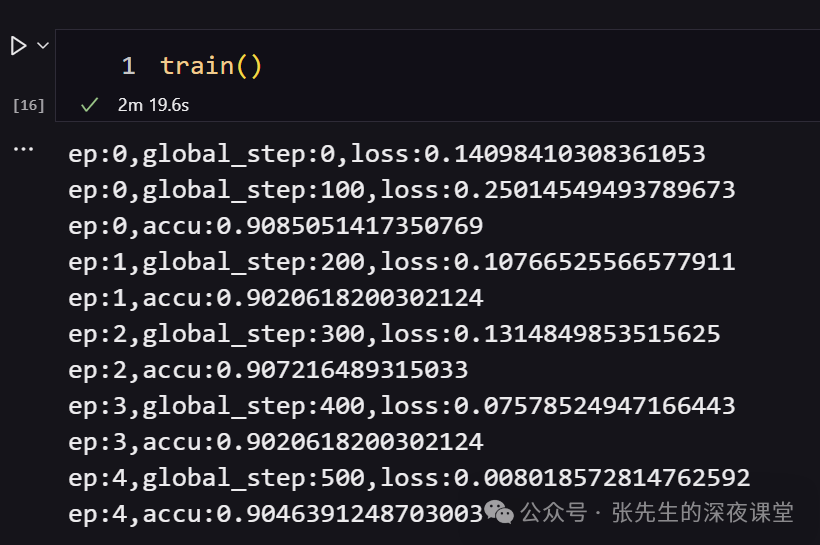
开始模型训练和验证
3.8 模型预测
先放上代码

返回最终结果为好评

针对当前输入值,变量logits,为tensor([[-1.1857, 1.6127]]
变量pred为tensor([1])
3.9 资源查看和优化
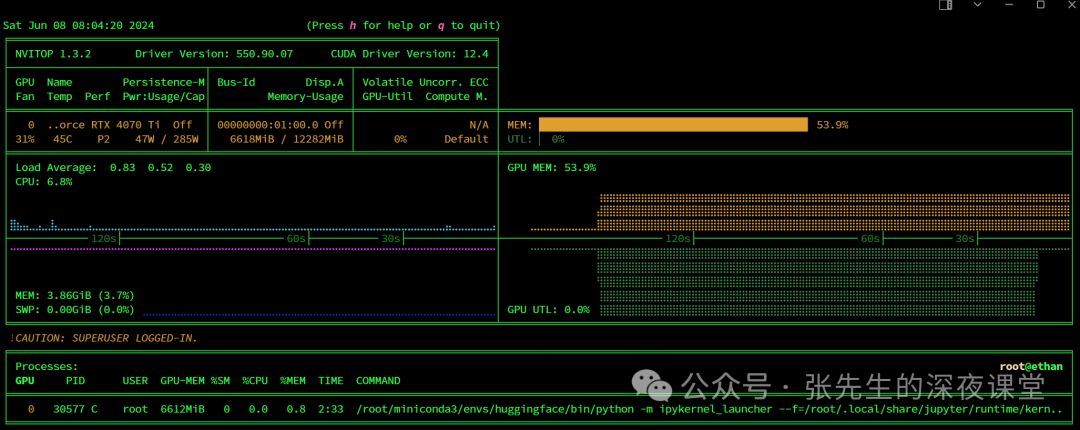
我们在模型训练过程中我们可以通过nvitop命令来查看来监控显存使用情况,确保显存被正确释放
使用conda install -c conda-forge nvitop进行安装
我们的显卡的内存占用稳定为53.9%
当我们batch_size又原来的调整为128,12G显卡内存几乎被占满
trainloader = DataLoader(trainset,batch_size=128,shuffle=True,collate_fn=collate_fun)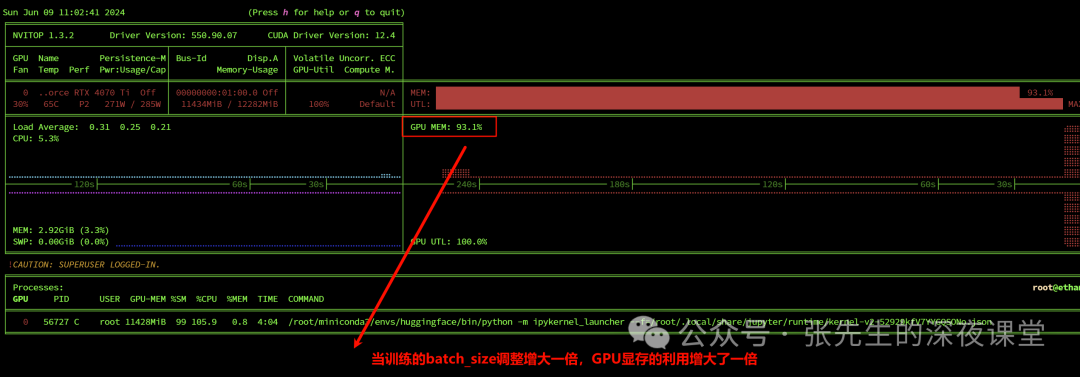
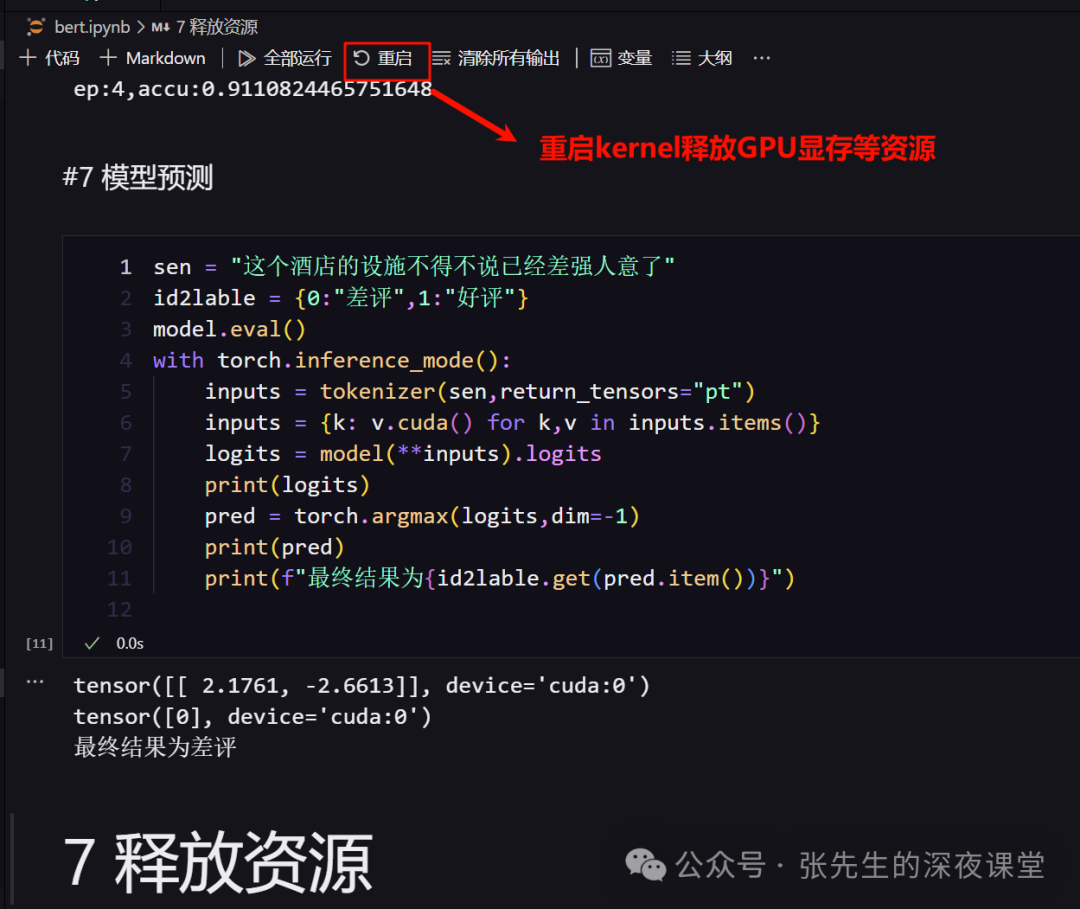
3.10 释放资源
使用 Jupyter Notebook 界面:在 Jupyter Notebook 界面中,你可以点击菜单栏的 "Kernel",然后选择 "Restart" 选项
如果是本文这种远程方式连接到主机,可以直接在vscode界面中
3.11 如何离线使用Huggingface模型
由于国内网络问题,我们是无法访问Huggingface官网的
首先我们想办法先正常访问到Huggingface官网https://huggingface.co/
查找我们需要的模型,例如google-bert/bert-base-chinese
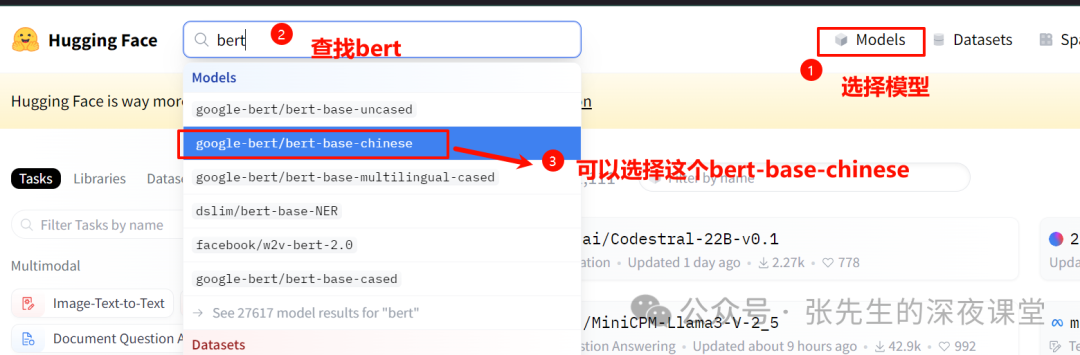
选择对应的模型
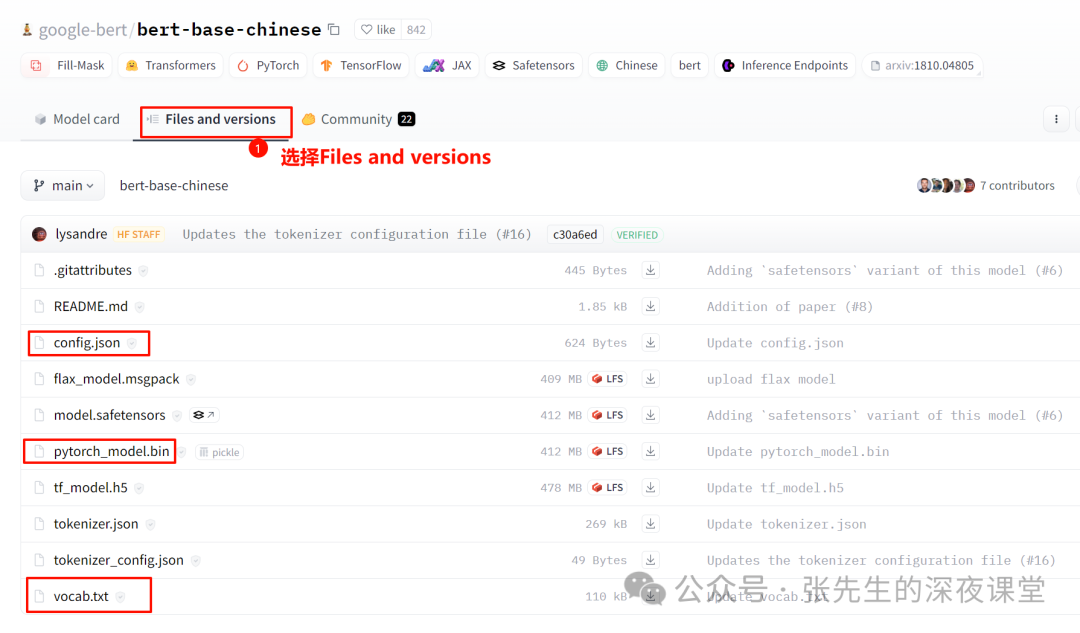
我们选择下载
1、config.json: 模型的配置文件,里面记录了所有用于训练的参数设置
2、PyTorch_model.bin:模型文件本身
3、vocab.txt:词表文件,尽管 BERT 可以处理一百多种语言,但是它仍旧需要词表文件用于识别所支持语言的字符、字符串或者单词
tf_model.h5是TensorFlow 的模型,model.safetensors是safetensors格式,flax_model.msgpack使用Flax库序列化的预训练模型文件
不会解决网络的朋友也可以使用国内镜像站点https://hf-mirror.com/
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。